Reasoning対応のOCR特化VLMモデル「NuMarkdown-8B-Thinking」を試す
私たちは、NuMarkdown-8B-Thinkingをリリースします。これはオープンソース(MITライセンス)の推論OCRモデルです 🧠✨📄
NuMarkdown-8B-Thinkingは、どうやら初めて(!)の、PDF/スキャン/スプレッドシートをMarkdownファイルに変換することに特化した推論VLMです(通常、RAGアプリケーションに使用されます)。
このモデルは、Markdownファイルを生成する前に、ドキュメントのレイアウトを把握するために思考トークンを生成します。特に、奇妙なレイアウトや複雑な表を含むドキュメントの理解に優れています。思考トークンの数は、タスクの難易度に応じて最終回答の20%から500%まで変動します。
このモデルは、@Alibaba_Qwen 2.5-VL-7B をベースに、合成されたDoc → 推論 → Markdownの例でファインチューニングを行い、その後、レイアウト中心のリワードを用いたRLフェーズ(GRPO)を実施しました。
NuMarkdownは、GPT-4oのような一般的な非推論モデルや、OCRFluxのような特化型OCRモデルを上回り、Gemini 2.5のような大型の推論クローズドソースモデルとも競合できる性能を発揮しています!
この偉業を成し遂げたAlexandre Constantinにお祝いを申し上げます。
モデル
ReasoningがOCRにやってきた 🧠✨📄🤘
NuMarkdown-8B-Thinkingは、初の推論型OCR VLM(視覚言語モデル)です。ドキュメントをクリーンなMarkdownファイルに変換することに特化しており、RAGアプリケーションに最適です。Markdownファイルを生成する前に、ドキュメントのレイアウトを把握するために「思考トークン」を生成します。特に、レイアウトが複雑だったり、変わったテーブルが含まれているドキュメントの理解が得意です。思考トークンの数は、タスクの難易度によって最終的な回答の20%から500%まで変動します。
NuMarkdown-8B-Thinkingは、Qwen 2.5-VL-7Bをベースに、合成された「ドキュメント→推論→Markdown」例でファインチューニングされています。その後、レイアウト重視の報酬を用いた強化学習(GRPO)フェーズが行われています。
結果
NuMarkdown-8B-Thinkingは、GPT-4oのような一般的な非推論モデルや、OCRFluxのような特化型OCRモデルを上回る性能を発揮しています。また、Gemini 2.5のような大規模な推論型クローズドソースモデルとも競合できるレベルです。
人気のある他モデルとのアリーナランキング(trueskill-2ランキングシステム、約500件のモデル匿名投票による)
順位 モデル名 μ σ μ − 3σ 🥇 1 gemini-flash-reasoning 26.75 0.80 24.35 🥈 2 NuMarkdown-reasoning 26.10 0.79 23.72 🥉 3 NuMarkdown-reasoning-w/o_grpo 25.32 0.80 22.93 4 OCRFlux-3B 24.63 0.80 22.22 5 gpt-4o 24.48 0.80 22.08 6 gemini-flash-w/o_reasoning 24.11 0.79 21.74 7 RolmoOCR 23.53 0.82 21.07 私たちは、llmArenaのような複雑なドキュメントからMarkdownへの変換タスク用の「Markdown Arena」を公開する予定です。これにより、さまざまなソリューションを評価するためのツールを提供します。
他モデルとのWin/Draw/Lose率(画像のみ)
referred from https://huggingface.co/numind/NuMarkdown-8B-Thinking###トレーニング
- SFT: 公開PDFから生成した合成推論トレースを用いた、単一エポックの教師ありファインチューニング。
- RL(GRPO): 難易度の高い画像例を使い、レイアウト重視の報酬を用いた強化学習フェーズ。

Colaboratoryで試してみる。最初にL4で軽くやってみたのだけど、どう考えてもVRAM足りなさそうな雰囲気だったので、A100で。
モデルカードでは、 vLLM と Transformers でのサンプルが記載されているが今回はTransformersで。
依存パッケージ等については特に書かれていないが、flash-attn だけは必要になりそうなので追加(flash-attnの最新版だとどうも上手くいかないので、2.7.xで最も新しいものにしている)。あとはColaboratoryのプリインストールで行けそう。
!pip install "flash-attn==2.7.4.post1" --no-build-isolation
XのポストからするとPDFを直接読み込めそうに読めるのだが、サンプルコードでは画像を読み込んでいるようなので、pdf2imageを使ってPDFから一旦画像に変換するようにする。
!apt update && apt install -y poppler-utils
!pip install pdf2image
サンプルとして、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを使用させていただく。
PDFの特徴
- サイズ: 1.8MB
- ページ数: 21
- 縦長レイアウト
- 文字は横書き
- 表・グラフ等含む
参考までに一部抜粋。
PDFをダウンロード
!wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
各ページごとに画像に変換
import os
from pdf2image import convert_from_path
kobe_pdf = "r5_doukou.pdf"
kobe_output_dir = "kobe"
def convert_pdf_to_image(pdf_path, output_dir_path):
os.makedirs(output_dir_path, exist_ok=True)
images = convert_from_path(pdf_path)
for i, image in enumerate(images):
output_path = f"{output_dir_path}/page_{i + 1}.png"
image.save(output_path, "PNG")
print(f"Saved: {output_path}")
convert_pdf_to_image(kobe_pdf, kobe_output_dir)
