ElevenLabsのTTSを再び試す(日本語の方言を使う?)
以前に試したElevenLabs
いつの間にやらこんなものが
確かにGUIで見てみると、音声のフィルタ条件にある。

言語ごとに種類は異なるみたい。
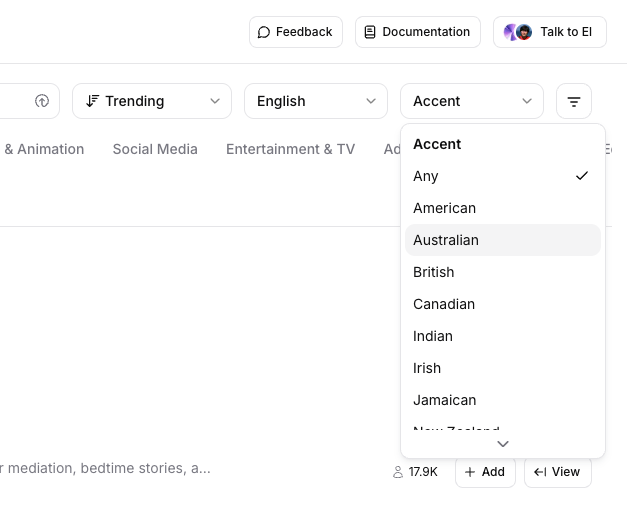
ただし、例えば関西弁でフィルタしてみるとこうなる。

