WebサイトをスクレイピングしてLLMで使いやすいデータにする「Firecrawl」をセルフホストしてみる
Firecrawl
以下で少し触れたFirecrawl。
Webサイトをクロールして、JSONやMarkdownなどLLMで使いやすいデータに変換するサービス。
オフィシャルではないけども以下で紹介されている。
https://www.youtube.com/watch?v=fDSM7chMo5E
Jina.aiのReader APIと似たような感じかな?
ソースはGitHubで公開(ライセンスはAGPL-3.0)されていて、docker composeでセルフホストできるらしい。
一応READMEには以下とある。
このリポジトリは開発初期段階にある。まだmonoリポジトリのカスタムモジュールをマージしているところだ。完全なセルフホストデプロイの準備はまだできていないが、ローカルで実行することはすでに可能だ。
とりあえず試してみる。
🔥 Firecrawl
あらゆるウェブサイトをクロールし、LLM対応のマークダウンまたは構造化データに変換する。Mendable.aiとFirecrawlコミュニティによって構築された。強力なスクレイピング、クローリング、データ抽出機能を含む。
Firecrawlとは?
Firecrawlは、URLを取得し、クロールし、クリーンなマークダウンまたは構造化データに変換するAPIサービスである。アクセス可能なすべてのサブページをクロールし、それぞれのきれいなデータを提供する。サイトマップは必要ない。
使い方は?
ホスティング・バージョンで使いやすいAPIを提供している。ここでプレイグラウンドとドキュメントを見つけることができる。バックエンドをセルフホストすることもできる。
- API
- Python SDK
- Node SDK
- Langchainインテグレーション🦜🔗
- Langchain JSインテグレーション 🦜 🔗
- LlamaIndexインテグレーション
- Difyインテグレーション
- Langflowインテグレーション
- Crew.aiインテグレーション
- Flowise AIインテグレーション
- PraisonAIインテグレーション
- Zapierインテグレーション
- SDKまたはインテグレーションが必要?イシューを開いて私たちに知らせてほしい。
ライセンス免責事項
このプロジェクトは主にGNU Affero General Public License v3.0 (AGPL-3.0)の下でライセンスされている。しかし、このプロジェクトの特定のコンポーネント、特に
/apps/js-sdkと/apps/python-sdkディレクトリにあるSDKはMITライセンスでライセンスされている。注意:
AGPL-3.0ライセンスは、特に指定がない限り、プロジェクトのすべての部分に適用される。
apps/js-sdkと/apps/python-sdkのSDKはMITライセンスでライセンスされる。詳細については、これらのディレクトリにあるLICENSEファイルを参照のこと。
このプロジェクトを使用したり、プロジェクトに貢献したりする場合は、使用している特定のコンポーネントの適切なライセンス条項に従っていることを確認すること。
特定のコンポーネントのライセンスの詳細については、それぞれのディレクトリにあるLICENSEファイルを参照するか、プロジェクトのメンテナに問い合わせること。
AGPLについてはこちらがわかりやすかった
以下に従って進めてみる。LAN内にあるUbuntu 22.04サーバ上でやる。Docker等はすでにあるものとする。
レポジトリクローン
$ git clone https://github.com/mendableai/firecrawl && cd firecrawl
.envを雛形からコピーして作成
$ cp ./apps/api/.env.example ./.env
.envはこういう内容。コメントは日本語にした。
# ===== 必須の環境変数 ======
NUM_WORKERS_PER_QUEUE=8
PORT=3002
HOST=0.0.0.0
REDIS_URL=redis://localhost:6379
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/html
## DB認証を有効にするには、supabaseを設定する必要がある
USE_DB_AUTHENTICATION=true
# ===== オプションの環境変数 ======
# Supabaseの設定 (DB認証や高度なロギングなどをサポートするために使用)
SUPABASE_ANON_TOKEN=
SUPABASE_URL=
SUPABASE_SERVICE_TOKEN=
# その他のオプション
TEST_API_KEY= # 認証を設定し、実際のAPIキーでテストしたい場合に使用
RATE_LIMIT_TEST_API_KEY_SCRAPE= # スクレイピングのレート制限をテストしたい場合に設定
RATE_LIMIT_TEST_API_KEY_CRAWL= # クローリングのレート制限をテストしたい場合に設定
SCRAPING_BEE_API_KEY= #ScrapingBeeでJSブロッキングを処理したい場合に設定
OPENAI_API_KEY= # LLMに依存する機能(画像のALT生成など)を追加する場合に設定
BULL_AUTH_KEY= @
LOGTAIL_KEY= # Logtailで基本的なロギングを設定する場合に使用