こんな感じで生成される。
kobe
├── page_10.png
├── page_11.png
├── page_12.png
├── page_13.png
├── page_14.png
├── page_15.png
├── page_16.png
├── page_17.png
├── page_18.png
├── page_19.png
├── page_1.png
├── page_20.png
├── page_21.png
├── page_2.png
├── page_3.png
├── page_4.png
├── page_5.png
├── page_6.png
├── page_7.png
├── page_8.png
└── page_9.png
モデルとプロセッサをロード
import torch
from PIL import Image
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
model_id = "numind/NuMarkdown-8B-reasoning"
processor = AutoProcessor.from_pretrained(
model_id,
trust_remote_code=True,
min_pixels=100*28*28, max_pixels=5000*28*28
)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto",
trust_remote_code=True,
)
この時点でVRAM消費は16GB程度。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100-SXM4-40GB Off | 00000000:00:04.0 Off | 0 |
| N/A 36C P0 52W / 400W | 16241MiB / 40960MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
ではまず1ページ目を読ませてみる。

img = Image.open("kobe/page_1.png").convert("RGB")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
],
}
]
prompt = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_input = processor(text=prompt, images=[img], return_tensors="pt").to(model.device)
with torch.no_grad():
model_output = model.generate(**model_input, temperature = 0.7, max_new_tokens=5000)
result = processor.decode(model_output[0])
reasoning = result.split("<think>")[1].split("</think>")[0]
answer = result.split("<answer>")[1].split("</answer>")[0]
print(answer)
だいたい20分ぐらいかかって回答が生成された。
# 令和5年度 神戸市観光動向調査結果について
**調査目的**
本調査は,来神観光客の特質と神戸市内の観光動向を把握し,今後の観光行政の参考とすることを目的に実施。
**調査方法**
調査員が対面にてアンケート項目を聞き取りする形で実施。
**調査日**
① 令和5年 5月 13 日(土)・20 日(土)※
② 令和5年 9月 9 日(土)
③ 令和5年 11月 25 日(土)/12 月 2 日(土)※
④ 令和6年 2月 10 日(土)・17 日/3月 30 日(土)※
※雨天等により、一部の調査地点については延期して実施。
**調査地点**
| 地区 | NO | 調査地点 | サンプル数 |
| :--- | :- | :------- | ----------: |
| 北野 | 1 | 北野町広場 | 246 |
| | 2 | 北野工房のまち | 154 |
| 市街地 | 3 | 南京町広場 | 218 |
| | 4 | 総合インフォメーションセンター | 198 |
| | 5 | 旧居留地 | 201 |
| | 6 | 神戸布引ロープウェイハーブ園山麓駅 | 203 |
| | 7 | 白鶴酒造資料館内 | 205 |
| | 8 | 王子動物園内 | 235 |
| | 9 | 県立美術館前 | 217 |
| | 10 | さんちか夢広場 | 208 |
| | 11 | 神戸空港屋上階展望ロビー | 212 |
| | 12 | IKEA神戸 | 192 |
| | 13 | 能福寺(兵庫大仏) | 147 |
| | 14 | 兵庫津ミュージアム | 204 |
| 神戸港 | 15 | 神戸海洋博物館前及び周辺 | 200 |
| | 16 | 中突堤中央ターミナル周辺 | 208 |
| | 17 | umie モザイク | 201 |
| | 18 | ハーバーランド総合インフォメーション前 | 213 |
| 六甲・摩耶 | 19 | 六甲天覧台 | 209 |
| | 20 | 摩耶山掬星台広場 | 200 |
| | 21 | 六甲山牧場内 | 215 |
| | 22 | 六甲ガーデンテラス内 | 211 |
| 有馬 | 23 | 有馬温泉観光総合案内所前 | 214 |
| | 24 | 金の湯前 | 216 |
| | 25 | 六甲有馬ロープウェイ有馬温泉駅 | 232 |
| 須磨・舞子 | 26 | 須磨離宮公園 | 202 |
| | 27 | 舞子公園(舞子海上プロムナード) | 230 |
| 西北神 | 28 | 神戸ワイナリー(農業公園) | 235 |
| | 29 | 神戸フルーツ・フラワーパーク大沢園内 | 209 |
| | 30 | 神戸三田プレミアム・アウトレット | 215 |
| 合計 | | | 6,250 |
ちなみにサンプルコードでは省略されているが、Reasoningの結果も見れる。
print(reasoning)
Reasoningは英語になっているが、結構色々考えているなという感じ。
1. **Identify and Transcribe Header**: The document has a main title at the top: "令和5年度 神戸市観光動向調査結果について". This should be rendered as an H1 heading.
