Qwenの画像編集モデル「Qwen−Image-Edit」を試す
前回試したQwen-Image
画像編集は後日リリースとなっていたのだがリリースされた様子。
モデル
GPT-5による翻訳
referred from https://huggingface.co/Qwen/Qwen-Image-Edit
referred from https://huggingface.co/Qwen/Qwen-Image-Editはじめに
Qwen-Image の画像編集バージョンである Qwen-Image-Edit を紹介できることを大変嬉しく思います。20B Qwen-Image モデルを基盤として構築された Qwen-Image-Edit は、Qwen-Image 独自のテキスト描画機能を画像編集タスクへと拡張し、精密なテキスト編集を可能にしました。さらに、Qwen-Image-Edit は入力画像を Qwen2.5-VL(視覚的意味制御用) と VAE Encoder(視覚的外観制御用) に同時に入力することで、意味編集と外観編集の両方に対応しています。最新モデルを体験するには、Qwen Chat にアクセスし、「Image Editing」機能を選択してください。
主な特徴:
- 意味編集と外観編集: Qwen-Image-Edit は、低レベルの視覚的外観編集(要素の追加・削除・修正を行い、他の領域は完全に変更しない)と高レベルの意味編集(IP の創作、物体の回転、スタイル変換など、ピクセル全体を変えても意味的一貫性を保持する)の両方をサポートします。
- 精密なテキスト編集: Qwen-Image-Edit は中国語と英語のバイリンガルテキスト編集に対応しており、画像内のテキストをフォント・サイズ・スタイルを維持したまま直接追加・削除・修正できます。
- 強力なベンチマーク性能: 複数の公開ベンチマークでの評価により、Qwen-Image-Edit は画像編集タスクにおいて最先端(SOTA)の性能を達成し、強力な基盤モデルであることが実証されています。


ショーケース
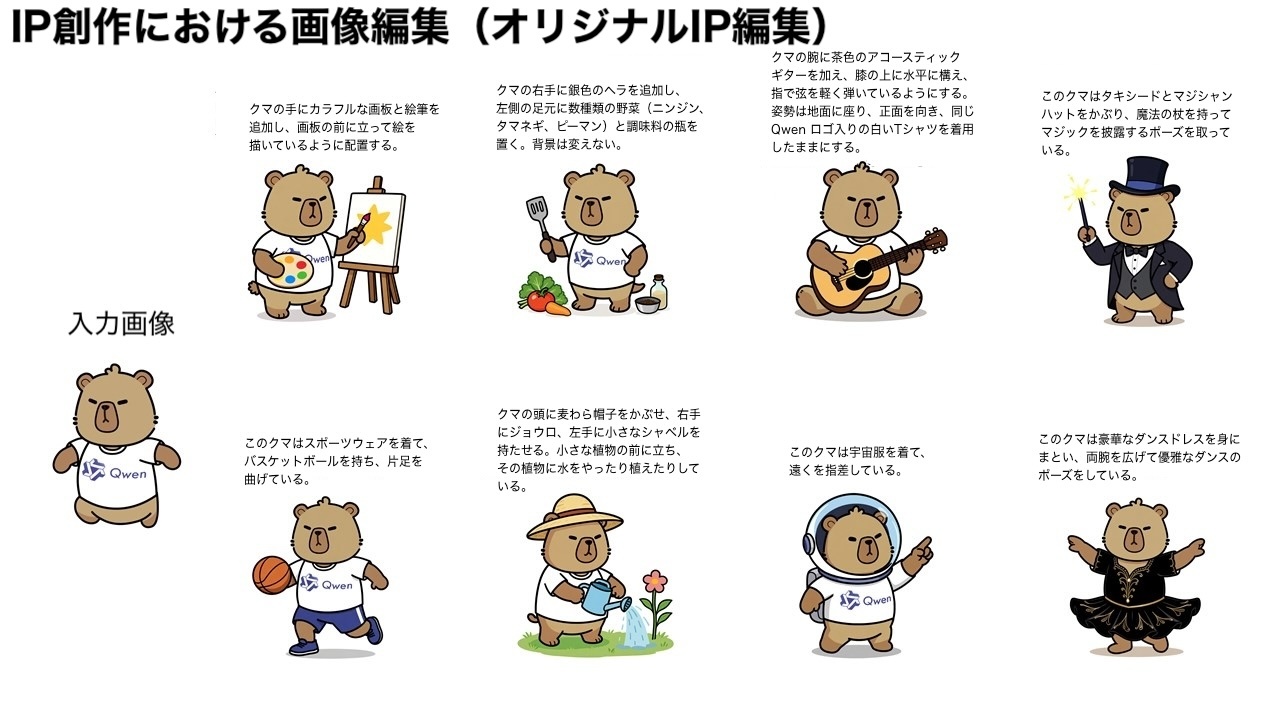
Qwen-Image-Edit の大きな特徴のひとつは、意味編集と外観編集の強力な能力にあります。意味編集とは、元の意味的な一貫性を保持しつつ、画像の内容を修正することを指します。この能力を直感的に示すために、Qwen のマスコットであるカピバラを例にしてみましょう。
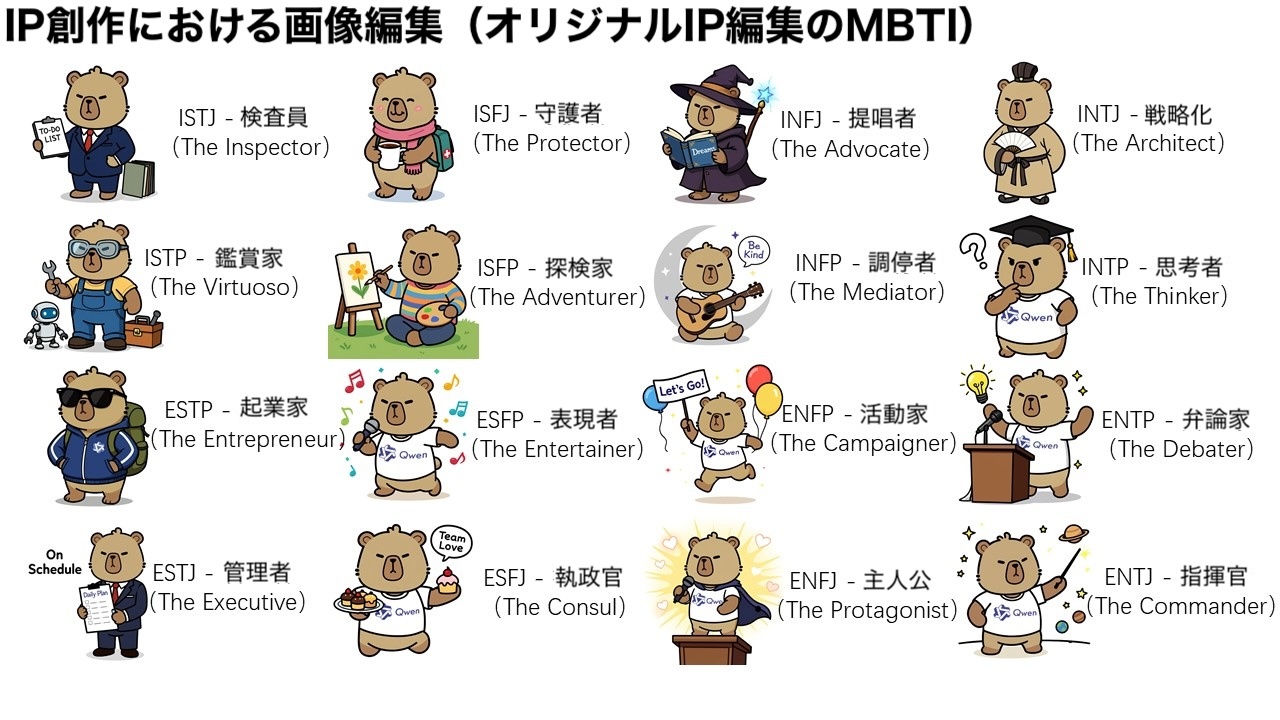
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432ご覧の通り、編集後の画像は入力画像(最も左の画像)と多くのピクセルが異なるにもかかわらず、カピバラのキャラクターとしての一貫性は完璧に保持されています。Qwen-Image-Edit の強力な意味編集能力により、オリジナル IP コンテンツの多様で容易な創造が可能です。さらに Qwen Chat 上では、16 の MBTI 性格タイプをテーマにした編集プロンプトを設計しました。これを利用して、マスコットのカピバラを基に MBTI テーマの絵文字パックを作成し、IP の表現と展開を容易に拡大しました。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432また、新しい視点の合成も意味編集の重要な応用シナリオです。以下の例では、Qwen-Image-Edit が物体を 90 度回転させるだけでなく、180 度の回転を行い、物体の背面を直接確認できることを示しています。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432意味編集のもう一つの典型的な応用はスタイル変換です。例えば、入力された肖像画をジブリ風などさまざまな芸術スタイルに簡単に変換できます。この機能はバーチャルアバターの生成などに大きな価値を持ちます。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432意味編集に加えて、外観編集も一般的な画像編集の要件です。外観編集は、画像の特定領域を完全に保持したまま、特定の要素を追加・削除・修正することに重点を置きます。以下の画像は、看板をシーンに追加する例を示しています。ご覧のように、Qwen-Image-Edit は看板を正しく挿入するだけでなく、それに対応する反射も生成し、細部にまで優れた配慮を示しています。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432次の例では、髪の毛の細い毛束や小さな物体を取り除く方法を示しています。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432さらに、画像内の特定の文字「n」の色を青に変更し、特定要素を精密に編集できます。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432外観編集は、人物の背景調整や服装変更といったシナリオにも広く応用できます。以下の 3 枚の画像は、それぞれの実用的な利用例を示しています。