LLAMAPARSE_API_KEY= # PDFの解析にLlamaParseのキーがある場合に設定
SERPER_API_KEY= #検索APIとしてSerperAPIのキーがある場合に設定
SLACK_WEBHOOK_URL= # Slackにのヘルスステータスのメッセージを送信するか場合に設定
POSTHOG_API_KEY= # ジョブのログなどのPostHogイベントを送信したい場合は設定
POSTHOG_HOST= # ジョブのログなどのPostHogイベントを送信したい場合は設定
STRIPE_PRICE_ID_STANDARD=
STRIPE_PRICE_ID_SCALE=
STRIPE_PRICE_ID_STARTER=
STRIPE_PRICE_ID_HOBBY=
STRIPE_PRICE_ID_HOBBY_YEARLY=
STRIPE_PRICE_ID_STANDARD_NEW=
STRIPE_PRICE_ID_STANDARD_NEW_YEARLY=
STRIPE_PRICE_ID_GROWTH=
STRIPE_PRICE_ID_GROWTH_YEARLY=
HYPERDX_API_KEY=
HDX_NODE_BETA_MODE=1
FIRE_ENGINE_BETA_URL= # FireEngineのクローズドベータを利用したい場合は設定
# Playwrightのプロキシ設定 (oxylabsのような、リクエストごとにIPをローテーションしてくれるプロキシサービスを使う方法もある)
PROXY_SERVER=
PROXY_USERNAME=
PROXY_PASSWORD=
# プロキシの帯域幅を節約するためにメディアリクエストをブロックしたい場合は設定
BLOCK_MEDIA=
# FireCrawをセルフホストで使用する場合はWebhookのURLを設定
SELF_HOSTED_WEBHOOK_URL=
# メールのトランザクション用にResedのAPIキーを設定
RESEND_API_KEY=
いろいろなサービスとの連携ができるようだが、ローカルで動かすだけなら以下の箇所だけ変更すれば良さそう。
REDIS_URL=redis://redis:6379 # localhostからredisに変更
USE_DB_AUTHENTICATION=false # 認証不要に変更
docker composeで起動する
$ docker compose build
$ docker compose up
3002番ポートでAPIエンドポイントが立ち上がる。XXX.XXX.XXX.XXXはサーバのIPアドレス等に適宜置き換え。curlでアクセスしてみる。
$ curl http://XXX.XXX.XXX.XXX:3002/
以下のように表示されればOK。
SCRAPERS-JS: Hello, world! Fly.io
ではREADMEに従って、用意されているエンドポイントを試してみる。
スクレイピング
単一のURLに対するスクレイピングは/v0/scrapeに対して行う。
$ curl -X POST http://XXX.XXX.XXX.XXX:3002/v0/scrape \
-H 'Content-Type: application/json' \
-d '{
"url": "https://mendable.ai"
}' | jq -r .
出力は一部割愛。
{
"success": true,
"data": {
"content": "\n\nIntroducing [Firecrawl](https://firecrawl.dev/?ref=mendable+banner)\n(...snip...)",
"markdown": "\n\nIntroducing [Firecrawl](https://firecrawl.dev/?ref=mendable+banner)\n 🔥 - (...snip...)",
"metadata": {
"title": "Mendable",
"description": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"robots": "follow, index",
"ogTitle": "Mendable",
"ogDescription": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"ogUrl": "https://mendable.ai/",
"ogImage": "https://mendable.ai/mendable_new_og1.png",
"ogLocaleAlternate": [],
"ogSiteName": "Mendable",
"sourceURL": "https://mendable.ai",
"pageStatusCode": 200,
"sitemap": {
"changefreq": "hourly"
}
}
},
"returnCode": 200
}
.data.markdownにMarkdownで整形されたテキストが入るっぽい。
クローリング
こちらは起点となるURLを渡すと、サイトマップやリンクなどを再帰的に追いかけて複数のページをまるっとスクレイピングしてくれるものみたい。
URLを送る。
$ curl -X POST http://XXX.XXX.XXX.XXX:3002/v0/crawl \
-H 'Content-Type: application/json' \
