「InternVL3」を試す
4月頃か、気づいてなかった
InternVL3:ネイティブなマルチモーダル事前学習でオープンソースのマルチモーダルモデルを前進させる
referred from https://internvl.github.io/blog/2025-04-11-InternVL-3.0/私たちは、優れた総合性能を示す高度なマルチモーダル大規模言語モデル(MLLM)シリーズ InternVL3 を紹介します。InternVL 2.5 と比較して、InternVL3 はマルチモーダルな知覚および推論能力が向上しており、さらにツール使用、GUI エージェント、産業用画像解析、3 D ビジョン認識などへとマルチモーダル機能を拡張しています。また、InternVL3 では、対応する事前学習済み基盤モデルが言語コンポーネントの初期化に用いられている Qwen 2.5 Chat モデルとの比較も行いました。ネイティブなマルチモーダル事前学習の恩恵により、InternVL3 シリーズは Qwen 2.5 シリーズよりも優れたテキスト性能全体を達成しています。
InternVL3 ファミリーは以下の設計に基づいて構築されています。
可変視覚位置エンコーディング: 可変視覚位置エンコーディング(V2PE) を統合し、視覚トークンに対してより小さく柔軟な位置インクリメントを使用します。この変更により、位置ウィンドウを過度に拡張することなく、より長いマルチモーダル文脈を扱うことが容易になります。
ネイティブマルチモーダル事前学習: 言語事前学習とマルチモーダル整合学習を単一の事前学習ステージに統合するアプローチを提案します。従来のパラダイム—まず言語のみの大規模モデルを学習し(通常は言語事前学習とその後の言語後続学習)、後に追加モダリティを適合させる—とは異なり、我々の方法では事前学習中に大規模テキストコーパスとともにマルチモーダルデータ(例:画像–テキスト、動画–テキスト、または画像–テキスト混合列)をインターリーブさせることで統合的最適化を行います。この統一的学習スキームにより、モデルは言語能力とマルチモーダル能力を同時に習得し、追加のブリッジモジュールや後続のモデル間アライメント処理を導入することなく視覚と言語のタスクを扱う能力を高めます。
Mixed Preference Optimization: 事前学習および SFT 中、モデルは前の正解トークンを条件に次トークンを予測しますが、推論時にはモデル自身が生成したトークンに基づいて予測を行います。この正解トークンとモデル予測トークンの不一致は分布のシフトを引き起こし、Chain-of-Thought(CoT)推論能力を損なう可能性があります。この問題を緩和するために、Mixed Preference Optimization(MPO) を採用し、正例と負例の両方からの追加的監督を導入してモデル応答分布を正解分布に合わせ、推論性能を向上させます。
VisualPRM を用いたテスト時スケーリング: テスト時スケーリングは LLM および MLLM の推論能力を高める有効な手法であることが示されています。本研究では Best-of-N 評価戦略を用い、VisualPRM-8B を批評モデルとして、推論および数学評価において最良の応答を選択します。
referred from https://internvl.github.io/blog/2025-04-11-InternVL-3.0/InternVL3 のアーキテクチャは、その前身と同じ一般的な枠組みである「ViT-MLP-LLM」パラダイムに従います。前バージョン同様、ピクセル・アンシャッフル処理を適用して視覚トークン数を元の 4 分の 1 に削減しました。さらに、InternVL 1.5 と同様の動的解像度戦略を採用し、画像を 448 × 448 ピクセルのタイルに分割しています。InternVL 2.0 以降の主な違いは、複数画像および動画データのサポートを追加した点です。特筆すべきは、InternVL3 では 可変視覚位置エンコーディング(V2PE) を統合し、視覚トークンに対してより小さく柔軟な位置インクリメントを利用していることです。V2PE の恩恵により、InternVL3 は前モデルよりも長いコンテキストの理解能力が向上しています。

モデルのバリエーションが多い。1B / 2B / 8B / 9B / 14B / 38B / 78Bで、それぞれ
- 事前学習済モデル(
*-pretrained) - Insturctモデル(
*-Instruct: 事前学習済モデル+教師ありファインチューニング) - MPOモデル(サフィックスなし: 事前学習済モデル+教師ありファインチューニング+Mixed Preference Optimization)
- AWQ(
*-AWQ: MPOモデルのAWQ量子化バージョン)
が用意されている。どれを使っていいかわからない場合はMPOモデル(サフィックスなし)を使え、と書いてある。
追記20250514
後で気づいたのだけど、モデルのバリエーションには-hfというサフィックスがついたものもある(Collectionsにはなかった)。例えば以下。
このリポジトリには、OpenGVLab/InternVL3-2B モデルの Hugging Face 🤗 Transformers 実装が含まれています。
これは OpenGVLab のオリジナルリリースと機能的に同等であることを目的としています。
Transformers ネイティブモデルとして、SDPA を含む eager モードや FA2 などの各種アテンション実装といったコアライブラリ機能をサポートし、画像・動画・テキストが入り混じった入力に対する効率的なバッチ推論を実現します。
