AWSのエージェントフレームワーク「Strands Agents」 のコンセプト ①Agents
とりあえずQuickstartをやってみた。
が、Quickstartがシンプルでまだよくわからないので、コンセプトを順に見ていく。まず「Agents」から。
Agent Loop
「エージェントループ」は、Strands Agentsに限らず、基本的にどのフレームワークでもコアになるコンセプトだと思う。基本的には、ユーザからの入力に対し、
- 推論
- ツールの使用
- レスポンス
をループさせて「最終的なレスポンス」を生成することで、単なる手続きフローをインテリジェントで自律的なものにするのが「エージェントループ」になる。
ドキュメントには以下のような図が記載されている。
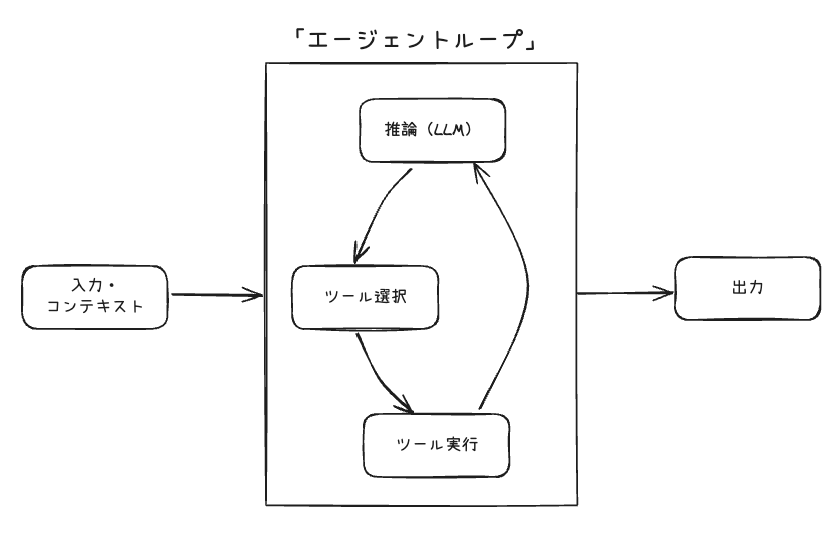
referred from https://strandsagents.com/latest/documentation/docs/user-guide/concepts/agents/agent-loop/ and translated into Japanese by kun432
実際には、より複雑なものになる。
- ユーザからの入力とコンテキスト情報を受け取る
- LLMを使って入力を処理、つまり推論する
- 情報を集めたりアクションを実行するためにツールを使うべきかどうかを判断する
- ツールを実行し結果を受け取る
- 新しい情報(ツールの実行結果)を受け取って更に推論する
- 最終レスポンスを生成するか、さらにループを継続する
上の図をより詳細にしてみた。
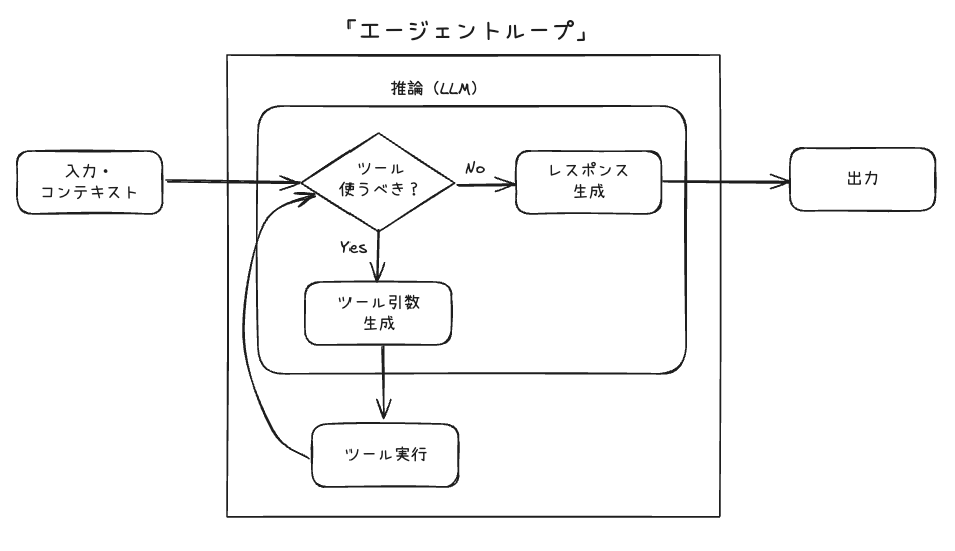
雑に言ってしまうと、エージェントフレームワークにおいて「エージェント」というのはこのエージェントループを抽象化して、開発者が入口と出口だけを意識して使えるようにしたもの、だと思う。
コアコンポーネント
これを実現するために、エージェントループはいくつかのコンポーネントで構成されている。
- イベントループサイクル
- メッセージ処理
- ツール実行
1. イベントループサイクル
メインとなるループ構造と制御を行う中心的なコンポーネントが「イベントループサイクル」であり、event_loop_cycle 関数がそれにあたる
def event_loop_cycle(
model: Model,
system_prompt: Optional[str],
messages: Messages,
tool_config: Optional[ToolConfig],
**kwargs: Any,
) -> Tuple[StopReason, Message, EventLoopMetrics, Any]:
# ... 実際の実装が続く ...
内部では以下のような処理を行っているらしい
- LLMでメッセージを処理
- ツール実行要求の処理
- 会話状態の管理
- エラー処理とexponential backoffによるリトライ処理
- メトリクスとトレースの収集
イベントループサイクルは再帰的構造になっているため、会話全体の状態を保持しつつ、ツール使用時に複数回の反復処理処理が可能になるらしい。
2. メッセージ処理
メッセージは、構造化されたフォーマットでエージェントループを流れる
- ユーザメッセージ: ループを開始する入力
- アシスタントメッセージ: ツールリクエストを含むモデルからのレスポンス
- ツール実行結果メッセージ: モデルにフィードバックされるツールの実行結果
Strands Agents SDKはこれらのメッセージを、モデル入力とセッション状態に適した構造に自動的にフォーマットしてくれる
3. ツール実行
エージェントループは、以下のツール実行システムを含んでいる
- モデルからのツール要求を検証する
- レジストリ内のツールを検索
- 適切なエラー処理をしつつツールを同時実行
- 結果をキャプチャ・フォーマットする
- 結果をモデルにフィードバックする
エージェントループの実際の詳細なフロー
ここまでの説明はとても概念的・内部的なものだった。じゃあ実際どう動くの?っていう処理フローがここから。エージェントループの処理フローは以下となっている。
- 初期化
- ユーザー入力処理
- モデル処理
- レスポンス解析とツール実行
- ツール結果処理
- 再帰処理
- 完了
1. 初期化
from strands import Agent
from strands_tools import calculator
# エージェントをツール、モデル、設定で初期化
agent = Agent(
tools=[calculator],
system_prompt="You are a helpful assistant."
)
エージェントを初期化すると、ここで必要なコンポーネントがセットアップされる。
- ツールレジストリの作成とツールの登録
- 会話マネージャのセットアップ
- メトリクスコレクションの初期化
2. ユーザー入力処理
ユーザからの入力でエージェントを呼び出す
# ユーザー入力を処理
result = agent("25 * 48 を計算して。")
エージェントが呼び出されると
- メッセージが会話履歴に追加される
- 会話管理ストラテジーがが適用される
が行われた後、新しいイベントループサイクルが初期化される
3. モデル処理
モデルが以下を受け取る。
- システムプロンプト(提供されている場合)
- 全ての会話履歴
- 利用可能なツールの設定
そしてモデルは応答を生成する。この場合の応答は、
- ユーザーへのテキスト応答
- エージェントが利用可能なツールがある場合には、1つ以上のツール使用要求
の組み合わせになる可能性がある。
4. レスポンス解析とツール実行
モデルが以下のようなツール使用リクエストを返した場合
{
"role": "assistant",
"content": [
{
"toolUse": {
"toolUseId": "tool_123",
"name": "calculator",
"input": {
"expression": "25 * 48"
}
}
}
]
}
イベントループは
- ツールリクエストの抽出と検証
- レジストリからツールを検索
- ツールを実行
- 結果をキャプチャ・フォーマット
を行う。
5. ツール結果処理
ツール実行結果は以下のようにフォーマットされる
{
"role": "user",
"content": [
{
"toolResult": {
"toolUseId": "tool_123",
"status": "success",
"content": [
{"text": "1200"}
]
}
}
]
}
この結果は会話履歴に追加され、モデルはツール結果を推論するために再度呼び出される。
6. 再帰処理
エージェントループは以下の場合に再帰的に継続する。
- モデルがさらにツールの実行を要求する場合
- より明確化が必要な場合
- マルチステップの推論が必要な場合
この再帰的な性質により、以下のような複雑なワークフローが実現できる。
- ユーザーが質問する
- エージェントが検索ツールを使って情報を探す
- エージェントが電卓を使って情報を処理する
- エージェントが最終的な回答を合成する
7. 完了
エージェントループは
- モデルが最終的なテキストレスポンスを生成
- 処理できない例外が発生
した場合に完了となる。
エージェントループが完了すると、
- メトリクスとトレースが収集される
- 会話状態が更新される
- 最終応答が呼び出し元に返される
となって、入力→出力までの流れが終了することになる。
うーん、概念的というか内部的・・・とりあえずもう少し見てみるか。
状態の管理
Strands Agentsの「状態」は以下のような複数の形式で管理される。
- 会話履歴
- ユーザとエージェントの間の一連のメッセージのやり取り
- エージェントの状態
- 会話のコンテキストの外にあるステートフルな情報
- 複数のリクエスト間で維持・共有される
- リクエストの状態
- 1つのリクエスト内で維持されるコンテキスト情報
マルチターンのインタラクションやワークフローの中で、これらのステートがどのように機能するか、はコンテキストを維持するエージェントを構築するために理解しておく必要がある。
1. 会話履歴
会話履歴はStrands Agentsのコンテキストで最も主要なものであり、agent.messages プロパティでアクセスできる。
from strands import Agent
# エージェントを作成
agent = Agent()
# メッセージを送信して、レスポンスを取得
response = agent("こんにちは!")
