「GLM-4.1V-9B-Thinking」を試す
モデルはこちら
ビジョン言語モデル(VLMs)は、知能システムの基本的な構成要素として確立されています。現実世界のAIタスクがますます複雑化する中、VLMsは基本的なマルチモーダル知覚を超え、複雑なタスクにおける推論能力を向上させる必要があります。これには、精度、包括性、知能の向上が含まれ、複雑な問題解決、長文脈理解、マルチモーダルエージェントなどの応用が可能になります。
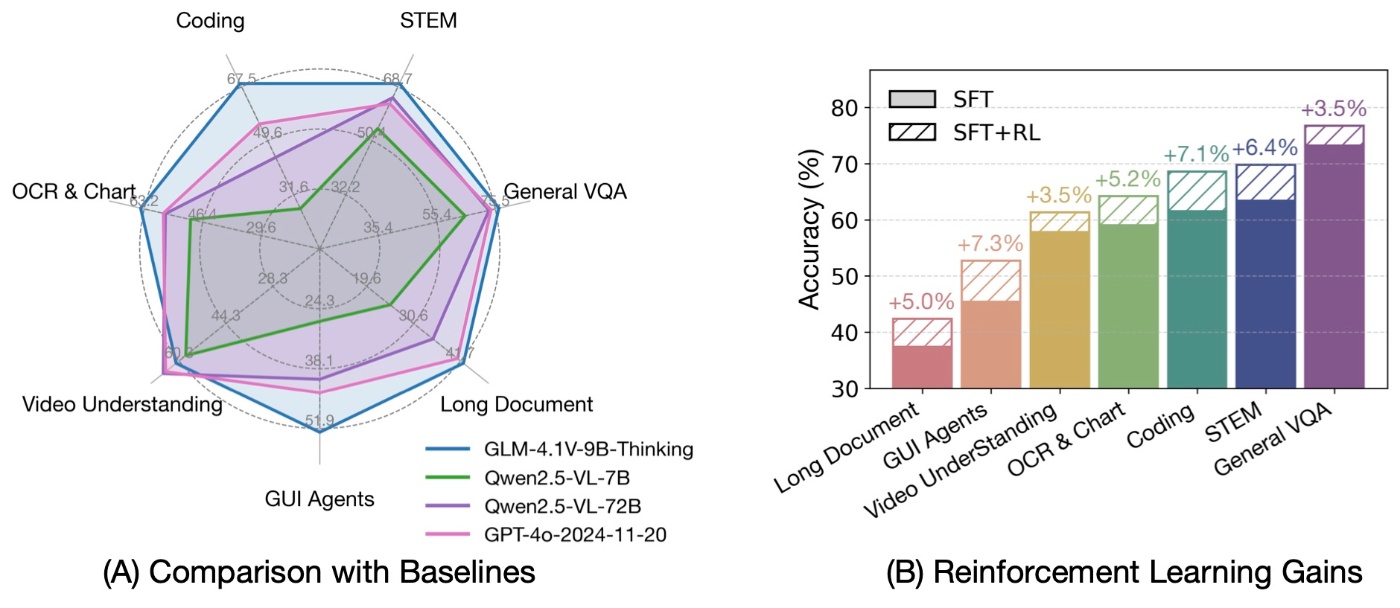
GLM-4-9B-0414基礎モデルを基盤として、私たちは新しいオープンソース VLM モデル GLM-4.1V-9B-Thinking を提案します。このモデルは、ビジョン言語モデルにおける推論の限界を追求するために設計されました。推論パラダイムを導入し、強化学習を活用することで、モデルは能力を大幅に向上させています。100億パラメータ級のVLMにおいて最先端の性能を達成し、18のベンチマークタスクで720億パラメータのQwen-2.5-VL-72Bと匹敵または上回る結果を示しています。さらに、VLMの能力の限界を追求するための研究を支援するため、ベースモデルGLM-4.1V-9B-Baseをオープンソース化しています。
referred from https://huggingface.co/THUDM/GLM-4.1V-9B-Thinking前世代のモデルである CogVLM2 および GLM-4V シリーズと比較して、GLM-4.1V-Thinking には以下の改善点があります。
- このシリーズ初の推論に焦点を当てたモデルであり、数学だけでなく、さまざまなサブドメインでも世界トップクラスの性能を発揮します。
- 64k のコンテキスト長に対応しています。
- 任意のアスペクト比と最大 4K の画像解像度に対応しています。
- 中国語と英語のバイリンガル使用に対応したオープンソース版を提供しています。
GitHubレポジトリ
実行要件が書いてある。
推論
デバイス(シングルGPU) フレームワーク 最低メモリ スピード 精度 NVIDIA A100 transformers 22GB 14~22トークン/秒 BF16 NVIDIA A100 vLLM 22GB 60~70トークン/秒 BF16 ファインチューニング
以下はLLaMA-Factoryツールキット使って画像ファインチューニングした結果に基づく。
デバイス(クラスタ) ストラテジー 最低メモリ / GPU数 バッチサイズ(GPUごと) フリーズ設定 NVIDIA A100 LORA 21GB / 1GPU 1 VITをフリーズ NVIDIA A100 FULL ZERO2 280GB / 4GPU 1 VITをフリーズ NVIDIA A100 FULL ZERO3 192GB / 4GPU 1 VITをフリーズ NVIDIA A100 FULL ZERO2 304GB / 4GPU 1 フリーズなし NVIDIA A100 FULL ZERO3 210GB / 4GPU 1 フリーズなし ※注記: Zero2でファインチューニングは損失がゼロになること場合がある。安定したトレーニングにはZero3が推奨。
実行要件を踏まえて、Colaboratory A100で。モデルカードに従って試してみる。
パッケージインストール
!pip install git+https://github.com/huggingface/transformers.git
Successfully installed transformers-4.54.0.dev0
モデルとプロセッサのロード
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
この時点でVRAM消費は20GBぐらい。
Thu Jul 3 23:04:48 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100-SXM4-40GB Off | 00000000:00:04.0 Off | 0 |