2. **Process Introductory Paragraphs**: Below the main title, there are three distinct sections with blue rounded labels: "調査目的", "調査方法", and "調査日". Each label is followed by a paragraph of text. These can be represented as a list or just separate paragraphs. Given their visual layout, treating them as separate paragraphs under their respective labels (which can be bolded or simply part of the text) is appropriate.
3. **Handle "調査日" Section**: This section contains a numbered list of dates. The accompanying footnote "※雨天等により、一部の調査地点については延期して実施。" should be placed directly after the list.
4. **Identify and Convert Main Table Structure**: The majority of the content is a large table titled "調査地点". This table has four columns: "地区", "NO", "調査地点", and "サンプル数".
5. **Determine Table Columns and Headers**: The table clearly has 4 columns. The headers are "地区", "NO", "調査地点", and "サンプル数".
6. **Handle Merged Cells in "地区" Column**: The "地区" column has merged cells for categories like "北野", "市街地", "神戸港", "六甲・摩耶", "有馬", "須磨・舞子", and "西北神". GitHub Flavored Markdown (GFM) tables do not directly support merged cells. The best approach is to repeat the "地区" name for each row it applies to, or leave it blank for subsequent rows within the same "region" if it makes more sense contextually. In this case, repeating the region name is clearer and maintains the logical grouping.
7. **Transcribe Table Content Row by Row**: Carefully transcribe all text and numbers into the table cells. Pay attention to Japanese characters and special characters like "・" and "/".
8. **Identify and Transcribe Table Footer**: There is a "合計" row at the bottom right, indicating a total sample count. This should be included as a final row in the table.
9. **Final Review**: Check for any missed text, incorrect formatting, or issues with table alignment. Ensure all Japanese text is accurately transcribed. The overall structure is straightforward, so no complex LaTeX or image placeholders are needed beyond the table itself.
一度推論したあとのVRAM消費は37GBと結構上がっていた。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100-SXM4-40GB Off | 00000000:00:04.0 Off | 0 |
| N/A 70C P0 392W / 400W | 37315MiB / 40960MiB | 100% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