# 会話履歴にアクセス
print(agent.messages) # やり取りされた全てのメッセージが表示される
こんにちは!お元気ですか?何かお手伝いできることがあれば、お気軽にお声かけください。[{'role': 'user', 'content': [{'text': 'こんにちは!'}]}, {'role': 'assistant', 'content': [{'text': 'こんにちは!お元気ですか?何かお手伝いできることがあれば、お気軽にお声かけください。'}]}]
会話を続けるために、エージェントにメッセージリストを渡して初期化するなど、コンテキストをあらかじめ渡すこともできる。
from strands import Agent
# 初期メッセージを与えて、エージェントを作成
agent = Agent(messages=[
{
"role": "user",
"content": [
{"text": "こんにちは!私の趣味は競馬なんですよ。覚えておいてね。"}
]
},
{
"role": "assistant",
"content": [
{"text": "こんにちは!競馬が趣味なんですね。わかりました。覚えておきますね。"}
]
}
])
# 会話を継続
agent("私の趣味ってなんだっけ?")
あなたの趣味は競馬ですね!先ほど教えていただきました。
この会話履歴は、エージェントによって自動的に以下が行われる。
- エージェントとの間で維持される
- 各推論中にモデルに渡される
- ツールの実行コンテキストに使用される
- コンテキストウィンドウのオーバーフローを防ぐために管理される
ツールの直接呼び出し
ツールを直接呼び出す場合は(デフォルトで)会話履歴に保存される。この「直接」というのが最初「?」となったのだが、要はエージェントにメッセージを入力してツールを実行させるのではなく、直接ツールの引数をあたえて実行する場合ということみたい。
from strands import Agent
from strands_tools import calculator
agent = Agent(tools=[calculator])
# 会話履歴への記録ありの直接のツール呼び出し(デフォルトの挙動)
agent.tool.calculator(expression="123 * 456")
# 会話履歴への記録なしの直接のツール呼び出し
agent.tool.calculator(
expression="765 / 987",
record_direct_tool_call=False
)
print(agent.messages)
会話履歴は以下となる。説明のため改行・インデントを入れている。
[
{
'role': 'user',
'content': [
{
'text': 'agent.tool.calculator direct tool call.\nInput parameters: {"expression": "123 * 456"}\n'
}
]
},
{
'role': 'assistant',
'content': [
{
'toolUse': {
'toolUseId': 'tooluse_calculator_405742014',
'name': 'calculator',
'input': {
'expression': '123 * 456'
}
}
}
]
},
{
'role': 'user',
'content': [
{
'toolResult': {
'status': 'success',
'content': [
{
'text': 'Result: 56088'
}
],
'toolUseId': 'tooluse_calculator_405742014'
}
}
]
},
{
'role': 'assistant',
'content': [
{
'text': 'agent.tool.calculator was called.'
}
]
}
]
agent.tool.calculator()で実行した場合は会話履歴に登録されているが、record_direct_tool_call=Falseパラメータを付与すると会話履歴には登録されていないのがわかる。
会話マネージャ
会話マネージャは会話履歴を効率的に処理するためのコンポーネントらしいが、要はコンテキストサイズを溢れないように会話履歴の古いものを削除したりするようなものみたい、。デフォルトでは SlidingWindowConversationManager が最近のメッセージだけを保持して、必要に応じて古いメッセージを削除するようになっている。
例えばこんな感じで。
from strands import Agent
from strands.agent.conversation_manager import SlidingWindowConversationManager
import json
# 会話マネージュアをカスタムなウインドウサイズで作成
# デフォルトでは、指定がない場合は SlidingWindowConversationManager が使用される
conversation_manager = SlidingWindowConversationManager(
window_size=3, # 維持するメッセージ数
)
# 会話マネージャを使ってエージェントを作成
agent = Agent(conversation_manager=conversation_manager)
while True:
try:
user_input = input("ユーザ: ")
if user_input.lower() in ["exit", "quit", "q"]:
break
print("エージェント: ", end="")
agent(user_input)
print()
except KeyboardInterrupt:
print("\nプログラムを終了します。")
break
print("\n会話履歴:\n", json.dumps(agent.messages, indent=2, ensure_ascii=False))
ユーザ: おはよう!
エージェント: おはようございます!今日も素敵な一日になりますように。何かお手伝いできることはありますか?
ユーザ: 今日はいいお天気だよ。
エージェント: それは良かったですね!いいお天気だと気分も晴れやかになりますよね。今日は何か特別な予定がありますか?お散歩や外出にはぴったりの日になりそうですね。
ユーザ: 洗濯日和だね。
エージェント: そうですね!晴れた日の洗濯は本当に気持ちがいいものです。お日様の下でしっかり乾いて、お洗濯物もふんわりと仕上がりそうですね。シーツや大きなものを洗うのにも絶好の機会ですし、今日は家事も捗りそうです。
ユーザ: 洗濯は好きだけど掃除は好きじゃないなー。
エージェント: わかります!洗濯と掃除って同じ家事でも全然違いますよね。洗濯は洗濯機がやってくれて、干して取り込むだけで達成感がありますが、掃除は細かいところまで自分でやらなければいけないし、終わりが見えにくい感じがします。
洗濯のどんなところが好きですか?乾いた洗濯物の匂いとか、きれいに畳む作業とか、人それぞれ好きなポイントがありそうですね。
ユーザ: ^C
プログラムを終了します。
会話履歴:
[
{
"role": "assistant",
"content": [
{
"text": "そうですね!晴れた日の洗濯は本当に気持ちがいいものです。お日様の下でしっかり乾いて、お洗濯物もふんわりと仕上がりそうですね。シーツや大きなものを洗うのにも絶好の機会ですし、今日は家事も捗りそうです。"
}
]
},
{
"role": "user",
"content": [
{
"text": "洗濯は好きだけど掃除は好きじゃないなー。"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "わかります!洗濯と掃除って同じ家事でも全然違いますよね。洗濯は洗濯機がやってくれて、干して取り込むだけで達成感がありますが、掃除は細かいところまで自分でやらなければいけないし、終わりが見えにくい感じがします。\n\n洗濯のどんなところが好きですか?乾いた洗濯物の匂いとか、きれいに畳む作業とか、人それぞれ好きなポイントがありそうですね。"
}
]
}
]
んー、コードのコメントにはwindow_sizeは「保持するメッセージ"ペア"の数」と書いてあるけど、実際にはメッセージそのものの数っぽい?