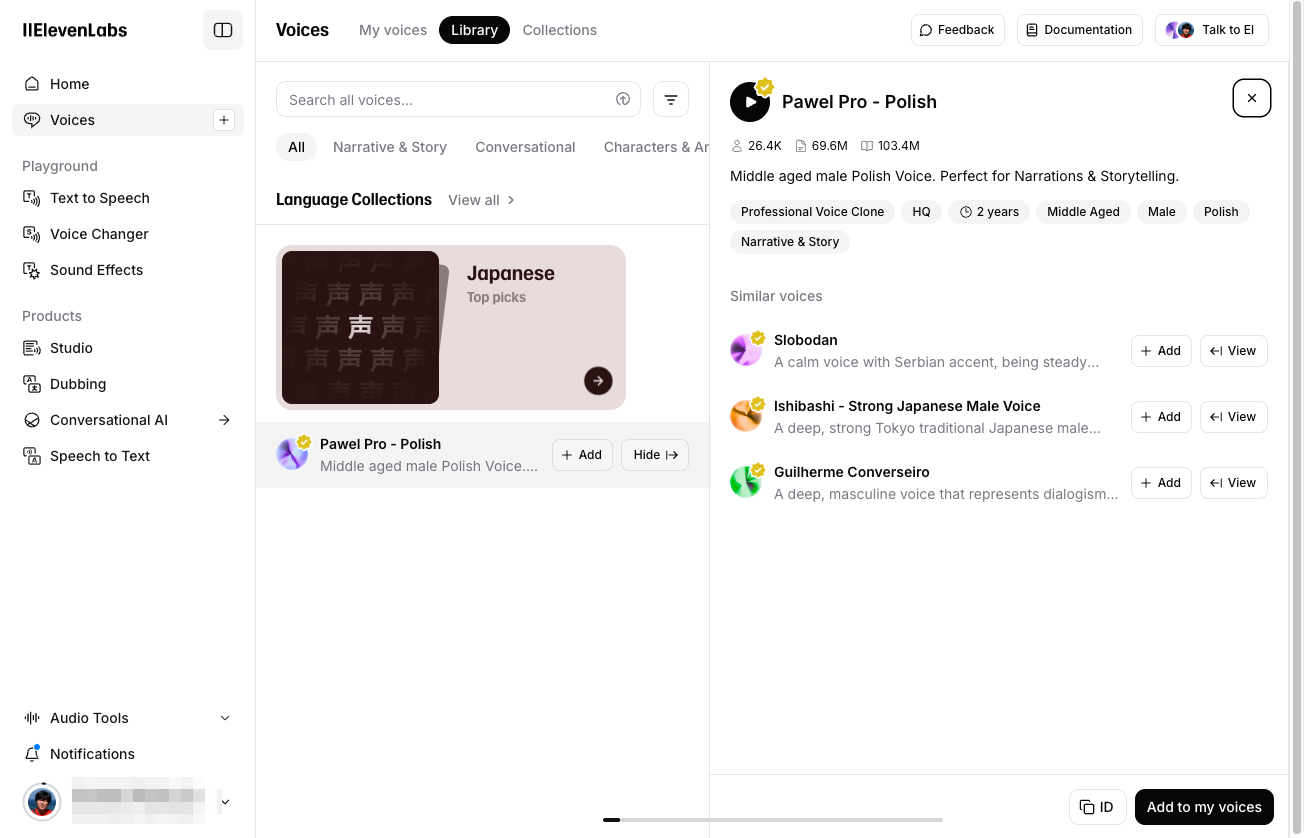
ポーランド語の音声、かつ、これはユーザが作成・シェアした音声が表示されている。
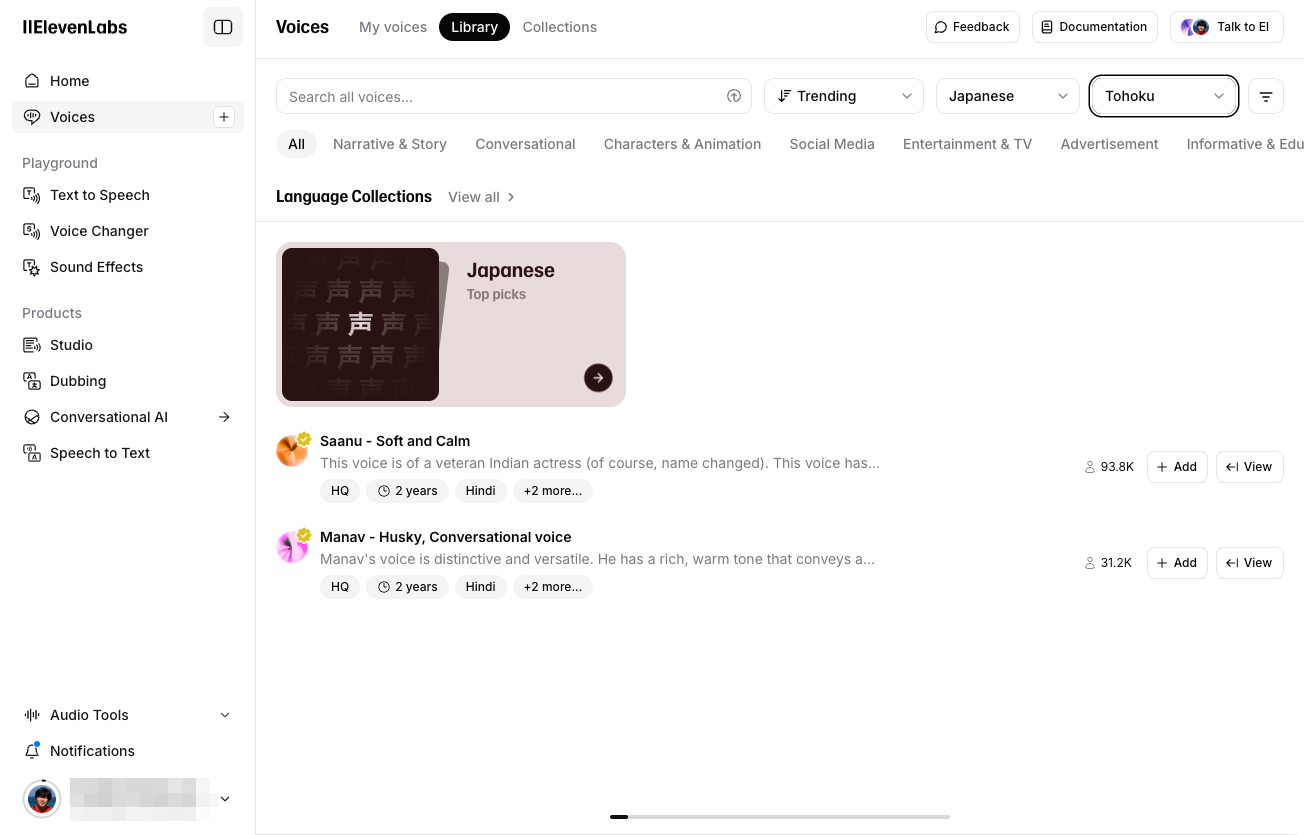
東北弁だと、ヒンズー語の音声、こちらもユーザが作成・シェアした音声が表示されている。
日本語モデルを選択して、Text to Speechのプレイグラウンドを開いても、それっぽいものはない。
ドキュメントを見ても単にアクセントでフィルタできる、ということしか書いてなくて、生成時にアクセントを設定できるようにも見えない。
ということは音声クローン周りかな?
Voice Designでやってみた。プロンプトにアクセントについて記載すると一応それっぽい感じのアクセントになってる様子。
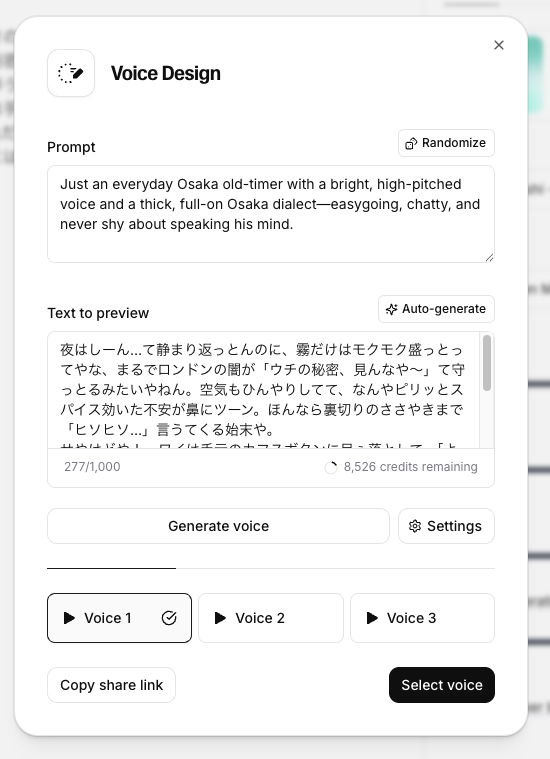
あぁ、なるほど、ラベルでつけれるんだ。多分これが検索でフィルタできるんだな。ただし、Voice Designで作った音声はシェアできないようで、Voice Cloneを使って音声を作成する必要がありそう。自分はVoice Cloneを試したことはないけども、作成する際にラベルを設定ができるんだろうと思う。

ちなみに、上で作った音声のサンプル。まあ関西弁っぽさは多少は出ているかな、完璧な関西弁には遠いけども。
ElevenLabsのVoice Cloneのドキュメント
シェアされた音声にはNotice Periodがつけれる、ということは、使えなくなるっていう可能性が常にあるんだよね。
ElevenLabs側で公式日本語音声、それにあわせてアクセントにも対応してくれるか、もしくは生成時に反映できるといいんだけどなぁ。
まあ発話の精度は以前と変わってないので、ちょっとこのあたりに期待
日本語の発話ですが、ELEVEN V3のモデルは段違いに自然な感じでした。
以前よりかなり良くなって、API提供に期待できそうですね!