次に4ページ目。
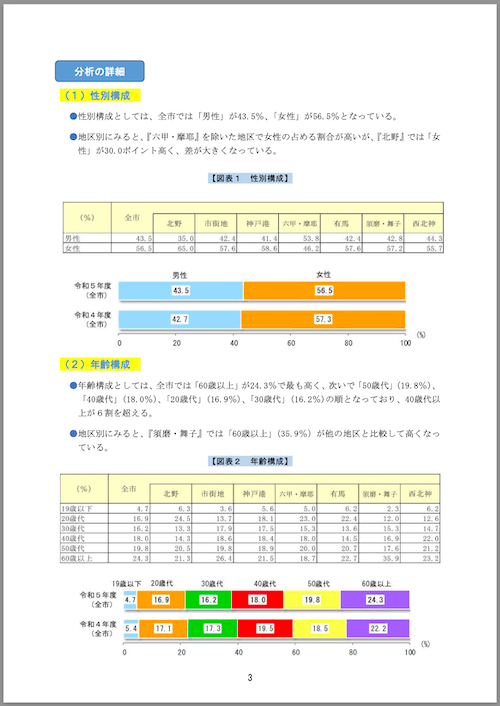
img = Image.open("kobe/page_4.png").convert("RGB")
(snip)
回答
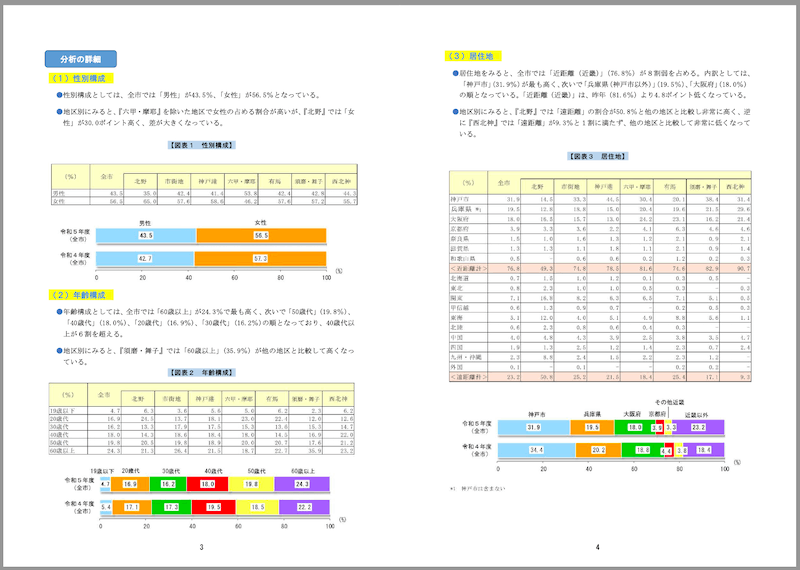
# 分析の詳細
## (1) 性別構成
- 性別構成としては、全市では「男性」が43.5%、「女性」が56.5%となっている。
- 地区別にみると、『六甲・摩耶』を除いた地区で女性の占める割合が高いが、『北野』では「女性」が30.0ポイント高く、差が大きくなっている。
【図表 1 性別構成】
| (%) | 全市 | 北野 | 市街地 | 神戸港 | 六甲・摩耶 | 有馬 | 須磨・舞子 | 西北神 |
|---|---|---|---|---|---|---|---|---|
| 男性 | 43.5 | 35.0 | 42.4 | 41.4 | 53.8 | 42.4 | 42.8 | 44.3 |
| 女性 | 56.5 | 65.0 | 57.6 | 58.6 | 46.2 | 57.6 | 57.2 | 55.7 |

## (2) 年齢構成
- 年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、「40歳代」(18.0%)、「20歳代」(16.9%)、「30歳代」(16.2%)の順となっており、40歳以上が6割を超える。
- 地区別にみると、『須磨・舞子』では「60歳以上」(35.9%)が他の地区と比較して高くなっている。
【図表 2 年齢構成】
| (%) | 全市 | 北野 | 市街地 | 神戸港 | 六甲・摩耶 | 有馬 | 須磨・舞子 | 西北神 |
|---|---|---|---|---|---|---|---|---|
| 19歳以下 | 4.7 | 6.3 | 3.6 | 5.6 | 5.0 | 6.2 | 2.3 | 6.2 |
| 20歳代 | 16.9 | 24.5 | 13.7 | 18.1 | 23.0 | 22.4 | 12.0 | 12.6 |
| 30歳代 | 16.2 | 13.3 | 17.9 | 17.5 | 15.3 | 13.6 | 15.3 | 14.7 |
| 40歳代 | 18.0 | 14.3 | 18.6 | 18.4 | 18.0 | 14.5 | 16.9 | 22.0 |
| 50歳代 | 19.8 | 20.5 | 19.8 | 18.9 | 20.0 | 20.7 | 17.6 | 21.2 |
| 60歳以上 | 24.3 | 21.3 | 26.4 | 21.5 | 18.7 | 22.7 | 35.9 | 23.2 |

3
なるほど、グラフのところは画像として認識していて、アンカーテキストに説明が入っている。ただし英語。
Reasoningも。こちらも結構細かく推論しているね。
1. **Identify and Transcribe Main Sections and Headings:**
The document is structured with clear headings and subheadings. I will transcribe these directly, using appropriate Markdown heading levels. The main sections are "分析の詳細" (Analysis Details) and its sub-sections "(1) 性別構成" (Sexual Composition) and "(2) 年齢構成" (Age Composition).
2. **Transcribe Introductory Text and Bullet Points:**
Under each main section, there is introductory text followed by bullet points. I will transcribe this text as plain paragraphs and then convert the bullet points into Markdown list items. The bullet points are indicated by a blue circular icon.
3. **Handle Tables:**
There are two tables in the document.
- **Table 1 (Sexual Composition):**
- The table has a main header "性別構成" (Sexual Composition) which spans multiple columns. This needs to be represented correctly in Markdown.
