「LLMは次にくる単語の確率予測をするもの」をちょっとだけイメージできるようにする
こちらは「LLM・LLM活用 Advent Calendar 2024」の1日目の記事です!
対象読者
LLMをなんとなく触り始めた人
はじめに
LLMはよく、「次にくる単語を予測して出力する」と説明されます。これは入力した内容を元に、出現確率を予測するモデルであるから、その中から可能性の高い単語を選択することで文章の生成ができるわけです。ただし、ぶっちゃけて言うとAPIレベルで叩いたりllama.cppを遊ぶ分にはそこはラップされており、基本的にはあまり考える必要はないように作られていると思いますし、個人的にもLLMを用いたプロダクトを作る際はそこは強く意識する必要はないとも考えています。
一方で、それを少し把握しつつ確率分布を見たりそれを弄ったりすることでLLMを用いた表現の可能性を探ることができるはずです。この記事はLLMの出力内容および各トークンごとの確率を眺めつつ、何に使えるかを考えることを目的とします。
ゴール
- Transformersで候補トークンとその候補の確率を表示させて、確認してみる
- これを利用したちょっとした実装例をぼんやり考えてみる
動作環境
筆者は以下の環境で行っています
- python 3.10.9
- torch 2.5.1+cu124
- transformers 4.46.3
- google/gemma-2-2b-jpn-it
確率予測状況を見てみる
まずは、各トークンごとに本当に確率を予測してるのか見てみましょう。
これは各トークン毎に上位3つの候補とその確率をあげ、もっとも可能性の高いものを選択していくスクリプトです。最後に最終結果が出力されます。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
def print_generation_process(prompt: str):
model_name = "./gemma-2-2b-jpn-it"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
# generate APIを使用
outputs = model.generate(
tokenizer.encode(prompt, return_tensors="pt").to(device),
max_length=50,
num_return_sequences=1,
temperature=1.0,
do_sample=True,
# 生成過程の確率を取得
output_scores=True,
return_dict_in_generate=True,
num_beams=1
)
# 生成されたテキスト全体を表示
generated_text = tokenizer.decode(
outputs.sequences[0], skip_special_tokens=True)
if hasattr(outputs, "scores"):
# GPUのテンソルをCPUに一度だけ移動
scores = [score[0].cpu() for score in outputs.scores]
for i, score in enumerate(scores):
probs = torch.softmax(score, dim=-1) # 全部を足したら1になるような確率に変換している。[[0.3, 0.2, 0.05...]]みたいな形になってる。
top_probs, top_indices = torch.topk(probs, k=3) # k=3で上位3つを表してる。probsに確率、indicesにindex、つまり生のトークンが入ってる
print(f"\nステップ {i+1}の上位トークン:")
for prob, idx in zip(top_probs, top_indices):
token = tokenizer.decode([idx]) # indexをdecodeすることで自然言語に直る
print(f" - {token}: {prob.item():.4f}")
print(f"生成されたテキスト: {generated_text}")
if __name__ == "__main__":
prompt = "<bos><start_of_turn>user\nバベルの塔って何?\n<end_of_turn><start_of_turn>model\n"
print_generation_process(prompt)
実行するとバベルの塔は、古代の伝説に登場する、高大な塔です。が出力されました。下記スクショが各トークン毎の確率予想です。
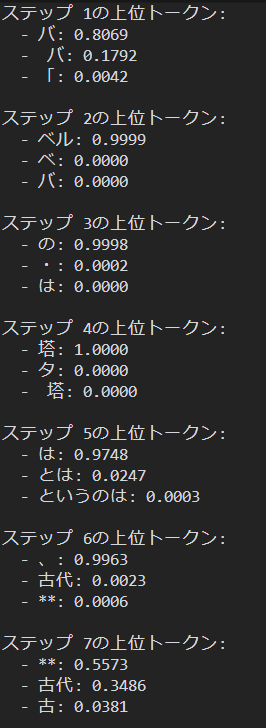
上記を見て面白いのはステップ7です。本当であれば**が一番可能性として高いはずが、古代を選択していることがわかります。これはdo_sample=Trueというパラメータが原因です。このパラメータは、算出された確率を元に実際に抽選を行って次のトークンを確定させます。なので例えばステップ7の場合は、34%を引いたわけですね。逆にdo_sampleをFalseにすると、一番確率が高いものが絶対に選ばれるようになります。
さて、これで各トークン毎に予測を行っていることがわかりました。
一方、これは「全てを生成した後に、各トークンの確率を出力をする」スクリプトなので、トークンの確率結果にかかわらず最後まで出力されてしまいます。
一定以上の確率のトークンが見つからなかったら停止させてみる
from transformers import AutoModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList
import torch
class ProbabilityThresholdCriteria(StoppingCriteria):
def __init__(self, threshold: float, tokenizer):
self.threshold = threshold
self.tokenizer = tokenizer
self.stopped = False