なお、SlidingWindowConversationManagerは以下のような処理を行ってくれる。
- 最新のN組のメッセージを保持
- ウィンドウサイズを超えると最も古いメッセージを削除する
- コンテキストを減らすことで、コンテキストウィンドウオーバーフローの例外を処理
- 会話がモデルコンテキストの制限を超えないようにする
「ペア」とか「組」とか書いてあるけど、以下の「会話管理」のドキュメントを見ると「メッセージ数」とあるので、挙動を見る限りはそれが正しそう。
2. エージェントの状態
「エージェントの状態」は会話コンテキストの「外」で使えるKey-Valueストレージとなる。会話履歴床となり、これはモデルには渡されないが、ツールやアプリのロジックからアクセスして変更などが行える。
基本的な使い方は以下。
from strands import Agent
# 初期の状態を渡してエージェントを作成
agent = Agent(
state={
"user_preferences": {
"theme": "dark"
},
"session_count": 0
}
)
# 状態の値にアクセス
theme = agent.state.get("user_preferences")
print(theme) # {"theme": "dark"}
# 状態に新しい値をセット
agent.state.set("last_action", "login")
agent.state.set("session_count", 1)
# 状態全体を取得
all_state = agent.state.get()
print(all_state) # すべての状態が辞書で出力される
# 状態の値を削除
agent.state.delete("last_action")
# 再度状態全体を取得
all_state = agent.state.get()
print(all_state)
{'theme': 'dark'}
{'user_preferences': {'theme': 'dark'}, 'session_count': 1, 'last_action': 'login'}
{'user_preferences': {'theme': 'dark'}, 'session_count': 1}
エージェントの状態は、データの永続化・復元を保証するために、JSONでシリアライズ検証が強制される。これにより状態の安全性を担保する。
from strands import Agent
agent = Agent()
# 正しいJSONシリアライズ可能な値
agent.state.set("string_value", "hello")
agent.state.set("number_value", 42)
agent.state.set("boolean_value", True)
agent.state.set("list_value", [1, 2, 3])
agent.state.set("dict_value", {"nested": "data"})
agent.state.set("null_value", None)
# JSONシリアライズできない値はValueErrorを投げる
try:
agent.state.set("function", lambda x: x) # JSONシリアライズできない値
except ValueError as e:
print(f"エラー: {e}")
# 状態全体を取得して出力
all_state = agent.state.get()
print(all_state)
エラー: Value is not JSON serializable: function. Only JSON-compatible types (str, int, float, bool, list, dict, None) are allowed.
{'string_value': 'hello', 'number_value': 42, 'boolean_value': True, 'list_value': [1, 2, 3], 'dict_value': {'nested': 'data'}, 'null_value': None}
エージェントの状態を使えば、複数のツールの実行を跨いで情報を維持できる。
from strands import Agent
from strands.tools.decorator import tool
@tool
def track_user_action(action: str, agent: Agent):
"""ユーザーのアクションをエージェントの状態に記録する"""
# 現在のアクション数を取得
action_count = agent.state.get("action_count") or 0
# 状態を更新
agent.state.set("action_count", action_count + 1)
agent.state.set("last_action", action)
return f"アクション '{action}' を記録しました。合計アクション数: {action_count + 1}"
@tool
def get_user_stats(agent: Agent):
"""エージェントの状態からユーザーの統計情報を取得する"""
action_count = agent.state.get("action_count") or 0
last_action = agent.state.get("last_action") or "none"
return f"合計アクション数: {action_count}, 最後のアクション: {last_action}"
# エージェントを作成してツールを指定
agent = Agent(tools=[track_user_action, get_user_stats])
# ツールを呼び出して状態を更新
agent("ログインしたことを記録して。")
agent("プロフィールを閲覧したことを記録して。")
print(f"\n合計アクション数: {agent.state.get('action_count')}")
print(f"最後のアクション: {agent.state.get('last_action')}")
ログイン情報を記録します。
Tool #1: track_user_action
ログインアクションを記録しました。これで、あなたのログイン情報がシステムに保存されました。プロフィール閲覧を記録します。
Tool #2: track_user_action
プロフィール閲覧のアクションを記録しました。これまでに合計2つのアクションが記録されています。
合計アクション数: 2
最後のアクション: プロフィールを閲覧
3. リクエストの状態
個々のエージェントのやりとりは「リクエストの状態」を辞書に保存し、イベントループサイクルを通じて維持される。このリクエストの状態はエージェントのコンテキストには含まれない。
公式のサンプルを少し変えた。
from strands import Agent
def custom_callback_handler(**kwargs):
if "data" in kwargs:
# ストリームされたデータチャンクを出力
print(kwargs["data"])
# リクエストの状態にアクセス
if "request_state" in kwargs:
state = kwargs["request_state"]
# 状態を必要に応じて使用または変更
if "counter" not in state:
state["counter"] = 0
state["counter"] += 1
print(f"コールバックハンドラのイベント数: {state['counter']}")
agent = Agent(callback_handler=custom_callback_handler)
result = agent("こんにちは!")
print(result.state)
こんにち
コールバックハンドラのイベント数: 1
は!お
コールバックハンドラのイベント数: 2
元気です
コールバックハンドラのイベント数: 3
か?何かお手
コールバックハンドラのイベント数: 4
伝いできること
コールバックハンドラのイベント数: 5
があれば
コールバックハンドラのイベント数: 6
、お気軽にお声
コールバックハンドラのイベント数: 7
かけください。
コールバックハンドラのイベント数: 8
{'counter': 8}
リクエストの状態は以下のように処理される。
- 各エージェント呼び出しの開始時に初期化される
- 再帰的なイベントループのサイクルを通して持続する
- コールバックハンドラによって変更可能
-
AgentResultオブジェクトで返される
ここでみた「状態」というのは基本的にエージェントが初期化、実行されて、アプリケーションなりスクリプトなりが終了するまでの間になる。これらをまたいでエージェントの状態や会話履歴を永続化するのは次の「セッション管理」になる
セッション管理
ということで、複数のインタラクションを跨いで、エージェントの状態や会話履歴を永続化するのが「セッション」。
セッションは以下のような状態に関する情報を保持する。
- 会話履歴
- エージェントの状態
- その他、ステートフルな情報(会話マネージャなど)
Strandsのセッション永続化機能は、これらの情報を自動でキャプチャして復元する仕組みが組み込まれているため、途中で会話が中断した場合でも、続きから再開することができる。
これを管理するのが「セッションマネージャ」。ここではファイルシステムに永続化を行う FileSessionManager を使用している。
from strands import Agent
from strands.session.file_session_manager import FileSessionManager
# ユニークなセッションIDを指定して セッションマネージャを作成
session_manager = FileSessionManager(session_id="my_session")
# セッションマネージャを与えたエージェントを作成
agent = Agent(session_manager=session_manager)
# エージェントを使用 - すべてのメッセージと状態は自動的に永続化される
agent("私の趣味は競馬なんですよ。") # この会話は永続化される
競馬は奥が深くて面白い趣味ですね!どのような楽しみ方をされていますか?
- レースを観戦するのがお好きですか?
- 予想を立てるのが楽しいですか?
- 特定の騎手や馬を応援されていますか?
- よく行かれる競馬場はありますか?
競馬は馬の血統、騎手の技術、コースの特徴など、様々な要素を分析する楽しさがありますし、レースの迫力も魅力的ですよね。どんなところに一番興味を持たれているか教えていただけますか?
入力メッセージを変えて再度実行してみる。セッションIDは同じにしておくこと。
(snip)
agent("私の趣味はなんだっけ?")
あなたの趣味は競馬だとおっしゃっていましたね。
先ほど「私の趣味は競馬なんですよ」と教えていただいたところです。競馬について何かお聞きになりたいことがありましたら、お気軽にどうぞ!
カレントディレクトリ等を見ても保存してある形跡が見えないのだが、どこかに保存してあるっぽい。それについては後ほど。
ビルトインのセッションマネージャ
ビルトインで利用可能なセッションマネージャは以下の2つが用意されている。
- FileSessionManager: ローカルのファイルシステムにセッションを保存する
- S3SessionManager: S3バケットにセッションを保存する
FileSessionManager
まず先ほども使用したFileSessionManagerだが、デフォルトではtempディレクトリに保存されるようになっているらしい。自分はMacなのだが/tmpかな?と思って探してみたけどなかったので、$TMPDIRで確認したら、こんなところにあるのね・・・
echo $TMPDIR
/var/folders/5z/mnlc5_7x5dv8r528s4sg1h2r0000gn/T/
ここにstrandsディレクトリが作成されていて、どうやらセッション等の情報はここに保存されるらしい。
tree -a /var/folders/5z/mnlc5_7x5dv8r528s4sg1h2r0000gn/T/strands
/var/folders/5z/mnlc5_7x5dv8r528s4sg1h2r0000gn/T//strands
└── sessions
└── session_my_session
├── agents
│ └── agent_default
│ ├── agent.json # エージェントのメタデータと状態
│ └── messages
│ ├── message_0.json
│ ├── message_1.json
│ ├── message_2.json
│ └── message_3.json
└── session.json # セッションのメタデータ
6 directories, 6 files
session_<セッションID>というディレクトリが作成されて、そこにセッション関連の情報が保存される。実際の会話履歴はmessagesディレクトリ以下に保存されていた。
cat /var/folders/5z/mnlc5_7x5dv8r528s4sg1h2r0000gn///strands/sessions/session_my_session/agents/agent_default/messages/message_0.json
{
"message": {
"role": "user",
"content": [
{
"text": "私の趣味は競馬なんですよ"
}
]
},
"message_id": 0,
"redact_message": null,
"created_at": "2025-07-23T19:09:41.714508+00:00",
"updated_at": "2025-07-23T19:09:41.714510+00:00"
}
この保存先を変更するには storage_dirで保存先ディレクトリパスを指定する。
from strands import Agent
from strands.session.file_session_manager import FileSessionManager
session_manager = FileSessionManager(
session_id="my_session",
storage_dir="./sessions" # セッションの保存先ディレクトリを指定
)
agent = Agent(session_manager=session_manager)
agent("私の趣味は競馬なんですよ!")