-d '{
"url": "https://mendable.ai"
}'
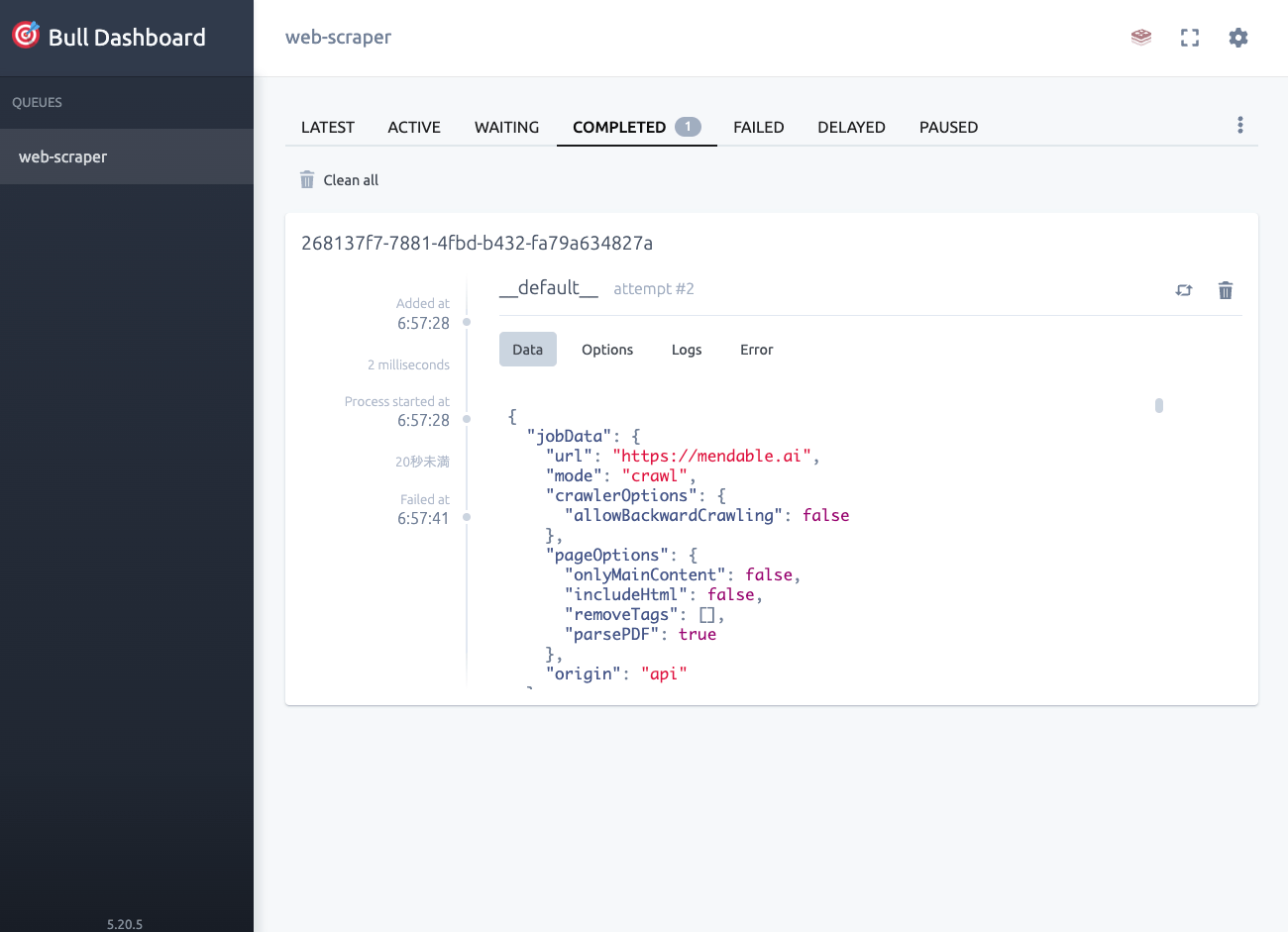
ジョブがキューイングされる。
{"jobId":"268137f7-7881-4fbd-b432-fa79a634827a"}
ジョブの状態は/v0/crawl/status/[ジョブID]で確認できる。
$ curl -X GET http://rtx4090.local:3002/v0/crawl/status/268137f7-7881-4fbd-b432-fa79a634827a \
-H 'Content-Type: application/json' | jq -r .
statusでジョブの実行状況がわかる。以下のようにcompletedになっていれば、各ページごとのオブジェクトがリストで返ってくる。
{
"status": "completed",
"current": 27,
"total": 27,
"data": [
{
"content": "\n\nIntroducing [Firecrawl](https://firecrawl.dev/?ref=mendable+banner)\n 🔥(snip)",
"markdown": "\n\nIntroducing [Firecrawl](https://firecrawl.dev/?ref=mendable+banner)\n 🔥(snip)",
"metadata": {
"title": "Mendable",
"description": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"robots": "follow, index",
"ogTitle": "Mendable",
"ogDescription": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"ogUrl": "https://mendable.ai/",
"ogImage": "https://mendable.ai/mendable_new_og1.png",
"ogLocaleAlternate": [],
"ogSiteName": "Mendable",
"sourceURL": "https://www.mendable.ai",
"pageStatusCode": 200,
"sitemap": {
"changefreq": "hourly"
}
}
},
{
"content": "\n\nIntroducing [Firecrawl](https://firecrawl.dev/?ref=mendable+banner)\n 🔥(snip)",
"markdown": "\n\nIntroducing [Firecrawl](https://firecrawl.dev/?ref=mendable+banner)\n 🔥(snip)",
"metadata": {
"title": "Mendable",
"description": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"robots": "follow, index",
"ogTitle": "Mendable",
"ogDescription": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"ogUrl": "https://mendable.ai/usecases/cs-enablement",
"ogImage": "https://mendable.ai/mendable_new_og1.png",
"ogLocaleAlternate": [],
"ogSiteName": "Mendable",
"sourceURL": "https://www.mendable.ai/usecases/cs-enablement",
"pageStatusCode": 200,
"sitemap": {
"changefreq": "hourly"
}
}
},
(snip)
],
"partial_data": []
}
また、ブラウザで/admin/@/queuesにアクセスすると、GUIで各ジョブの実行状況を確認することができる。
その他
- クラウドサービス版のようなリッチなGUIは用意されていなさそう。
-
USE_DB_AUTHENTICATIONを無効にすると、APIリクエスト時のTEST_API_KEYも効かないように思える。Authorizationヘッダーなしでも応答が返ってくる。 -
USE_DB_AUTHENTICATIONを有効にするにはSupabaseの設定が必要らしいのだが、どうもこれはセルフホストでSupabaseが使えるということではなく、FirecrawlのマネージドサービスでSupabase連携するためのものらしい
It looks like there’s a little mix-up with the DB authentication feature. Just to clarify, this setting is specifically for our managed services linked to supabase and isn’t suitable for a self-hosted setup like yours on Kubernetes.
