スパース検索モデル「SPLADE」を日本語で試す
SPLADE
このリポジトリには、SPLADEモデルのトレーニング、インデックス作成、検索を行うためのコードが含まれています。また、BEIRベンチマークの評価を開始するために必要なすべての内容も含まれています。
TL; DR SPLADEは、BERTのMLMヘッドと疎な正則化により、クエリ/ドキュメントの疎な展開を学習するニューラル検索モデルです。疎な表現は、密なアプローチと比較して、いくつかの利点があります。転置インデックスの効率的な利用、明示的な語彙の一致、解釈可能性などです。また、ドメイン外のデータ(BEIRベンチマーク)に対する汎化にも優れているようです。
- (v1、SPLADE)SPLADE:ファーストステージランキングのための疎な語彙および拡張モデル, Thibault Formal, Benjamin Piwowarski and Stéphane Clinchant。SIGIR21ショートペーパー。
ニューラル検索エンジンのトレーニングにおける最近の進歩を活用することで、私たちのv2モデルは、ハードネガティブマイニング、蒸留、より優れた事前学習言語モデルの初期化に依存し、ドメイン内(MS MARCO)およびドメイン外(BEIRベンチマーク)の両方の評価において、その有効性をさらに高めています。
- (v2、SPLADE v2) SPLADE v2: 情報検索のための疎な語彙および拡張モデル、Thibault Formal, Benjamin Piwowarski, Carlos Lassance, and Stéphane Clinchant。 arxiv。
- (v2bis、SPLADE++) 蒸留からハードネガティブサンプリングへ:疎なニューラル情報検索モデルをより効果的に、Thibault Formal, Carlos Lassance, Benjamin Piwowarski, and Stéphane Clinchant。 SIGIR22ショートペーパー(SPLADE v2 の拡張)。
最後に、いくつかの修正(クエリ固有の正則化、独立エンコーダーなど)を導入することで、効率性を向上させ、同じコンピューティング制約下で BM25 と同等のレイテンシを達成することができました。
-(効率的な SPLADE)SPLADE モデルの効率性に関する研究、Carlos Lassance および Stéphane Clinchant。SIGIR22 ショートペーパー。
さまざまな設定で学習したモデルの重みは、Hugging Faceと同様に、Naver Labs Europeのウェブサイトでもご覧いただけます。SPLADEは、モデルそのものというよりもモデルのクラスであることを念頭に置いてください。正則化の程度に応じて、異なる特性とパフォーマンスを持つさまざまなモデル(非常に疎なモデルから、クエリ/ドキュメントの拡張を頻繁に行うモデルまで)を得ることができます。
splade: 片側または両側の刃が鋭利なスプーンで、ナイフ、フォーク、スプーンとして使用できます。
日本語で学習させたモデル
参考
SPLADE(Sparse Lexical and Expansion Model)は、その名の通りスパース(疎)なベクトルを用いた検索モデルです。スパース検索といえば、長年利用されているBM25が代表的で、高い性能を誇るアルゴリズムとして広く利用されています。しかし、BM25はクエリとドキュメントの単語の完全一致に依存しているため、関連する単語や同義語を含む文書を見逃す可能性があります。
一方、SPLADEはTransformerアーキテクチャを活用して、文脈に基づく関連性の高い単語もベクトルに含めることができます。これにより、完全一致以外の単語も検索候補として取り込むことができ、より柔軟で効果的な検索が可能となります。
SPLADEとは関係ないけど、BAAI/bge-m3でもsparse vectorは生成できる。というか、Dense/Sparse/Multi-vector(ColBERT)を個別・組み合わせの全部ができる。
以前試した際には単純なdense retrievalでしか試せてないので、こちらも改めて確認してみるつもり。
今回はhotchpotchさんのjapanese-splade-base-v1を使用させていただいて試してみる。
環境はColaboratoryで。
japanese-splade-base-v1は2つの利用方法がある