| N/A 35C P0 53W / 400W | 20103MiB / 40960MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
では推論。サンプルで使用されている画像はこんな感じのもの。
from IPython.display import Image
url = "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
Image(url)

画像について説明してもらう
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": url
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(
generated_ids[0][inputs["input_ids"].shape[1]:],
skip_special_tokens=False
)
print(output_text)
結果。<think>と<answer>になっている。
<think>Got it, let's analyze the image. It's a black-and-white photo of a parrot, probably a cockatoo or similar species, perched on a branch or perch. The parrot is in a close-up view, showing its feathers, beak, and claws. The image has a monochrome tone, so all colors are shades of gray. The parrot's posture might be grooming itself, with one claw holding its feathers. The background is blurred, focusing attention on the parrot. Let's break down the elements: the bird's plumage, the perch, the monochrome style, and the composition. Need to describe the scene accurately, noting details like the bird's position, the perch, the texture of feathers, and the overall mood (since it's black and white, maybe a bit artistic or vintage).</think><answer>The image is a black - and - white photograph featuring a parrot, likely a cockatoo, perched on a curved perch. The parrot is captured in a close - up view, showcasing its detailed plumage, beak, and claws. Its posture suggests it might be grooming itself, with one claw holding its feathers. The background is softly blurred, which brings the focus entirely to the parrot. The monochrome style gives the image a classic, artistic feel, emphasizing the textures of the feathers and the contours of the bird’s body. The overall composition highlights the parrot’s natural beauty and the intricate details of its feathers and features.
