Qwenの画像生成モデル「Qwen−Image」を試す
モデル
GitHubレポジトリ
o3による翻訳
referred from https://github.com/QwenLM/Qwen-Image
referred from https://github.com/QwenLM/Qwen-Imageイントロダクション
Qwen-Image をリリースできることを大変うれしく思います。これは 複雑なテキスト描画 と 高精度な画像編集 で大きな進歩を達成した、20B(200億パラメータ)の MMDiT 画像基盤モデルです。実験により、画像生成と編集の双方で強力な汎用能力を示し、特にテキスト描画(とりわけ中国語)において卓越した性能を確認しました。
referred from https://github.com/QwenLM/Qwen-Imageニュース
- 2025.08.05: Qwen-Image が ComfyUI でネイティブにサポートされました。詳しくは Qwen-Image in ComfyUI: New Era of Text Generation in Images! をご覧ください。
- 2025.08.05: Qwen-Image が Qwen Chat で利用可能になりました。Qwen Chat を開き、「Image Generation」を選択してください。
- 2025.08.05: テクニカルレポート を Arxiv に公開しました!
- 2025.08.04: Qwen-Image の重みを公開しました!Huggingface および Modelscope をご確認ください。
- 2025.08.04: Qwen-Image をリリースしました!詳細は ブログ をご覧ください。
[!NOTE]
編集機能版の Qwen-Image はまもなく公開予定です。続報をお待ちください。高いトラフィックのため、オンラインデモを体験される方には DashScope、WaveSpeed、LibLib の利用も推奨します。リンクは下記の「コミュニティサポート」をご参照ください。



ショーケース
本モデルの注目すべき能力の一つは、多様な画像における高忠実度のテキスト描画です。英語のようなアルファベット言語でも、中国語のような表意文字でも、Qwen-Image は書体の細部、レイアウトの一貫性、文脈との調和を驚くほど正確に保ちます。テキストは単に上書きされるのではなく、視覚的な構成の中にシームレスに統合されます。
referred from https://github.com/QwenLM/Qwen-Imageテキストを超えて、Qwen-Image は幅広い画風をサポートする汎用的な画像生成にも秀でています。フォトリアリスティックな情景から印象派風の絵画、アニメ風の美学からミニマルデザインまで、モデルは多様なクリエイティブプロンプトに柔軟に適応し、アーティスト、デザイナー、ストーリーテラーにとって多用途なツールとなります。
referred from https://github.com/QwenLM/Qwen-Image画像編集に関しても、Qwen-Image は単純な調整をはるかに超えた機能を提供します。スタイル転送、物体の挿入・除去、ディテール強調、画像内テキストの編集、さらには人物ポーズの操作といった高度な処理を、直感的な入力と整合的な出力で実現します。この制御性の高さにより、プロフェッショナル級の編集を一般ユーザーでも扱えるようになります。
referred from https://github.com/QwenLM/Qwen-Image
さらに Qwen-Image は、生成や編集だけでなく「理解」も行います。物体検出、セマンティックセグメンテーション、深度・エッジ(Canny)推定、新規視点合成、超解像などの画像理解タスク群をサポートします。これらは技術的には別個の能力ですが、深い視覚理解に支えられた知的な画像編集の特化形として捉えることができます。
referred from https://github.com/QwenLM/Qwen-Imageこれらの機能が結びつくことで、Qwen-Image は単なる「美しい画像を作る」ためのツールにとどまらず、言語・レイアウト・イメージが交わる領域で、知的な視覚創作と操作のための包括的な基盤モデルとなります。




ライセンス契約
Qwen-Image は Apache 2.0 でライセンスされています。
公式のブログや論文も。
で、動かそうと思うと、そこそこの環境が必要になる様子で、ローカルで動かす場合にはComfyUIでGGUF版を動かすのが情報としては多いのだが、ComfyUI前に触ってから時間がたっているのでひとまずは違うやり方で使ってみたい。
でこういうのもあるらしい
DFloat11 圧縮モデル: Qwen/Qwen-Image
これは、元の Qwen/Qwen-Image モデルの DFloat11 形式で無損失圧縮されたバージョンです。元の BFloat16 モデルと比較してモデルサイズを 32% 削減しつつ、ビット同等の出力を維持し、効率的な GPU 推論をサポートしています。
🔥🔥🔥 DFloat11圧縮により、Qwen-Imageは単一の32GB GPUで実行可能となり、CPUオフロードを使用すれば単一の16GB GPUでも実行可能になりました。これらは、モデル品質を完全に維持したまま実現されています。 🔥🔥🔥
パフォーマンス比較
モデル モデルサイズ ピークGPUメモリ
(1328x1328画像生成時)生成時間
(A100 GPU)Qwen-Image (BFloat16) 約41 GB OOM - Qwen-Image (DFloat11) 28.42 GB 29.74 GB 100秒 Qwen-Image (DFloat11 + GPUオフロード) 28.42 GB 16.68 GB 260秒
見た感じCLIで使えそうなので、これを試してみようと思う。
環境はUbuntu-22.04+メモリ96GB+VRAM24GB(RTX4090)。
uvでプロジェクト作成
uv init -p 3.12 qwen-image-work && cd $_
パッケージ追加