- YASEM (Yet Another Splade|Sparse Embedder) を使う。これもhotchpotchさん作。
- transformersを使う。
とりあえずREADMEにあるとおり、両方で進めてみる。
yasemを使う
パッケージインストール。fugashi、unidic-liteも必要になる。japanize-matplotlibは可視化用。
!pip install yasem fugashi unidic-lite japanize-matplotlib
yasemを使うとかなりシンプルに書ける。文章は適当に生成させたもの。
from yasem import SpladeEmbedder
model_name = "hotchpotch/japanese-splade-base-v1"
embedder = SpladeEmbedder(model_name)
sentences = [
"美味しい料理には、新鮮な食材選び、適切な火加減や調理時間を守ることで、素材の旨味を最大限に引き出せます。",
"日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。",
"天気予報の信頼性は、短期・長期などの予報期間によって大きく異なり、局地的な現象の予測は特に難しいです。",
"気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用します。"
]
embeddings = embedder.encode(sentences)
similarity = embedder.similarity(embeddings, embeddings)
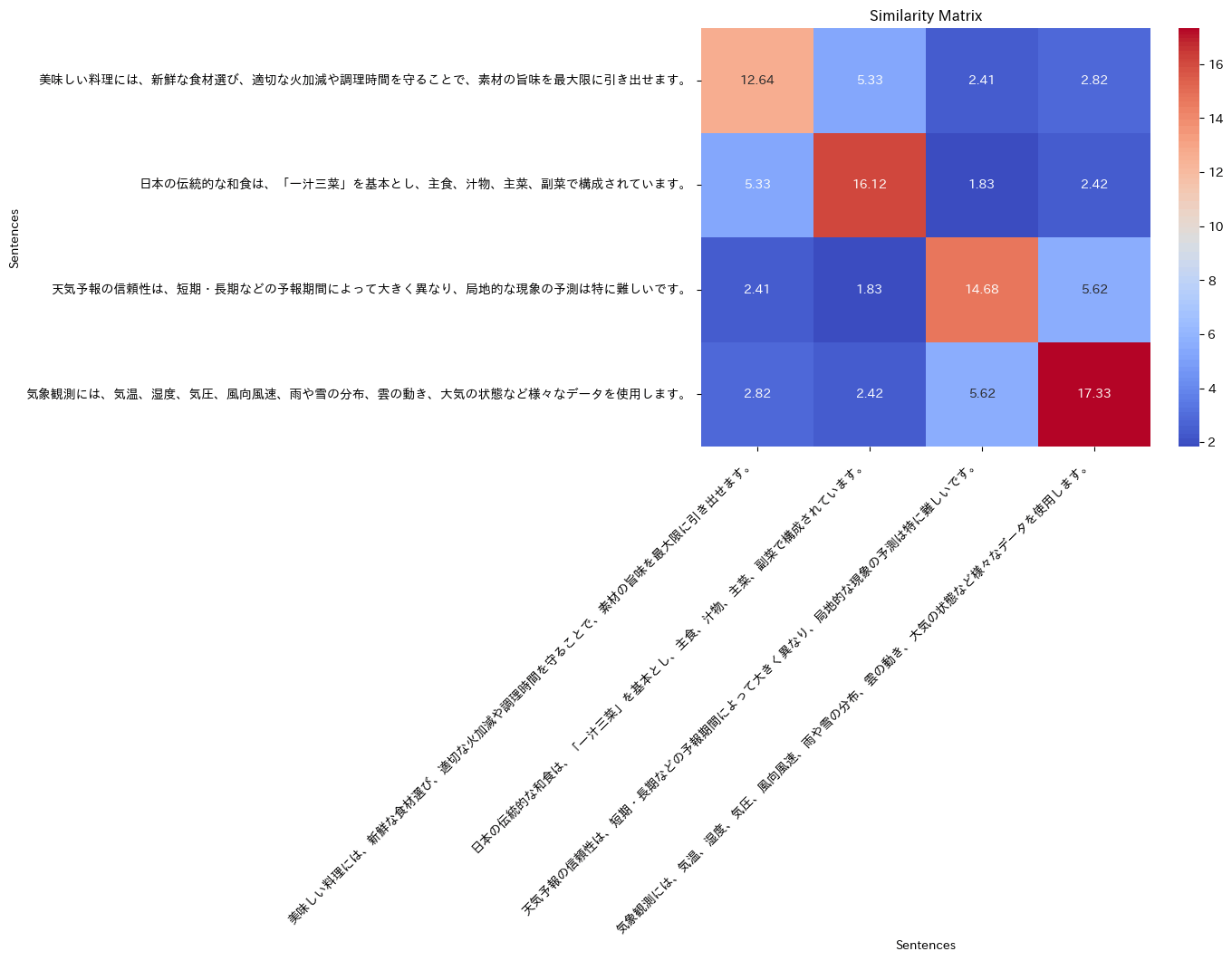
print(similarity)
[[12.64093034 5.32854173 2.41221038 2.82054849]
[ 5.32854173 16.1185551 1.83413256 2.4233649 ]
[ 2.41221038 1.83413256 14.6751727 5.61724945]
[ 2.82054849 2.4233649 5.61724945 17.33412389]]
各文章感の類似度を可視化してみる
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
plt.figure(figsize=(8, 6))
sns.heatmap(similarity, annot=True, cmap="coolwarm", fmt=".2f",
xticklabels=sentences, yticklabels=sentences)
plt.title("Similarity Matrix")
plt.xlabel("Sentences")
plt.ylabel("Sentences")
plt.xticks(rotation=45, ha="right")
plt.tight_layout()
plt.show()
文章のトークンを見てみる。
token_values = embedder.get_token_values(embeddings[0])
print(token_values)
{'料理': 1.2060546875, '方法': 1.0517578125, 'いう': 0.99951171875, '食品': 0.9560546875, '美味': 0.8515625, '素材': 0.6943359375, '調理': 0.689453125, '新鮮': 0.666015625, 'は': 0.66552734375, '旨': 0.63671875, '選択': 0.61376953125, '時間': 0.5927734375, '良い': 0.583984375, '引き': 0.57958984375, '加減': 0.57958984375, '火': 0.560546875, '語': 0.53662109375, '効果': 0.53466796875, '食': 0.51611328125, '適切': 0.478271484375, '食材': 0.475830078125, '味': 0.46240234375, '価格': 0.425537109375, '必要': 0.399658203125, '手順': 0.360107421875, '守る': 0.35400390625, 'おい': 0.3212890625, '期間': 