OpenAI Chat Completion APIのパラメータ
普段よく使うもの以外にもいろいろ知らない・使ったことがないパラメータがあるので、実際に試してみて自分の知識を整理したい。
以下の記事でも説明されている
よく使うもの・知ってるもの
共通
modelmessages-
max_completion_tokens: 過去良く使っていたmax_tokensはDeprecatedらしい streamntemperaturetop_pfrequency_penaltypresence_penaltystopseed
Tool Call
toolstool_choiceparallel_tool_calls-
functions: Deprecated。toolsを使う。 -
function_call: Deprecated。tool_choice
マルチモーダルやStructured Output・Predicted Output
modalitiesaudioresponse_formatprediction
それ以外で気になったのものを見ていく。
store / metadata / user
どれも基本的にはOpenAI上にデータを残すのが目的。
| パラメータ | 用途 | デフォルト値 | 備考 |
|---|---|---|---|
store |
リクエストの出力をOpenAI上に保存するか | false ※オプション |
モデル蒸留や評価で使える ダッシュボードやAPIで参照できる |
metadata |
メタデータを追加でOpenAI上に保存できる。 ‐ 16対のKVペア ‐ キーは64文字以内 ‐ 値は512文字以内 |
- ※オプション | ダッシュボードやAPIで参照・フィルタできる。store=Trueが前提 |
user |
ユニークな識別子を付与 | - ※オプション | OpenAIがモニタリングしたりabuseの検知に使う |
ということでやってみる。Colaboratoryで。
OpenAIパッケージをインストール。
!pip install -U openai
!pip freeze | grep -i openai
openai==1.63.0
なお、最近のColaboratoryはどうやらopenaiパッケージはデフォルトで入っているようで、自分が確認した際には1.61.1がインストールされていた。このバージョンでもOpenAI上にデータを残すことはできるのだが、データの確認等がAPIからできないので、最新にしておくことをオススメ。
APIキーをセット。
from google.colab import userdata
import os
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
こんな感じで、store=Trueを付与してリクエストする。
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "developer", "content": "あなたは親切な日本語のアシスタントです。"},
{"role": "user", "content": "Hello!"}
],
store=True
)
print(completion.choices[0].message.content)
こんにちは!どうかされましたか?お手伝いできることがあれば教えてください。
でダッシュボードを見てみると以下のように記録されているのがわかる。

次にメタデータを追加してみる。モデルも変更しておいた。
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "developer", "content": "あなたは親切な日本語のアシスタントです。"},
{"role": "user", "content": "おはようございます!"}
],
store=True,
metadata={
"key1": "value1",
"key2": "value2",
"key3": "value3",
}
)
print(completion.choices[0].message.content)
おはようございます!今日はどんなことをお手伝いしましょうか?
メタデータ付きで付与されているのがわかる。

記録されたチャットは、フィルタしたり、検索したり、ということができる様子。

メタデータを指定した場合はこれでフィルタできる。

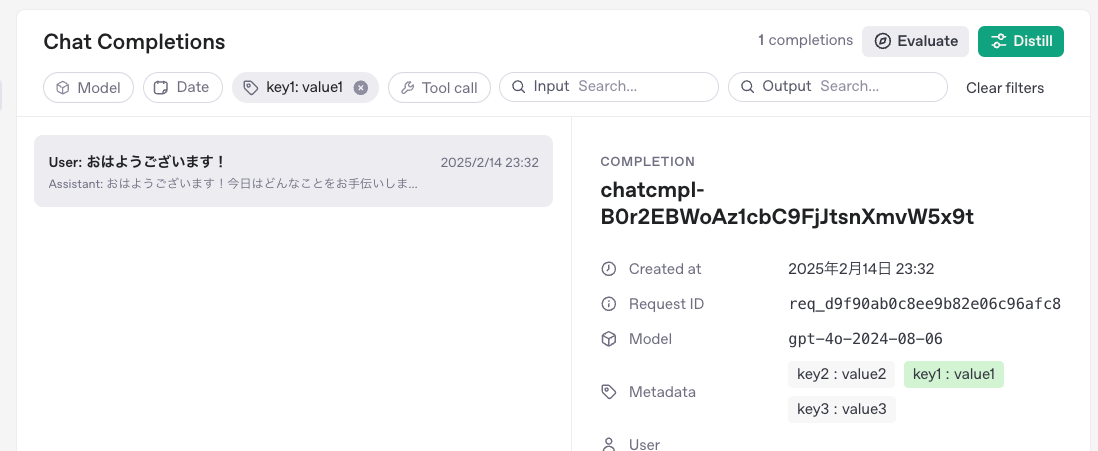
なので、ここで絞り込んだりして、評価やモデル蒸留に使える、ということなのだろう。

userについても試してみる。
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "developer", "content": "あなたは親切な日本語のアシスタントです。"},
{"role": "user", "content": "こんにちは。私の名前は太郎です。"}
],
user="taro_12345"
)
print(completion.choices[0].message.content)
userは別にstore=Trueがなくても使える。ただし、当然ダッシュボードには表示されない。
store=Trueをつけて送信すれば登録されるし、Userに指定した文字列も確認できる。
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "developer", "content": "あなたは親切な日本語のアシスタントです。"},
{"role": "user", "content": "こんにちは。私の名前は花子です。"}
],
store=True,
user="hanako_67890"
)
print(completion.choices[0].message.content)

ただ登録したとしても、これを使ってフィルタするようなメニューはない。

じゃあ何が嬉しいの?というところは以下にある。
