ElevenLabsのTTSを試す
公式
日本語については以下にサンプルとかまとめられている。サンプル試した感じだとイマイチな感がある。。。
で、APIのドキュメントを上記から辿ると404になる・・・
ドキュメントは以下にあった。
APIリファレンス
Pythonクライアントは以下
ここのUsageに従って試してみる。Colaboratoryで。
パッケージインストール
!pip install elevenlabs
!pip freeze | grep -i elevenlabs
elevenlabs==1.10.0
音声を生成。再生用のヘルパー関数が用意されていて、これにnotebook=Trueを渡すと再生用のコントローラが表示される。
from elevenlabs import play
from elevenlabs.client import ElevenLabs
from google.colab import userdata
client = ElevenLabs(
api_key=userdata.get('ELEVENLABS_API_KEY')
)
audio = client.generate(
text="Hello! 你好! Hola! नमस्ते! Bonjour! こんにちは! مرحبا! 안녕하세요! Ciao! Cześć! Привіт! வணக்கம்!",
voice="Brian",
model="eleven_multilingual_v2"
)
play(audio, notebook=True)

モデル(model)は以下の2種類が指定できる。
- Eleven Multilingual v2 (
eleven_multilingual_v2)- 安定性、言語の多様性、アクセントの正確さに優れている。
- 29言語をサポート。
- ほとんどのユースケースで推奨。
- Eleven Turbo v2.5 (
eleven_turbo_v2_5)- 高品質で、レスポンスが高速
- スピードが重要な開発者向けの用途に最適。
- 32言語をサポート。
なお、日本語はどちらにも含まれている。モデルについては以下を参照。上記以外の古いバージョンのモデルもある様子。
voiceで音声の声質を選択できる。以下で一覧を確認。
import json
# 以下で全音声の情報を取得できる
#print(json.dumps(response.dict(), indent=2, ensure_ascii=False))