uv add dfloat11[cuda12]
+ dfloat11==0.3.1
uv add git+https://github.com/huggingface/diffusers
+ diffusers==0.35.0.dev0 (from git+https://github.com/huggingface/diffusers@ba2ba9019f76fd96c532240ed07d3f98343e4041)
以下の内容で qwen_image.py を作成する
from diffusers import DiffusionPipeline, QwenImageTransformer2DModel
import torch
from transformers.modeling_utils import no_init_weights
from dfloat11 import DFloat11Model
import argparse
def parse_args():
parser = argparse.ArgumentParser(description='Generate images using Qwen-Image model')
parser.add_argument('--cpu_offload', action='store_true', help='Enable CPU offloading')
parser.add_argument('--no_pin_memory', action='store_true', help='Disable memory pinning')
parser.add_argument('--prompt', type=str, default='A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197".',
help='Text prompt for image generation')
parser.add_argument('--negative_prompt', type=str, default=' ',
help='Negative prompt for image generation')
parser.add_argument('--aspect_ratio', type=str, default='16:9', choices=['1:1', '16:9', '9:16', '4:3', '3:4'],
help='Aspect ratio of generated image')
parser.add_argument('--num_inference_steps', type=int, default=50,
help='Number of denoising steps')
parser.add_argument('--true_cfg_scale', type=float, default=4.0,
help='Classifier free guidance scale')
parser.add_argument('--seed', type=int, default=42,
help='Random seed for generation')
parser.add_argument('--output', type=str, default='example.png',
help='Output image path')
parser.add_argument('--language', type=str, default='en', choices=['en', 'zh'],
help='Language for positive magic prompt')
return parser.parse_args()
args = parse_args()
model_name = "Qwen/Qwen-Image"
with no_init_weights():
transformer = QwenImageTransformer2DModel.from_config(
QwenImageTransformer2DModel.load_config(
model_name, subfolder="transformer",
),
).to(torch.bfloat16)
DFloat11Model.from_pretrained(
"DFloat11/Qwen-Image-DF11",
device="cpu",
cpu_offload=args.cpu_offload,
pin_memory=not args.no_pin_memory,
bfloat16_model=transformer,
)
pipe = DiffusionPipeline.from_pretrained(
model_name,
transformer=transformer,
torch_dtype=torch.bfloat16,
)
pipe.enable_model_cpu_offload()
positive_magic = {
"en": "Ultra HD, 4K, cinematic composition.", # for english prompt,
"zh": "超清,4K,电影级构图" # for chinese prompt,
}
# Generate with different aspect ratios
aspect_ratios = {
"1:1": (1328, 1328),
"16:9": (1664, 928),
"9:16": (928, 1664),
"4:3": (1472, 1140),
"3:4": (1140, 1472),
}
width, height = aspect_ratios[args.aspect_ratio]
image = pipe(
prompt=args.prompt + positive_magic[args.language],
negative_prompt=args.negative_prompt,
width=width,
height=height,