リクエストにエンドユーザーのIDを記載して送信することは、OpenAIによる監視と不正行為の検出に役立つ便利なツールとなります。これにより、OpenAIがアプリケーションでポリシー違反を検出した場合に、より実用的なフィードバックを貴社チームに提供できるようになります。
IDは、各ユーザーを一意に識別できる文字列である必要があります。身元を特定できる情報を送信しないために、ユーザー名またはメールアドレスをハッシュ化することをお勧めします。ログインしていないユーザーに製品のプレビューを提供している場合は、代わりにセッションIDを送信することができます。
登録したデータはAPIからも確認できる。ただし上にも書いた通り、
自分が確認した際には
1.61.1がインストールされていた。このバージョンでもOpenAI上にデータを残すことはできるのだが、データの確認等がAPIからできないので、最新にしておくことをオススメ。
1.61.1だとどうやらこのAPIに対応していない模様なので、最新にしておくべし。
登録したデータの一覧。
from openai import OpenAI
import json
client = OpenAI()
completions = client.chat.completions.list()
print(json.dumps(completions.model_dump(), indent=2, ensure_ascii=False))
{
"data": [
{
"id": "chatcmpl-B0rCBJjmNOCkvMiX67JMwuBO9FrXW",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "こんにちは、花子さん!お会いできて嬉しいです。今日はどんなことをお話ししましょうか?",
"refusal": null,
"role": "assistant",
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1739544183,
"model": "gpt-4o-mini-2024-07-18",
"object": "chat.completion",
"service_tier": "default",
"system_fingerprint": "fp_00428b782a",
"usage": {
"completion_tokens": 28,
"prompt_tokens": 35,
"total_tokens": 63,
"completion_tokens_details": null,
"prompt_tokens_details": null
},
"request_id": "req_224565d91bae4a2f1819250e2848858e",
"tool_choice": null,
"seed": 825972772783062999,
"top_p": 1.0,
"temperature": 1.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"input_user": "hanako_67890",
"tools": null,
"metadata": {},
"response_format": null
},
{
"id": "chatcmpl-B0r2EBWoAz1cbC9FjJtsnXmvW5x9t",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "おはようございます!今日はどんなことをお手伝いしましょうか?",
"refusal": null,
"role": "assistant",
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1739543566,
"model": "gpt-4o-2024-08-06",
"object": "chat.completion",
"service_tier": "default",
"system_fingerprint": "fp_523b9b6e5f",
"usage": {
"completion_tokens": 19,
"prompt_tokens": 30,
"total_tokens": 49,
"completion_tokens_details": null,
"prompt_tokens_details": null
},
"request_id": "req_d9f90ab0c8ee9b82e06c96afc83fcd99",
"tool_choice": null,
"seed": 1276955394494865368,
"top_p": 1.0,
"temperature": 1.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"input_user": null,
"tools": null,
"metadata": {
"key2": "value2",
"key1": "value1",
"key3": "value3"
},
"response_format": null
},
{
"id": "chatcmpl-B0qzrDg2J6X2OHEx52vTezFua7SLy",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "こんにちは!どうかされましたか?お手伝いできることがあれば教えてください。",
"refusal": null,
"role": "assistant",
"audio": null,
"function_call": null,
"tool_calls": null
}
}
],
"created": 1739543419,
"model": "gpt-4o-mini-2024-07-18",
"object": "chat.completion",
"service_tier": "default",
"system_fingerprint": "fp_bd83329f63",
"usage": {
"completion_tokens": 23,
"prompt_tokens": 27,