# 音声の特徴がわかりやすいものだけをピックアップしてみた
for voice in response.voices:
print("Voice Name:", voice.name)
print("Voice ID:", voice.voice_id)
print(voice.labels)
print()
Voice Name: Aria
Voice ID: 9BWtsMINqrJLrRacOk9x
{'accent': 'American', 'description': 'expressive', 'age': 'middle-aged', 'gender': 'female', 'use_case': 'social media'}
Voice Name: Roger
Voice ID: CwhRBWXzGAHq8TQ4Fs17
{'accent': 'American', 'description': 'confident', 'age': 'middle-aged', 'gender': 'male', 'use_case': 'social media'}
Voice Name: Sarah
Voice ID: EXAVITQu4vr4xnSDxMaL
{'accent': 'american', 'description': 'soft', 'age': 'young', 'gender': 'female', 'use_case': 'news'}
Voice Name: Laura
Voice ID: FGY2WhTYpPnrIDTdsKH5
{'accent': 'American', 'description': 'upbeat', 'age': 'young', 'gender': 'female', 'use_case': 'social media'}
Voice Name: Charlie
Voice ID: IKne3meq5aSn9XLyUdCD
{'accent': 'Australian', 'description': 'natural', 'age': 'middle aged', 'gender': 'male', 'use_case': 'conversational'}
Voice Name: George
Voice ID: JBFqnCBsd6RMkjVDRZzb