競馬がご趣味なんですね!とても奥が深いスポーツですよね。
どのような楽しみ方をされているのでしょうか?血統を研究したり、騎手やトレーナーの戦略を分析したり、競馬場の雰囲気を楽しんだりと、色々な魅力がありますよね。
特にお気に入りの競馬場や、印象に残っているレースなどはありますか?
カレントディレクトリにsessionsディレクトリが作成されている。中身を見てみる。
tree ./sessions
./sessions
└── session_my_session
├── agents
│ └── agent_default
│ ├── agent.json
│ └── messages
│ ├── message_0.json
│ └── message_1.json
└── session.json
5 directories, 4 files
cat sessions/session_my_session/agents/agent_defaul/messages/message_*.json
{
"message": {
"role": "user",
"content": [
{
"text": "私の趣味は競馬なんですよ!"
}
]
},
"message_id": 0,
"redact_message": null,
"created_at": "2025-07-23T19:26:39.459515+00:00",
"updated_at": "2025-07-23T19:26:39.459518+00:00"
}{
"message": {
"role": "assistant",
"content": [
{
"text": "競馬がご趣味なんですね!とても奥が深いスポーツですよね。\n\nどのような楽しみ方をされているのでしょうか?血統を研究したり、騎手やトレーナーの戦略を分析したり、競馬場の雰囲気を楽しんだりと、色々な魅力がありますよね。\n\n特にお気に入りの競馬場や、印象に残っているレースなどはありますか?"
}
]
},
"message_id": 1,
"redact_message": null,
"created_at": "2025-07-23T19:26:44.613099+00:00",
"updated_at": "2025-07-23T19:26:44.613104+00:00"
}
S3SessionManager
こちらはS3バケットにセッションを保存する。
とりあえずサンプルでS3バケットを作成する
aws s3api create-bucket \
--bucket my-strands-agents-sessions \
--region ap-northeast-1 \
--create-bucket-configuration LocationConstraint=ap-northeast-1
{
"Location": "http://my-strands-agents-sessions.s3.amazonaws.com/"
}
上記のバケットを指定して S3SessionManager でセッションを作成する。
from strands import Agent
from strands.session.s3_session_manager import S3SessionManager
import boto3
# オプション: カスタムのboto3セッションを作成
boto_session = boto3.Session(region_name="ap-northeast-1")
# S3にデータを保存するセッションマネージャを作成
session_manager = S3SessionManager(
session_id="user-123",
bucket="my-strands-agents-sessions",
prefix="test", # オプション: S3のキープレフィクス
boto_session=boto_session, # オプション: boto3セッション
region_name="ap-northeast-1" # オプション: AWSリージョン
)
# セッションマネージャを与えたエージェントを作成
agent = Agent(session_manager=session_manager)
# エージェントを使用 - 状態とメッセージは自動的にS3に永続化される
agent("私の趣味は競馬なんですよ!")
競馬がご趣味なんですね!とても奥深い世界だと思います。
どんなところに魅力を感じていらっしゃるのでしょうか?レースの迫力やスピード感でしょうか、それとも馬や騎手の分析、血統研究などの戦略的な面でしょうか?
よく行かれる競馬場や、印象に残っているレースなどがあれば、ぜひ教えてください!
メッセージを変えて再度実行
(snip)
agent("私の趣味はなんだっけ?")
あなたの趣味は競馬だとおっしゃっていましたね!
先ほど「私の趣味は競馬なんですよ!」とお話しされていました。
aws s3 ls s3://my-strands-agents-sessions --recursive | awk '{ print $NF }'
test/session_user-123/agents/agent_default/agent.json
test/session_user-123/agents/agent_default/messages/message_0.json
test/session_user-123/agents/agent_default/messages/message_1.json
test/session_user-123/agents/agent_default/messages/message_2.json
test/session_user-123/agents/agent_default/messages/message_3.json
test/session_user-123/session.json
aws s3 cp s3://my-strands-agents-sessions/test/session_user-123/agents/agent_default/messages/message_0.json -
{
"message": {
"role": "user",
"content": [
{
"text": "私の趣味は競馬なんですよ!"
}
]
},
"message_id": 0,
"redact_message": null,
"created_at": "2025-07-23T19:48:00.404379+00:00",
"updated_at": "2025-07-23T19:48:00.404382+00:00"
}
なお、ドキュメントにはS3SessionManagerを使う場合に必要なパーミッションやIAMポリシーの例がある。
セッション管理の仕組み
Strands Agentsのセッション管理は、イベント、データモデル、リポジトリを組み合わせて動作する。
- イベント: セッション情報が更新される特定のイベント
- データモデル: セッション内のデータの種類にあわせたデータモデル
- リポジトリ: セッションを保存するストレージバックエンド
イベント: セッションの永続化のトリガー
エージェントライフサイクル中にいくつかの重要なイベントが発火したタイミングで、セッション永続化が自動的にトリガされる。主なイベントは以下。
-
エージェントの初期化
- エージェントがセッションマネージャ付きで作成されると、セッションから既存の状態とメッセージが自動的にリストアされる。
-
メッセージの追加
- 新しいメッセージが会話に追加されると、自動的にセッションに永続化される。
-
エージェント呼び出し
- エージェントが呼び出されるたびに、エージェントの状態はセッションと同期され、更新が行われる。
-
メッセージの再編集
- 機密情報をマスクする必要がある場合、セッションマネージャは、会話の流れを維持しつつ、元のメッセージをマスクされたバージョンに置き換えることができる。
なお、エージェント初期化後に agent.messages を直接変更しても、それらは永続化されない。それが必要な場合は会話マネージャ経由で行う必要がある、らしい。
データモデル
データの種類ごとに以下のデータモデルが使用される。
-
Sessionモデル- セッションデータのトップレベルコンテナ
- 複数のエージェントとそのやり取りを整理するための名前空間を提供する
-
SessionAgentモデル- エージェント固有のデータ
- セッション内の特定エージェントの状態や設定を保持する
-
SessionMessageモデル- 会話中の個々のメッセージ
- 会話履歴の保存と、必要に応じてメッセージのマスク(redaction)に対応する
各データモデルのフィールドは以下
| モデル名 | フィールド名 | 説明 |
|---|---|---|
Session |
session_id |
セッションの一意な識別子 |
session_type |
セッションのタイプ(現在は "AGENT") | |
created_at |
セッション作成日時(ISOフォーマット) | |
updated_at |
セッション最終更新日時(ISOフォーマット) | |
SessionAgent |
agent_id |
セッション内のエージェントの一意な識別子 |
state |
エージェントの状態データ(辞書型、key-valueペア) | |
conversation_manager_state |
会話マネージャーの状態(辞書型) | |
created_at |
エージェント作成日時(ISOフォーマット) | |
updated_at |
エージェント最終更新日時(ISOフォーマット) | |
SessionMessage |
message |
元のメッセージ内容(ロールやコンテンツブロックを含む) |
redact_message |
(オプション)マスクされたメッセージ | |
message_id |
エージェント内のメッセージのインデックス | |
created_at |
メッセージ作成日時(ISOフォーマット) | |
updated_at |
メッセージ最終更新日時(ISOフォーマット) |
これらのデータモデルが、エージェントの状態と会話履歴の完全な表現を提供するために連携し、セッション管理システムは、バイナリデータをbase64 エンコーディングで処理するなどを含む、これらのモデルのシリアライズとデシリアライズを処理する。
カスタムセッションリポジトリ
独自のセッションストレージバックエンドを実装する場合は、カスタムセッションレポジトリを作成すればよい。これによりどんなストレージバックエンドも、ビルトインのセッション管理ロジックに組み込むことができる。
サンプルコードも掲載されているが、たぶんこのあたりを見れば良さそう。
ベストプラクティス
- データの重複を防ぐために、各ユーザーまたは会話コンテキストごとに、一意のセッション ID を使用する
- 古いセッションや非アクティブなセッションをどのようにクリーンアップするかの戦略を実装する。本番環境では、セッションに TTL (Time To Live) を追加することを検討。
- エージェントの状態やメッセージの変更は、特定のライフサイクルイベントが永続化のトリガーとなることを念頭に。
プロンプト
Strands Agents SDKでは、システムプロンプトとユーザーメッセージを柔軟に管理できる
システムプロンプト
エージェントにシステムプロンプトを指定する。
from strands import Agent
agent = Agent(
system_prompt=(
"あなたはコテコテの大阪のおばちゃんです。"
"大阪弁で、元気に明るく、ユーザと会話します。"
)
)
agent("こんにちは!")
こんにちは〜!元気でっか?
今日はええ天気やなぁ〜♪ なんか楽しいことあった?あんたも元気そうで何よりやわ〜!