self.last_scores = None
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
if scores is None or len(scores) == 0:
return False
probs = torch.softmax(scores[-1], dim=-1)
max_prob = torch.max(probs).item()
if max_prob < self.threshold:
self.stopped = True
self.last_scores = scores[-1]
return max_prob < self.threshold
def print_generation_process(prompt: str):
model_name = "./gemma-2-2b-jpn-it"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
# 確率しきい値の設定
prob_threshold = 0.8
prob_threshold_criteria = ProbabilityThresholdCriteria(
prob_threshold, tokenizer)
stopping_criteria = StoppingCriteriaList([prob_threshold_criteria])
# generate APIの呼び出しを更新
outputs = model.generate(
tokenizer.encode(prompt, return_tensors="pt").to(device),
max_length=128,
num_return_sequences=1,
temperature=1.0,
do_sample=True,
output_scores=True,
return_dict_in_generate=True,
num_beams=1,
stopping_criteria=stopping_criteria, # 停止条件を追加
early_stopping=True # この行を追加
)
# 生成されたテキスト全体を表示
generated_text = tokenizer.decode(
outputs.sequences[0], skip_special_tokens=True)
print(f"\n生成されたテキスト: {generated_text}")
# 停止理由の表示
if prob_threshold_criteria.stopped:
print("\n生成が確率しきい値により停止されました")
print(f"しきい値: {prob_threshold}")
# 停止時点での上位5トークンの確率を表示
last_probs = torch.softmax(prob_threshold_criteria.last_scores, dim=-1)
top_probs, top_indices = torch.topk(last_probs, k=5)
print("\n停止時点での上位5トークン:")
for prob, idx in zip(top_probs, top_indices):
# すべてのトークンIDを処理
for i in range(len(idx)):
token_id = int(idx[i].cpu())
token = tokenizer.decode([token_id])
prob_value = float(prob[i].cpu())
print(f" - {token}: {prob_value:.4f}")
if __name__ == "__main__":
prompt = "<bos><start_of_turn>user\nバベルの塔って何?\n<end_of_turn><start_of_turn>model\n"
print_generation_process(prompt)
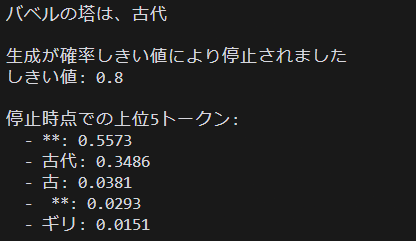
やっていることはほぼ同じですが,ProbabilityThresholdCriteriaというものが増えています。これはencodeを途中で止めるための基準が書かれています。max_prob = torch.max(probs).item()で、候補の中で一番確率が高いものを指定し、もしもそれがthreshold(今回であれば0.8)未満だった場合に止まります。last_scoresに止まった部分を保存しておいて、後で参照できるようにしているわけです。
これで、我々は少なくとも以下の2つができるようになりました
- 各トークンの確率を確認
- 確率によって止める手段を確認
最後に、これを使ってなにができるかを考えてみましょう。
結局確率が見れたら何ができるだろうか
実はこの問の回答の一つはkyo-takanoさんが公開している「ローカルLLMはこーやって使うの💢」で確認できます。
kyo-takanoさんは上記記事にて「ハルシネーションの検出、可視化」をユースケースとして上げています。この確率が低くなっているとき(上記記事では「エントロピーが高い時」と表現されています)は言ってしまえば予測が難しい状況にあるわけなので、そのタイミングでハルシネーションが起こりやすいはずです。
そこから派生して、ある条件で確率が低くなったときはそこまでの文字列を使って検索を行い、出てきた情報を再度入力文字列として埋め込み、LLM推論を再開することで一定のハルシネーションリスクの軽減ができるのではないでしょうか。
また、全ての生成が終わった後、生成した各トークンの確率があるしきい値未満である確率(たとえば0.4未満のトークン出力が8割を超えているとか)が出たときはフロントエンド側で「間違えている出力の可能性があります」と表示することもできそうです。
(おまけ)確率が見れたら何ができるかをAIキャラの文脈で考えてみる
