「LMDeploy」を試す
InternVL3を試したのだけど
モデルカードに記載されている使用方法の1つとして、「LMDeploy」での使い方載っていた。
LMDeploy
LMDeploy は、LLM および VLM の圧縮、展開、および提供を行うためのツールキットです。
LMDeploy は、マルチモーダルビジョン言語モデル (VLM) の複雑な推論プロセスを、Large Language Model (LLM) の推論パイプラインと同様の使いやすいパイプラインに抽象化します。
スッキリ書けて良さそうに思ったので、少し試してみようと思う。
GitHubレポジトリ
日本語のREADMEもある
基本的なところだけ抜粋
紹介
LMDeployは、MMRazor および MMDeploy チームによって開発された、LLMの圧縮、デプロイ、およびサービングのためのツールキットです。以下の主要な機能を備えています:
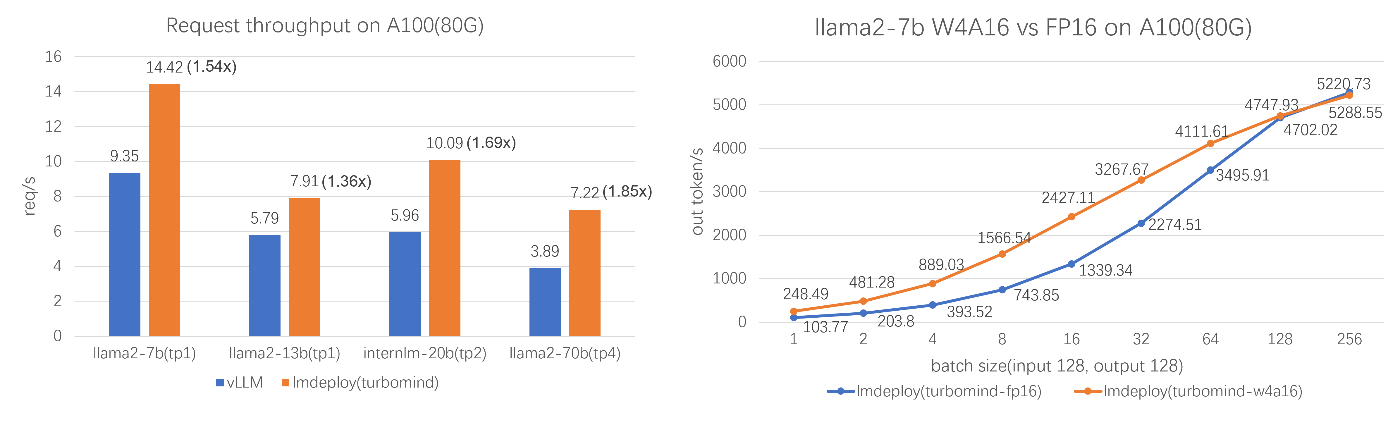
効率的な推論: LMDeployは、persistent batch(連続バッチ)、ブロック化されたKVキャッシュ、動的分割と融合、テンソル並列、高性能なCUDAカーネルなどの主要な機能を導入し、vLLMよりも最大1.8倍のリクエストスループットを提供します。
効果的な量子化: LMDeployは、重みのみおよびk/vの量子化をサポートし、4ビットの推論性能はFP16の2.4倍です。量子化の品質はOpenCompassの評価を通じて確認されています。
簡単な分散サーバー: リクエスト分散サービスを活用することで、LMDeployは複数のマシンおよびカードにわたるマルチモデルサービスのデプロイを容易にします。
インタラクティブな推論モード: マルチラウンドの対話プロセス中にアテンションのk/vをキャッシュすることで、エンジンは対話履歴を記憶し、履歴セッションの繰り返し処理を回避します。
優れた互換性: LMDeployは、KV Cache Quant、AWQ、および Automatic Prefix Caching を同時に使用することをサポートします。
パフォーマンス
LMDeploy TurboMindエンジンは卓越した推論能力を持ち、さまざまな規模のモデルで、vLLMの1.36〜1.85倍のリクエストを毎秒処理します。静的推論能力の面では、TurboMind 4ビットモデルの推論速度(out token/s)はFP16/BF16推論をはるかに上回ります。小さなバッチでは、2.4倍に向上します。
referred from https://github.com/InternLM/lmdeploy/tree/main/README_ja.mdサポートされているモデル
LLM VLM Llama (7B - 65B)
Llama2 (7B - 70B)
Llama3 (8B, 70B)
Llama3.1 (8B, 70B)
Llama3.2 (1B, 3B)
InternLM (7B - 20B)
InternLM2 (7B - 20B)
InternLM3 (8B)
InternLM2.5 (7B)
Qwen (1.8B - 72B)
Qwen1.5 (0.5B - 110B)
Qwen1.5 - MoE (0.5B - 72B)
Qwen2 (0.5B - 72B)
Qwen2-MoE (57BA14B)
Qwen2.5 (0.5B - 32B)
Qwen3, Qwen3-MoE
Baichuan (7B)
Baichuan2 (7B-13B)
Code Llama (7B - 34B)
ChatGLM2 (6B)
GLM4 (9B)
CodeGeeX4 (9B)
YI (6B-34B)
Mistral (7B)
DeepSeek-MoE (16B)
DeepSeek-V2 (16B, 236B)
DeepSeek-V2.5 (236B)
Mixtral (8x7B, 8x22B)
Gemma (2B - 7B)
StarCoder2 (3B - 15B)
Phi-3-mini (3.8B)
Phi-3.5-mini (3.8B)
Phi-3.5-MoE (16x3.8B)
Phi-4-mini (3.8B)
MiniCPM3 (4B)LLaVA(1.5,1.6) (7B-34B)
InternLM-XComposer2 (7B, 4khd-7B)
InternLM-XComposer2.5 (7B)
Qwen-VL (7B)
Qwen2-VL (2B, 7B, 72B)
Qwen2.5-VL (3B, 7B, 72B)
DeepSeek-VL (7B)
DeepSeek-VL2 (3B, 16B, 27B)
InternVL-Chat (v1.1-v1.5)
InternVL2 (1B-76B)
InternVL2.5(MPO) (1B-78B)
InternVL3 (1B-78B)
Mono-InternVL (2B)
ChemVLM (8B-26B)
CogVLM-Chat (17B)
CogVLM2-Chat (19B)
MiniCPM-Llama3-V-2_5
MiniCPM-V-2_6
Phi-3-vision (4.2B)
Phi-3.5-vision (4.2B)
GLM-4V (9B)
Llama3.2-vision (11B, 90B)
Molmo (7B-D,72B)
Gemma3 (1B - 27B)
Llama4 (Scout, Maverick)LMDeployは、TurboMind および PyTorch の2つの推論エンジンを開発しました。それぞれ異なる焦点を持っています。前者は推論性能の究極の最適化を目指し、後者は完全にPythonで開発されており、開発者の障壁を下げることを目指しています。
サポートされているモデルの種類や推論データタイプに違いがあります。各エンジンの能力についてはこの表を参照し、実際のニーズに最適なものを選択してください。