num_inference_steps=args.num_inference_steps,
true_cfg_scale=args.true_cfg_scale,
generator=torch.Generator(device="cuda").manual_seed(args.seed)
).images[0]
image.save(args.output)
max_memory = torch.cuda.max_memory_allocated()
print(f"Max memory: {max_memory / (1000 ** 3):.2f} GB")
Usage
uv run qwen_image.py --help
usage: qwen_image.py [-h] [--cpu_offload] [--no_pin_memory] [--prompt PROMPT] [--negative_prompt NEGATIVE_PROMPT]
[--aspect_ratio {1:1,16:9,9:16,4:3,3:4}] [--num_inference_steps NUM_INFERENCE_STEPS]
[--true_cfg_scale TRUE_CFG_SCALE] [--seed SEED] [--output OUTPUT] [--language {en,zh}]
Generate images using Qwen-Image model
options:
-h, --help show this help message and exit
--cpu_offload Enable CPU offloading
--no_pin_memory Disable memory pinning
--prompt PROMPT Text prompt for image generation
--negative_prompt NEGATIVE_PROMPT
Negative prompt for image generation
--aspect_ratio {1:1,16:9,9:16,4:3,3:4}
Aspect ratio of generated image
--num_inference_steps NUM_INFERENCE_STEPS
Number of denoising steps
--true_cfg_scale TRUE_CFG_SCALE
Classifier free guidance scale
--seed SEED Random seed for generation
--output OUTPUT Output image path
--language {en,zh} Language for positive magic prompt
CPUオフロードの場合は --cpu_offload を指定して実行。初回はモデルもダウンロードされるが、かなり時間がかかるので注意(30GBぐらいある)。
uv run qwen_image.py \
--cpu_offload \
--prompt "Two racehorses are neck and neck as they approach the finish line, with each jockey urging their mount on with everything they've got."

何度か試してみたけど、モデルのダウンロードを除いて、スクリプト実行→モデルロード→生成まで、トータルで約30分ぐらいかなあ・・・
ずっと張り付いてみてたわけではないけど、ざっくりだと
- RAM: 60GB
- VRAM: 17GB
ぐらいが使用量の最大って感じだった。
一応日本語のプロンプトでも認識はしてくれるみたい。
uv run qwen_image.py \
--cpu_offload \
--prompt "2頭の競走馬がゴール前で競っている。それぞれの騎手は懸命に馬を追っている。"

他のモデルとの比較はうみゆきさんが紹介されていたサイトが興味深かった。
複数のモデルで、同じプロンプトを渡して指示内容を満たせた生成ができたか、それを異なるプロンプトで複数回実施してどれだけ達成できたか?というもの。トップはさすがの4oで次点がImagen4なんだけど、Qwen−Imageはその次となっている。
まあ日本語文字の生成はやはり厳しそう。
やはりComfyUIでやるのが良さそう。
別途ComfyUIでも試してみよう。
参考
ComfyUIで試してみる。たまにしか使わないので手順を毎回調べてる気がするな。GGUF使えるのとかも全然知らなかった。
とりあえず、このためにCUDA-12.8に上げた・・・(そして若干ハマった・・・)。
以下手順。余談だが、ComfyUIのドキュメントは以下のWikiサイトが参考になった。(非公式みたいだが)
uv init -p 3.12 --bare comfyui && cd comfyui
cat <<EOF >> pyproject.toml
[tool.uv.sources]
torch = { index = "pytorch-cu128" }
torchvision = { index = "pytorch-cu128" }
torchaudio = { index = "pytorch-cu128" }
[[tool.uv.index]]
name = "pytorch-cu128"
url = "https://download.pytorch.org/whl/cu128"
explicit = true
EOF
uv add torch torchvision torchaudio
uv add comfy-cli pip
uv run comfy --here install
uv run comfy launch -- --listen 0.0.0.0
ブラウザで8188番ポートにアクセスしてみると、ComfyUI-Managerも見えている。なお、LAN内でのホスト名では何やらエラーになって、IPアドレスを指定しないとアクセスできなかった。
ComfyUIで試せるQwen-Imageは以下の3つかな?