"total_tokens": 50,
"completion_tokens_details": null,
"prompt_tokens_details": null
},
"request_id": "req_5e9acf016e20a4c261e1fc0f8c8cf664",
"tool_choice": null,
"seed": -5310028355959518786,
"top_p": 1.0,
"temperature": 1.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"input_user": null,
"tools": null,
"metadata": {},
"response_format": null
}
],
"has_more": false,
"object": "list",
"first_id": "chatcmpl-B0rCBJjmNOCkvMiX67JMwuBO9FrXW",
"last_id": "chatcmpl-B0qzrDg2J6X2OHEx52vTezFua7SLy"
}
あとは
- データを個別に取得
- データのメッセージ部分を個別に取得
- データの削除
- データの更新
が可能となっている。おそらくユースケースとしては、データの更新でメタデータを更新して、それを評価やモデル蒸留につなげる、といった使い方なのだろうと思う。
logprobs / top_logprobs
トークンの出現確率を確認することができる。
| パラメータ | 用途 | デフォルト値 | 備考 |
|---|---|---|---|
logprobs |
メッセージのコンテンツで返される出力トークンのログ確率を返すかどうか。 | False ※オプション | |
top_logprobs |
各トークン位置で返される可能性が最も高いトークンの数を指定。 例えば 5の場合、出力の各トークン位置で最も可能性が高い上位5つのトークンとその対数確率が返される。- 0から20までの整数 |
- ※オプション |
logprobs=Trueが前提 |
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "developer", "content": "あなたは親切な日本語のアシスタントです。常に簡潔に回答します。"},
{"role": "user", "content": "日本の総理大臣は?回答だけ答えて。"}
],
logprobs=True,
top_logprobs=5
)
print(completion.choices[0].message.content)
岸田文雄です。
最新の情報ではないことは一旦おいといて、こんな感じでデータが追加されている。
print(json.dumps(completion.choices[0].logprobs.model_dump()["content"], indent=2, ensure_ascii=False))
[
{
"token": "岸",
"bytes": [
229,
178,
184
],
"logprob": -0.00050787657,
"top_logprobs": [
{
"token": "岸",
"bytes": [
229,
178,
184
],
"logprob": -0.00050787657
},
{
"token": "\\xe9\\x88",
"bytes": [
233,
136
],
"logprob": -8.875508
},
{
"token": "河",
"bytes": [
230,
178,
179
],
"logprob": -9.500508
},
{
"token": "現在",
"bytes": [
231,
143,
190,
229,
156,
168
],
"logprob": -9.625508
},
{
"token": "松",
"bytes": [
230,
157,
190
],
"logprob": -10.750508
}
]
},
{
"token": "田",
"bytes": [
231,
148,
176
],
"logprob": -1.1637165e-05,
"top_logprobs": [
{
"token": "田",
"bytes": [
231,
148,
176
],
"logprob": -1.1637165e-05
},
{
"token": "信",
"bytes": [
228,
191,
161
],
"logprob": -11.375011
},
{
"token": "井",
"bytes": [
228,
186,
149
],
"logprob": -17.250011
},
{
"token": "防",
"bytes": [
233,
152,
178
],
"logprob": -18.437511
},
{
"token": " 信",
"bytes": [
32,
228,
191,
161
],
"logprob": -18.625011
}
]
},
{
"token": "文",
"bytes": [
230,
150,
135
],
"logprob": -2.2365493e-05,
"top_logprobs": [
{
"token": "文",
"bytes": [
230,
150,
135
],
"logprob": -2.2365493e-05
},
{
"token": " 文",
"bytes": [
32,
230,
150,
135
],
"logprob": -10.750022
},
{
"token": "裕",
"bytes": [
232,
163,
149
],
"logprob": -15.250022
},
{
"token": "総",
"bytes": [
231,
183,
143
],
"logprob": -15.250022
},
{
"token": "翔",
"bytes": [
231,
191,
148
],
"logprob": -16.500023
}
]
},
{
"token": "雄",