- .envを見ると色々なサービスとの連携ができるようだがドキュメントがほぼ無いに等しい。
ということで、例えばFirecrawlをパブリックにセルフホストしてAPI叩く、みたいな感じで使おうと思うと、最低限何かしらのセキュリティを自分で確保する必要が出てくる(Firecrawlのセルフホスト版にはその機能がなさそう)。
あと、ローカルで動かせば無料で何回も叩ける、というのはあるのだけども、ブロックされたりとか過度に負荷かけてしまうみたいなことも当然ながら可能性としてはないこともないと思うので、この辺の諸々をまるっとやってくれるSaaSにもメリットはあるし、業務で使うならその方が楽かなぁという感はある。
似たような位置付けのJina Readerと比較したくなる。セルフホストは置いといて、クラウドサービスのスペックを雑に比較してみる。あくまでも個人の所感。
- 個人的にはややFirecrawlのほうが細かく制御できて良さそうかなぁと思うけど、そこまで大きな差はないのではと思う。Jina Readerはシンプルに使えるのが良いけど、クローリングはなさそうかな?
- 費用はJinaのほうがかなり良さそう
- Jinaはプリペイド方式でEmbeddingやリランキングなどの別サービスでも使えるっぽいし、多分こっちのほうが安いし、無料枠も大きめ。Firecrawlは月額+月のリクエスト数上限があるので、Jinaに比べるとちょっと高いかな。
- Jinaのほうがレートリミットもゆるい。Firecrawlは結構厳しい感がある。
- 使い勝手は甲乙つけがたい
- Jinaはとてもシンプルで使いやすそう
- FirecrawlはSDKがあるし、ドキュメントもそれなりにある
整形されたデータはそれほど違いはないように思えるけど、個人的にちょっとポイントとなる要素があってその点を踏まえるとFirecrawlのほうがやや良かった印象は持った。
ただ両方ともそれなりにいろいろ設定はあるし、今回は細かいところまで見ていないので、ある程度使い込んだ上で価格も踏まえて、ってところではある。
最初にセットアップしたときは実はうまく動かなかったのだけど、誰かのIssueに相乗りしていろいろ試したり、コードおっかけてPRしたので、今はセットアップで詰まることはないと思う。マージがめちゃ迅速でありがたかった。
Jina Readerも一応セルフホストできる、の、かな???Firebaseにインストールするっぽい。
ちょっとJina Reader使ってて気になったのは、ヘッダーとかサイドメニューとかも拾ってきちゃうところ。
FireCrawlだとonlyMainContentというオプションを付けると、ヘッダーやフッター、ナビゲーション関連のコンテンツを取得せずに、メインのコンテンツだけ取得してくれる。
ここは結構大きいなぁ、、、単一URLじゃなくてクローリングできるってのもメリットとしてはあるんだけども、こちらの方がメリットある、
セルフホストでもonlyMainContentが有効になるか確認してみた。
対象は https://docs.llamaindex.ai/en/latest/module_guides/workflow/のページ。
onlyMainContentを有効にしなかった場合
$ curl -X POST http://X.X.X.X:3002/v0/scrape \
-H 'Content-Type: application/json' \
-d '{ "url":"https://docs.llamaindex.ai/en/latest/module_guides/workflow/"}' \
| jq -r .data.content
サイドメニューが出力されている
[Skip to content](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflows)
[](https://docs.llamaindex.ai/en/latest/ "LlamaIndex")
LlamaIndex
Workflows
Initializing search
* [Home](https://docs.llamaindex.ai/en/latest/)
* [Learn](https://docs.llamaindex.ai/en/latest/understanding/)
* [Use Cases](https://docs.llamaindex.ai/en/latest/use_cases/)
* [Examples](https://docs.llamaindex.ai/en/latest/examples/)
* [Component Guides](https://docs.llamaindex.ai/en/latest/module_guides/)
* [Advanced Topics](https://docs.llamaindex.ai/en/latest/optimizing/production_rag/)
* [API Reference](https://docs.llamaindex.ai/en/latest/api_reference/)
* [Open-Source Community](https://docs.llamaindex.ai/en/latest/community/integrations/)
* [LlamaCloud](https://docs.llamaindex.ai/en/latest/llama_cloud/)
[](https://docs.llamaindex.ai/en/latest/ "LlamaIndex")
LlamaIndex
* [ ]
[Home](https://docs.llamaindex.ai/en/latest/)
Home
* [High-Level Concepts](https://docs.llamaindex.ai/en/latest/getting_started/concepts/)
* [Installation and Setup](https://docs.llamaindex.ai/en/latest/getting_started/installation/)
* [How to read these docs](https://docs.llamaindex.ai/en/latest/getting_started/reading/)
* [ ] Starter Examples
Starter Examples
長いので省略するけど、ほんとに長い。。。
Table of contents
* [Getting Started](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#getting-started)
* [Defining Workflow Events](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#defining-workflow-events)
* [Setting up the Workflow Class](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#setting-up-the-workflow-class)
* [Workflow Entry Points](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflow-entry-points)
* [Workflow Exit Points](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflow-exit-points)
* [Running the Workflow](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#running-the-workflow)
* [Drawing the Workflow](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#drawing-the-workflow)
* [Working with Global Context/State](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#working-with-global-contextstate)
* [Waiting for Multiple Events](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#waiting-for-multiple-events)
* [Stepwise Execution](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#stepwise-execution)
* [Decorating non-class Functions](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#decorating-non-class-functions)
* [Examples](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#examples)
Workflows[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflows "Permanent link")
======================================================================================================
A `Workflow` in LlamaIndex is an event-driven abstraction used to chain together several events. Workflows are made up of `steps`, with each step responsible for handling certain event types and emitting new events.
