改めて「BAAI/bge-m3」でDense・Sparse・Multi Vectorを試す
以前に一度試していたが、当時はDense Embeddingしか考えていなかった。
モデルカードにもある通り、BAAI/bge-m3は、Dense / Sparse / マルチベクトル(ColBERT)にも対応しているので、これだけでハイブリッドができてしまうのではないか?ということで、試してみる。
BGE-M3 (論文、コード)
本プロジェクトでは、多機能性、多言語性、多粒度性という汎用性の高さで際立つBGE-M3を紹介します。
- 多機能性:埋め込みモデルの一般的な3つの検索機能、すなわち、密な検索、マルチベクトル検索、疎な検索を同時に実行できます。
- 多言語性:100以上の実用言語をサポートできます。
- 多粒度性:短い文章から最大8192トークンの長い文書まで、さまざまな粒度の入力データを処理できます。
RAGにおける検索パイプラインに関するいくつかの提案
私たちは、ハイブリッド検索+再ランキングという以下のパイプラインの使用を推奨しています。
- ハイブリッド検索は、さまざまな手法の長所を活用し、より高い精度とより強力な汎化能力を提供します。 典型的な例としては、埋め込み検索と BM25 アルゴリズムの両方を使用することが挙げられます。 埋め込み検索と疎な検索の両方をサポートする BGE-M3 を使用してみましょう。 これにより、緻密な埋め込みを生成する際に追加コストなしでトークン重み(BM25 と同様)を取得することができます。 ハイブリッド検索を使用するには、Vespa や Milvus を参照してください
- クロスエンコーダーモデルとして、バイエンコーダー埋め込みモデルよりも、リランカーの方が精度が高いことが示されています。検索後にリランキングモデル(bge-reranker、bge-reranker-v2など)を利用することで、選択されたテキストをさらにフィルタリングすることができます。
Colaboratoryで。
パッケージインストール。モデルロード時にpeftがないと言って怒られるのであわせてインストール。
!pip install FlagEmbedding peft
モデルのロード。BAAIが提供しているFlagEmbeddingを使う。use_fp16をTrueにすると、性能が少し落ちるが計算速度が向上するらしい。
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=False)
Dense Embedding
ではまずDense Embeddingから。
sentences_1 = [
"和食の特徴について教えて",
"気象観測にはどのようなデータが使用されますか?",
]
sentences_2 = [
"日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。",
"気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用して行われます。",
]
embeddings_1 = model.encode(
sentences_1,
batch_size=12,
max_length=8192, # If you don't need such a long length, you can set a smaller value to speed up the encoding process.
)['dense_vecs']
embeddings_2 = model.encode(sentences_2)['dense_vecs']
print()
print(embeddings_1.shape)
print(embeddings_2.shape)
similarity = embeddings_1 @ embeddings_2.T
print()
print(similarity)
次元数は1024であることがわかる。sentences_1とsentences_1の類似度マトリックスが出力されている。
