軽量・高速なオンデバイス向けVLM「LFM2-VL」を試す
LFM2-VLの紹介 — スマートフォンやラップトップからウェアラブルデバイス、組み込みシステムまで、現実世界での展開に向けた新しい世代の効率的なビジョン言語モデル。 🧵
LFM2アーキテクチャに基づいて構築されたLFM2-VLは、テキストと画像を以下のように処理します:
- 既存のVLMと比較してGPU上での推論が最大2倍高速
- 低遅延、エッジ最適化されたパフォーマンス
- 微調整とカスタマイズのためのオープンウェイトの柔軟性
モバイルAIツール、オフラインのビジョン言語アプリ、または制約された環境におけるマルチモーダルエージェント——LFM2-VLは一切の妥協なく提供します。
ブログ: https://liquid.ai/blog/lfm2-vl-efficient-vision-language-models
モデル: https://huggingface.co/LiquidAI/LFM2-VL-1.6B
以前に試した、オンデバイス向けのモデル「LFM2」をベースにVLM化したモデルが出たみたい。
テキストモデルについては、350M / 700M / 1.2B の3種類あったけど、以前試した際に、
- 日本語はまあ普通に使える
- ただし日本に関する知識はない
- このクラスだと指示追従性は果たして?
という印象を持っているのだけど、VLMになってどうだろうか?試してみる。
モデル。バリエーションは450Mと1.2Bの2つ。あと、MLXフォーマットも用意されている。
モデルカード(450Mのもの、多分1.2Bも書いてあることは同じ)をざっと。
LFM2-VL
LFM2-VLは、Liquid AIによる初のマルチモーダルモデルシリーズであり、可変解像度のテキストと画像を処理するように設計されています。LFM2バックボーン上に構築され、低レイテンシおよびエッジAIアプリケーション向けに最適化されています。
我々は、450M(リソース制約の厳しいデバイス向け)と1.6B(より高性能でありながら軽量)パラメータを持つ、2つのポストトレーニング済みチェックポイントの重みを公開します。
- 既存のVLMと比較してGPU上で推論速度が2倍でありながら競争力のある精度を維持
- 柔軟なアーキテクチャ:推論時に速度と品質のトレードオフをユーザーが調整可能
- ネイティブ解像度処理:512×512までを処理し、大きな画像に対してはインテリジェントなパッチ処理を用いてアップスケーリングや歪みを回避
我々のビジョン言語モデルについてはLFM2-VL記事を、その言語バックボーンについてはLFM2記事をご覧ください。
📄 モデル詳細
小規模なサイズのため、LFM2-VLモデルは限定的なユースケースに対してファインチューニングすることを推奨します。これらは指示追従と軽量なエージェントフローに対して学習されており、安全性が重要となる意思決定には使用を想定していません。
プロパティ LFM2-VL-450M LFM2-VL-1.6B パラメータ(LMのみ) 350M 1.2B ビジョンエンコーダ SigLIP2 NaFlex base (86M) SigLIP2 NaFlex shape-optimized (400M) バックボーン層 conv+attentionハイブリッド conv+attentionハイブリッド コンテキスト(テキスト) 32,768トークン 32,768トークン 画像トークン 動的、ユーザー調整可能 動的、ユーザー調整可能 語彙サイズ 65,536 65,536 精度 bfloat16 bfloat16 ライセンス LFM Open License v1.0 LFM Open License v1.0 対応言語: 英語
生成パラメータ: 推奨設定は以下の通りです:
- テキスト:
temperature=0.1,min_p=0.15,repetition_penalty=1.05- ビジョン:
min_image_tokens=64max_image_tokens=256,do_image_splitting=Trueチャットテンプレート: LFM2-VLは以下のようなChatMLライクなテンプレートを使用します:
<|startoftext|><|im_start|>system You are a helpful multimodal assistant by Liquid AI.<|im_end|> <|im_start|>user <image>Describe this image.<|im_end|> <|im_start|>assistant This image shows a Caenorhabditis elegans (C. elegans) nematode.<|im_end|>画像はセンチネル(