`Workflow`s in LlamaIndex work by decorating function with a `@step()` decorator. This is used to infer the input and output types of each workflow for validation, and ensures each step only runs when an accepted event is ready.
You can create a `Workflow` to do anything! Build an agent, a RAG flow, an extraction flow, or anything else you want.
Workflows are also automatically instrumented, so you get observability into each step using tools like [Arize Pheonix](https://docs.llamaindex.ai/en/latest/module_guides/observability/#arize-phoenix-local)
. (**NOTE:** Observability works for integrations that take advantage of the newer instrumentation system. Usage may vary.)
Tip
Workflows make async a first-class citizen, and this page assumes you are running in an async environment. What this means for you is setting up your code for async properly. If you are already running in a server like FastAPI, or in a notebook, you can freely use await already!
If you are running your own python scripts, its best practice to have a single async entry point.
`async def main(): w = MyWorkflow(...) result = await w.run(...) print(result) if __name__ == "__main__": import asyncio asyncio.run(main())`
Getting Started[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#getting-started "Permanent link")
------------------------------------------------------------------------------------------------------------------
As an illustrative example, let's consider a naive workflow where a joke is generated and then critiqued.
``from llama_index.core.workflow import ( Event, StartEvent, StopEvent, Workflow, step, ) # `pip install llama-index-llms-openai` if you don't already have it from llama_index.llms.openai import OpenAI class JokeEvent(Event): joke: str class JokeFlow(Workflow): llm = OpenAI() @step() async def generate_joke(self, ev: StartEvent) -> JokeEvent: topic = ev.topic prompt = f"Write your best joke about {topic}." response = await self.llm.acomplete(prompt) return JokeEvent(joke=str(response)) @step() async def critique_joke(self, ev: JokeEvent) -> StopEvent: joke = ev.joke prompt = f"Give a thorough analysis and critique of the following joke: {joke}" response = await self.llm.acomplete(prompt) return StopEvent(result=str(response)) w = JokeFlow(timeout=60, verbose=False) result = await w.run(topic="pirates") print(str(result))``
There's a few moving pieces here, so let's go through this piece by piece.
### Defining Workflow Events[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#defining-workflow-events "Permanent link")
`class JokeEvent(Event): joke: str`
Events are user-defined pydantic objects. You control the attributes and any other auxiliary methods. In this case, our workflow relies on a single user-defined event, the `JokeEvent`.
### Setting up the Workflow Class[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#setting-up-the-workflow-class "Permanent link")
`class JokeFlow(Workflow): llm = OpenAI(model="gpt-4o-mini") ...`
Our workflow is implemented by subclassing the `Workflow` class. For simplicity, we attached a static `OpenAI` llm instance.
### Workflow Entry Points[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflow-entry-points "Permanent link")
`class JokeFlow(Workflow): ... @step() async def generate_joke(self, ev: StartEvent) -> JokeEvent: topic = ev.topic prompt = f"Write your best joke about {topic}." response = await self.llm.acomplete(prompt) return JokeEvent(joke=str(response)) ...`
Here, we come to the entry-point of our workflow. While events are use-defined, there are two special-case events, the `StartEvent` and the `StopEvent`. Here, the `StartEvent` signifies where to send the initial workflow input.
The `StartEvent` is a bit of a special object since it can hold arbitrary attributes. Here, we accessed the topic with `ev.topic`, which would raise an error if it wasn't there. You could also do `ev.get("topic")` to handle the case where the attribute might not be there without raising an error.
At this point, you may have noticed that we haven't explicitly told the workflow what events are handled by which steps. Instead, the `@step()` decorator is used to infer the input and output types of each step. Furthermore, these inferred input and output types are also used to verify for you that the workflow is valid before running!