"bytes": [
233,
155,
132
],
"logprob": -0.00081296277,
"top_logprobs": [
{
"token": "雄",
"bytes": [
233,
155,
132
],
"logprob": -0.00081296277
},
{
"token": "夫",
"bytes": [
229,
164,
171
],
"logprob": -7.375813
},
{
"token": "男",
"bytes": [
231,
148,
183
],
"logprob": -8.625813
},
{
"token": "俊",
"bytes": [
228,
191,
138
],
"logprob": -13.375813
},
{
"token": "\\xe5\\x93",
"bytes": [
229,
147
],
"logprob": -14.125813
}
]
},
{
"token": "です",
"bytes": [
227,
129,
167,
227,
129,
153
],
"logprob": -0.10183589,
"top_logprobs": [
{
"token": "です",
"bytes": [
227,
129,
167,
227,
129,
153
],
"logprob": -0.10183589
},
{
"token": "。",
"bytes": [
227,
128,
130
],
"logprob": -2.851836
},
{
"token": "(",
"bytes": [
239,
188,
136
],
"logprob": -3.726836
},
{
"token": "<|end|>",
"bytes": null,
"logprob": -4.3518357
},
{
"token": "首",
"bytes": [
233,
166,
150
],
"logprob": -7.6018357
}
]
},
{
"token": "。",
"bytes": [
227,
128,
130
],
"logprob": -0.00046630012,
"top_logprobs": [
{
"token": "。",
"bytes": [
227,
128,
130
],
"logprob": -0.00046630012
},
{
"token": "。(",
"bytes": [
227,
128,
130,
239,
188,
136
],
"logprob": -7.8754663
},
{
"token": "(",
"bytes": [
239,
188,
136
],
"logprob": -9.875466
},
{
"token": "。(",
"bytes": [
227,
128,
130,
40
],
"logprob": -10.500466
},
{
"token": "।",
"bytes": [
224,
165,
164
],
"logprob": -12.375466
}
]
}
]
ちょっとわかりやすく書き換えてみる。
import math
for idx, c in enumerate(completion.choices[0].logprobs.content):
print("位置{}の上位トークン: ".format(idx))
for t in c.top_logprobs:
print(" - {:10s}: {:.5f}".format(t.token, math.exp(t.logprob)))
print()
位置0の上位トークン:
- 岸 : 0.99949
- \xe9\x88 : 0.00014
- 河 : 0.00007
- 現在 : 0.00007
- 松 : 0.00002
位置1の上位トークン:
- 田 : 0.99999
- 信 : 0.00001
- 井 : 0.00000
- 防 : 0.00000
- 信 : 0.00000
位置2の上位トークン:
- 文 : 0.99998
- 文 : 0.00002
- 裕 : 0.00000
- 総 : 0.00000
- 翔 : 0.00000
位置3の上位トークン:
- 雄 : 0.99919
- 夫 : 0.00063
- 男 : 0.00018
- 俊 : 0.00000
- \xe5\x93 : 0.00000
位置4の上位トークン:
- です : 0.90318
- 。 : 0.05774
- ( : 0.02407
- <|end|> : 0.01288
- 首 : 0.00050
位置5の上位トークン:
- 。 : 0.99953
- 。( : 0.00038
- ( : 0.00005
- 。( : 0.00003
- । : 0.00000
なるほど、LLMが次のトークンで最も確率が高いものを出力するということがこれから読み取れる。以下の記事で書かれていることの一端は確認できるということに思える。
logit_bias
特定のトークンに対して出現確率を直接調整するようなバイアスを掛けることができる。temperature / top_p / frequency_penalty / presence_penalty あたりと同じような役割になるが、トークンを指定できるというところが特徴になる。
| パラメータ | 用途 | デフォルト値 | 備考 |
|---|---|---|---|
logit_bias |
特定のトークンIDに対するバイアス値がマッピングされているJSONを渡して、出現確率を調整する - -100〜100の範囲で指定すると極端に調整される。- -1〜1の範囲で指定すると微調整される。- 大きいほど出現確率が上がる。小さいほど出現確率が下がる。 |
- ※オプション | 各トークン生成時にトークンの"logit"を計算するが、そこに加算される。サンプリングはこのlogitを元に行われるため、出現確率に影響する |
先ほどの出力を使って調整してみる。まずは出力された結果文字列のトークンIDを求める。
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4o-mini")