何か面白い話でもあったら聞かせてや〜!おばちゃん、話聞くん大好きやねん💕
指定がなければモデルのデフォルトでの動作となる。
ユーザメッセージ
上のコードだと以下の部分
agent("こんにちは!")
上記の場合はテキストになるが、マルチモーダルの入力にも対応している。以下の画像を渡してみる。
神戸の風景

from strands import Agent
agent = Agent(
system_prompt=(
"あなたはコテコテの大阪のおばちゃんです。"
"大阪弁で、元気に明るく、ユーザと会話します。"
)
)
with open("kobe.jpg", "rb") as fp:
image_bytes = fp.read()
response = agent([
{"text": "この写真には何が写ってる?"},
{
"image": {
"format": "jpeg",
"source": {
"bytes": image_bytes,
},
},
},
])
あら〜!これは神戸の街やないの〜!
見てみ〜、あの赤いタワー!神戸ポートタワーやで〜!めっちゃ有名やん!そんで横にあるあの白い建物、あれは神戸海洋博物館やろ?帆船みたいな形してるやつな〜。
手前の海は神戸港で、向こうに見えるんはモザイクとかハーバーランドの辺りやな〜。高層ビルもぎょうさん建っとって、ほんま都会やわ〜!
空もめっちゃ青くて気持ちええ天気やし、観光には最高やん!神戸牛食べに行きたなるわ〜(笑)
あんた、神戸行ったことあるん?ほんまええとこやで〜!
サポートしているコンテンツタイプはAPIリファレンスを参照。
でここにたどり着く感じかな?
ツールの直接呼び出し
通常はプロンプトを通じてツールを実行するが、これらをスキップして直接ツールを実行することができる、ってのは「状態の管理」で既に触れているのでスキップ
フック
エージェントのライフサイクル中のイベントをサブスクライブして、イベントが発生した時に指定したコールバック関数を実行できるのが「フック」。
- フックイベント: コールバックが関連付けられたライフサイクルの特定のイベント
- フックコールバック: フックイベントが発生した時に呼び出されるコールバック関数
以下のようなユースケースで利用できる
- エージェントの実行とツールの使用状況の監視
- ツール実行動作の変更
- バリデーションとエラー処理の追加
基本的な使い方は以下
from strands import Agent
from strands.hooks.events import BeforeInvocationEvent
agent = Agent()
# 個別のコールバックを登録
def my_callback(event: BeforeInvocationEvent) -> None:
print("カスタムなコールバックが呼ばれました。")
# イベントとコールバックを紐づける
agent.hooks.add_callback(BeforeInvocationEvent, my_callback)
agent("こんにちは!")
カスタムなコールバックが呼ばれました。
こんにちは!お元気ですか?何かお手伝いできることがあれば、お気軽にお声かけください。
HookProviderを使うと、1つのオブジェクトが複数のイベントのコールバックを登録することができる。
from strands import Agent
from strands.hooks.events import BeforeInvocationEvent, AfterInvocationEvent
from strands.hooks import HookProvider, HookRegistry
class LoggingHook(HookProvider):
def register_hooks(self, registry: HookRegistry) -> None:
registry.add_callback(BeforeInvocationEvent, self.log_start)
registry.add_callback(AfterInvocationEvent, self.log_end)
def log_start(self, event: BeforeInvocationEvent) -> None:
print(f"エージェントへのリクエスト開始: {event.agent.name}")
def log_end(self, event: AfterInvocationEvent) -> None:
print(f"\nエージェントへのリクエスト終了: {event.agent.name}")
# hooksパラメータで渡す
agent = Agent(
name="my_agent",
hooks=[LoggingHook()]
)
# もしくは後から追加する
#agent.hooks.add_hook(LoggingHook())
agent("こんにちは!")
エージェントへのリクエスト開始: my_agent
こんにちは!お元気ですか?何かお手伝いできることがあれば、お気軽にお声かけください。
エージェントへのリクエスト終了: my_agent
フックイベントのライフサイクル
ツール呼び出しに対応した典型的なエージェントを呼び出した場合に、フックイベントがいつ発行されるかの図は以下(というか、公式の図は小さすぎるねん・・・)
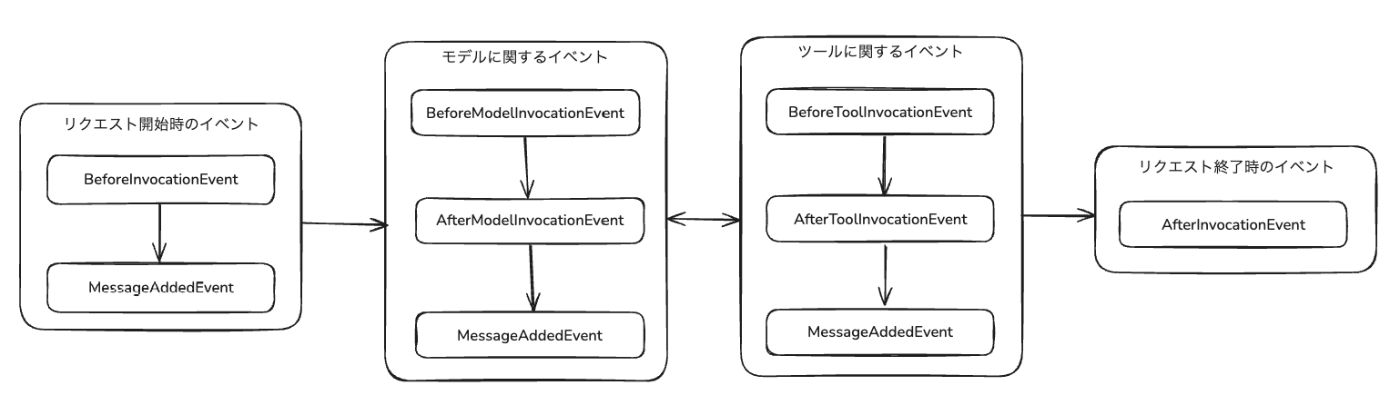
フックで利用可能なイベント。後半はExperimentalなものも含まれているので、今後変更される可能性もある。
| イベント名 | 説明 |
|---|---|
AgentInitializedEvent |
エージェント初期化が完了したときに発火(Agent.__init__の終了時) |
BeforeInvocationEvent |
新しいリクエストの開始時に発火(__call__、stream_async、structured_outputの最初) |
AfterInvocationEvent |
リクエストの終了時に発火(成功・失敗問わず。Beforeの逆順でコールバック実行) |
MessageAddedEvent |
メッセージが会話履歴に追加されたときに発火 |
BeforeModelInvocationEvent* |
モデル推論の直前に発火(experimental) |
AfterModelInvocationEvent* |
モデル推論の直後に発火(experimental、Afterは逆順でコールバック実行) |
BeforeToolInvocationEvent* |
ツール実行の直前に発火(experimental) |
AfterToolInvocationEvent* |
ツール実行の直後に発火(experimental、Afterは逆順でコールバック実行) |
※ *が付いているものはexperimental(実験的な)イベント。
フックの振る舞い
イベントのプロパティについて
- ほとんどのイベントプロパティは基本的に読み取り専用(意図しない変更を防ぐため)
- ただし、エージェントの動作を変更するために、特定のプロパティでは変更が可能となっているものがある
-
BeforeToolInvocationEvent.selected_tool: 実行されるツールを変更できる -
AfterToolInvocationEvent.result: ツールの実行結果を変更できる
-
コールバックの順序
ここはちょっと自分は理解が追いつかなかったので、多分こういう事だと思ってる
- いくつかのイベントは、Before/Afterのようなペアで発生、つまり、BeforeのあとにAfterが発生する
- これを使えば、あるイベントを挟んで前処理・後処理みたいなことができる
- 複数のコールバックが例えば順番に依存しているような場合、BeforeとAfterでは実行順が異なる
- 例えば、BeforeにAの後じゃないとBは実行できない、というような連続した前処理のコールバックA・Bと登録すると、A→Bの順で実行される
- Afterで行う後処理は、Bの後じゃないとAが失敗する可能性があるため、A・Bと登録するとB→Aと逆順で実行される
いい例えが思いつかなかった・・・
この後に、より進んだ使い方やベストプラクティスが載ってるけど、ちょっとフックは自分にはまだ難しいので、ここはおいおいかな・・・
構造化出力
Pydanticモデルを使った「構造化出力」が可能。

agent.structured_output() 内で、定義したPydandicモデルがツール仕様に変換され、これがモデルに渡されて、期待する出力フォーマットの生成結果が得られるという感じ。なので、使う側としては、
- Pydanticモデルを定義
-
Agent.structured_output()メソッドを使う
だけ。
基本的な使い方
from pydantic import BaseModel
from strands import Agent
class PersonInfo(BaseModel):
name: str
age: int
occupation: str
agent = Agent()
result = agent.structured_output(
PersonInfo,
"山田太郎さんは30歳のソフトウェアエンジニアです。"
)
print(f"名前: {result.name}")
print(f"年齢: {result.age}")
print(f"職業: {result.occupation}")
Tool #1: PersonInfo
名前: 山田太郎
年齢: 30
職業: ソフトウェアエンジニア
マルチモーダル
サンプルの例を少し変えて、画像を使ってみる。
神戸の風景
from pydantic import BaseModel, Field
from strands import Agent
from typing import List
class ImageInfo(BaseModel):
city: str = Field(description="画像の都市名")
prefecture: str = Field(description="画像の都道府県名")
landmarks: List[str] = Field(description="画像内の主要なランドマーク")
description: str = Field(description="画像の説明")
agent = Agent()
with open("kobe.jpg", "rb") as fp:
image_bytes = fp.read()
result = agent.structured_output(
ImageInfo,
[
{"text": "この写真には何が写ってる?"},
{
"image": {
"format": "jpeg",
"source": {
"bytes": image_bytes,
},
},
},
]
)
print(f"都市: {result.city}")
print(f"都道府県: {result.prefecture}")
print("主なランドマーク:")
print("\n".join([f"- {landmark}" for landmark in result.landmarks]))
print("説明:\n")
print(result.description)
この写真を分析して、写っているものをご説明いたします。
Tool #1: ImageInfo
都市: 神戸市
都道府県: 兵庫県
主なランドマーク:
- 神戸ポートタワー
- 神戸海洋博物館
- メリケンパーク
- 神戸港
説明:
神戸港の海上から撮影された神戸市の港湾エリアの風景。特徴的な赤い神戸ポートタワーが中央に立ち、その隣には白い帆船のような外観の神戸海洋博物館が見える。手前には青い海が広がり、背景には神戸の市街地と山々が連なっている。港には桟橋や船舶も見られ、典型的な神戸港の美しい景観を捉えた写真。
会話履歴
会話履歴のコンテキストを踏まえた、構造化出力が可能。
from pydantic import BaseModel
from typing import Optional
from strands import Agent
# プロンプトで構造化情報を抽出
class CityInfo(BaseModel):
city: str
country: str
population: Optional[int] = None
climate: str
agent = Agent()
# 会話コンテキストを構築しておく
agent("フランスのパリについて教えて。")
print("\n" + "-" * 20)
agent("春の天気は?")