transformersのパイプラインやチャットテンプレートを使って書けるみたい。そっちのほうが楽かもね。
以前Ovis2を試したときに性能比較でInternVL2.5が記載されていたのは見ていた。
その際はOvis2が日本語OCRとしてはかなり優秀だと思っていたので試していなかった。InternVL3の評価グラフにはOvis1.6はあるがOvis2は載っていない。並べてみるとおそらくほぼ同等レベルではないか?という感がある。

referred from https://internvl.github.io/blog/2025-04-11-InternVL-3.0/

referred from https://huggingface.co/AIDC-AI/Ovis2-1B
ただ、先日 llama.cpp で llama-server がマルチモーダルに対応して、対応モデルにInternVL3が含まれている(量子化済みモデルも公開されている)ため、こちらのほうが使い勝手が良さそう(Ovisは残念ながらllama.cppで対応していない)
ということで試してみる。
ちなみに以下でInternVL2.5のデモがある。前のバージョンである2.5だけど日本語は普通に使えるし画像内の文字なども結構読めている感がある。
まずはColaboratoryで。ランタイムはL4。MPOモデルの2Bを試す。
transformersは4.37.2以上が必要だが、現時点で確認した限り、Colaboratoryには4.51.3が事前にインストールされていたので、それを使う。あと、サンプルコードでは
- flash attentionを使用している
- bitsandbytesの量子化についても触れられている
のでこれらを追加しておく。
!pip install bitsandbytes
!pip install flash-attn --no-build-isolation
あとちょっとサンプルコードが複雑な感があるので、o3に単純化してもらった。
モデルとトークナイザーのロード
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3-2B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True
).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(
path,
trust_remote_code=True,
use_fast=False
)
モデルロード後のVRAM消費量は4.4GBぐらい
Wed May 14 08:24:39 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:00:03.0 Off | 0 |
| N/A 54C P0 29W / 72W | 4403MiB / 23034MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
まずはテキストだけでチャット
generation_config = dict(max_new_tokens=1024, do_sample=False)
question = "こんにちは、自己紹介してください。"
response, history = model.chat(
tokenizer,
None,
question,
generation_config,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
ユーザ: こんにちは、自己紹介してください。
アシスタント: こんにちは!私はAIの助手で、さまざまな質問に答えたり、情報を提供したりします。何かお手伝いできることがあれば、お知らせくださいね。
ユーザ: こんにちは、自己紹介してください。
アシスタント: こんにちは!私はAIの助手で、さまざまな質問に答えたり、情報を提供したりします。何かお手伝いできることがあれば、お知らせくださいね。
では画像を使ってみる。モデルレポジトリにあるサンプル画像を取得する。
!wget --content-disposition https://huggingface.co/OpenGVLab/InternVL3-2B/resolve/main/examples/image1.jpg?download=true
!wget --content-disposition https://huggingface.co/OpenGVLab/InternVL3-2B/resolve/main/examples/image2.jpg?download=true
画像を確認しておく。
from IPython.display import Image as IPyImage
from io import BytesIO
from PIL import Image
def show_thumbnail(file: str, target_px: int = 400) -> IPyImage:
img = Image.open(file)
buf = BytesIO()
fmt = (img.format or "JPEG").upper()
img.save(buf, format=fmt, quality=90)
w, h = img.size
param = {"width": target_px} if w >= h else {"height": target_px}
return IPyImage(data=buf.getvalue(), **param)
display(show_thumbnail("image1.jpg"))
print()