So, the final result is <|begin_of_box|>A black - and - white close - up photograph of a parrot perched on a curved perch, with the bird’s detailed plumage, beak, and claws in focus against a blurred background.<|end_of_box|></answer>
DeepL日本語訳
<think>わかりました、画像を分析しましょう。これは、おそらくオウムや類似の種と思われる、枝や止まり木に止まっているオウムの白黒写真です。オウムはクローズアップで写っており、羽、くちばし、爪が見えます。画像はモノクロ調で、すべての色がグレーの濃淡で表現されています。オウムの姿勢は、爪で羽を梳いているように見えます。背景はぼやけており、オウムに視線が集中するように構成されています。要素を分解してみましょう:鳥の羽毛、止まり木、モノクロームのスタイル、構図。シーンを正確に描写し、鳥の位置、止まり木、羽の質感、全体の雰囲気(モノクロのため、やや芸術的またはヴィンテージ風)などの詳細を記載する必要があります。</think><answer>画像は、おそらくオウム科の鳥であるオウムが曲がりくねった止まり木に止まっているモノクロ写真です。オウムはクローズアップで撮影されており、詳細な羽毛、くちばし、爪が鮮明に捉えられています。その姿勢から、自身を羽繕いしているように見え、一羽の爪で羽毛を握っています。背景は柔らかくぼやけており、オウムに完全に焦点が合っています。モノクロームのスタイルは、画像にクラシックで芸術的な雰囲気を与え、羽の質感と鳥の体の輪郭を強調しています。全体の構図は、オウムの自然な美しさと、羽や特徴の複雑な詳細を際立たせています。
したがって、最終的な結果は<|begin_of_box|>曲がりくねった止まり木に止まったオウムのモノクロのクローズアップ写真で、背景がぼやけた中で、鳥の羽、くちばし、爪の細部が鮮明に写っています。<|end_of_box|>です。</answer>
推論後のVRAM使用量
Thu Jul 3 23:05:46 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100-SXM4-40GB Off | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 81W / 400W | 20269MiB / 40960MiB | 35% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
日本語でも聞いてみる。
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": url
},
{
"type": "text",
"text": "この画像について説明して。"
}
],
}
]
(snip)
<think>用户现在需要描述这张黑白照片里的鹦鹉。首先看画面主体是一只鹦鹉,姿态应该是互动或整理羽毛?先观察细节:鹦鹉的羽毛、姿态、环境。照片是黑白的,所以色彩信息没有,但可以看纹理和形态。
首先,画面中心是一只鹦鹉,可能是在整理自己或者互动?鹦鹉的姿态,一只手(爪子)可能抓着什么,比如栖息的杆?然后看羽毛的细节,翅膀和身体的羽毛纹理,黑白对比下显得有层次。背景是模糊的植物,可能是自然环境,比如树丛,所以环境是户外或类似鸟类的栖息地。
然后描述元素:主体是鹦鹉,姿态(比如一只鹦鹉可能用爪子整理羽毛,或者和同伴互动?不过照片里看起来是一只?不对,看画面,可能是一只鹦鹉,姿态是低头或者整理自己,爪子抓着杆子?然后羽毛的细节,黑白照片下羽毛的纹理、层次感。背景的植物作为环境,衬托主体。
现在组织语言:这张黑白照片展示了一只鹦鹉,它正栖息在某个支撑物(可能是栖木)上。鹦鹉的羽毛在黑白对比下呈现出丰富的纹理和层次感,身体姿态显得放松,可能在进行整理羽毛或互动的动作(比如用喙或爪子接触自己)。背景是模糊的植物,营造出自然的环境氛围,让主体鹦鹉更加突出。整体画面通过黑白的色调,突出了鹦鹉的形态和羽毛细节,给人一种静谧的感觉,仿佛是在展示鹦鹉在自然环境中的状态。
再检查细节:鹦鹉的羽毛蓬松,姿态可能是低头靠近自己,爪子抓着栖木,背景的植物是模糊的,所以焦点在鹦鹉身上。总结:这是一张黑白摄影作品,主体是一只鹦鹉,它栖息在支撑物上,姿态自然,背景为模糊的植物,整体画面通过黑白对比突出鹦鹉的形态与羽毛细节,营造出自然静谧的氛围,展现了鹦鹉在自然环境中的状态。</think><answer>这张黑白照片展示了一只鹦鹉,它栖息在支撑物(可能是栖木)上。画面中鹦鹉的羽毛在黑白对比下呈现出丰富的纹理与层次感,身体姿态显得放松,似乎在进行整理羽毛或互动的动作(如用喙、爪子接触自身)。背景是模糊的植物,营造出自然的环境氛围,让主体鹦鹉更加突出。整体画面通过黑白色调,突出了鹦鹉的形态、羽毛细节,传递出一种静谧的自然感,展现了鹦鹉在自然环境中的状态。</answer>