tokens = enc.encode("岸田文雄です。")
for token_id in tokens:
token_str = enc.decode([token_id])
print(f"'{token_str}' ({token_id})")
'岸' (86845)
'田' (30814)
'文' (4883)
'雄' (52446)
'です' (15121)
'。' (788)
「岸」のトークンIDは86845なので、これの出現確率を大幅に下げてみる。
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "developer", "content": "あなたは親切な日本語のアシスタントです。常に簡潔に回答します。"},
{"role": "user", "content": "日本の総理大臣は?回答だけ答えて。"}
],
logprobs=True,
top_logprobs=5,
logit_bias={
"86845": -50,
}
)
print(completion.choices[0].message.content)
結果
現在の日本の総理大臣は鈴木俊一です。
現在の日本の総理大臣は、鈴木善幸です。
萩生田光一(はぎゅうだこういち)です。
岡田克也です。
鈴木善幸です。
おお、全く違う。ちなみにlogit_biasを指定しない場合、10回中10回「岸田文雄」になるので、これが抑制されることで全く結果が変わるということがよく分かる。
このときのlogprobesを見てみる。
import math
for idx, c in enumerate(completion.choices[0].logprobs.content):
print("***** 位置{} *****".format(idx))
print("選択されたトークン:")
print(" - {:10s}: {:.5f}".format(c.token, math.exp(c.logprob) ))
print("上位トークン: ")
for t in c.top_logprobs:
print(" - {:10s}: {:.5f}".format(t.token, math.exp(t.logprob)))
print()
***** 位置0 *****
選択されたトークン:
- \xe9\x88 : 0.00008
上位トークン:
- 岸 : 0.99964
- \xe9\x88 : 0.00008
- 河 : 0.00005
- 現在 : 0.00004
- 松 : 0.00001
***** 位置1 *****
選択されたトークン:
- \xb4 : 1.00000
上位トークン:
- \xb4 : 1.00000
- \x8d : 0.00000
- \x8e : 0.00000
- \x87 : 0.00000
- \xb8 : 0.00000
***** 位置2 *****
選択されたトークン:
- 木 : 0.99998
上位トークン:
- 木 : 0.99998
- 鹿 : 0.00001
- 村 : 0.00000
- 木 : 0.00000
- wood : 0.00000
***** 位置3 *****
選択されたトークン:
- 善 : 0.52110
上位トークン:
- 善 : 0.52110
- 俊 : 0.31606
- 義 : 0.04847
- 宗 : 0.03775
- \xe8\xb2 : 0.02940
***** 位置4 *****
選択されたトークン:
- 幸 : 0.99485
上位トークン:
- 幸 : 0.99485
- 晴 : 0.00359
- \xe8\xb2 : 0.00026
- 人 : 0.00020
- 仁 : 0.00016
***** 位置5 *****
選択されたトークン:
- です : 0.27513
上位トークン:
- ( : 0.66001
- です : 0.27513
- <|end|> : 0.03724
- 。 : 0.01552
- ( : 0.00831
***** 位置6 *****
選択されたトークン:
- 。 : 0.89362
上位トークン:
- 。 : 0.89362
- 。( : 0.07335
- ( : 0.03058
- 。( : 0.00222
- 。ただ : 0.00008
なるほど、調整されたトークンは一応上位に上がってきているのだが、どうも無視されて2番目のものが選択されるという感じっぽい。
なお、logit_biasに複数登録するとレスポンスが極端に悪くなった。3つ登録しただけでなかなか返ってこなくなったので、注意したほうがいいかもしれない。
stream_options
ストリーミング時のオプション
| パラメータ | 用途 | デフォルト値 | 備考 |
|---|---|---|---|
stream_options |
ストリーミング時のオプション。{"include_usage": True}を指定すると、リクエスト全体のトークン使用量が最後のチャンクの前に追加される。 |
- ※オプション |
stream=Trueが前提 |
from openai import OpenAI
client = OpenAI()
stream = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "developer", "content": "あなたは親切な日本語のアシスタントです。"},
{"role": "user", "content": "こんにちは!"}
],
stream=True,
stream_options={"include_usage": True}
)
for chunk in stream:
if chunk.choices:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="\n")
else:
print(json.dumps(chunk.usage.model_dump(), indent=2, ensure_ascii=False))
こんにちは
!