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432Qwen-Image-Edit の際立った機能のひとつは、正確なテキスト編集能力です。これは Qwen-Image の深いテキスト描画技術に基づいています。以下の 2 つの事例は、英語テキスト編集における Qwen-Image-Edit の強力な性能を鮮やかに示しています。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432Qwen-Image-Edit は中国語のポスターも直接編集でき、大きな見出し文字の修正だけでなく、小さく複雑な文字要素の精密な調整も可能です。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432最後に、Qwen-Image によって生成された書道作品の誤りを段階的に修正するための連鎖的な編集アプローチを具体例で示します。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432この作品には生成エラーを含む漢字がいくつか存在します。Qwen-Image-Edit を利用すれば、それらを一歩ずつ修正できます。例えば、元の画像にバウンディングボックスを描き、修正すべき領域を指定し、Qwen-Image-Edit に特定部分を修正させます。ここでは「稽」を赤枠で正しく書かせ、「亭」を青枠で正確に描画するよう指示しています。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432しかし実際には、「稽」という文字は比較的珍しく、モデルは一度では正しく修正できませんでした。「稽」の右下部分は「日」ではなく「旨」であるべきです。この時点で「日」の部分を赤枠でさらに強調し、Qwen-Image-Edit にこの細部を調整させて「旨」に置き換えます。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432素晴らしいと思いませんか?このように連鎖的で段階的な編集アプローチを用いることで、目的の最終結果に至るまで文字の誤りを継続的に修正できます。
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432
referred from https://huggingface.co/Qwen/Qwen-Image-Edit and translated into Japanese by kun432最終的に、完全に正しい書道版の『蘭亭序』を得ることに成功しました!
まとめると、Qwen-Image-Edit が画像生成分野をさらに前進させ、視覚コンテンツ制作の技術的障壁を本当に下げ、さらに多くの革新的な応用を促進することを願っています。
ライセンス契約
Qwen-Image は Apache 2.0 ライセンスの下で提供されています。



















おそらくこちらもハードウェア要件が高いだろうということで、色々見てみる
GGUFは複数あるが、ComfyUIでの使用想定。
DFloat11版はこちらもあった。
DFloat11 圧縮モデル: Qwen/Qwen-Image-Edit
これは、元の Qwen/Qwen-Image-Edit モデルの DFloat11 形式で無損失圧縮されたバージョンです。元の BFloat16 モデルと比較してモデルサイズを 32% 削減しつつ、ビット同等の出力を維持し、効率的な GPU 推論をサポートしています。
🔥🔥🔥 DFloat11圧縮により、Qwen-Image-Editは単一の32GB GPUで実行可能となり、CPUオフロードを使用すれば単一の24GB GPUでも実行可能ながら、モデル品質を完全に維持できます。 🔥🔥🔥
📊 性能比較
モデル モデルサイズ ピークGPUメモリ 生成時間 (A100 GPU) Qwen-Image-Edit (BFloat16) ~41 GB OOM - Qwen-Image-Edit (DFloat11) 28.43 GB 30.11 GB 280秒 Qwen-Image-Edit (DFloat11 + CPUオフロード) 28.43 GB 22.71 GB 570秒
DFloat11 + CPUオフロードなら、RTX4090で動かせそう?こちらで試してみる。
環境はUbuntu-22.04+メモリ96GB+VRAM24GB(RTX4090)。
uvでプロジェクト作成
uv init -p 3.12 qwen-image-edit-work && cd $_
パッケージ追加
uv add dfloat11[cuda12]
+ dfloat11==0.3.2
uv add git+https://github.com/huggingface/diffusers
+ diffusers==0.36.0.dev0 (from git+https://github.com/huggingface/diffusers@4fcd0bc7ebb934a1559d0b516f09534ba22c8a0d)