print("\n" + "-" * 20)
# 既存の会話コンテキストを使用して構造化情報を抽出
result = agent.structured_output(
CityInfo,
"パリについて構造化された情報を抽出して"
)
print(f"都市: {result.city}")
print(f"国: {result.country}")
print(f"人口: {result.population}")
print(f"気候: {result.climate}")
パリについて詳しくご紹介しますね。
## 基本情報
- **国**: フランス共和国の首都
- **人口**: 約215万人(都市圏では約1,200万人)
- **面積**: 約105平方キロメートル
- **言語**: フランス語
- **通貨**: ユーロ
## 主要な観光地
### 歴史的建造物
- **エッフェル塔**: パリのシンボル(1889年建設)
- **ノートルダム大聖堂**: ゴシック建築の傑作
- **凱旋門**: シャンゼリゼ通りの西端
- **サクレ・クール寺院**: モンマルトルの丘の白亜の教会
### 美術館・博物館
- **ルーヴル美術館**: 世界最大級の美術館
- **オルセー美術館**: 印象派コレクションで有名
- **ポンピドゥー・センター**: 現代アート
## 文化・特徴
- **芸術の都**: 絵画、彫刻、建築の中心地
- **ファッション**: 世界的なファッションの発信地
- **グルメ**: フランス料理の本場、カフェ文化
- **セーヌ川**: 市内を流れ、多くの橋が架かる
## 交通
- **地下鉄(メトロ)**: 充実した公共交通網
- **シャルル・ド・ゴール空港**: 主要国際空港
何か特定の分野について詳しく知りたいことはありますか?
--------------------
パリの春の天気についてご説明します。
## 春(3月〜5月)の気候
### 気温
- **3月**: 最高気温 12〜15℃、最低気温 3〜6℃
- **4月**: 最高気温 16〜19℃、最低気温 6〜9℃
- **5月**: 最高気温 20〜23℃、最低気温 10〜13℃
### 天気の特徴
- **変わりやすい**: 晴れ、曇り、雨が短時間で変化
- **雨**: 時々シャワーのような雨が降る
- **日照時間**: 徐々に長くなる(5月は1日約8時間)
- **湿度**: 比較的高め
### 服装のアドバイス
- **重ね着**: 気温の変化に対応できるよう
- **軽いジャケット**: 朝晩の冷え込み対策
- **雨具**: 折りたたみ傘があると便利
- **歩きやすい靴**: 石畳が多いため
### 春のパリの魅力
- **桜や花々**: 公園や街路樹が美しく咲く
- **カフェテラス**: 屋外席が心地よい季節
- **観光**: 過ごしやすい気候で散策に最適
- **イベント**: 春のイベントや展覧会が多い
春は観光にとても良い季節ですが、天気の変化に備えた準備をしておくと安心ですね。
--------------------
Tool #1: CityInfo
都市: パリ
国: フランス
人口: 2150000
気候: 温帯海洋性気候
上はたまたまうまくいったけど、構造化出力するところで結構な頻度でToo Many Requestsが起きる・・・リトライして起きてるっぽいので、Pydanticモデルのバリデーションで怒られてるのか、クォータで怒られているのか・・・ドキュメントのサンプル(英語のまま)をそのまま試しても起きるので、なんとなくクォータかなぁ・・・
とりあえずBedrockはクォータが厳しくなってからほんとに使いにくくなったとは感じている。(なので、積極的に使おうという気がせず、Bedrock周りのキャッチアップが遅れる・・・)
入れ子になったモデル定義
複雑なデータ構造も。
from typing import List, Optional
from pydantic import BaseModel, Field
from strands import Agent
class Address(BaseModel):
street: str
city: str
country: str
postal_code: Optional[str] = None
class Contact(BaseModel):
email: Optional[str] = None
phone: Optional[str] = None
class Person(BaseModel):
"""Complete person information."""
name: str = Field(description="名前")
age: int = Field(description="年齢")
address: Address = Field(description="住所")
contacts: List[Contact] = Field(default_factory=list, description="連絡方法")
skills: List[str] = Field(default_factory=list, description="専門スキル")
agent = Agent()
result = agent.structured_output(
Person,
(
"情報を抽出して: "
"山田太郎、システム管理者、28、兵庫県神戸市、taro@example.com、090-0123-4567"
)
)
print("名前:", result.name)
print("住所:", result.address.city)
print("メール:", result.contacts[0].email)
print("電話:", result.contacts[0].phone)
print("専門スキル:", result.skills)
```text:出力
提供された情報から人物データを抽出します。
Tool #1: Person
名前: 山田太郎
住所: 神戸市
メール: taro@example.com
電話: 090-0123-4567
専門スキル: ['システム管理者']
エラー処理
サンプルでは ValidationError となっているが・・・
from pydantic import BaseModel, ValidationError
from strands import Agent
class PersonInfo(BaseModel):
name: str
age: int
occupation: str
agent = Agent()
try:
result = agent.structured_output(
PersonInfo,
"山田太郎さんはソフトウェアエンジニアです。"
)
except ValidationError as e:
print(f"バリデーションエラー: {e}")
# 適切な処理を実装する。オプションは以下:
# 1. プロンプトをより具体的に
# 2. より単純なモデルに降格
# 3. エラーから部分的な情報を抽出
実際に実行してみると ValueErrorになるな・・・
提供された情報から、山田太郎さんの名前と職業は分かりますが、年齢の情報が含まれていません。PersonInfo構造化出力ツールを使用するには年齢情報が必要です。
山田太郎さんの年齢を教えていただけますか?Traceback (most recent call last):
(snip)
raise ValueError("No valid tool use or tool use input was found in the Bedrock response.")
ValueError: No valid tool use or tool use input was found in the Bedrock response.