(2, 1024)
(2, 1024)
[[0.67249537 0.30672002]
[0.25503713 0.7772308 ]]
これを可視化してみる。
!pip install japanize-matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
plt.figure(figsize=(8, 6))
sns.heatmap(similarity, annot=True, cmap="coolwarm", cbar=True, xticklabels=sentences_2, yticklabels=sentences_1)
plt.title("Similarity Matrix")
plt.xlabel("Sentences 2")
plt.ylabel("Sentences 1")
plt.xticks(rotation=45, ha="right")
plt.yticks(rotation=0)
plt.show()
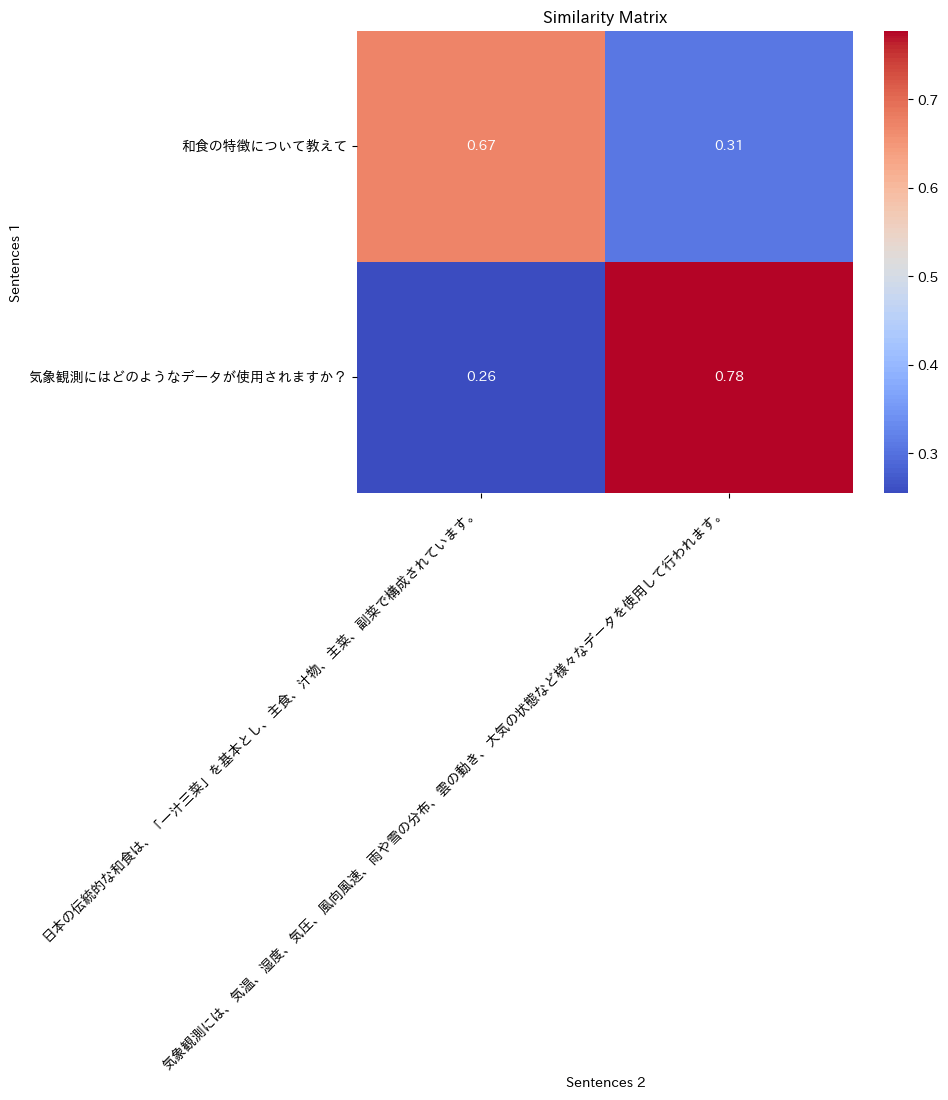
期待した通りの結果となっている。
Sparse Embedding
Sparse Embeddingの場合は、model.encodeにreturn_sparse=Trueを付与すれば良いみたい。
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=False)
sentences_1 = [
"和食の特徴について教えて",
"気象観測にはどのようなデータが使用されますか?",
]
sentences_2 = [
"日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。",
"気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用して行われます。",
]
output_1 = model.encode(sentences_1, return_dense=True, return_sparse=True, return_colbert_vecs=False)
output_2 = model.encode(sentences_2, return_dense=True, return_sparse=True, return_colbert_vecs=False)
出力を見てみると、dense / sparse / マルチベクトル(ColBert)がまとめて1つのオブジェクトとして返されるのがわかる。でreturn_XXXで値が含まれるかどうかを制御するのね。なるほど。
output_1
{'dense_vecs': array([[-0.00335188, -0.02330471, -0.03598176, ..., -0.01485317,
-0.02870478, 0.00837168],
[-0.04722963, -0.00286717, -0.07604853, ..., -0.00685869,
-0.02472899, -0.02347181]], dtype=float32),
'lexical_weights': [defaultdict(int,
{'6': 0.039999153,
'264': 0.24916205,
'6042': 0.24643333,
'195507': 0.21352378,
'12081': 0.068092145,
'99161': 0.1580703}),
defaultdict(int,
{'11232': 0.18505993,
'24082': 0.23081456,
'34502': 0.18924505,
'38114': 0.18417098,
'2880': 0.04287909,
'88302': 0.06464201,
'45465': 0.24703243,
'281': 0.04135511,
'2229': 0.13676628,