- The first column is "性別" (Gender).
- The second column is "全市" (Overall).
- The subsequent columns are region names: "北野", "市街地", "神戸港", "六甲・摩耶", "有馬", "須磨・舞子", "西北神".
- The data is numerical percentages.
- I will create a Markdown table with these columns.
- **Table 2 (Age Composition):**
- Similar structure to Table 1, with "年齢構成" (Age Composition) as the main header.
- The first column is "年齢" (Age).
- The second column is "全市" (Overall).
- The subsequent columns are region names: "北野", "市街地", "神戸港", "六甲・摩耶", "有馬", "須磨・舞子", "西北神".
- The data is numerical percentages.
- I will create a Markdown table with these columns.
4. **Handle Bar Charts:**
There are two bar charts in the document.
- **Bar Chart 1 (Sexual Composition):**
- This chart shows "男性" (Male) and "女性" (Female) percentages for "令和5年度 (全市)" (Fiscal Year 5 (Overall)) and "令和4年度 (全市)" (Fiscal Year 4 (Overall)).
- The x-axis is labeled "%" (Percent).
- The y-axis has labels for the years and the overall category.
- The values are displayed inside the bars.
- Since Markdown does not support embedded images or complex diagrams like bar charts, I will represent them as image placeholders with a descriptive alt text.
- **Bar Chart 2 (Age Composition):**
- This chart shows age group percentages for "令和5年度 (全市)" (Fiscal Year 5 (Overall)) and "令和4年度 (全市)" (Fiscal Year 4 (Overall)).
- The x-axis is labeled "%" (Percent).
- The y-axis has labels for the years and the overall category.
- The age groups are "19歳以下", "20歳代", "30歳代", "40歳代", "50歳代", "60歳以上".
- The values are displayed inside the bars.
- Again, I will represent this as an image placeholder.
5. **Transcribe Page Number:**
The document has a page number "3" at the bottom center. I will include this at the very end of the Markdown output.
6. **Review and Format:**
- Ensure all text is transcribed accurately.
- Check Markdown syntax for tables (pipes, hyphens for headers, correct alignment).
- Verify list item formatting.
- Ensure image placeholders are correctly named and ordered.
- Maintain the original document's logical flow.
VRAM消費はちょっと増えていた。
Thu Aug 7 18:38:56 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100-SXM4-40GB Off | 00000000:00:04.0 Off | 0 |
| N/A 36C P0 52W / 400W | 39515MiB / 40960MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
まとめ
試行回数が多いわけではないので雰囲気でしか判断できないけど、Geminiのあの画像認識力に、オープンモデルで迫っているってのは素直にすごいのではないかと思う。日本語も普通に出力されるけど、ここは Qwen 2.5-VL-7B ベース だからってのもあるよね。
ただ、現状かなりのVRAMを求められるのと、Colaboratoryだからなのかもしれないが1ページ推論するだけで数十分かかるので、ちょっと使いづらさはある。
Reasoning対応のVLMとしては過去に以下を試しているのだけどもそれと比較すると
- GLM-4.1V-9B-Thinking
- 日本語(の画像)を理解はできるが、基本的に出力は英語 or 中国語
- VRAM消費は20GB前後で(NuMarkdown-8B-Thinkingに比べれば)少ない
- チャットでやりとりが前提
- NuMarkdown-8B-Thinking
- 日本語(の画像)を理解できて、基本的に出力は英語 or 中国語
- VRAM消費は40GB近くと高い
- チャットでのやりとりはできるかわからないが、OCR+Markdown変換に特化している印象
という感じ。GLM-4.1V-9B-Thinkingを試したときにも書いているけど、Reasoningがあることで認識精度が上がる感は確かにあるが、単純なOCR用途だけだとそれに対して求められるスペックが用意できるか、ってところになるかなぁ。ある程度割り切れば軽量でもそこそこ精度高くて使いやすいモデルが他にもあるので、ユースケース次第だとは思うけども、個人的には難しいなと感じてしまった。
ただReasoningで精度は確かに向上しているという実感はあるので、今後はReasoning対応VLMってのがだんだん普通になっていくのかなと思ったり。
HuggingFace Jobsというのを使うと良いらしい?
調べてみたけど、HuggingFace上でDockerを使ったコンテナでジョブ実行ができるサービスらしい。
どうやらuvでサクッと動かせるみたいなのだけども、有償アカウント向けなので、自分はちょっと試せないな。でもまあドキュメントのOCRだったらこういうほうがやりやすいかもね、金額次第だけども。