<image>)で参照され、プロセッサにより自動的に画像トークンに置き換えられます。
Hugging Face transformersの.apply_chat_template()関数を用いて適用できます。アーキテクチャ
- ハイブリッドバックボーン: 言語モデルタワー(LFM2-1.2BまたはLFM2-350M)とSigLIP2 NaFlexビジョンエンコーダ(400M形状最適化版または86Mベース版)の組み合わせ
- ネイティブ解像度処理: 最大512×512ピクセルの画像をアップスケーリングせずに処理し、非標準のアスペクト比も歪みなく保持
- タイル分割戦略: 大きな画像を512×512の非重複パッチに分割し、1.6Bモデルでは全体文脈のためにサムネイルエンコーディングを含む
- 効率的なトークンマッピング: pixel unshuffleを用いた2層MLPコネクタにより画像トークンを削減(例: 256×384画像→96トークン、1000×3000画像→1,020トークン)
- 推論時の柔軟性: ユーザーが最大画像トークン数やパッチ数を調整可能で、再学習不要で速度と品質のトレードオフを実現
学習アプローチ
- LFM2ベースモデル上に構築し、テキスト対画像比を徐々に調整するジョイント中間学習で視覚と言語能力を融合
- 画像理解および視覚タスクに重点を置いたジョイントSFTを適用
- 大規模なオープンソースデータセットと社内生成の合成視覚データを組み合わせ、タスクカバレッジのバランスを考慮
- 段階的学習戦略を採用: ベースモデル → ジョイント中間学習 → 教師ありファインチューニング
🏃 LFM2-VLの実行方法
このColabノートブックで直接実行・テスト可能です。
🔧 ファインチューニング方法
最大性能を得るため、LFM2-VLモデルをユースケースに応じてファインチューニングすることを推奨します。
ノートブック 説明 リンク SFT (TRL) LoRAアダプタを用いた教師ありファインチューニング(SFT)ノートブック Colabで開く 📈 パフォーマンス
モデル RealWorldQA MM-IFEval InfoVQA (Val) OCRBench BLINK MMStar MMMU (Val) MathVista SEEDBench_IMG MMVet MME MMLU InternVL3-2B 65.10 38.49 66.10 831 53.10 61.10 48.70 57.60 75.00 67.00 2186.40 64.80 InternVL3-1B 57.00 31.14 54.94 798 43.00 52.30 43.20 46.90 71.20 58.70 1912.40 49.80 SmolVLM2-2.2B 57.50 19.42 37.75 725 42.30 46.00 41.60 51.50 71.30 34.90 1792.50 - LFM2-VL-1.6B 65.23 37.66 58.68 742 44.40 49.53 38.44 51.10 71.97 48.07 1753.04 50.99
モデル RealWorldQA MM-IFEval InfoVQA (Val) OCRBench BLINK MMStar MMMU (Val) MathVista SEEDBench_IMG MMVet MME MMLU SmolVLM2-500M 49.90 11.27 24.64 609 40.70 38.20 34.10 37.50 62.20 29.90 1448.30 - LFM2-VL-450M 52.29 26.18 46.51 655 41.98 40.87 33.11 44.70 63.50 33.76 1239.06 40.16 InternVL 3およびSmolVLM2モデルについては、VLMEvalKitを用いてMM-IFEvalおよびInfoVQA (Val)スコアを取得しました。
ざっと見た感じ、1.6B のほうは InternVL3-2B が強そうだけど、パラメータサイズが多少少なめの割には近しいところまで迫ってるという感じで、450M はSmolVLM2よりもかなり良い、という風に読める。
ライセンスは独自
テキストモデルと同じだと思うけど、以前確認した際は以下のような感じだった。