display(show_thumbnail("image2.jpg"))

1枚目の画像を入力に使う。InternVLに入力する画像については以下とある。
さらに、InternVL 1.5 と同様の動的解像度戦略を採用し、画像を 448×448 ピクセルのタイルに分割しました。InternVL 2.0 からの主な違いは、マルチ画像およびビデオデータのサポートが新たに追加されたことです。
基本は448×448ピクセルで、それに合わない場合はリサイズしたり、タイル分割したり、みたいなことが必要になる。このあたりのヘルパー関数が用意されている。
import torchvision.transforms as T
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
load_image()を使って画像を読み込み、これをプロンプトとともに渡す。プロンプトに<image>と入力した箇所に挿入されるみたい。
generation_config = dict(max_new_tokens=1024, do_sample=False)
pixel_values = load_image('image1.jpg', max_num=12).to(torch.bfloat16).cuda()
question = '<image>\nこの画像について簡潔に説明して。'
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
ユーザ: <image>
この画像について簡潔に説明して。
アシスタント: この画像は、リッキーというリッキー・ラッキーという名の紅毛狐が、木製の柵や木の上に居た写真です。リッキーは、顔を傾けて見ている様子で、落ち着いた表情をしています。背景には木々が見え、自然な環境が感じられます。
ユーザ: <image>
この画像について簡潔に説明して。
アシスタント: この画像は、リッキーというリッキー・ラッキーという名の紅毛狐が、木製の柵や木の上に居た写真です。リッキーは、顔を傾けて見ている様子で、落ち着いた表情をしています。背景には木々が見え、自然な環境が感じられます。
見えているものとしてはあってるんだけど、変な名前がついててここはちょっとハルシネーションしてるかな。英語で試してみると、
(snip)
question = '<image>\nPlease describe the image shortly.'
(snip)
A red panda is resting on a wooden platform, with its fluffy fur and large eyes visible. The background features green foliage and a tree trunk.
というような、いかにも期待するような結果にはなってるので、日本語は多少精度が落ちるのかもしれない。ただ、今の設定はサンプリング無効(常に同じ回答になる)なので、ここはパラメータを調整すれば変わってくると思う。
画像を使った推論後のVRAM消費量は4.9GB
Wed May 14 10:00:25 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:00:03.0 Off | 0 |
| N/A 67C P0 50W / 72W | 4933MiB / 23034MiB | 41% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
あと、マルチターンのチャットにも対応している。return_history=Trueにすると会話履歴が返ってくる。(説明の簡単のため少しインデント入れている)
print(history)
[
(
'<image>\nこの画像について簡潔に説明して。',
'この画像は、リッキーというリッキー・ラッキーという名の紅毛狐が、木製の柵や木の上に居た写真です。リッキーは、顔を傾けて見ている様子で、落ち着いた表情をしています。背景には木々が見え、自然な環境が感じられます。'
)
]
これをhistoryパラメータで再度渡してやる。
question = 'この画像についての短い詩を書いて。'
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
history=history,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
ユーザ: この画像についての短い詩を書いて。
アシスタント: リッキーの目を窺う
木の上に眠る姿
自然の光に輝く
心のリッキーの日々
複数の画像を使う。複数の画像の使い方に複数のパターンがある。
- 複数の画像を結合して1つの画像として渡す
- 複数の画像を個別に渡す
- 複数の画像をそれぞれ個別に推論する(バッチ)
まず1つ目。複数の画像をタイル化して結合、そして1つの画像として渡すパターン。
generation_config = dict(max_new_tokens=1024, do_sample=False)
pixel_values1 = load_image('image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('image2.jpg', max_num=12).to(torch.bfloat16).cuda()
# 画像を結合
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
# <image>は1回で良い
question = '<image>\n2つの画像について詳しく説明して。'