'41771': 0.060274795,
'32': 0.026572984})],
'colbert_vecs': None}
convert_id_to_tokenメソッドで、文字列内のトークンごとの重みを見ることができる。
print(model.convert_id_to_token(output_1['lexical_weights'][0]))
{'': 0.039999153, '和': 0.24916205, '食': 0.24643333, 'の特徴': 0.21352378, 'について': 0.068092145, '教えて': 0.1580703}
類似度はcompute_lexical_matching_scoreメソッドで求めることができる。
lexical_scores = model.compute_lexical_matching_score(output_1['lexical_weights'][0], output_2['lexical_weights'][0])
print(lexical_scores)
0.13668444124050438
類似度をマトリックスで計算して可視化してみる。
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
import numpy as np
num_sentences_1 = len(sentences_1)
num_sentences_2 = len(sentences_2)
similarity = np.zeros((num_sentences_1, num_sentences_2))
for i in range(num_sentences_1):
for j in range(num_sentences_2):
similarity[i, j] = model.compute_lexical_matching_score(output_1['lexical_weights'][i], output_2['lexical_weights'][j])
plt.figure(figsize=(8, 6))
sns.heatmap(similarity, annot=True, cmap="coolwarm", cbar=True, xticklabels=sentences_2, yticklabels=sentences_1)
plt.title("Similarity Matrix")
plt.xlabel("Sentences 2")
plt.ylabel("Sentences 1")
plt.xticks(rotation=45, ha="right")
plt.yticks(rotation=0)
plt.show()
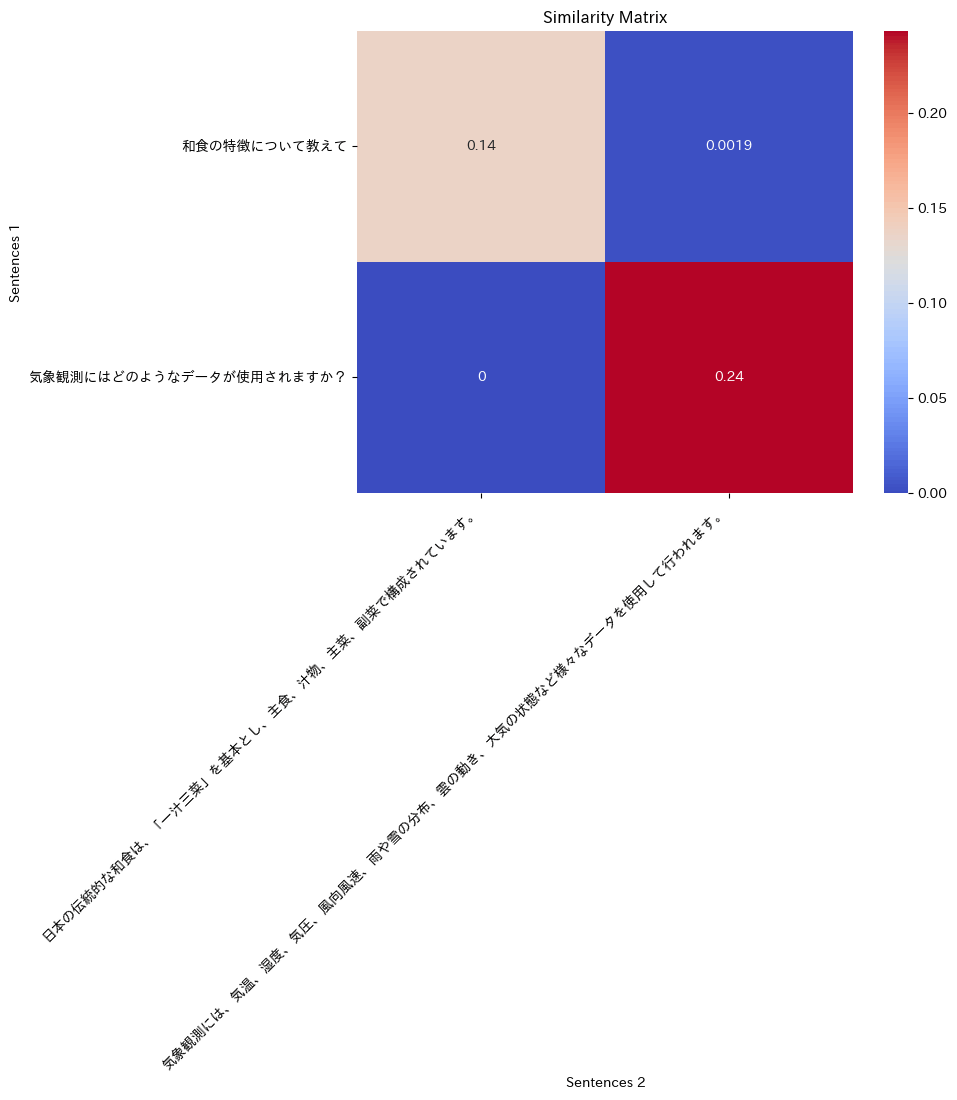
Multi Vector
上でもチラッと見えていたけど、Multi Vectorを有効にするにはreturn_colbert_vecsをTrueにする。
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=False)
sentences_1 = [
"和食の特徴について教えて",
"気象観測にはどのようなデータが使用されますか?",
]
sentences_2 = [
"日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。",
"気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用して行われます。",
]
output_1 = model.encode(sentences_1, return_dense=True, return_sparse=True, return_colbert_vecs=True)
output_2 = model.encode(sentences_2, return_dense=True, return_sparse=True, return_colbert_vecs=True)