なるほど、基本的には英語・中国語のみということか。
聞き方を変えてみた。
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": url
},
{
"type": "text",
"text": "describe this image in Japanese"
}
],
}
]
(snip)
<think>用户现在需要把这张鹦鹉的照片用日语描述。首先观察图片内容:黑白照片,鹦鹉的姿态,羽毛细节,动作等。要准确描述场景、主体、动作等。
首先,画像は白黒の写真で、鳥(パラオ)が写っています。パラオは、羽毛が豊かで、一羽が木製の棒(もしくは籠の部品)に足をかけています。その姿勢は、頭を後ろに傾け、口を開けているように見えます。背景には植物が見え、自然な環境に置かれています。全体の雰囲気は、静かで、パラオの表情や羽毛の質感が強調されています。
然后组织语言,用自然的日语表达:
「この画像は白黒の写真で、パラオ(鳥)が写っています。パラオは羽毛が豊かで、木製の棒(もしくは籠の部品)に足をかけています。姿勢は頭を後ろに傾け、口を開けているように見えます。背景には植物が見え、自然な環境に置かれています。全体の雰囲気は静かで、パラオの表情や羽毛の質感が強調されています。」
检查是否准确,描述元素:黑白照片、鹦鹉(パラオ)、羽毛、姿态(足をかけて、頭を傾ける、口を開けて)、背景(植物、自然環境)、整体氛围(静か、羽毛・表情の質感)。
再调整语句使其更流畅自然:
「この画像は白黒の写真で、パラオ(鳥)が写っています。パラオは豊かな羽毛を持ち、木製の棒(もしくは籠の部品)に足をかけています。姿勢は頭を後ろに傾け、口を開けているように見えます。背景には植物が見え、自然な環境に置かれています。全体の雰囲気は静かで、パラオの表情や羽毛の質感が強調されています。」
或者更简洁:
「白黒の写真で、羽毛の豊かなパラオが写っています。パラオは木製の棒に足をかけており、頭を後ろに傾け口を開けています。背景には植物があり、自然な環境にいます。全体は静かで、パラオの表情や羽毛の質感が見えます。」
不过需要更详细一点,符合描述图片的要求。最终版本:
「この画像は白黒の写真で、パラオ(鳥)が写っています。パラオは豊かな羽毛を持ち、木製の棒(もしくは籠の部品)に足をかけています。その姿勢は頭を後ろに傾け、口を開けているように見えます。背景には植物が見え、自然な環境に置かれています。全体の雰囲気は静かで、パラオの表情や羽毛の質感が強調されています。」
确认每个元素:黑白、主体(パラオ)、姿态(足をかける、頭傾け、口開く)、背景(植物、自然)、氛围(静か、質感)。
现在用更自然的日语表达,可能更口语化或正式一点,但用户需要的是描述图片,所以准确传达信息。
最终描述:
「この画像は白黒の写真で、パラオ(鳥)が写っています。パラオは豊かな羽毛を持ち、木製の棒に足をかけています。姿勢は頭を後ろに傾け、口を開けているように見えます。背景には植物が見え、自然な環境に置かれています。全体の雰囲気は静かで、パラオの表情や羽毛の質感が強調されています。」
或者简化为:
「白黒写真で、羽毛の多いパラオが写っています。パラオは木の棒に足をかけていて、頭を後ろに傾けて口を開けています。背景には植物があり、自然な場所にいます。全体は静かで、パラオの表情や羽毛の質感が見えます。」
不过可能需要更准确,比如“足をかけて”是站在上面,“傾ける”是头向后倾斜,“口を開けて”是张嘴。
总结,最终描述:
「この画像は白黒の写真で、パラオ(鳥)が写っています。パラオは豊かな羽毛を持ち、木製の棒に足をかけています。その姿勢は頭を後ろに傾け、口を開けているように見えます。背景には植物が見え、自然な環境に置かれています。全体の雰囲気は静かで、パラオの表情や羽毛の質感が強調されています。」
这样应该覆盖了图片的主要元素:黑白、主体(鹦鹉)、姿态、背景、氛围。</think><answer>以下是对该图片的日语描述:
「この画像は白黒の写真で、パラオ(鳥)が写っています。パラオは豊かな羽毛を持ち、木製の棒(もしくは籠の部品)に足をかけています。姿勢は頭を後ろに傾け、口を開けているように見えます。背景には植物が見え、自然な環境に置かれています。全体の雰囲気は静かで、パラオの表情や羽毛の質感が強調されています。」
(注:描述中“パラオ”为鹦鹉的日语表述,可根据语境替换为“鳥”等更通用的表述;整体围绕画面主体(鹦鹉)、姿态、背景、氛围等要素展开,准确传达图片内容。)</answer>
日本語の画像を食わせてみる
風景

messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://storage.googleapis.com/zenn-user-upload/82968d23b6c5-20250228.jpg"
},
{
"type": "text",
"text": "describe this image. where is this?"
}
],
}
]
<think>Got it, let's analyze the image. The key elements are a red tower, modern buildings, a waterfront with boats, and a distinctive white structure. The red tower is the Kobe Port Tower, which is a well-known landmark in Kobe, Japan. The waterfront area with the tower and the surrounding architecture matches Kobe's harborland area. So, this location is likely Kobe Port, specifically the Kobe Harborland area with the Kobe Port Tower.</think><answer>This image shows a waterfront cityscape with a prominent red tower, modern buildings, and a harbor with boats. The distinctive red tower is the Kobe Port Tower, a well - known landmark in Kobe, Japan. The area is part of Kobe's Harborland, a popular waterfront district. Therefore, this location is <|begin_of_box|>Kobe Port (Harborland area in Kobe, Japan)<|end_of_box|>.</answer>
日本語訳
<think>わかりました、画像を分析しましょう。重要な要素は、赤い塔、近代的な建物、ボートのあるウォーターフロント、そして特徴的な白い建造物です。赤い塔は、神戸の有名なランドマークである神戸ポートタワーです。塔と周囲の建築物のあるウォーターフロントエリアは、神戸のハーバーランドエリアと一致しています。したがって、この場所は神戸港、具体的には神戸ポートタワーのある神戸ハーバーランドエリアである可能性が高いです。</think>
<answer>この画像は、赤い塔が印象的なウォーターフロントの街並み、近代的なビル、そして船が停泊する港を描いたものです。特徴的な赤い塔は、神戸の有名なランドマークである神戸ポートタワーです。このエリアは、人気のウォーターフロント地区である神戸のハーバーランドの一部です。したがって、この場所は<|begin_of_box|>神戸港(神戸のハーバーランドエリア)<|end_of_box|>です。</answer>
日本の知識もある程度持ってそう
書籍の表紙

messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://storage.googleapis.com/zenn-user-upload/caa14aef4b7e-20250226.png"
},
{
"type": "text",
"text": "What does the cover of this book say?"
}
],
}
]
<think>Got it, let's look at the book cover image. The title in large black text is "全体観" (which is "Overall View" maybe, but let's check the Japanese text). Then there's a subtitle: "ドキュメント・コミュニケーションの全体観" (Document Communication's Overall View). Below that, there's text about "提案書、報告書、会議資料の「実」を「効率化」で向上するメカニズム" (Mechanism to improve the "effectiveness" of proposal documents, reports, meeting materials). Then "上巻 原則と手順 上川邦夫" (Volume 1: Principles and Procedures, Uekawa Kuniо).