### Workflow Exit Points[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflow-exit-points "Permanent link")
`class JokeFlow(Workflow): ... @step() async def critique_joke(self, ev: JokeEvent) -> StopEvent: joke = ev.joke prompt = f"Give a thorough analysis and critique of the following joke: {joke}" response = await self.llm.acomplete(prompt) return StopEvent(result=str(response)) ...`
Here, we have our second, and last step, in the workflow. We know its the last step because the special `StopEvent` is returned. When the workflow encounters a returned `StopEvent`, it immediately stops the workflow and returns whatever the result was.
In this case, the result is a string, but it could be a dictionary, list, or any other object.
### Running the Workflow[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#running-the-workflow "Permanent link")
`w = JokeFlow(timeout=60, verbose=False) result = await w.run(topic="pirates") print(str(result))`
Lastly, we create and run the workflow. There are some settings like timeouts (in seconds) and verbosity to help with debugging.
The `.run()` method is async, so we use await here to wait for the result.
Drawing the Workflow[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#drawing-the-workflow "Permanent link")
----------------------------------------------------------------------------------------------------------------------------
Workflows can be visualized, using the power of type annotations in your step definitions. You can either draw all possible paths through the workflow, or the most recent execution, to help with debugging.
`from llama_index.core.workflow import ( draw_all_possible_paths, draw_most_recent_execution, ) # Draw all draw_all_possible_paths(JokeFlow, filename="joke_flow_all.html") # Draw an execution w = JokeFlow() await w.run(topic="Pirates") draw_most_recent_execution(w, filename="joke_flow_recent.html")`
Working with Global Context/State[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#working-with-global-contextstate "Permanent link")
-----------------------------------------------------------------------------------------------------------------------------------------------------
Optionally, you can choose to use global context between steps. For example, maybe multiple steps access the original `query` input from the user. You can store this in global context so that every step has access.
`from llama_index.core.workflow import Context @step(pass_context=True) async def query(self, ctx: Context, ev: QueryEvent) -> StopEvent: # retrieve from context query = ctx.data.get("query") # store in context ctx["key"] = "val" result = run_query(query) return StopEvent(result=result)`
Waiting for Multiple Events[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#waiting-for-multiple-events "Permanent link")
------------------------------------------------------------------------------------------------------------------------------------------
The context does more than just hold data, it also provides utilities to buffer and wait for multiple events.
For example, you might have a step like:
`@step(pass_context=True) async def query( self, ctx: Context, ev: QueryEvent | RetrieveEvent ) -> StopEvent | None: data = ctx.collect_events(evm[QueryEvent, RetrieveEvent]) # check if we can run if data is None: return None # use buffered events print(data[0]) # QueryEvent print(data[1]) # RetrieveEvent`
Using `ctx.collect_events()` we can buffer and wait for ALL expected events to arrive. This function will only return data (in the requested order) once all events have arrived.
Stepwise Execution[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#stepwise-execution "Permanent link")
------------------------------------------------------------------------------------------------------------------------
Workflows have built-in utilities for stepwise execution, allowing you to control execution and debug state as things progress.
`w = JokeFlow(...) # Kick off the workflow w.run_step(topic="Pirates") # Iterate until done while not w.is_done(): w.run_step() # Get the final result result = w.get_result()`
Decorating non-class Functions[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#decorating-non-class-functions "Permanent link")
------------------------------------------------------------------------------------------------------------------------------------------------
You can also decorate and attach steps to a workflow without subclassing it.
Below is the `JokeFlow` from earlier, but defined without subclassing.
`from llama_index.core.workflow import ( Event, StartEvent, StopEvent, Workflow, step, ) class JokeEvent(Event): joke: str joke_flow = Workflow(timeout=60, verbose=True) @step(workflow=joke_flow) async def generate_joke(ev: StartEvent) -> JokeEvent: topic = ev.topic prompt = f"Write your best joke about {topic}." response = await llm.acomplete(prompt) return JokeEvent(joke=str(response)) @step(workflow=joke_flow) async def critique_joke(ev: JokeEvent) -> StopEvent: joke = ev.joke prompt = ( f"Give a thorough analysis and critique of the following joke: {joke}" ) response = await llm.acomplete(prompt) return StopEvent(result=str(response))`
Examples[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#examples "Permanent link")
----------------------------------------------------------------------------------------------------
You can find many useful examples of using workflows in the notebooks below:
* [RAG + Reranking](https://docs.llamaindex.ai/en/latest/examples/workflow/rag/)
* [Reliable Structured Generation](https://docs.llamaindex.ai/en/latest/examples/workflow/reflection/)
* [Function Calling Agent](https://docs.llamaindex.ai/en/latest/examples/workflow/function_calling_agent/)
* [ReAct Agent](https://docs.llamaindex.ai/en/latest/examples/workflow/react_agent/)
Back to top
[Previous\
\
Routing](https://docs.llamaindex.ai/en/latest/module_guides/querying/router/)
[Next\
\
Query Pipeline](https://docs.llamaindex.ai/en/latest/module_guides/querying/pipeline/)
Hi, how can I help you?