類似度はcolbert_scoreメソッドで得られる。
print(model.colbert_score(output_1['colbert_vecs'][0], output_2['colbert_vecs'][0]))
tensor(0.6928)
同様に類似度をマトリックスで計算して可視化してみる。
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
import numpy as np
num_sentences_1 = len(sentences_1)
num_sentences_2 = len(sentences_2)
similarity = np.zeros((num_sentences_1, num_sentences_2))
for i in range(num_sentences_1):
for j in range(num_sentences_2):
similarity[i, j] = model.colbert_score(output_1['colbert_vecs'][i], output_2['colbert_vecs'][j]).item()
plt.figure(figsize=(8, 6))
sns.heatmap(similarity, annot=True, cmap="coolwarm", cbar=True, xticklabels=sentences_2, yticklabels=sentences_1)
plt.title("Similarity Matrix")
plt.xlabel("Sentences 2")
plt.ylabel("Sentences 1")
plt.xticks(rotation=45, ha="right")
plt.yticks(rotation=0)
plt.show()
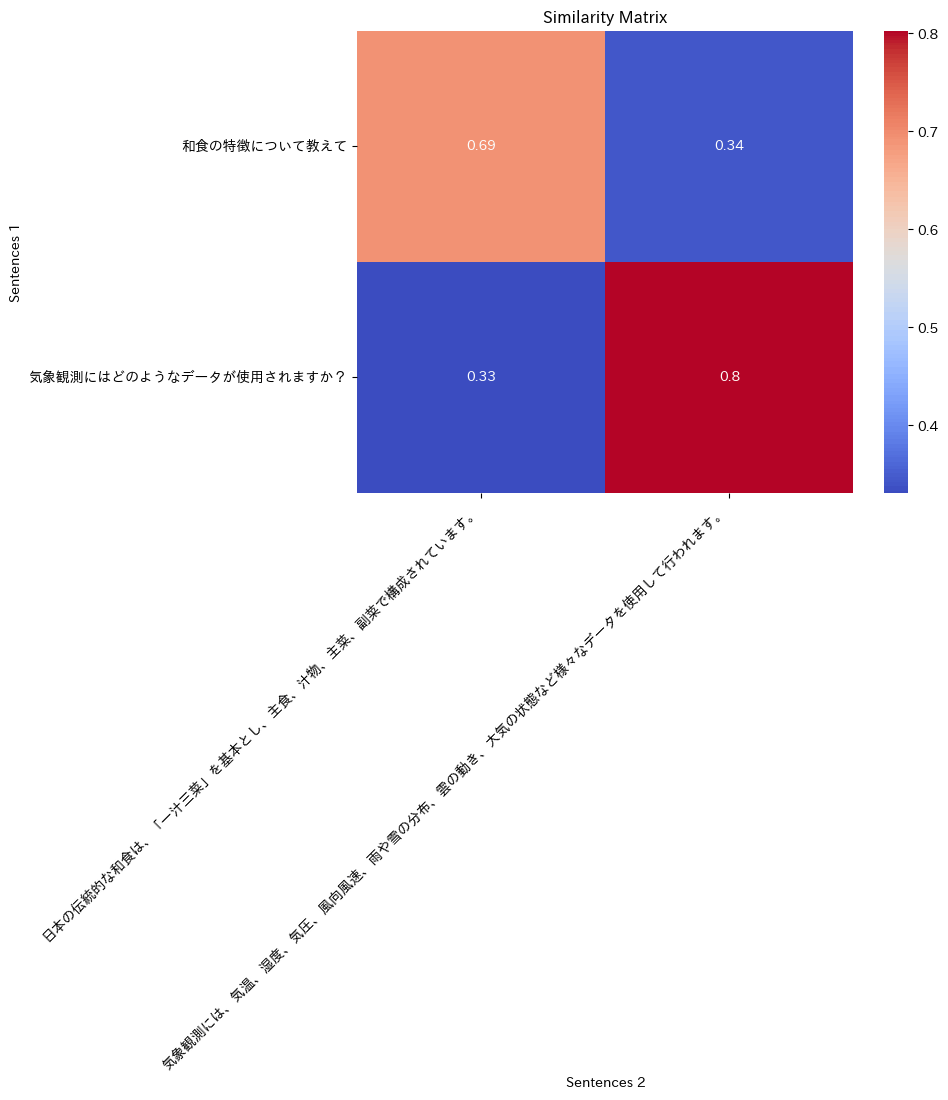
Dense / Sparse / Multi Vectorのハイブリッドを一気に行うこともできる。weights_for_different_modesで重み付けを調整できる。
from FlagEmbedding import BGEM3FlagModel
import json
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
sentences_1 = [
"和食の特徴について教えて",
"気象観測にはどのようなデータが使用されますか?",
]
sentences_2 = [
"日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。",
"気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用して行われます。",
]
sentence_pairs = [[i,j] for i in sentences_1 for j in sentences_2]
scores = model.compute_score(
sentence_pairs,
# a smaller max length leads to a lower latency
max_passage_length=512,
# weights_for_different_modes(w) は重み付き和に使用されます:
# [0]*dense_score + w[1]*sparse_score + w[2]*colbert_score
weights_for_different_modes=[0.4, 0.2, 0.4]
)
print(json.dumps(scores, indent=2))
sparse+denseとcolbert+sparse+denseがハイブリッドの検索結果みたい。
{
"colbert": [
0.6927509307861328,
0.3438541889190674,