{'accent': 'British', 'description': 'warm', 'age': 'middle aged', 'gender': 'male', 'use_case': 'narration'}
Voice Name: Callum
Voice ID: N2lVS1w4EtoT3dr4eOWO
{'accent': 'Transatlantic', 'description': 'intense', 'age': 'middle-aged', 'gender': 'male', 'use_case': 'characters'}
Voice Name: River
Voice ID: SAz9YHcvj6GT2YYXdXww
{'accent': 'American', 'description': 'confident', 'age': 'middle-aged', 'gender': 'non-binary', 'use_case': 'social media'}
Voice Name: Liam
Voice ID: TX3LPaxmHKxFdv7VOQHJ
{'accent': 'American', 'description': 'articulate', 'age': 'young', 'gender': 'male', 'use_case': 'narration'}
Voice Name: Charlotte
Voice ID: XB0fDUnXU5powFXDhCwa
{'accent': 'Swedish', 'description': 'seductive', 'age': 'young', 'gender': 'female', 'use_case': 'characters'}
Voice Name: Alice
Voice ID: Xb7hH8MSUJpSbSDYk0k2
{'accent': 'British', 'description': 'confident', 'age': 'middle-aged', 'gender': 'female', 'use_case': 'news'}
Voice Name: Matilda
Voice ID: XrExE9yKIg1WjnnlVkGX
{'accent': 'American', 'description': 'friendly', 'age': 'middle-aged', 'gender': 'female', 'use_case': 'narration'}
Voice Name: Will
Voice ID: bIHbv24MWmeRgasZH58o