ど
の
よう
に
お
手
伝
い
できます
か
?
{
"completion_tokens": 14,
"prompt_tokens": 27,
"total_tokens": 41,
"completion_tokens_details": {
"accepted_prediction_tokens": 0,
"audio_tokens": 0,
"reasoning_tokens": 0,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
}
ストリーミングの場合、何もしない場合はトークン使用量などが取得できないのだが、これで取得できる。
reasoning_effort
o1やo3-miniなどreasoningモデル専用のパラメータ。
| パラメータ | 用途 | デフォルト値 | 備考 |
|---|---|---|---|
reasoning_effort |
reasoningにどれぐらいの労力をかけるかを設定。高いほどreasoningトークンを消費し時間をかける。 - high- medium- low
|
medium ※オプション |
モデルがo1やo3-miniの場合のみ |
reasoningモデルについては以下に記載がある
上記の例では、
reasoning_effortパラメータ(これらのモデルの開発中に「ジュース」という愛称で呼ばれていました)を使用して、プロンプトに対する応答を作成する前に、モデルが生成すべき推論トークンの数を指定します。このパラメータには、low、medium、またはhighのいずれかを指定できます。lowは速度とトークンの使用量を重視し、highはより完全な推論を重視しますが、その分、生成されるトークン数が増え、応答が遅くなります。デフォルト値は中程度で、これは速度と推論の正確さのバランスを取ったものです。
推論モデルは、入力と出力のトークンに加えて、推論トークンを導入する。 モデルはこれらの推論トークンを使って「考え」、プロンプトの理解を分解し、応答を生成するための複数のアプローチを検討する。 推論トークンを生成した後、モデルは目に見える完了トークンとして答えを生成し、そのコンテキストから推論トークンを破棄します。
あまりいい例とは思わないが、試しにo3-miniでやってみる。まずlow。
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="o3-mini",
messages=[
{"role": "developer", "content": "あなたは親切な日本語のアシスタントです。"},
{"role": "user", "content": "競馬の楽しみ方は色々あると思うけど、最も重要なものを1つ考えて。"}
],
reasoning_effort="low"
)
print(completion.choices[0].message.content)
競馬の楽しみ方はいろいろありますが、個人的に最も重要だと思うのは「自分なりの視点や知識を深め、その過程自体を楽しむこと」です。
理由は以下の通りです。
① レースは単なる運や結果だけでなく、出走馬の能力や血統、調教の状況、騎手の技量、そして当日の馬場状態など、さまざまな要素が絡み合っています。これらの情報を集め、予想を練る過程自体が大きな楽しみになるでしょう。
② 自分なりの予想スタイルや分析方法を確立することで、たとえ結果が思い通りでなくても、そのプロセスが次のレースへのモチベーションとなり、競馬全体がより奥深く感じられます。
③ また、知識を深めることで馬券購入自体が単なるギャンブルではなく、スポーツ観戦としても楽しむことができ、勝敗に一喜一憂するだけではなく、レースの背景や戦略に目を向けられるようになります。
つまり、競馬の魅力は結果だけでなく、その裏側にあるさまざまな要素やドラマを自分なりに解釈して楽しむことにあると思います。この「自分で情報を集め、考察し、予想を楽しむこと」が、競馬をより豊かな経験にしてくれる大切なポイントだと言えるでしょう。
だいたい8秒ほどかかった。トークン使用量は以下。
print(json.dumps(completion.usage.model_dump(), indent=2, ensure_ascii=False))
{
"completion_tokens": 876,
"prompt_tokens": 50,
"total_tokens": 926,
"completion_tokens_details": {
"accepted_prediction_tokens": 0,
"audio_tokens": 0,