商用利用に制限(年間売上1,000万ドル以上。研究・非営利は除く。)がある、元の著作権表示は保持、改変時は改変箇所を記載、ぐらいで、独自ライセンスだけど結構緩めな印象。なお、使用時は原文の確認を推奨。
Colaboratoryノートブックが用意されているので、それを使ってみる。ランタイムはT4で。
そのまま上から実行していくだけだが、一応見ていく。
パッケージをアップデート
!pip install -qqqU transformers pillow --progress-bar off
モデルとプロセッサをロード。使用しているのは1.6Bの方。モデルカードと違って、このnotebookではストリーミングも設定してある。
from transformers import AutoProcessor, AutoModelForImageTextToText, TextStreamer
from transformers.image_utils import load_image
# モデルとプロセッサをロード
model_id = "LiquidAI/LFM2-VL-1.6B"
model = AutoModelForImageTextToText.from_pretrained(
model_id,
device_map="auto",
torch_dtype="bfloat16",
trust_remote_code=True
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
streamer = TextStreamer(processor, skip_prompt=True, skip_special_tokens=False)
VRAM消費は3GBぐらい。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 44C P0 26W / 70W | 3126MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
では推論。
サンプルで使用されている画像は中華街のもの。Phi-4-multimodalで使用されていたものと同じだね。
from IPython.display import display, Image as IPImage
# 画像をロード
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
image = load_image(url)
display(IPImage(url=url))
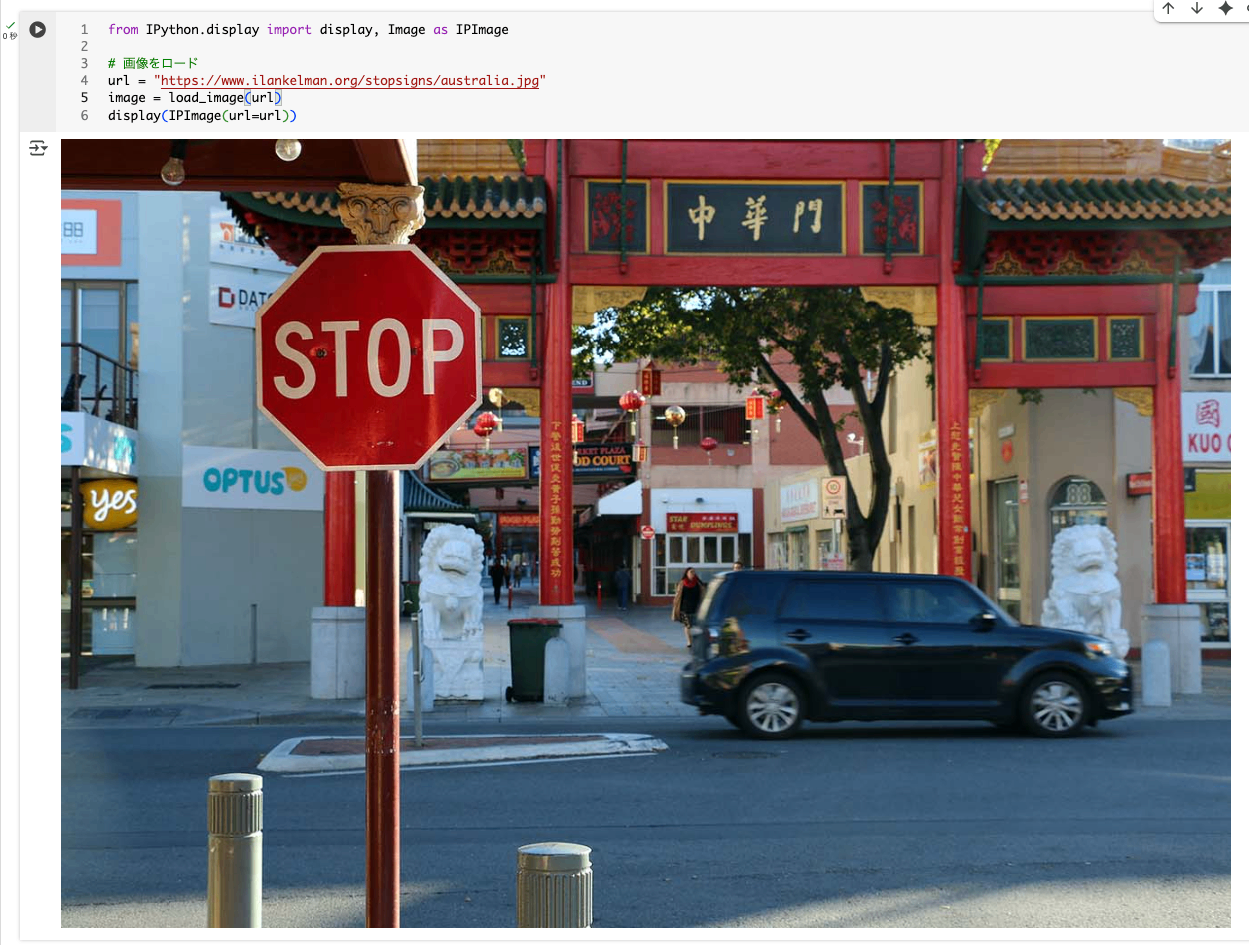
まずはサンプル通り英語で推論してみる。
# 会話を構築
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "What is in this image?"},
],
},
]
# 回答を生成
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
tokenize=True,
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=256, streamer=streamer)
結果。実際にはストリーミングで出力されるので高速。
This image shows a bustling street scene in what appears to be a Chinatown area. The focal point is a red stop sign with white lettering, positioned on a metal pole. Behind the stop sign, there's a large red archway with Chinese characters, likely marking the entrance to a Chinatown district.
The street is lined with various shops and businesses, including a store called "Optus" and another with a sign that says "KUO". There are also other businesses visible, though their names aren't clearly identifiable.