あと、自分の環境だけかもしれないが、TorchVisionが足りなかった。
uv add torchvision
以下の内容で qwen_image_edit.py を作成する
import argparse
import torch
from diffusers.utils import load_image
from diffusers import QwenImageTransformer2DModel, QwenImageEditPipeline
from transformers.modeling_utils import no_init_weights
from dfloat11 import DFloat11Model
def parse_args():
parser = argparse.ArgumentParser(description='Edit images using Qwen-Image-Edit model')
parser.add_argument('--cpu_offload', action='store_true', help='Enable CPU offloading')
parser.add_argument('--cpu_offload_blocks', type=int, default=16, help='Number of transformer blocks to offload to CPU')
parser.add_argument('--no_pin_memory', action='store_true', help='Disable memory pinning')
parser.add_argument('--image', type=str, default="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png",
help='Path to input image or URL')
parser.add_argument('--prompt', type=str, default='Add a hat to the cat.',
help='Text prompt for image editing')
parser.add_argument('--negative_prompt', type=str, default=' ',
help='Negative prompt for image editing')
parser.add_argument('--num_inference_steps', type=int, default=50,
help='Number of denoising steps')
parser.add_argument('--true_cfg_scale', type=float, default=4.0,
help='Classifier free guidance scale')
parser.add_argument('--seed', type=int, default=42,
help='Random seed for generation')
parser.add_argument('--output', type=str, default='qwen_image_edit.png',
help='Output image path')
return parser.parse_args()
args = parse_args()
model_id = "Qwen/Qwen-Image-Edit"
with no_init_weights():
transformer = QwenImageTransformer2DModel.from_config(
QwenImageTransformer2DModel.load_config(
model_id, subfolder="transformer",
),
).to(torch.bfloat16)
DFloat11Model.from_pretrained(
"DFloat11/Qwen-Image-Edit-DF11",
device="cpu",
cpu_offload=args.cpu_offload,
cpu_offload_blocks=args.cpu_offload_blocks,
pin_memory=not args.no_pin_memory,
bfloat16_model=transformer,
)
pipeline = QwenImageEditPipeline.from_pretrained(
model_id, transformer=transformer, torch_dtype=torch.bfloat16,
)
pipeline.enable_model_cpu_offload()
pipeline.set_progress_bar_config(disable=None)
image = load_image(args.image)
inputs = {
"image": image,
"prompt": args.prompt,
"generator": torch.manual_seed(args.seed),