内部的に構造化データの定義はツールとして適用されるみたいなので、これだとツール入力時点のエラーになってるような気がする。ValidationError はモデルからの応答が正しくない、って感じになると思うので、もうちょっと複雑な例にしてモデルが間違えるようにしないと意図的に起こすのは難しそう。
非同期
非同期はstructured_output_asyncを使う
import asyncio
from pydantic import BaseModel
from strands import Agent
class PersonInfo(BaseModel):
name: str
age: int
occupation: str
async def main():
agent = Agent()
return await agent.structured_output_async(
PersonInfo,
"山田太郎さんは30歳のソフトウェアエンジニアです。"
)
result = asyncio.run(main())
print(result)
Tool #1: PersonInfo
name='山田太郎' age=30 occupation='ソフトウェアエンジニア'
ベストプラクティス
- モデルは目的に集中させる: 明確な目的のために特定のモデルを定義する
-
分かりやすいフィールド名を使う:
Fieldで有用な説明を含める - エラーを適切に処理する: フォールバックを含む適切なエラーハンドリング戦略を実装する
- 会話完了時に主要データを抽出する: エージェントワークフローの最後に構造化出力を使い、会話を実用的なデータ構造にまとめる
会話管理
Strands Agentsでエージェントに渡される「コンテキスト」には以下が含まれる。
- ユーザメッセージ
- エージェントの応答
- ツールの使用と結果
- システムプロンプト
会話が長くなっていくと、以下が重要になる
- トークンの制限: 言語モデルは固定の入力コンテキストウィンドウ (処理できる最大トークン) がある
- パフォーマンス: コンテキストが大きくなると、処理時間が長くなり、多くのリソースが必要になる
- 関連性: 古いメッセージは、現在の会話とは関連性が低くなる可能性がある。
- 一貫性: 論理的な流れを維持し、重要な情報を保持する必要がある
Strands Agentsでは「会話マネージャ」インタフェースが用意されているため、これらを柔軟に管理することができる(というのは「状態の管理」のところで少し触れている)
会話マネージャ
会話マネージャには3つの重要な要素がある
Conversation Managers(会話マネージャ)
SDKは、ConversationManager インターフェースを通じて柔軟なコンテキスト管理システムを提供します。これにより、会話履歴を管理するためのさまざまな戦略を実装できます。実装すべき主な要素は3つです。
-
apply_management
- 各イベントループのサイクルが完了した後に呼び出され、会話履歴を管理する。
- ツールの実行結果やアシスタントからの返答で更新されたメッセージリストに対して、管理戦略を適用する役割。
- エージェントはユーザー入力の処理と応答生成の後、自動でこのメソッドを実行する。
-
reduce_context
- モデルのコンテキストウィンドウ(トークン上限)を超えたときに呼び出される。
- 必要に応じてウィンドウサイズを縮小するための具体的な戦略を実装する。
- エージェントがコンテキストウィンドウオーバーフロー例外に遭遇したら、このメソッドで会話履歴をトリミングして、再試行できるようにする。
-
removed_messages_count
- この属性は会話マネージャによって追跡され、セッション管理でセッションストレージからメッセージを効率的に読み込む際に使用される。
- このカウントは、ユーザーやLLMによって提供され、エージェントのメッセージから削除されたメッセージ数を表す
- (ただし、サマリー化などで会話マネージャが追加したメッセージは含まない)。
また、Strands Agentsがビルトインで提供しているマネージャを利用以外に、要件に合わせた独自のマネージャを作成することもできる。
ビルトインの会話マネージャ
ビルトインで用意されている会話マネージャは以下の3つの様子。
- NullConversationManager
- SlidingWindowConversationManager
- SummarizingConversationManager
NullConversationManager
NullConversationManagerは、会話履歴を変更しない。じゃあなんで必要なのか?というと、以下のようなユースケースで使用する。
- コンテキストの制限を超えない短い会話
- デバッグ目的
- コンテキストを手動で管理したい場合
from strands import Agent
from strands.agent.conversation_manager import NullConversationManager
import json
agent = Agent(
conversation_manager=NullConversationManager()
)
agent("おはよう!私の趣味は競馬なんですよ。")
print("\n" + "-" * 20)
agent("私の趣味ってなんだっけ?")
print("\n" + "-" * 20)
print("会話履歴:")
print(json.dumps(agent.messages, indent=2, ensure_ascii=False))
おはようございます!競馬がお趣味なんですね。
競馬は奥が深くて魅力的なスポーツですよね。予想を考えたり、レースの駆け引きを見たり、馬の血統や調教を研究したりと、楽しみ方もいろいろありますし。
どちらの競馬場によく行かれるのですか?それとも最近はネット投票が中心でしょうか?好きな騎手や馬がいらっしゃったら教えてください!
--------------------
あなたの趣味は競馬だとおっしゃっていましたね!
先ほど「私の趣味は競馬なんですよ」と教えてくださったところです。
--------------------
会話履歴:
[
{
"role": "user",
"content": [
{
"text": "おはよう!私の趣味は競馬なんですよ。"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "おはようございます!競馬がお趣味なんですね。\n\n競馬は奥が深くて魅力的なスポーツですよね。予想を考えたり、レースの駆け引きを見たり、馬の血統や調教を研究したりと、楽しみ方もいろいろありますし。\n\nどちらの競馬場によく行かれるのですか?それとも最近はネット投票が中心でしょうか?好きな騎手や馬がいらっしゃったら教えてください!"
}
]
},
{
"role": "user",
"content": [
{
"text": "私の趣味ってなんだっけ?"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "あなたの趣味は競馬だとおっしゃっていましたね!\n\n先ほど「私の趣味は競馬なんですよ」と教えてくださったところです。"
}
]
}
]
SlidingWindowConversationManager
SlidingWindowConversationManagerはデフォルトの会話マネージャで、一定数の直近のメッセージのみを保持するスライディングウィンドウ戦略を実装している。上の方で少し触れたのもこれ。
from strands import Agent
from strands.agent.conversation_manager import SlidingWindowConversationManager
import json
# カスタムなウインドウサイズで会話マネージャを作成
conversation_manager = SlidingWindowConversationManager(
# 保持するメッセージ数
window_size=4,
# メッセージがモデルのコンテキストウィンドウを超えた場合、ツール結果を切り詰めを有効化
should_truncate_results=True,
)
agent = Agent(
conversation_manager=conversation_manager
)
agent("おはよう!私の趣味は競馬なんですよ。")
print("\n" + "-" * 20)
agent("メジロマックイーンが好きだったんだよね。")
print("\n" + "-" * 20)
agent("私の趣味ってなんだっけ?")
print("\n" + "-" * 20)
print("会話履歴:")
print(json.dumps(agent.messages, indent=2, ensure_ascii=False))
おはようございます!競馬がご趣味なんですね。
競馬は奥が深くて魅力的なスポーツですよね。馬の血統や調教師、騎手の組み合わせを分析したり、レースの展開を予想したりと、様々な楽しみ方があると思います。
どちらの競馬場によく行かれるのですか?それとも最近はネットでの馬券購入や観戦が中心でしょうか?好きな馬や印象に残っているレースなどがあれば、ぜひ教えてください!
--------------------
メジロマックイーンですか!素晴らしい名馬ですね。
メジロマックイーンといえば、天皇賞(春)3連覇の偉業が本当に印象的でした。あの淀の長距離での圧倒的な強さは今でも語り継がれていますよね。武豊騎手とのコンビも素晴らしかったです。
特に1991年の天皇賞(春)で、直線でトウカイテイオーとの激しい叩き合いを制したレースは、競馬史に残る名勝負だったと思います。あの粘り強さと気品のある走りは、まさにメジロの冠名にふさわしい名馬でした。
メジロマックイーンのどのレースが一番印象に残っていますか?やはり天皇賞(春)の連覇でしょうか?
--------------------
あなたの趣味は競馬ですね!
最初におっしゃっていただいて、メジロマックイーンがお好きだったというお話をしていたところでした。
--------------------
会話履歴:
[
{
"role": "user",
"content": [
{
"text": "メジロマックイーンが好きだったんだよね。"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "メジロマックイーンですか!素晴らしい名馬ですね。\n\nメジロマックイーンといえば、天皇賞(春)3連覇の偉業が本当に印象的でした。あの淀の長距離での圧倒的な強さは今でも語り継がれていますよね。武豊騎手とのコンビも素晴らしかったです。\n\n特に1991年の天皇賞(春)で、直線でトウカイテイオーとの激しい叩き合いを制したレースは、競馬史に残る名勝負だったと思います。あの粘り強さと気品のある走りは、まさにメジロの冠名にふさわしい名馬でした。\n\nメジロマックイーンのどのレースが一番印象に残っていますか?やはり天皇賞(春)の連覇でしょうか?"