0.309814453125, '温度': 0.309814453125, '材料': 0.28955078125, '引き出し': 0.281494140625, '理由': 0.278564453125, '製品': 0.265869140625, '限': 0.264404296875, '作り': 0.264404296875, '##味': 0.258544921875, '##しい': 0.2208251953125, '最大': 0.21533203125, '定義': 0.1502685546875, 'コスト': 0.1485595703125, '果実': 0.1392822265625, '選定': 0.1273193359375, '鮮': 0.10552978515625, '選び': 0.10205078125, 'できる': 0.0958251953125, '利点': 0.078857421875, '活用': 0.06884765625, '選ば': 0.045806884765625}
なるほど、確かに元の文章に含まれていないけど、類似するような単語にもスコアが付いている。
ざっと全ての文章で、上位のスコアのトークンを見てみる。
import json
for idx, emb in enumerate(embeddings):
token_values = embedder.get_token_values(emb)
top_10_token_values = list(token_values.items())[:20]
print(f"### {sentences[idx]} ###\n")
for k, v in top_10_token_values:
print("%2.5f: %s" % (v, k))
print()
### 美味しい料理には、新鮮な食材選び、適切な火加減や調理時間を守ることで、素材の旨味を最大限に引き出せます。 ###
1.20605: 料理
1.05176: 方法
0.99951: いう
0.95605: 食品
0.85156: 美味
0.69434: 素材
0.68945: 調理
0.66602: 新鮮
0.66553: は
0.63672: 旨
0.61377: 選択
0.59277: 時間
0.58398: 良い
0.57959: 引き
0.57959: 加減
0.56055: 火
0.53662: 語
0.53467: 効果
0.51611: 食
0.47827: 適切
### 日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。 ###
1.25586: 日本
1.14941: 和
1.11133: 食品
1.03320: 汁
0.99854: いう
0.97266: 食
0.96045: 伝統
0.89404: 菜
0.88623: 料理
0.83643: 三
0.80566: は
0.76270: 構成
0.72021: 一
0.71729: 語
0.68311: ##菜
0.61230: 製品
0.59033: ##食
0.58301: 主
0.56396: 副
0.56201: 基本
### 天気予報の信頼性は、短期・長期などの予報期間によって大きく異なり、局地的な現象の予測は特に難しいです。 ###
1.33984: 天気
1.18262: 信頼
1.07227: 予測
1.03711: 予報
0.91943: いう
0.81592: 期間
0.80420: 雨
0.80420: 短期
0.77539: ##地
0.74170: 局
0.70654: 困難
0.67139: 現象
0.66357: 性
0.63477: 長期
0.61621: 温度
0.61035: 違い
0.57520: 信用
0.56787: は
0.52344: 難しい
0.51514: 理由
### 気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用します。 ###
1.20312: 観測
1.17285: 気象
1.14160: いう
0.99170: データ
0.94092: 大気
0.92432: 温度
0.91699: 使用
0.91650: 雨
0.91650: 天気
0.83643: 測定
0.80029: 気温
0.78906: 風速
0.74658: 気圧
0.67432: 情報
0.66943: 風
0.64893: 雲
0.63281: 方法
0.60986: は
0.53418: ##向