"reasoning_tokens": 512,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
}
reasoning_tokensってのがあるんだね。
では次にhigh
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="o3-mini",
messages=[
{"role": "developer", "content": "あなたは親切な日本語のアシスタントです。"},
{"role": "user", "content": "競馬の楽しみ方は色々あると思うけど、最も重要なものを1つ考えて。"}
],
reasoning_effort="high"
)
print(completion.choices[0].message.content)
競馬のさまざまな楽しみ方の中でも、個人的には「レースそのものが生み出すドラマと瞬間の興奮」を味わうことが最も重要だと思います。
もちろん、馬券で勝負する楽しみ方や、血統や騎手に注目して戦略を練る面白さもありますが、競馬場に集まる仲間たちと一緒に、予測不能なレース展開や、馬とジョッキーが見せる全力の走り、そして最後の直線での一瞬のドラマを共有する喜びは、他ではなかなか味わえない特別な体験です。
このドラマチックな瞬間こそ、日常では感じることの少ない熱狂や感動を呼び起こし、競馬を単なるギャンブル以上の「生のエンターテインメント」として楽しむ大きな魅力と言えるでしょう。
ただし、どの楽しみ方をするにしても、自己管理と責任ある行動が大切です。競馬本来の魅力は、その瞬間瞬間のドラマに心を委ね、一緒にその興奮を感じ合うことにあるのだと思います。
今度は15秒。トークン使用量も増えた。
print(json.dumps(completion.usage.model_dump(), indent=2, ensure_ascii=False))
{
"completion_tokens": 2158,
"prompt_tokens": 50,
"total_tokens": 2208,
"completion_tokens_details": {
"accepted_prediction_tokens": 0,
"audio_tokens": 0,
"reasoning_tokens": 1856,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
}
service_tier
これはScale Tierサービスを契約している場合のパラメータらしい。Scale Tierサービスってのは以下に説明があるが、前払いで安定したアクセスができるというものみたい。
Scale Tierでは、1つの専用モデルのスナップショットへのアクセス用に、1分あたりのAPI入力および出力トークン(「トークン単位」)を事前に一定数購入することができます。各トークン単位は最低30日間有効です。
Scale Tierを選択すると、以下の機能が利用可能になります:
- 予測可能なレイテンシ: Scale Tierは、ピーク時の需要時でも、従量課金制(PAYG)サービスよりも高速かつ安定した速度でトークンを生成するように設計されています。
- 上限のないスケール: Scale Tierでクォータを購入すると、自動的にレート制限に追加されるため、安心してさらにスケールアップできます。
- 高い信頼性: Scale Tierのトラフィックは、99.9%の稼働率SLAと優先コンピューティングを提供します。
| パラメータ | 用途 | デフォルト値 | 備考 |
|---|---|---|---|
service_tier |
- auto: プロジェクトがScale Tier有効の場合、Scale Tierクレジットを使用する。プロジェクトがScale Tier有効でない場合はデフォルトTierになる。- default: デフォルトTierを使用する。 |
auto ※オプション |
そういえば、レスポンスの中にも含まれている。
{
"id": "chatcmpl-B0tpzTRR0dHIZ8p3ZJp6aHf8kOw3k",
"choices": [
(snip)
],
"created": 1739554339,
"model": "o3-mini-2025-01-31",
"object": "chat.completion",
"service_tier": "default",
(snip)
個人アカウントで使うことはなさそうだけども、もし使える場合にはデフォルトがautoになっててScale Tierを意識しなくても使用するようなので、注意が必要かな。
また、追加されたら確認するかも。