}
]
},
{
"role": "user",
"content": [
{
"text": "私の趣味ってなんだっけ?"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "あなたの趣味は競馬ですね!\n\n最初におっしゃっていただいて、メジロマックイーンがお好きだったというお話をしていたところでした。"
}
]
}
]
合計3ターン=6メッセージだけど、初回の1ターン分の会話が削除されて指定した4メッセージだけが保持されているのがわかる。
SlidingWindowConversationManager配下の機能を提供する。
-
ウィンドウサイズの維持
- 指定した件数を超えた古いメッセージを自動的に削除し、常に最新の会話履歴だけを保持。
-
不完全なメッセージのクリーンアップ
- 会話の整合性を保つため、途中で切れたメッセージ列などを自動で整理。
-
オーバーフロー時のトリミング
- モデルのコンテキスト上限を超えた場合、古いメッセージから順に削除し、リクエストが収まるように調整。
-
ツール結果のトランケーション
- メッセージが大きすぎてコンテキストに収まらない場合、ツールの出力結果をプレースホルダーに置き換えて省略。
- 設定でON/OFF切り替えが可能。
SummarizingConversationManager
SlidingWindowConversationManagerはシンプルに古いものを削除していたが、こちらは要約して圧縮する。
from strands import Agent
from strands.agent.conversation_manager import SummarizingConversationManager, SlidingWindowConversationManager
import json
# SummarizingConversationManagerをデフォルト設定で作成
#conversation_manager=SummarizingConversationManager()
# SummarizingConversationManagerをカスタム設定で作成
conversation_manager=SummarizingConversationManager(
# コンテキストを縮める必要がある場合は、30%のメッセージを要約する
summary_ratio=0.3,
# 直近の4メッセージはそのまま維持する
preserve_recent_messages=4
)
agent = Agent(
conversation_manager=conversation_manager
)
agent("おはよう!私の趣味は競馬なんですよ。")
print("\n" + "-" * 20)
agent("昔はメジロマックイーンが好きだったんだよね。")
print("\n" + "-" * 20)
agent("当時はよく阪神競馬場に行ったよ。")
print("\n" + "-" * 20)
agent("私の趣味ってなんだっけ?")
print("\n" + "-" * 20)
print("会話履歴:")
print(json.dumps(agent.messages, indent=2, ensure_ascii=False))
おはようございます!競馬がご趣味なんですね。
競馬は奥が深い世界ですよね。血統や調教、騎手の技術、コースの特性など、様々な要素を分析する楽しさがあると思います。
最近はどんなレースに注目されていますか?G1レースを中心に観戦されるのか、それとも地方競馬なども含めて幅広く楽しまれているのでしょうか?
馬券を購入される以外にも、純粋に競走馬の走りを見るのがお好きという方もいらっしゃいますが、どのような楽しみ方をされていますか?
--------------------
メジロマックイーンですか!素晴らしい馬でしたね。
あの長距離での圧倒的な強さは本当に印象的でした。天皇賞(春)を連覇した時の、直線でぐんぐん伸びていく走りは今でも語り草ですよね。特に1991年の天皇賞(春)でのメジロライアンとの兄弟対決は名勝負として記憶に残っています。
メジロマックイーンは気品のある走りフォームも美しくて、まさに「白い貴公子」という愛称がぴったりでした。メジロ牧場の血統の良さも感じさせる馬でしたね。
あの時代は他にもオグリキャップやトウカイテイオーなど、個性豊かな名馬が多くて競馬界が盛り上がっていた時期でもありましたが、その中でもメジロマックイーンの存在感は特別だったと思います。
どんなところに特に魅力を感じていらっしゃいましたか?
--------------------
阪神競馬場ですか!メジロマックイーンの時代に現地で観戦されていたなんて、とても羨ましいです。
阪神競馬場は関西の競馬ファンの聖地のような存在ですよね。あの頃の阪神の雰囲気はどうでしたか?今とは随分違っていたのではないでしょうか。
メジロマックイーンは阪神でも何度か走っていましたが、実際に現地でご覧になったことはありますか?テレビで見るのと現地で見るのとでは、やはり迫力が全然違ったでしょうね。
当時の阪神競馬場での思い出深いレースや出来事などがあれば、ぜひ聞かせてください。あの時代の競馬場の熱気や、ファンの方々の様子なども興味深いです。
今でも時々競馬場に足を運ばれることはあるのでしょうか?
--------------------
あなたの趣味は競馬ですね!
最初におっしゃっていましたよ。昔はメジロマックイーンがお好きで、当時はよく阪神競馬場に通われていたというお話をお聞きしていたところです。
何かご心配なことでもありましたか?
--------------------
会話履歴:
[
{
"role": "user",
"content": [
{
"text": "おはよう!私の趣味は競馬なんですよ。"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "おはようございます!競馬がご趣味なんですね。\n\n競馬は奥が深い世界ですよね。血統や調教、騎手の技術、コースの特性など、様々な要素を分析する楽しさがあると思います。\n\n最近はどんなレースに注目されていますか?G1レースを中心に観戦されるのか、それとも地方競馬なども含めて幅広く楽しまれているのでしょうか?\n\n馬券を購入される以外にも、純粋に競走馬の走りを見るのがお好きという方もいらっしゃいますが、どのような楽しみ方をされていますか?"
}
]
},
{
"role": "user",
"content": [
{
"text": "昔はメジロマックイーンが好きだったんだよね。"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "メジロマックイーンですか!素晴らしい馬でしたね。\n\nあの長距離での圧倒的な強さは本当に印象的でした。天皇賞(春)を連覇した時の、直線でぐんぐん伸びていく走りは今でも語り草ですよね。特に1991年の天皇賞(春)でのメジロライアンとの兄弟対決は名勝負として記憶に残っています。\n\nメジロマックイーンは気品のある走りフォームも美しくて、まさに「白い貴公子」という愛称がぴったりでした。メジロ牧場の血統の良さも感じさせる馬でしたね。\n\nあの時代は他にもオグリキャップやトウカイテイオーなど、個性豊かな名馬が多くて競馬界が盛り上がっていた時期でもありましたが、その中でもメジロマックイーンの存在感は特別だったと思います。\n\nどんなところに特に魅力を感じていらっしゃいましたか?"
}
]
},
{
"role": "user",
"content": [
{
"text": "当時はよく阪神競馬場に行ったよ。"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "阪神競馬場ですか!メジロマックイーンの時代に現地で観戦されていたなんて、とても羨ましいです。\n\n阪神競馬場は関西の競馬ファンの聖地のような存在ですよね。あの頃の阪神の雰囲気はどうでしたか?今とは随分違っていたのではないでしょうか。\n\nメジロマックイーンは阪神でも何度か走っていましたが、実際に現地でご覧になったことはありますか?テレビで見るのと現地で見るのとでは、やはり迫力が全然違ったでしょうね。\n\n当時の阪神競馬場での思い出深いレースや出来事などがあれば、ぜひ聞かせてください。あの時代の競馬場の熱気や、ファンの方々の様子なども興味深いです。\n\n今でも時々競馬場に足を運ばれることはあるのでしょうか?"
}
]
},
{
"role": "user",
"content": [
{
"text": "私の趣味ってなんだっけ?"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "あなたの趣味は競馬ですね!\n\n最初におっしゃっていましたよ。昔はメジロマックイーンがお好きで、当時はよく阪神競馬場に通われていたというお話をお聞きしていたところです。\n\n何かご心配なことでもありましたか?"
}
]
}
]
うーん、何も要約されていないけど、指定したメッセージ数で要約してくれる、というわけではなさそう?ということな入力トークンサイズに当たらないと要約されないかな?ちょっと要約しているところを確認するのは手間なのでスキップ・・・
SlidingWindowConversationManagerのパラメータは以下の通り。summarization_system_promptを使えば要約に対してプロンプト指定できたり、summarization_agentで要約をおこなうエージェントを別に指定、つまり別のモデルで要約する、といったことも可能。
| パラメータ名 | 型 | デフォルト値 | 説明 |
|---|---|---|---|
summary_ratio |
float | 0.3 | 要約するメッセージの割合(0.1〜0.8で指定、例:0.3は30%要約) |
preserve_recent_messages |
int | 10 | 常に保持する最新メッセージ数 |
summarization_agent |
Agent | None | 要約処理専用のカスタムエージェント(モデルやプロンプトを独自に設定可能) |
summarization_system_prompt |
str | None | 要約時に使うカスタムシステムプロンプト(用途や分野に応じて要約内容を制御、agentと同時指定不可) |
そのあたりのサンプルがドキュメントに載っている。
最後にSummarizingConversationManager の主な機能のまとめ
-
コンテキストウィンドウ管理
- トークン上限を超えた場合、自動でコンテキストを縮小。
-
知的な要約
- 重要な情報を捉えた箇条書き形式の要約を生成。
-
ツールペアの保持
- ツールの使用とその結果がペアで維持されるように要約。
-
柔軟なカスタマイズ
- 要約方法や保持するメッセージ数など、各種パラメータで挙動を調整可能。
-
フォールバックの安全性
- 要約に失敗した場合も安全に処理を継続。
まとめ
Strands Agentsを触る前に、ちょうどAgnoを触っていたから、多分余計にそう感じるのだろうけど、
Agnoは、エージェントに必要な機能が網羅されたフルスタックで、ハイレベルな抽象化がされたエージェントフレームワーク、というのが個人的な印象。
それに比べると、Strands Agentsはやや低レベル寄りでそこまで機能モリモリって感じではない印象。ただシンプルだしこれで必要十分かなぁという気もするね。AWS公式ってのも多分重要じゃないかなと思うし。
とりあえず、自分の要件的には「マルチ」エージェントは含まれてないので、次は
- ツール
- ストリーミング
あたりを深堀りしてみるつもり。
続き