🦙
onlyMainContentを有効にした場合
$ curl -X POST http://X.X.X.X:3002/v0/scrape \
-H 'Content-Type: application/json' \
-d '{ "url":"https://docs.llamaindex.ai/en/latest/module_guides/workflow/", "pageOptions": {"onlyMainContent": true}}' \
\ jq -r .data.content
こちらはサイドメニューが出力されていない。
[Skip to content](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflows)
Workflows[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflows "Permanent link")
======================================================================================================
A `Workflow` in LlamaIndex is an event-driven abstraction used to chain together several events. Workflows are made up of `steps`, with each step responsible for handling certain event types and emitting new events.
`Workflow`s in LlamaIndex work by decorating function with a `@step()` decorator. This is used to infer the input and output types of each workflow for validation, and ensures each step only runs when an accepted event is ready.
You can create a `Workflow` to do anything! Build an agent, a RAG flow, an extraction flow, or anything else you want.
Workflows are also automatically instrumented, so you get observability into each step using tools like [Arize Pheonix](https://docs.llamaindex.ai/en/latest/module_guides/observability/#arize-phoenix-local)
. (**NOTE:** Observability works for integrations that take advantage of the newer instrumentation system. Usage may vary.)
Tip
Workflows make async a first-class citizen, and this page assumes you are running in an async environment. What this means for you is setting up your code for async properly. If you are already running in a server like FastAPI, or in a notebook, you can freely use await already!
If you are running your own python scripts, its best practice to have a single async entry point.
`async def main(): w = MyWorkflow(...) result = await w.run(...) print(result) if __name__ == "__main__": import asyncio asyncio.run(main())`
Getting Started[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#getting-started "Permanent link")
------------------------------------------------------------------------------------------------------------------
As an illustrative example, let's consider a naive workflow where a joke is generated and then critiqued.
``from llama_index.core.workflow import ( Event, StartEvent, StopEvent, Workflow, step, ) # `pip install llama-index-llms-openai` if you don't already have it from llama_index.llms.openai import OpenAI class JokeEvent(Event): joke: str class JokeFlow(Workflow): llm = OpenAI() @step() async def generate_joke(self, ev: StartEvent) -> JokeEvent: topic = ev.topic prompt = f"Write your best joke about {topic}." response = await self.llm.acomplete(prompt) return JokeEvent(joke=str(response)) @step() async def critique_joke(self, ev: JokeEvent) -> StopEvent: joke = ev.joke prompt = f"Give a thorough analysis and critique of the following joke: {joke}" response = await self.llm.acomplete(prompt) return StopEvent(result=str(response)) w = JokeFlow(timeout=60, verbose=False) result = await w.run(topic="pirates") print(str(result))``
There's a few moving pieces here, so let's go through this piece by piece.
### Defining Workflow Events[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#defining-workflow-events "Permanent link")
`class JokeEvent(Event): joke: str`
Events are user-defined pydantic objects. You control the attributes and any other auxiliary methods. In this case, our workflow relies on a single user-defined event, the `JokeEvent`.
### Setting up the Workflow Class[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#setting-up-the-workflow-class "Permanent link")
`class JokeFlow(Workflow): llm = OpenAI(model="gpt-4o-mini") ...`
Our workflow is implemented by subclassing the `Workflow` class. For simplicity, we attached a static `OpenAI` llm instance.
### Workflow Entry Points[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflow-entry-points "Permanent link")
`class JokeFlow(Workflow): ... @step() async def generate_joke(self, ev: StartEvent) -> JokeEvent: topic = ev.topic prompt = f"Write your best joke about {topic}." response = await self.llm.acomplete(prompt) return JokeEvent(joke=str(response)) ...`
Here, we come to the entry-point of our workflow. While events are use-defined, there are two special-case events, the `StartEvent` and the `StopEvent`. Here, the `StartEvent` signifies where to send the initial workflow input.
The `StartEvent` is a bit of a special object since it can hold arbitrary attributes. Here, we accessed the topic with `ev.topic`, which would raise an error if it wasn't there. You could also do `ev.get("topic")` to handle the case where the attribute might not be there without raising an error.
At this point, you may have noticed that we haven't explicitly told the workflow what events are handled by which steps. Instead, the `@step()` decorator is used to infer the input and output types of each step. Furthermore, these inferred input and output types are also used to verify for you that the workflow is valid before running!
### Workflow Exit Points[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#workflow-exit-points "Permanent link")
`class JokeFlow(Workflow): ... @step() async def critique_joke(self, ev: JokeEvent) -> StopEvent: joke = ev.joke prompt = f"Give a thorough analysis and critique of the following joke: {joke}" response = await self.llm.acomplete(prompt) return StopEvent(result=str(response)) ...`
Here, we have our second, and last step, in the workflow. We know its the last step because the special `StopEvent` is returned. When the workflow encounters a returned `StopEvent`, it immediately stops the workflow and returns whatever the result was.
In this case, the result is a string, but it could be a dictionary, list, or any other object.
### Running the Workflow[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#running-the-workflow "Permanent link")
`w = JokeFlow(timeout=60, verbose=False) result = await w.run(topic="pirates") print(str(result))`
Lastly, we create and run the workflow. There are some settings like timeouts (in seconds) and verbosity to help with debugging.