{'accent': 'American', 'description': 'friendly', 'age': 'young', 'gender': 'male', 'use_case': 'social media'}
Voice Name: Jessica
Voice ID: cgSgspJ2msm6clMCkdW9
{'accent': 'American', 'description': 'expressive', 'age': 'young', 'gender': 'female', 'use_case': 'conversational'}
Voice Name: Eric
Voice ID: cjVigY5qzO86Huf0OWal
{'accent': 'American', 'description': 'friendly', 'age': 'middle-aged', 'gender': 'male', 'use_case': 'conversational'}
Voice Name: Chris
Voice ID: iP95p4xoKVk53GoZ742B
{'accent': 'American', 'description': 'casual', 'age': 'middle-aged', 'gender': 'male', 'use_case': 'conversational'}
Voice Name: Brian
Voice ID: nPczCjzI2devNBz1zQrb
{'accent': 'American', 'description': 'deep', 'age': 'middle-aged', 'gender': 'male', 'use_case': 'narration'}
Voice Name: Daniel
Voice ID: onwK4e9ZLuTAKqWW03F9
{'accent': 'British', 'description': 'authoritative', 'age': 'middle-aged', 'gender': 'male', 'use_case': 'news'}
Voice Name: Lily
Voice ID: pFZP5JQG7iQjIQuC4Bku
{'accent': 'British', 'description': 'warm', 'age': 'middle-aged', 'gender': 'female', 'use_case': 'narration'}