- bf16 / fp8
- GGUF
前者はComfy公式のブログ記事に載っている。
まずはこちらから。
「ワークフロー」→「テンプレートを参照」
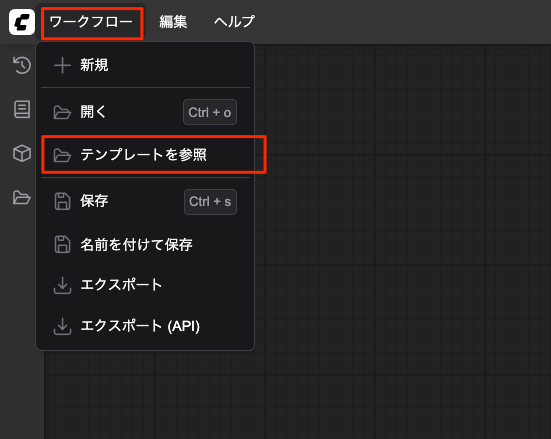
起動直後にも表示されていたが、テンプレートの一覧が表示される。「画像」を選択すると「Qwen-Image Text to Image」が表示されていた。これを選択。

フローが読み出される。フロー内で使用しているモデル等が見つからない場合はこういう表示が出るのね。

便利ー!と思って「ダウンロード」をクリックしてみると、単にブラウザでダウンロードされるだけで、Comfy内でよしなにダウンロード・配置してくれるわけではない様子・・・あと「URLをコピー」が(自分の環境のせいかもしれないが)全く効かなかった・・・
ということでそれぞれをブラウザでダウンロードして、それぞれを以下のパスに配置する。なおこのテンプレートではfp8版が使用されている様子。
comfyui
├── ComfyUI
(snip)
│ ├── models
│ │ ├── checkpoints
│ │ ├── clip
│ │ ├── clip_vision
│ │ ├── configs
│ │ ├── controlnet
│ │ ├── diffusers
│ │ ├── diffusion_models
│ │ │ └── qwen_image_fp8_e4m3fn.safetensors # ここ
│ │ ├── embeddings
│ │ ├── gligen
│ │ ├── hypernetworks
│ │ ├── loras
│ │ ├── photomaker
│ │ ├── style_models
│ │ ├── text_encoders
│ │ │ └── qwen_2.5_vl_7b_fp8_scaled.safetensors # ここ
│ │ ├── unet
│ │ ├── upscale_models
│ │ ├── vae
│ │ │ └── qwen_image_vae.safetensors # ここ
│ │ └── vae_approx
(snip)