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
history=None,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
question = 'この2つの画像の共通点と相違点を教えて。'
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
history=history,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
ユーザ: <image>
2つの画像について詳しく説明して。
アシスタント: この画像には、2つの異なる場面が含まれています。
1. **左の画像**:
- この画像は、紅熊猫(かに)が木の柵や木製の架け橋に頬をつけている場面です。紅熊猫は毛が濃い赤と白の色で、耳と鼻の周りには白い毛が特徴です。この動物は、竹や木製の構造物に頬をつけて、何かを探し回っている様子です。背景には、木々が見え、自然な環境が感じられます。
2. **右の画像**:
- この画像は、大熊猫(だいぼう)が竹を食いながら、竹の葉や枝を抱きしめている場面です。大熊猫は毛が白と黒の色で、顔に大きな黒い斑点があります。この動物は、竹の葉を口に含み、周囲の竹の葉や枝を抱きしめています。背景には、竹や緑の植物が見え、自然な環境が感じられます。
2つの画像の共通点は、両方の動物は竹を食べているシーンで、自然な環境に身を置いていることです。それぞれの動物は、それぞれの環境の中で、自然な行動を取っています。
ユーザ: この2つの画像の共通点と相違点を教えて。
アシスタント: この2つの画像の共通点と相違点を以下に説明します。
### 共通点
1. **動物**: 両方の画像にいる動物は、それぞれの種類の熊(紅熊猫と大熊猫)です。
2. **竹**: 両方の動物は、竹を食べている場面です。竹は両方の動物の食事の主な成分です。
3. **自然な環境**: 両方の動物は、自然な環境の中で活動しています。竹や木製の構造物が背景で見えます。
### 相違点
1. **動物の種類**:
- 左の画像は、紅熊猫(かに)です。
- 右の画像は、大熊猫(だいぼう)です。
2. **姿勢**:
- 左の画像では、紅熊猫は木製の柵や架け橋に頬をつけている。
- 右の画像では、大熊猫は竹を抱きしめながら食べています。
3. **毛色**:
- 左の画像では、紅熊猫は濃い赤と白の毛で特徴があります。
- 右の画像では、大熊猫は白と黒の毛で特徴があります。
4. **背景の構造**:
- 左の画像では、木製の柵や架け橋が背景です。
- 右の画像では、竹や緑の植物が背景です。
### 总結
2つの画像は、同じ種類の動物(紅熊猫と大熊猫)が異なる種類の竹を食べている場面で、自然な環境の中で活動していることです。共通点は動物種類、竹の食べ物、自然な環境です。相違点は動物の種類、姿勢、毛色、背景の構造です。
ちょいちょいふりがなおかしかったり中国語でてきたりするのはまあしょうがないかな。でも其々の画像を理解しているように見える。
複数の画像を個別に渡すパターン。こちらも一旦は結合されるのだけどnum_patches_listパラメータで、それぞれの画像のタイル数の配列を渡すことで、モデルはそれぞれの画像を識別できる、という感じ。
generation_config = dict(max_new_tokens=1024, do_sample=False)
pixel_values1 = load_image('image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('image2.jpg', max_num=12).to(torch.bfloat16).cuda()
# 結合しつつ、num_patches_listでそ画像の境界を示す
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
# 画像の数だけ<image>が必要
question = '画像1: <image>\n画像2: <image>\n2つの画像について詳しく説明して。'
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
num_patches_list=num_patches_list,
history=None,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
question = 'この2つの画像の共通点と相違点を教えて。'
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
num_patches_list=num_patches_list,
history=history,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
ユーザ: 画像1: <image>
画像2: <image>
2つの画像について詳しく説明して。
アシスタント: 画像1と画像2は、それぞれ異なる種類の動物が描かれています。
画像1は、紅熊猫(学名:Ailurus fulgens)を写真にしています。紅熊猫は、赤と白の毛で特徴的な動物で、日本の「かわいい」という意味の「かわい」という言葉から名付けられました。彼らは、日本の亀裂や竹林に住み、木の枝や木製の構造物で遊び、食事も竹や木製の葉物を食べます。この画像では、紅熊猫が木製の柵や木の枝に頬を伏し、落ち着きのある表情で写っています。