A black SUV is driving down the street, and there are a few pedestrians visible in the background. The scene is set during the day, with sunlight illuminating the area.
The architecture and signage strongly suggest this is a Chinatown district in a city, possibly in Australia given the "Optus" sign, which is an Australian telecommunications company. The combination of Chinese characters, the style of the buildings, and the presence of Chinese cultural elements like the archway and lion statues all point to this being a Chinatown area.<|im_end|>
日本語訳(DeepL)
この画像は、チャイナタウンのエリアと思われる賑やかな街並みの風景を示しています。焦点となっているのは、金属のポールに設置された赤い停止標識で、白い文字が書かれています。停止標識の背後には、中国文字が書かれた大きな赤いアーチがあり、おそらくチャイナタウン地区の入り口をマークしています。
通りには様々な店舗や事業者が並んでおり、その中には「Optus」という名の店舗や「KUO」と書かれた看板の店舗があります。他の店舗も確認できますが、その名前は明確に識別できません。
黒いSUVが通りを走っており、背景には数人の歩行者が見えます。シーンは昼間で、日光がエリアを照らしています。
建築物や看板のスタイルから、これは都市のチャイナタウン地区であることが強く示唆されています。特に「Optus」の看板はオーストラリアの通信会社であることから、オーストラリアの都市である可能性が高いです。中国文字、建物のデザイン、アーチや獅子像などの中国文化の要素が、この地域がチャイナタウンであることを明確に示しています。
推論後は少しVRAM消費が増えている
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 54C P0 27W / 70W | 4532MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
では日本語で試してみる。少し出力トークンを増やしてある。
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "この画像には何が写っている?"},
],
},
]
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
tokenize=True,
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, streamer=streamer)
この画像には、多様な要素が写っています。中央には、赤いポストに Stop という文字が書かれた標識があります。道路の両側には、赤いポストと白い石像が配置されています。
道路には、黒い車が通過しています。周囲には、建物、商店、道路の標識が広く見られます。
商店には、 Optus、Kuo、YESなどのブランドが表示されています。
このシーンは、都市の環境を示しており、商業施設、交通、建築物が混在しています。
この画像は、多文化都市の雰囲気を捉えており、商業施設と道路が混在する都市環境を示しています。<|im_end|>
テキストモデルもそうだったけど、日本語は普通に使えそう。
手持ちの画像で試してみる。プロンプトは全て この画像について日本語で説明して。。
神戸の風景

この画像は、海岸の景観を捉えたものです。前面には波が穏やかに揺れ、海水は深い青色を帯びています。海岸には、白い建物や塔が立ち並び、近代的な都市の景観が広がっています。特に、赤い塔は海岸にそびえ立ち、印象的な存在感を放っています。
海岸には、ボートやフェリーが運ばれている場所が確認でき、港の様子が伺えます。背景には、緑豊かな山が広がり、自然と都市が調和して存在する様子が描かれています。
全体として、美しい海岸の景観と近代的な都市の景観が調和して描かれており、自然と都市の融合を示しています。