The `.run()` method is async, so we use await here to wait for the result.
Drawing the Workflow[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#drawing-the-workflow "Permanent link")
----------------------------------------------------------------------------------------------------------------------------
Workflows can be visualized, using the power of type annotations in your step definitions. You can either draw all possible paths through the workflow, or the most recent execution, to help with debugging.
`from llama_index.core.workflow import ( draw_all_possible_paths, draw_most_recent_execution, ) # Draw all draw_all_possible_paths(JokeFlow, filename="joke_flow_all.html") # Draw an execution w = JokeFlow() await w.run(topic="Pirates") draw_most_recent_execution(w, filename="joke_flow_recent.html")`
Working with Global Context/State[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#working-with-global-contextstate "Permanent link")
-----------------------------------------------------------------------------------------------------------------------------------------------------
Optionally, you can choose to use global context between steps. For example, maybe multiple steps access the original `query` input from the user. You can store this in global context so that every step has access.
`from llama_index.core.workflow import Context @step(pass_context=True) async def query(self, ctx: Context, ev: QueryEvent) -> StopEvent: # retrieve from context query = ctx.data.get("query") # store in context ctx["key"] = "val" result = run_query(query) return StopEvent(result=result)`
Waiting for Multiple Events[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#waiting-for-multiple-events "Permanent link")
------------------------------------------------------------------------------------------------------------------------------------------
The context does more than just hold data, it also provides utilities to buffer and wait for multiple events.
For example, you might have a step like:
`@step(pass_context=True) async def query( self, ctx: Context, ev: QueryEvent | RetrieveEvent ) -> StopEvent | None: data = ctx.collect_events(evm[QueryEvent, RetrieveEvent]) # check if we can run if data is None: return None # use buffered events print(data[0]) # QueryEvent print(data[1]) # RetrieveEvent`
Using `ctx.collect_events()` we can buffer and wait for ALL expected events to arrive. This function will only return data (in the requested order) once all events have arrived.
Stepwise Execution[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#stepwise-execution "Permanent link")
------------------------------------------------------------------------------------------------------------------------
Workflows have built-in utilities for stepwise execution, allowing you to control execution and debug state as things progress.
`w = JokeFlow(...) # Kick off the workflow w.run_step(topic="Pirates") # Iterate until done while not w.is_done(): w.run_step() # Get the final result result = w.get_result()`
Decorating non-class Functions[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#decorating-non-class-functions "Permanent link")
------------------------------------------------------------------------------------------------------------------------------------------------
You can also decorate and attach steps to a workflow without subclassing it.
Below is the `JokeFlow` from earlier, but defined without subclassing.
`from llama_index.core.workflow import ( Event, StartEvent, StopEvent, Workflow, step, ) class JokeEvent(Event): joke: str joke_flow = Workflow(timeout=60, verbose=True) @step(workflow=joke_flow) async def generate_joke(ev: StartEvent) -> JokeEvent: topic = ev.topic prompt = f"Write your best joke about {topic}." response = await llm.acomplete(prompt) return JokeEvent(joke=str(response)) @step(workflow=joke_flow) async def critique_joke(ev: JokeEvent) -> StopEvent: joke = ev.joke prompt = ( f"Give a thorough analysis and critique of the following joke: {joke}" ) response = await llm.acomplete(prompt) return StopEvent(result=str(response))`
Examples[#](https://docs.llamaindex.ai/en/latest/module_guides/workflow/#examples "Permanent link")
----------------------------------------------------------------------------------------------------
You can find many useful examples of using workflows in the notebooks below:
* [RAG + Reranking](https://docs.llamaindex.ai/en/latest/examples/workflow/rag/)
* [Reliable Structured Generation](https://docs.llamaindex.ai/en/latest/examples/workflow/reflection/)
* [Function Calling Agent](https://docs.llamaindex.ai/en/latest/examples/workflow/function_calling_agent/)
* [ReAct Agent](https://docs.llamaindex.ai/en/latest/examples/workflow/react_agent/)
Back to top
Hi, how can I help you?
🦙
curlの統計を見てもボリュームがぜんぜん違う
onlyMainContentを有効にしなかった場合
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 389k 100 389k 100 71 94984 16 0:00:04 0:00:04 --:--:-- 95131
onlyMainContentを有効にした場合
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 23519 100 23406 100 113 5457 26 0:00:04 0:00:04 --:--:-- 5489
onlyMainContentをどう判断しているのかはわからないし、あらゆるサイトで上手くいくかどうかはわからないけど、このオプションはかなり有用。
複数URLからざっと情報集めるみたいなことをしたくて、最初にJina Readerを使って、Colaboratory向け・Streamlit向けで作ってみたのだけど、コンテンツサイズがデカくなりすぎてちょっと使えなかった。
ということで、onlyMainContentが効くFireCrawlを使って、StreamlitのGUI作ってみた

セルフホストで使うことを想定しているけども、一応FireCrawlのクラウドにも対応している。