Voice Name: Bill
Voice ID: pqHfZKP75CvOlQylNhV4
{'accent': 'American', 'description': 'trustworthy', 'age': 'old', 'gender': 'male', 'use_case': 'narration'}
なお、ElevenLabsには音声クローンの機能があり、例えば自分の音声データから音声を作成して、それを使ってTTSすることもできるが、ここでは触れない。
話し方をパラメータで調整することができる。
from elevenlabs import Voice, VoiceSettings, play
from elevenlabs.client import ElevenLabs
client = ElevenLabs(
api_key=userdata.get('ELEVENLABS_API_KEY')
)
audio = client.generate(
text="こんにちは!私の名前はアリアです!",
model="eleven_multilingual_v2",
voice=Voice(
voice_id='9BWtsMINqrJLrRacOk9x', # 音声のモデルIDで指定するみたい
settings=VoiceSettings(
stability=0.71,
similarity_boost=0.5,
style=0.0,
use_speaker_boost=True
)
)
)
play(audio, notebook=True)
調整できるパラメータは以下にある
Stability
Stabilityのスライダーは、音声の安定性と各世代間のランダム性を決定します。このスライダーを下げると、音声の感情表現の幅が広がります。前述の通り、この値もオリジナルの音声に大きく影響されます。スライダーを低く設定しすぎると、ランダム性が強すぎて不自然なパフォーマンスとなり、キャラクターが早口になる可能性があります。逆に、スライダーを高く設定しすぎると、感情表現が乏しく単調な音声になる可能性があります。
Similarity
Similarityスライダーは、AIが音声を再現する際に、オリジナルの音声にどの程度近づけるかを決定します。オリジナルの音声の品質が低く、類似性スライダーが高く設定されている場合、オリジナルの録音にアーチファクトやバックグラウンドノイズが含まれていた場合、AIが音声を再現しようとすると、それらのノイズが再現される可能性があります。