画像2は、大熊猫(学名:Ailuropoda melanoleuca)を写真にしています。大熊猫は、中国の「かわいい」という意味の「かわいい」という言葉から名付けられた動物で、特に竹を食べるのが特徴です。彼らは、竹の葉や枝を食べ、木製の柵や竹林に住み、日本の「かわいい」という意味の「かわいい」という言葉から名付けられました。この画像では、大熊猫が竹の葉を口にし、木製の柵や竹林の中を探索しています。
二つの動物は、それぞれの特徴的な毛色と食性に特徴があり、それぞれの環境に適応しています。
ユーザ: この2つの画像の共通点と相違点を教えて。
アシスタント: 画像1と画像2の共通点と相違点を以下に説明します。
### 共通点
1. **動物種**:両方の画像は、それぞれの種類の動物を写しています。画像1は紅熊猫、画像2は大熊猫です。
2. **自然環境**:両方の動物は、自然環境の中で生活しています。紅熊猫は日本の亀裂や竹林に住み、大熊猫は竹林や木製の柵に住みます。
3. **表情**:両方の動物は、落ち着きのある表情をしています。紅熊猫は、木製の柵に頬を伏し、目を細かく見ている様子です。大熊猫は、竹の葉を口にし、木製の柵や竹林の中を探索しています。
### 相違点
1. **毛色**:紅熊猫は赤と白の毛で特徴的で、大熊猫は白と黒の毛で特徴的です。
2. **食性**:紅熊猫は竹や木製の葉物を食べ、大熊猫は竹を主食として食べます。
3. **環境**:紅熊猫は日本の亀裂や竹林に住み、大熊猫は竹林や木製の柵に住みます。両方の動物は竹林や木製の柵に住みますが、環境の違いがあります。
4. **姿勢**:紅熊猫は木製の柵に頬を伏し、目を細かく見ている様子です。大熊猫は竹の葉を口にし、木製の柵や竹林の中を探索しています。
### 总結
画像1と画像2は、同じ種類の動物(紅熊猫と大熊猫)を写しているものの、毛色、食性、環境、姿勢に違いがあります。それぞれの特徴が自然環境の中でどのように適応しているかが示されています。
画像を個別で指定できるので、マルチターンのチャットだとこちらのほうがいいかもね。
最後にバッチ。これは単にバッチで推論できるというだけだけど、バッチ用のメソッドを使う。
pixel_values1 = load_image('image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nこの画像について詳しく説明して。'] * len(num_patches_list)
responses = model.batch_chat(
tokenizer,
pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config
)
for question, response in zip(questions, responses):
print(f'ユーザ: {question}\nアシスタント: {response}')
print("----------")
ユーザ: <image>
この画像について詳しく説明して。
アシスタント: この画像は、紅狐(かに)が木の上にいる写真です。紅狐は、特徴的な赤と黒の毛色と白いフリルが特徴的な動物で、日本の国営公園や動物園でよく見られます。この写真では、紅狐は木の柵や柵の上に首を伸ばして、落ち着いた表情で見ているようです。背景には木々が見え、自然な環境が感じられます。
----------
ユーザ: <image>
この画像について詳しく説明して。
アシスタント: この画像は、大熊猫(もはや「かわいい」と呼ばれるほど可愛らしい姿をしています)が竹を食いながら、木の下で過ごしている様子です。竹は大熊猫の主食であり、彼らは竹を食べることでエネルギーを貯め、毛を育てます。この環境は、自然な竹林を模した人工的な環境で、大熊猫が自然な状況で生活できるように設計されています。背景には他の大熊猫が見えますが、写真の焦点は元の写真の中心部にある大きな、白と黒の斑点が特徴の大きな頭部の大熊猫です。
----------
何回か繰り返しているとVRAM消費が少し上がっていた。
Wed May 14 11:05:10 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:00:03.0 Off | 0 |
| N/A 63C P0 30W / 72W | 5567MiB / 23034MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
InternVL3では動画も読み込める。モデルレポジトリにあるサンプル動画を取得する
wget --content-disposition https://huggingface.co/OpenGVLab/InternVL3-2B/resolve/main/examples/red-panda.mp4?download=true
Colaboratoryで再生して確認
from IPython.display import Video
Video("red-panda.mp4", embed=True)



動画を読み込む場合のヘルパー関数も用意されている。
!pip install decord
from decord import VideoReader, cpu
import numpy as np
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
動画を渡す場合はフレームに分割して渡すのね。
video_path = 'red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'フレーム{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'レッサーパンダは何してる?'