0.52832: 湿
transformersを使う
from transformers import AutoModelForMaskedLM, AutoTokenizer
import torch
model_name = "hotchpotch/japanese-splade-base-v1"
model = AutoModelForMaskedLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def splade_max_pooling(logits, attention_mask):
relu_log = torch.log(1 + torch.relu(logits))
weighted_log = relu_log * attention_mask.unsqueeze(-1)
max_val, _ = torch.max(weighted_log, dim=1)
return max_val
sentences = [
"美味しい料理には、新鮮な食材選び、適切な火加減や調理時間を守ることで、素材の旨味を最大限に引き出せます。",
"日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。",
"天気予報の信頼性は、短期・長期などの予報期間によって大きく異なり、局地的な現象の予測は特に難しいです。",
"気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用します。"
]
tokens = tokenizer(
sentences, return_tensors="pt", padding=True, truncation=True, max_length=512
)
tokens = {k: v.to(model.device) for k, v in tokens.items()}
with torch.no_grad():
outputs = model(**tokens)
embeddings = splade_max_pooling(outputs.logits, tokens["attention_mask"])
similarity = torch.matmul(embeddings.unsqueeze(0), embeddings.T).squeeze(0)
print(similarity)
tensor([[12.6324, 5.3323, 2.4128, 2.8186],
[ 5.3323, 16.1204, 1.8345, 2.4232],
[ 2.4128, 1.8345, 14.6706, 5.6130],
[ 2.8186, 2.4232, 5.6130, 17.3225]])
ほぼほぼ同じような結果になっている。
Sparse EmbeddingだとBM25が多そうだけど、類義語とかへの対応が難しいと思うので、とても良さそうに思える。
実際に導入するにあたってはhotchpotchさんの記事にある通り、
単語特徴量が結果に色濃く出るタスクでは、軒並み高性能な結果となっています。代わりに、jagovfaqs(FAQ)のような似ている文章の理解が必要そうなタスクでは、あまり振るわない結果となっています。
この辺はむしろDense Embeddingsが得意な領域だと思うので、使い分けを意識する必要がある。
SPLADEの運用は、密ベクトルモデルとほぼ同様に運用ができるため、難しくありません。検索エンジンは先ほど述べた通りスパース検索もサポートしているものがほとんどです。 またSPLADEのスパースベクトルを得ることも、何か複雑なことを行なっているわけではなく、単語(token)の各スコアを、SPLADE max と呼ばれる max pooling と対数飽和関数の組み合わせに通すだけです。
また、高速で本番運用しやすい推論サーバである text-embedding-inference (blog記事) からも利用可能です。
text-embedding-inferenceもちょっと見てみようと思うが、Qdrant FastEmbedあたりで使えるといいな。ONNXに変換する必要はあるけども。
学習のためのレポジトリまで用意されてるー
さらに、元のSPLADE実装(naver/splade)がCC-BY-NCライセンスで提供されており商用利用に制限があることから、論文を基にTrainerを実装し、MITライセンスのオープンソースソフトウェアとして公開した。