"true_cfg_scale": args.true_cfg_scale,
"negative_prompt": args.negative_prompt,
"num_inference_steps": args.num_inference_steps,
}
with torch.inference_mode():
output = pipeline(**inputs)
output_image = output.images[0]
output_image.save(args.output)
max_gpu_memory = torch.cuda.max_memory_allocated()
print(f"Max GPU memory allocated: {max_gpu_memory / 1000 ** 3:.2f} GB")
Usage
uv run qwen_image_edit.py --help
usage: qwen_image_edit.py [-h] [--cpu_offload] [--cpu_offload_blocks CPU_OFFLOAD_BLOCKS] [--no_pin_memory]
[--image IMAGE] [--prompt PROMPT] [--negative_prompt NEGATIVE_PROMPT]
[--num_inference_steps NUM_INFERENCE_STEPS] [--true_cfg_scale TRUE_CFG_SCALE] [--seed SEED]
[--output OUTPUT]
Edit images using Qwen-Image-Edit model
options:
-h, --help show this help message and exit
--cpu_offload Enable CPU offloading
--cpu_offload_blocks CPU_OFFLOAD_BLOCKS
Number of transformer blocks to offload to CPU
--no_pin_memory Disable memory pinning
--image IMAGE Path to input image or URL
--prompt PROMPT Text prompt for image editing
--negative_prompt NEGATIVE_PROMPT
Negative prompt for image editing
--num_inference_steps NUM_INFERENCE_STEPS
Number of denoising steps
--true_cfg_scale TRUE_CFG_SCALE
Classifier free guidance scale
--seed SEED Random seed for generation
--output OUTPUT Output image path
入力画像は前回Qwen-Imageで生成した以下の画像を使用する。

この画像の馬場をダートから芝に変えてみる。CPUオフロードの場合は --cpu_offload を指定して実行。初回はモデルもダウンロードされるのでしばし待つ。
uv run qwen_image_edit.py \
--cpu_offload \
--image horserace.png \
--prompt "Change the track surface from dirt to turf."
のだが、残念・・・
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 18.00 MiB. GPU 0 has a total capacity of 23.49 GiB of which 8.88 MiB is free. Including non-PyTorch memory, this process has 23.25 GiB memory in use. Of the allocated memory 22.57 GiB is allocated by PyTorch, and 230.19 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
この場合、オフロードするブロック数を増やせばいいらしいのだが、色々パラメータを替えたりしても、Cuda out of memory を回避できない・・・・
uv run qwen_image_edit.py \
--cpu_offload \
--cpu_offload_blocks 120 \
--image horserace.png \
--no_pin_memory \
--prompt "Change the track surface from dirt to turf."
諦めてComfyUIにしたほうが良さそう・・・
うみゆきさんの記事を参考にComfyUIでやるのが良さそう。
改めてdiffusersを試しているけど、bitsandbytes を使って量子化しているノートブックを見つけた。torchaoを使った量子化も同じレポジトリにある。