# 以下のようなプロンプトになる
# ---
# フレーム1: <image>
# フレーム2: <image>
# ...
# フレーム8: <image>
# レッサーパンダは何してる?
# ---
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
num_patches_list=num_patches_list,
history=None,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
question = 'この動画について詳しく説明して。'
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
num_patches_list=num_patches_list,
history=history,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
ユーザ: フレーム1: <image>
フレーム2: <image>
フレーム3: <image>
フレーム4: <image>
フレーム5: <image>
フレーム6: <image>
フレーム7: <image>
フレーム8: <image>
レッサーパンダは何してる?
アシスタント: レッサーパンダは、竹の枝に巻かれた竹の葉を噛み砕くことで、食事をしています。この行為は、レッサーパンダの自然な食事の一部であり、彼らが竹を食べることを好む動物の特徴です。
ユーザ: この動画について詳しく説明して。
アシスタント: この動画は、レッサーパンダが竹の枝に巻かれた竹の葉を噛み砕く様子を撮影したものです。レッサーパンダは、竹を食べることを好む動物の特徴で、この行為は自然な食事の一部です。動画の背景は、草の生い茂りや竹の枝が見える自然な環境で、レッサーパンダが遊ぶ場所を示しています。動画の内容は、動物の自然な行動を表現しており、動物の生態学や食事の様子を示しています。
モデルカードには
- ストリーミング出力
- LMDeployを使った、パイプラインでの利用、モデルをOpenAI互換APIサーバとしてデプロイする
なども記載されている。
LMDeployって知らなかったけど、かなりシンプルに書けそうで便利そう。また試してみる。
過去VLMを試す際に使っている手持ちの画像で試してみる。
日本の風景

!wget https://storage.googleapis.com/zenn-user-upload/82968d23b6c5-20250228.jpg -O kobe.jpg
generation_config = dict(max_new_tokens=1024, do_sample=False)
pixel_values = load_image('kobe.jpg', max_num=12).to(torch.bfloat16).cuda()
question = '<image>\nこの画像について詳しく説明して。'
response = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
)
print(response)
この画像は、日本の神戸市を背景にした海の景色です。主要な観光スポットである「神戸テレビ塔」が中央に位置し、その先には「神戸海洋館」の白いデザインが見えます。海の静けさと都市の並びが美しい風景で、都市の活力と海の魅力が融合しています。
response = model.generate_content([image, "この写真に写っているもので、最も有名と考えられる建築物は何でどこに写っていますか?"])
print(response)
この写真に最も有名と考えられる建築物は、赤い塔です。これは、日本の大阪市にある「大阪城タワー」です。この塔は、大阪市内に位置し、観光客の目にする場所にあります。
書籍の表紙

!wget https://storage.googleapis.com/zenn-user-upload/caa14aef4b7e-20250226.png -O book.png
generation_config = dict(max_new_tokens=1024, do_sample=False)
pixel_values = load_image('book.png', max_num=12).to(torch.bfloat16).cuda()
question = '<image>\nこの画像について詳しく説明して。'
response = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
)
print(response)
この画像は、ビジネス書籍の表紙と裏表紙の組み合わせです。タイトルは「ドキュメント・コミュニケーションの全体観」で、内容はビジネス書籍の「読解」「制作」「ビジュアル」の3要素についての理論と手法を紹介しています。著者は上川形夫です。