配置したらフローを実行する。

しばし待つと、以下のように一番右側に画像が生成される。
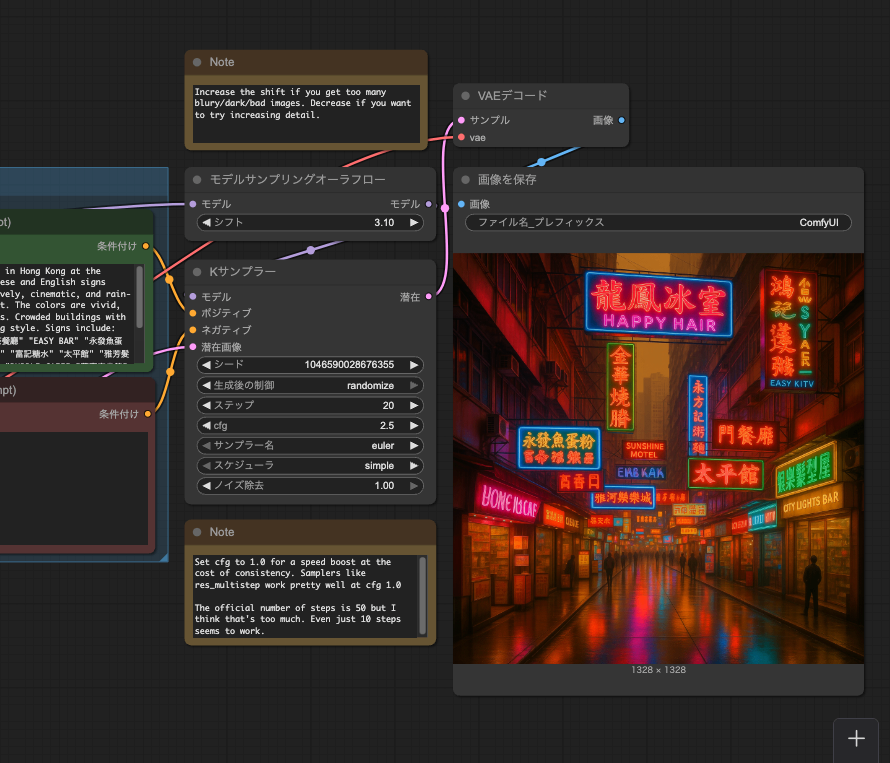
デフォルトのプロンプトはここで設定されている。
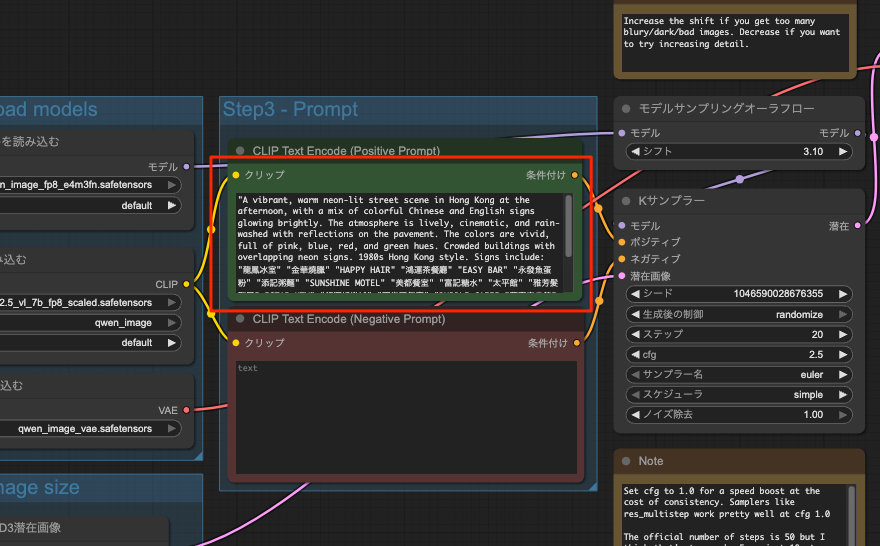
こんな内容
"A vibrant, warm neon-lit street scene in Hong Kong at the afternoon, with a mix of colorful Chinese and English signs glowing brightly. The atmosphere is lively, cinematic, and rain-washed with reflections on the pavement. The colors are vivid, full of pink, blue, red, and green hues. Crowded buildings with overlapping neon signs. 1980s Hong Kong style. Signs include:
"龍鳳冰室" "金華燒臘" "HAPPY HAIR" "鴻運茶餐廳" "EASY BAR" "永發魚蛋粉" "添記粥麵" "SUNSHINE MOTEL" "美都餐室" "富記糖水" "太平館" "雅芳髮型屋" "STAR KTV" "銀河娛樂城" "百樂門舞廳" "BUBBLE CAFE" "萬豪麻雀館" "CITY LIGHTS BAR" "瑞祥香燭莊" "文記文具" "GOLDEN JADE HOTEL" "LOVELY BEAUTY" "合興百貨" "興旺電器" And the background is warm yellow street and with all stores' lights on.
(日本語訳)