書籍の画像

この画像には、ドキュメントコミュニケーションの概念を説明した本が写されています。
本の表紙には、主に日本語で書かれています。
表紙の最下部には、緑色の部分に日本語で書かれた文字があります。
本のタイトルは「ドキュメントコミュニケーションの概念の全論理」です。
本の表紙には、図やグラフが描かれています。
この本は、ドキュメントコミュニケーションの概念を説明した本です。<|im_end|>
架空の請求書の画像

この画像は、 inventories に関する書類です。書類には、会社名、会社番号、電話番号、ファックス番号が記載されています。また、書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計金額が記載されています。書類には、商品名、数量、単価、合計
最後はちょっと繰り返しになって応答が壊れてしまった。
推奨パラメータに合わせてみる。
生成パラメータ: 推奨設定は以下の通りです:
- テキスト:
temperature=0.1,min_p=0.15,repetition_penalty=1.05- ビジョン:
min_image_tokens=64max_image_tokens=256,do_image_splitting=True
まずはサンプルの中華街の画像で。
image = load_image("https://www.ilankelman.org/stopsigns/australia.jpg")
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "この画像について日本語で説明して。"},
],
},
]
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
tokenize=True,
# 推奨パラメータを追加
min_image_tokens=64,
max_image_tokens=256,
do_image_splitting=True
).to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=2048,
streamer=streamer,
# 推奨パラメータを追加
do_sample=True,
temperature=0.1,
min_p=0.15,
repetition_penalty=1.05
)
この画像は、ロンドンの Chinatown にある中国風のゲートを示しています。赤いゲートには中国語の文字が書かれており、伝統的な中国建築様式を彷彿とさせるデザインが特徴です。
ゲートの下には、黒い車が通過しています。ゲートの両側には白い獅子像が置かれており、中国文化の象徴です。
ゲートの下には商店が並んでおり、 Optus や Kuo などのブランドが表示されています。商店は中国風の装飾が施されたものも多く、-Chinese 風の雰囲気を演出しています。
このゲートは、ロンドンの Chinatown 地区の重要なランドマークであり、中国文化の存在を示すものです。中国人コミュニティの歴史や文化を反映した建築物や商店が集まる場所として、地域の多文化性を示しています。
先ほど回答が繰り返しになってしまった請求書画像で再度実施した結果が以下。
この画像は、 japanese の書類です。この書類には、会社名、住所、電話番号、ファックス番号が記載されています。また、書類の種類や内容に関する情報も含まれています。書類には、A4サイズの印刷物、20本の印刷物、50本の印刷物の価格が記載されています。書類には、10%の税金が加算され、合計で154,000円となります。書類には、会社名と住所が記載されており、会社名は"Kyokushin Kogyo Co., Ltd."です。
ちょっと試してみた感じ、この推奨パラメータを設定しておかないと結構繰り返し出力が起きやすい感はある。
まとめ
LFM2で日本語は一応使えたので、それがベースになっているLFM2-VLでも日本語はまあ使えそう。
ただし、軽量なので、知識は少なく、指示追従性もそれほど高くないと予想される。モデルカードにも書いてあるが、使用するユースケースの選定と、それに応じたファインチューニングは前提となると思われる。ただそのあたりも含めてファインチューニング用のノートブックが用意されているのは好印象。
なお、450Mもざっと試してみた感じ、日本語は普通に使えそうなので、(性能のトレードオフは当然あるとしても)より軽量に使いたいならそちらを試してみると良い。
llama.cppに対応したみたい