裏表紙には、ビジネスコミュニケーションの進展の3つの要素を示す図が示されています。これらは「理解」、「行動」、「早見」です。図の中央には「プロセス」が示され、その周りには「手法」が囲まれています。この図は、ビジネスコミュニケーションにおける理解、行動、早見のプロセスや手法の組み合わせを示しています。
裏表紙の下部には、ビジネスコミュニケーションの進展の3要素についてのメッセージが書かれています。「解・動・早」で進めていきたいと述べており、理解、行動、早見が重要であることを強調しています。
日本語の文字はかなり読めてる。小さな文字の読み間違いは画像の質にもよるかも。
ダミーの請求書

!wget https://storage.googleapis.com/zenn-user-upload/4697c3aef653-20250226.png -O invoice.png
generation_config = dict(max_new_tokens=1024, do_sample=False)
pixel_values = load_image('invoice.png', max_num=12).to(torch.bfloat16).cuda()
question = '<image>\nこの画像について詳しく説明して。'
response = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
)
print(response)
この画像は、請求書(請求書番号: INV-2024-0820)の例として、模範商事株式会社の請求書です。以下に主要な内容を説明します。
会社情報
- 会社名: 模範商事株式会社
- 住所: 〒100-0001 東京都千代田区見本町1-1
- 電話: 03-1234-5678
- FAX: 03-1234-5679
請求書内容
- 請求書の通り: 下記の通りご請求申し上げます。
請求内容
- 項目と数量:
- 特選和紙 (A4サイズ): 1000枚
- 単価: ¥50
- 金額: ¥50,000
- 高級墨 (松煙): 20本
- 単価: ¥2,000
- 金額: ¥40,000
- 筆セット (各種): 50本
- 単価: ¥1,000
- 金額: ¥50,000
総計
- 小計: ¥140,000
- 消費税 (10%): ¥14,000
- 合計金額: ¥154,000
備考
- 支払いは請求書発行日より30日以内にお願いいたします。
- 振込手数料は貴社負担でお願いいたします。
- 本書に関するお問い合わせは下記担当者までご連絡ください。
責任担当
- 負責: 営業部 見本 太郎
この請求書は、特定の文房具の購入を求めるものです。
おお、こちらは完璧に近いのでは。
まとめ
2Bなので知識が足りないってのはあるかも。特に日本の知識はやや弱そう。ここはもう少し大きめのモデルで試してみないとわからないけど、次が8Bなんだよねー。
ただ、日本語の文字はかなり読めてる。これはInternVL2.5でもある程度読めてるように思えるけど、3でさらに精度は上がってるのではないかと思うし、Ovis2と同じく軽量OCRとして十分使えそう。
おまけで縦書きも試してみた。青空文庫の「走れメロス」の冒頭部分。
メロスは激怒した。必ず、かの邪智暴虐の王を除かなければならぬと決意した。メロスには政治がわからぬ。メロスは、村の牧人である。笛を吹き、羊と遊んで暮して来た。けれども邪悪に対しては、人一倍に敏感であった。きょう未明メロスは村を出発し、野を越え山越え、十里はなれた此のシラクスの市にやって来た。メロスには父も、母も無い。女房も無い。十六の、内気な妹と二人暮しだ。この妹は、村の或る律気な一牧人を、近々、花婿として迎える事になっていた。結婚式も間近かなのである。メロスは、それゆえ、花嫁の衣裳やら祝宴の御馳走やらを買いに、はるばる市にやって来たのだ。先ず、その品々を買い集め、それから都の大路をぶらぶら歩いた。メロスには竹馬の友があった。セリヌンティウスである。今は此のシラクスの市で、石工をしている。その友を、
これをゴニョゴニョして縦書き画像にして読み込ませてみた結果。
generation_config = dict(max_new_tokens=1024, do_sample=False)
pixel_values = load_image('yokogaki.png', max_num=12).to(torch.bfloat16).cuda()
question = '<image>\nこの画像に書かれていることを書いて。'
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
この画像には、メロスが激怒した政治的事件についての記述があります。メロスは、内気な妹と二人暮らしの村の牧人である母親を邪悪に攻撃し、妹の結婚式を近所から集まりに買い占める事件を起こしています。また、メロスは花嫁の衣装や祝宴の御馳走を買って来ていたと述べています。この事件は、メロスの激怒の原因となっています。
question = 'メロスはどの場所に行った?'