Style Exaggeration
新しいモデルの導入に伴い、スタイルの誇張設定も追加されました。この設定は、オリジナルの話し手のスタイルを増幅しようと試みます。この設定は、0以外の値に設定すると、追加の計算リソースを消費し、レイテンシが増加する可能性があります。この設定を使用すると、オリジナルの音声のスタイルを強調し、模倣しようとするため、モデルの安定性が若干低下することが分かっています。
一般的には、この設定は常に0にしておくことをお勧めします。
Speaker Boost
これも新しいモデルで導入された設定です。この設定自体は非常にわかりやすく、オリジナルのスピーカーとの類似性を高めます。ただし、この設定を使用すると、計算負荷がやや高くなり、レイテンシが増加します。この設定による違いは、一般的にかなり微妙です。
その他にもいろいろAPIはあるようだが割愛。自分が知りたかったのはマルチリンガルをどう設定するのか?というところだったので。
料金
クレジット制になっていて、使用するモデルごとに消費するクレジットが異なる様子。ちなみに無料枠だと10000クレジット/月で、TTSだけに限定すると以下のような目安になっていた。
- 高品質モデル
- 10000文字(〜10分)
- 高速モデル
- 20000文字(〜20分)
あとはざっと見た感じ同時接続数の制約が結構きついように思える、特に根拠があるわけではないんだけど。無料だと2まで。
プロンプトから音声を作成できる機能が追加されていた。
ElevenLabsのコンソールで、"Voices"から"Add new voice"をクリック

"Voice Design"を選択
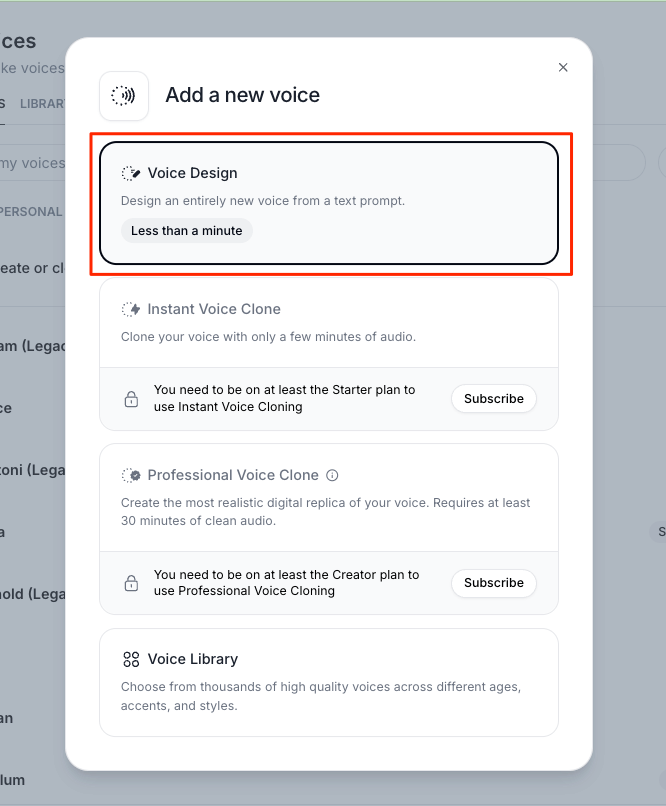
プロンプトと発話させたいテキストを入力して"Generate voice"をクリック。プロンプトについてはこちら。
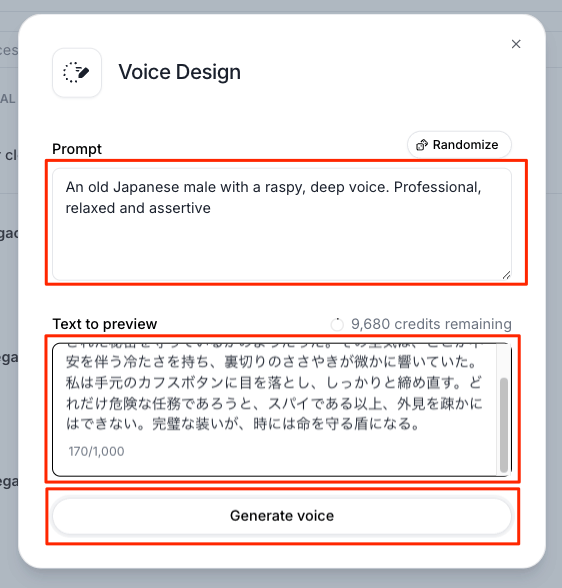
3パターン、音声が生成されるのでそれぞれプレビューを確認。気に入らなければ、プロンプト修正するなどして再度生成すればよい。一番良いと思うものを選択して"Select voice"をクリック。全部選んだりはできないみたい。
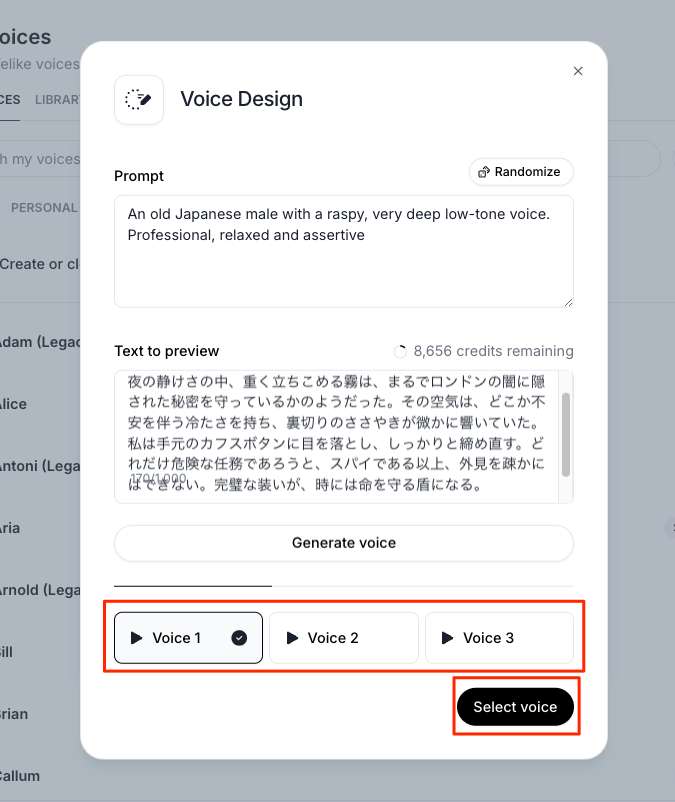
音声一覧で"Personal"を選択すると作成した音声がリストに載っている。"Use"をクリック。