0.33112210035324097,
0.8023961186408997
],
"sparse": [
0.13668441772460938,
0.0019006684888154268,
0.0,
0.2431826889514923
],
"dense": [
0.6724953651428223,
0.3067200183868408,
0.25503721833229065,
0.7772307991981506
],
"sparse+dense": [
0.49389171600341797,
0.20511357486248016,
0.1700248122215271,
0.5992147326469421
],
"colbert+sparse+dense": [
0.5734354257583618,
0.26060980558395386,
0.23446372151374817,
0.6804872751235962
]
}
weights_for_different_modesを[0.25, 0.5, 0.25]に変えるとこうなる。
{
"colbert": [
0.6927509307861328,
0.3438541889190674,
0.33112210035324097,
0.8023961186408997
],
"sparse": [
0.13668441772460938,
0.0019006684888154268,
0.0,
0.2431826889514923
],
"dense": [
0.6724953651428223,
0.3067200183868408,
0.25503721833229065,
0.7772307991981506
],
"sparse+dense": [
0.31528806686401367,
0.10350712388753891,
0.08501240611076355,
0.4211987257003784
],
"colbert+sparse+dense": [
0.40965378284454346,
0.16359388828277588,
0.1465398371219635,
0.5164980888366699
]
}
まとめ
以前試した際はDense Embeddingsのことしか考えてなくて、最近たまたまSPLADEを試してみて、そういえばBGE-M3もSparse Embeddingsできるよなーというのを思い出して、改めて試し直した次第。
Sparse Embeddingsは今もBM25が一般的かなと思うけど、運用も大変そうに思えて、その点ではSPLADE悪くないなと思ったんだけど、BGE-M3なら1つでDense/Sparse/Multi Vectorが使えるってのが強みかな。マルチリンガル対応だし、リランカーも用意されているので、そのあたりも含めて、まるっと乗っかるということもできる。
ただBGE-M3 Sparse Embeddingsのトークンごとの重みの出力を日本語SPLADEと比較した感じだと、類義語に強いのはSPLADEの方なのかな?という気がしているがどうだろう?単語単位の類義語→文章単位の類似性までいくとDense Embeddingの領域とも被ってくると思うので、やはりハイブリッドで使うというのが汎用性が高いのだろうとは思う。
いずれにせよ、BM25以外にも選択肢が増えるのは良いと思う。
リランカーも試してみたい。
bge-m3をフレームワークで使う場合、Denseはどれも使えるのだけど、Dense・Sparse・Multi Vectorを全部使えるものとなると選択肢は少ない。
LlamaIndexならばBGEM3Indexで、weights_for_different_modesを使ったハイブリッドなインデックスが作成できる様子。
LangChainにはどうもなさそうなので自分で作る必要がありそう。以下の記事だと、LangChainのHuggingFaceBgeEmbeddingsを使ってるけど、Denseだけになる。
あとはこんなのを見つけた