香港の午後、ネオンの光が輝く活気ある温かい街並み。色鮮やかな中国語と英語の看板が明るく輝き、混ざり合っています。雰囲気は活気があり、映画のような雰囲気で、雨に洗われた路面には反射が映っています。色は鮮やかで、ピンク、ブルー、レッド、グリーンが豊富です。重なり合うネオン看板の密集した建物。1980年代の香港スタイル。看板には以下のものが含まれます: 「龍鳳冰室」 「金華燒臘」 「HAPPY HAIR」 「鴻運茶餐廳」 「EASY BAR」 「永發魚蛋粉」 「添記粥麵」 「SUNSHINE MOTEL」 「美都餐室」 「富記糖水」 「太平館」 「雅芳髮型屋」 「STAR KTV」「銀河娛樂城」「百樂門舞廳」「BUBBLE CAFE」「万豪麻雀館」「CITY LIGHTS BAR」「瑞祥香燭荘」「文記文具」「GOLDEN JADE HOTEL」「LOVELY BEAUTY」「合興百貨」「興旺電気」 。背景は温かい黄色の街並みで、すべての店の明かりが点灯しています。
画像は右クリックでダウンロードできるとともに、ファイルとして以下に保存されていた。
comfyui
├── ComfyUI
(snip)
│ ├── output
│ │ └── ComfyUI_00001_.png
(snip)
CLIで試したときと同じプロンプトでも。
2頭の競走馬がゴール前で競っている。それぞれの騎手は懸命に馬を追っている。
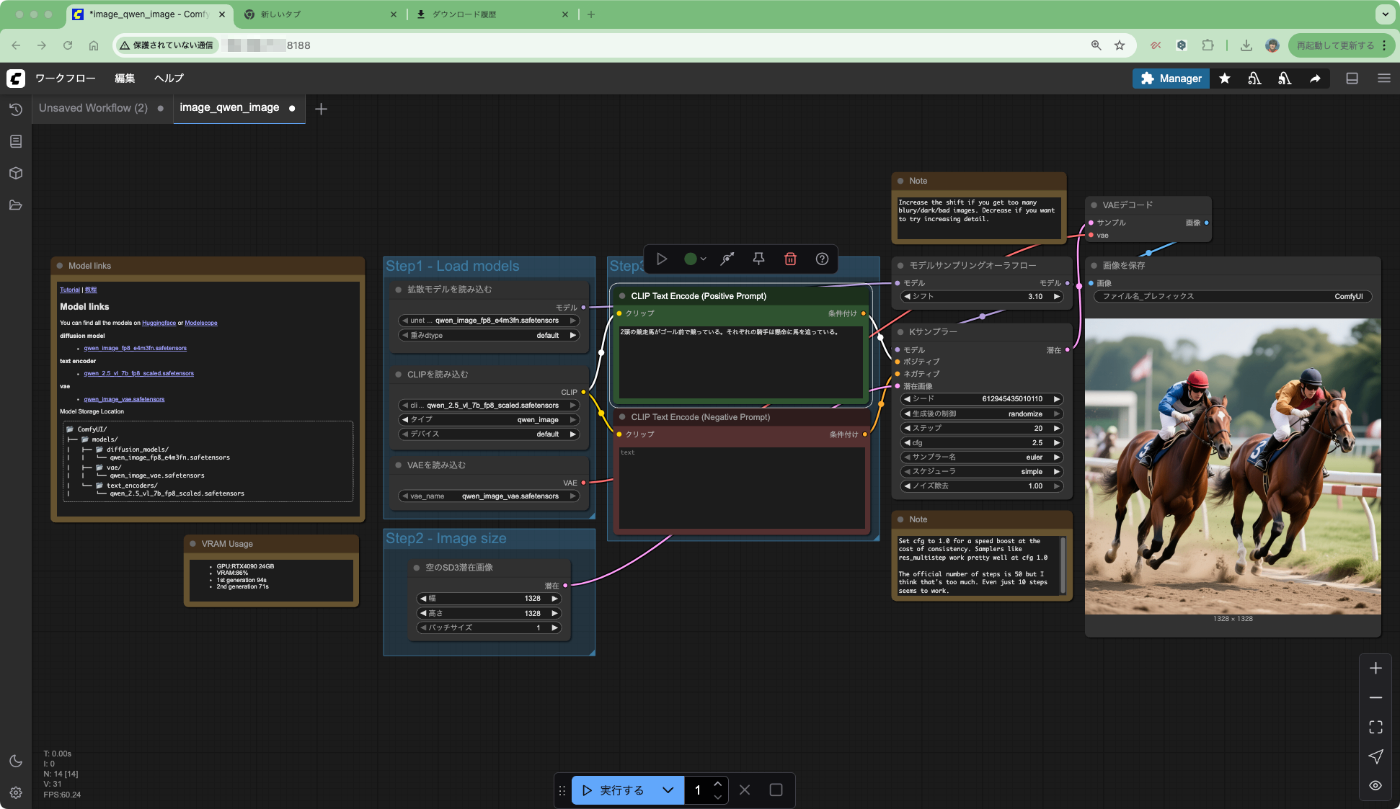

実行時間がこのテンプレートのデフォルト設定だと、初回はモデルロードも含めて2分程度、2回目以降は50秒程度だった。
VRAM消費
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.172.08 Driver Version: 570.172.08 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:01:00.0 Off | Off |
| 57% 76C P2 430W / 450W | 21172MiB / 24564MiB | 100% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
GGUFは別途試す。
画像編集も出た
参考
diffusersを使ってbitsandbytes を使って量子化しているノートブックを見つけた。torchaoを使った量子化も同じレポジトリにある。