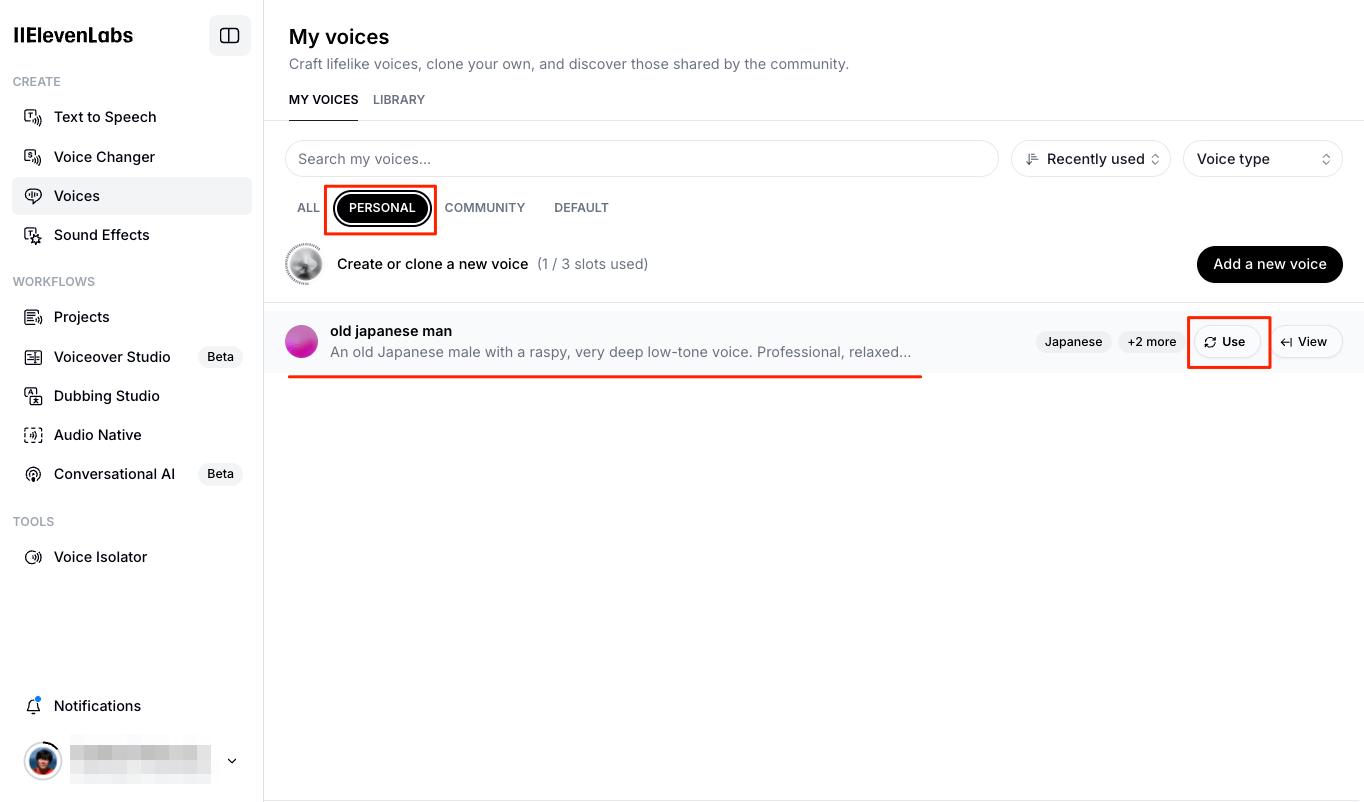
TTSのPlaygroundで実際に試すことができる
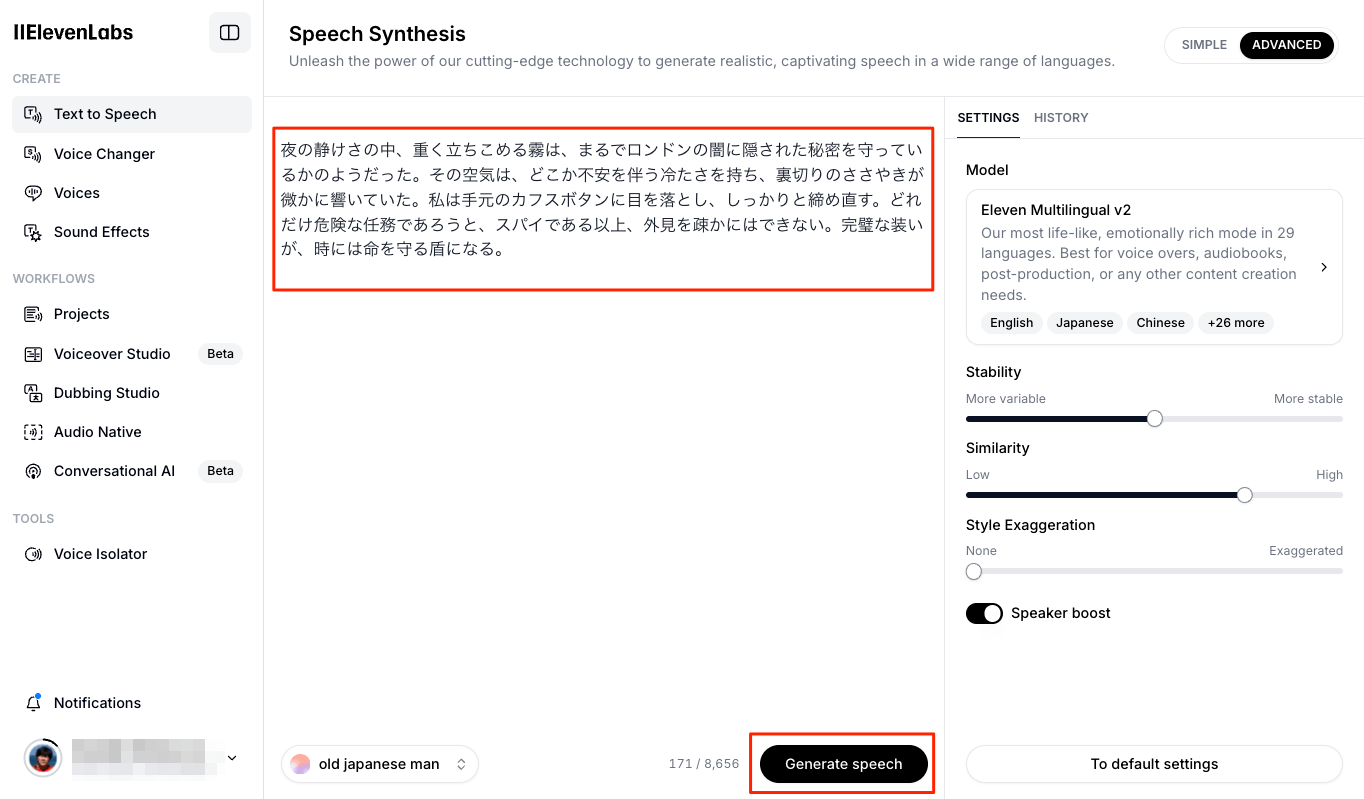
生成した音声はダウンロードが可能
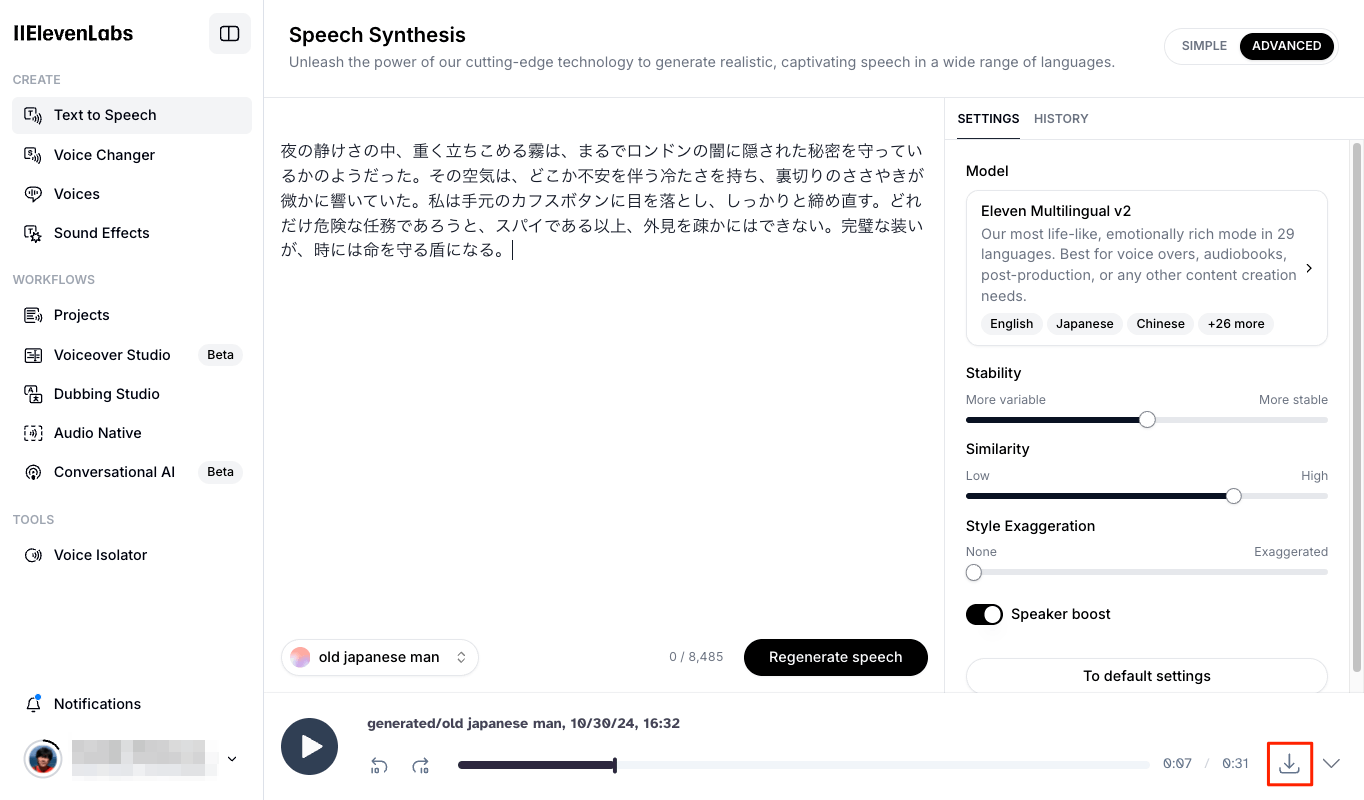
あと、試してないけど、 音声IDを指定すればSDKからも利用できるのではなかろうかできた。
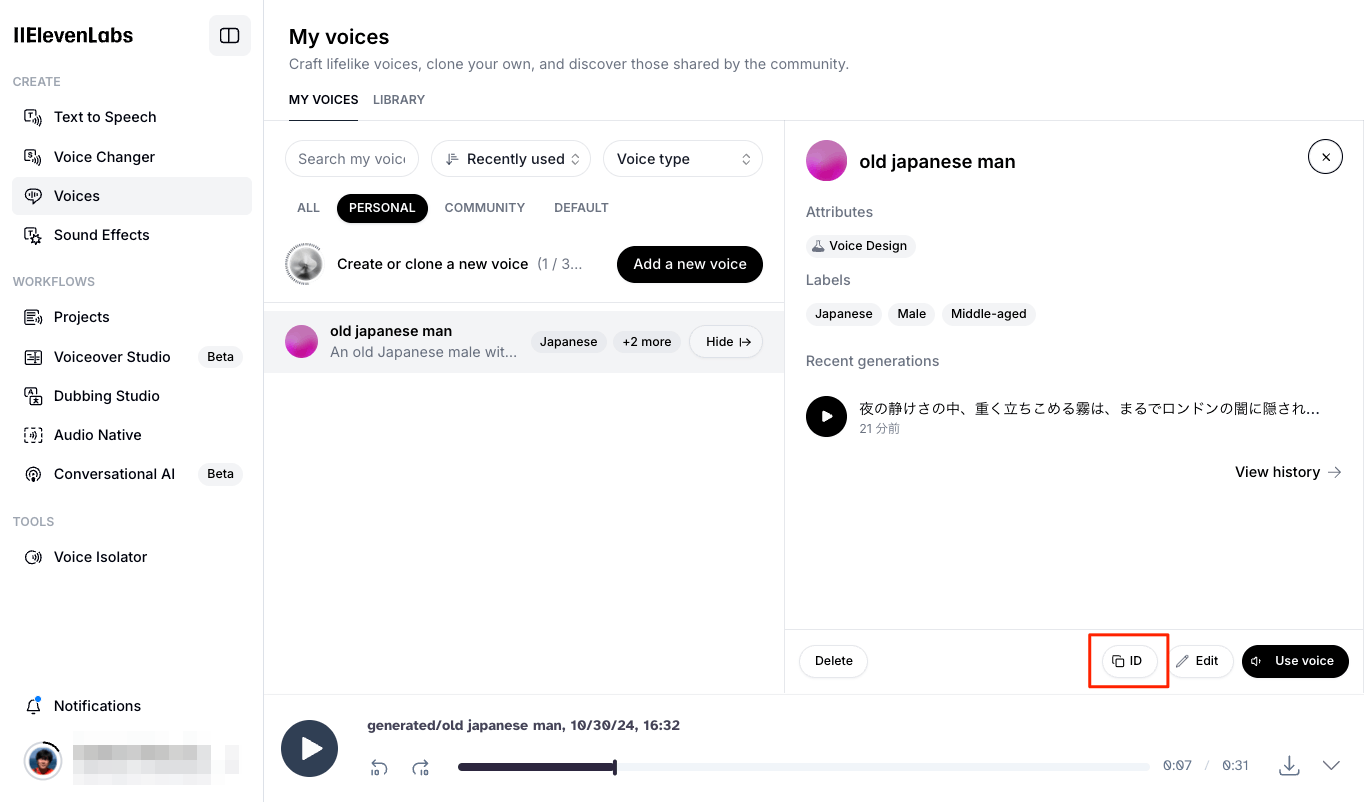
実際に作成した音声はこちら
ElevenLabsは正しく漢字を読めないケースが結構ある印象。
ドキュメントではなく、GitHubのREADMEを見てて気づいたのだけど、どうやらストリーミングで入力を受けることができるらしい。ということは、LLMの出力をストリーミングで受けて、レイテンシーなしにTTSできるはず。
ちょっとColaboratoryでは難しそうなので、ローカルのMac上でやる。
オーディオの再生にmpvが必要になるので、Homebrewでインストール。
brew install mpv
mpv --version
mpv 0.39.0 Copyright © 2000-2024 mpv/MPlayer/mplayer2 projects
libplacebo version: v7.349.0
FFmpeg version: 7.1
FFmpeg library versions:
libavcodec 61.19.100
libavdevice 61.3.100
libavfilter 10.4.100
libavformat 61.7.100
libavutil 59.39.100
libswresample 5.3.100
libswscale 8.3.100
Python仮想環境を作成。自分はmiseを使うが、適宜。
mkdir elevenlabs-work && cd elevenlabs-work
mise use python@3.12
cat << 'EOS' >> .mise.toml
[env]
_.python.venv = { path = ".venv", create = true }
EOS
mise trust
パッケージインストール
pip install elevenlabs openai
pip freeze | egrep -i "elevenlabs|openai"