僕はAIキャラクターを作ることが多いのでその側面で考えてみましょう。取れる情報は先程と同じで、基本的には前の章で考えていたことをどう表現するかになりそうです。例えば先程のハルシネーションでいえば、0.3を切った瞬間にいきなりパニックになって「間違ったこと言ったかも!ごめん!」って謝り始めるとかは、やっていることは出力停止でしかないわけですが、それをトリガーにして使うLLMを切り替えたり、話す内容を変えたりすることに派生できるはずです。また、直近5回の発言で生成した各トークンの確率で、しきい値未満である割合が多いほど汗を垂らし始めるとかも面白そうです。
LLMは出力だけでなく、出力に基づくプロセスを見ることができるのも魅力だと感じました。皆さんも是非試して遊んでみて下さい。
宣伝
「ローカルLLMに向き合う会」という、知識がなくてもTransformersやllama.cpp等のローカルLLMに一から向き合うことを目的としたDiscordサーバーがあります。
もしこれの記事を見てローカルLLMが気になった方は是非入ってみてください。

参考:個人的な理解のためのサンプルコード
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from typing import List, Tuple
def generate_with_probabilities(
model,
tokenizer,
prompt: str,
num_candidates: int = 3,
max_length: int = 50,
temperature: float = 1.0
) -> List[Tuple[str, List[Tuple[str, float]]]]:
"""
文章生成時の各トークンの候補と確率を表示する関数
Args:
model: 生成モデル
tokenizer: トークナイザー
prompt: 入力プロンプト
num_candidates: 各ステップで表示する候補数
max_length: 最大生成長
temperature: 生成時の温度パラメータ
Returns:
生成されたトークンとその候補リスト
"""
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output_tokens = []
for _ in range(max_length):
with torch.no_grad():
outputs = model(input_ids) # このoutputはモデルの出力全部がはいってる。中間層の状態なども
# [batch_size, sequence_length, vocab_size]
# 第1次元(:): バッチの全要素を選択(今回はバッチサイズ1なので実質的に最初の要素)
# 第2次元(-1): 最後のトークンの位置を選択。例えば「今日の天気は」の場合は「は」になる。これの次のトークンを予測する。
# 第3次元(:): そのトークンに対する全語彙のスコアを選択
logits = outputs.logits[:, -1, :] # 最後のトークンのスコアを抽出している。
fix_logits = logits / temperature # 温度パラメータをかけている(省略)
# 全部を足したら1になるような確率に変換している。[[0.3, 0.2, 0.05...]]みたいな形になってる。 dim= -1は今回省略
probs = torch.softmax(fix_logits, dim=-1)
# 上位num_candidates個の確率とインデックスを取得。probs[0]はバッチサイズ1のときは、最初の要素を選択しようが最後を選択しようが同じ。
# 確率の配列とindexの配列。indexの複数形でindicesらしい
top_probs, top_indices = torch.topk(probs[0], num_candidates)
# 候補トークンとその確率を記録
candidates = []
for prob, idx in zip(top_probs, top_indices):
token = tokenizer.decode([idx])
candidates.append((token, prob.item()))
# 最初の候補が最も確率が高いものなので、それを使用
chosen_token = candidates[0][0] # タプルの最初の要素(トークン)
next_token_id = top_indices[0].reshape(1, 1) # [[1, 2, 3]]みたいな形に戻す
output_tokens.append((chosen_token, candidates))
# EOS トークンが生成されたら終了
if next_token_id.item() == tokenizer.eos_token_id:
break
input_ids = torch.cat(
[input_ids, next_token_id], dim=-1) # 作ったトークンを追加している
# max_length or EOSトークンが生成されるまで繰り返す
return output_tokens
def print_generation_process(prompt: str):
model_name = "./gemma-2-2b-jpn-it"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
outputs = generate_with_probabilities(model, tokenizer, prompt)
print(f"プロンプト: {prompt}\n")
for i, (chosen, candidates) in enumerate(outputs, 1):
print(f"ステップ {i}:")
print(f"選択されたトークン: {chosen}")
print("候補トークン:")
for token, prob in candidates:
print(f" - {token}: {prob:.4f}")
print()
if __name__ == "__main__":
prompt = "<bos><start_of_turn>user\nバベルの塔って何?\n<end_of_turn><start_of_turn>model\n"
print_generation_process(prompt)
Discussion