response, history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
history=history,
return_history=True
)
print(f'ユーザ: {question}\nアシスタント: {response}')
メロスは、この事件の起こりの場所は不明ですが、妹の結婚式を近所から集まりに買い占める事件が起こった村の近くにいることがわかります。
んー、字面だけで判断しているんじゃないかな。文章として読んで理解しているようには思えないかな。
ただ、先日 llama.cpp で llama-server がマルチモーダルに対応して、対応モデルにInternVL3が含まれている(量子化済みモデルも公開されている)ため、こちらのほうが使い勝手が良さそう(Ovisは残念ながらllama.cppで対応していない)
ということで、llama.cppのサーバで使ってみる。以下で簡単に使い方を書いている。
量子化モデルが使えるのでちょっと大きめの8Bを使ってみる。(モデルダウンロードには時間がかかる・・・)
./build/bin/llama-server -hf ggml-org/InternVL3-14B-Instruct-GGUF
ではGUIで試す

やはり日本語の知識はあまりなさそう。
次。
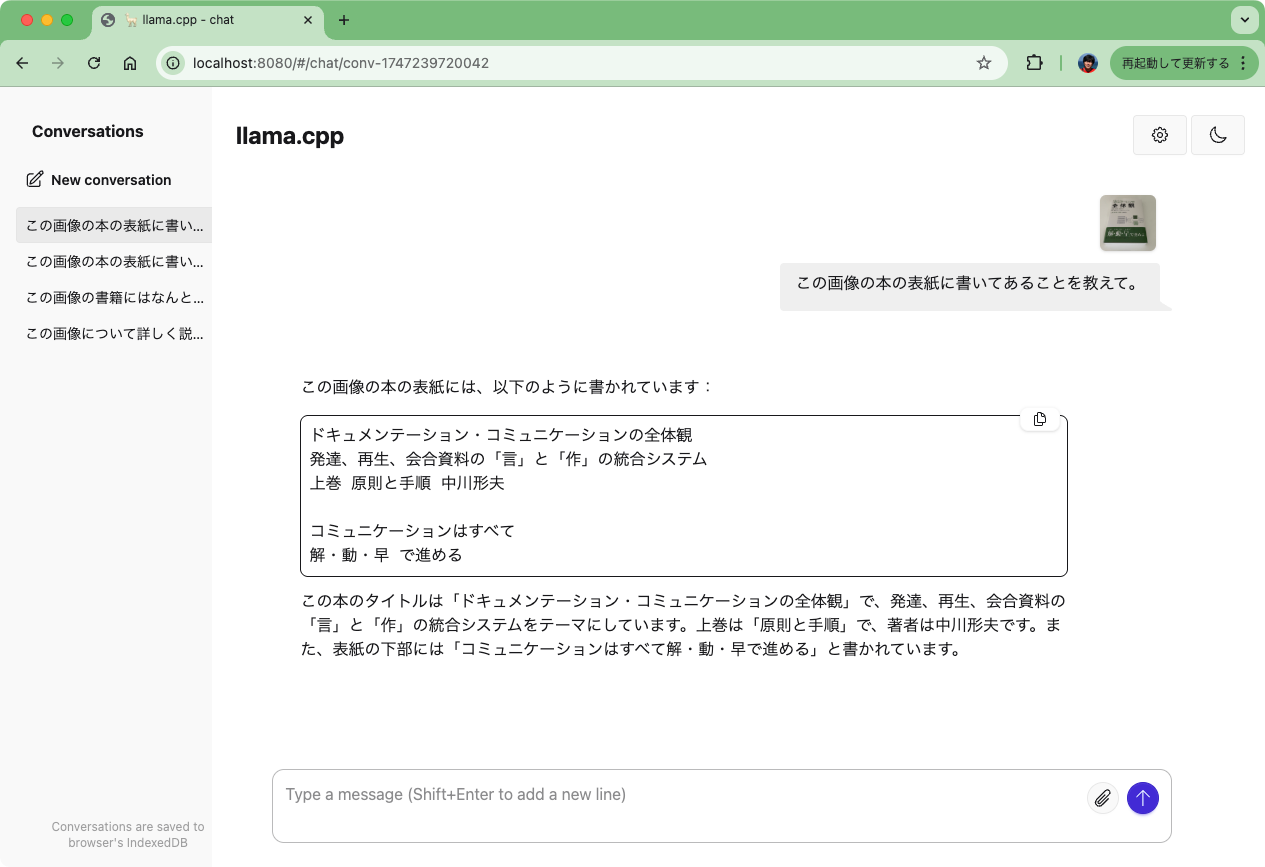
文字の読み取りはかなり正確。
8Bを試してみたけど、モデルサイズが上がっても日本の知識についてはあまりないみたい。あと文字の読み取りは2Bと同じく正確なんだけども、回答が壊れてしまったりする場合もあって、ちょっと安定しないかな。ただこちらは量子化の影響もあるとは思う。
地味にこの辺は重要かも
さらにツール使用、GUI エージェント、産業用画像解析、3 D ビジョン認識などへとマルチモーダル機能を拡張しています。