elevenlabs==1.50.3
openai==1.59.5
APIキーを環境変数にセット
export OPENAI_API_KEY="XXXXXXXXXX"
export ELEVENLABS_API_KEY="XXXXXXXXXX"
ではサンプルコード。ちょっとREADMEのサンプルコードだとうまく行ってるかどうかがわからないので、以下を参考にLLMのストリーミング出力と組み合わせてみた。
from elevenlabs.client import ElevenLabs
from elevenlabs import stream
from openai import OpenAI
import os
def get_text_stream(prompt: str):
client = OpenAI()
for chunk in client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
stream=True,
):
if (text_chunk := chunk.choices[0].delta.content) is not None:
print(f"\"{text_chunk}\"")
yield text_chunk
elevenlabs_client = ElevenLabs(
api_key=os.environ['ELEVENLABS_API_KEY']
)
text_stream = get_text_stream("please tell me about Albert Einstein.")
audio_stream = elevenlabs_client.generate(
text=text_stream,
voice="Brian",
model="eleven_multilingual_v2",
stream=True,
)
output = stream(audio_stream)
実行してみるとわかるけど、LLMからのストリーミングが終わらないうちにTTSが開始される。
ただし、
Note: if chunks don't end with space or punctuation (" ", ".", "?", "!"), the stream will wait for more text.
とあって、おそらく以下の箇所。
日本語の句読点には対応していないように思えるので、日本語向けに分割するようなジェネレータ関数を挟む必要がありそう。