Then the green section has "コミュニケーションはすべて 解・動・早 で進めよ" (Communication should proceed with "解" (explain), "動" (act), "早" (quickly)). Also, the diagram has "原則" (Principle), "技法" (Technique), "手順" (Procedure), "試合調整" (Adjustment).
So the main title is "全体観" (Overall View), subtitle about document communication, then the green part with the slogan. Let's list all the text:
- Top: "ドキュメント・コミュニケーションの 全体観" (Document Communication's Overall View)
- Below that: "提案書、報告書、会議資料の「実」を「効率化」で向上するメカニズム" (Mechanism to improve the "effectiveness" of proposal documents, reports, meeting materials)
- Then "上巻 原則と手順 上川邦夫" (Volume 1: Principles and Procedures, Uekawa Kuniо)
- Green section: "コミュニケーションはすべて 解・動・早 で進めよ" (Communication should proceed with "解" (explain), "動" (act), "早" (quickly)) and the smaller text "解いてただ、動いてただ、いたただ早く" (Explain, act, be quick)
- The diagram has "原則" (Principle), "技法" (Technique), "手順" (Procedure), "試合調整" (Adjustment)
So the cover text includes the title, subtitle, author info, and the slogan.</think><answer>To determine what the cover of the book says, we analyze the text elements on the image:
- Main Title: Large black text at the top reads “全体観” (Overall View), with a subtitle “ドキュメント・コミュニケーションの” (Document Communication’s).
- _Subtitle/Description: Below the main title, it says “提案書、報告書、会議資料の「実」を「効率化」で向上するメカニズム” (A mechanism to improve the “effectiveness” of proposal documents, reports, and meeting materials).
- Volume and Author: “上巻 原則と手順 上川邦夫” (Volume 1: Principles and Procedures, Uekawa Kuniо).
- Green Section Slogan: The green lower section has “コミュニケーションはすべて 解・動・早 で進めよ” (Communication should proceed with “解” (explain), “動” (act), “早” (quickly)), with a smaller text “解いてただ、動いてただ、いたただ早く” (Explain, act, be quick).
- Diagram Labels: The diagram includes “原則” (Principle), “技法” (Technique), “手順” (Procedure), “試合調整” (Adjustment).
Combining these, the key cover text includes the title, subtitle, author info, and slogan.
Ultimately, the answer is <|begin_of_box|>全体観(ドキュメント・コミュニケーションの全体観、提案書等の効率化メカニズム、コミュニケーションは解・動・早で進めよ等)<|end_of_box|>.</answer>
少し間違ってるところもあるけど、全体的に読めているし、Reasoningらしい意味が通っている感がある
ダミーの請求書

messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://storage.googleapis.com/zenn-user-upload/4697c3aef653-20250226.png"
},
{
"type": "text",
"text": "What does this invoice say in detail?"
}
],
}
]
<think>Got it, let's analyze the invoice image. First, the title is "御請求書" (Invoice). The invoice number is INV-2024-0820. The company name is 模範商事株式会社 (Modan Shoji Kabushiki Kaisha), with the address, phone, fax. The recipient is 範例工業株式会社 (Example Kogyo Kabushiki Kaisha).
Then there's a table with items: 特送和紙 (A4 size special washi paper), 高級墨 (premium ink), 笺セット (various stationery sets). Each has quantity, unit price, total.
The details:
- 特送和紙 (A4 size): 1000, ¥50 each, total ¥50,000
- 高級墨 (premium ink): 20, ¥2,000 each, total ¥40,000
- 笺セット (various stationery sets): 50, ¥1,000 each, total ¥50,000
Subtotal ¥140,000, tax 10% (¥14,000), total ¥154,000.Notes:
- 支払いは請求書発行日より30日以内にお願いいたします (Payment due within 30 days from invoice date)
- 抵送手数料は貴社負担でお願いいたします (Delivery fee is at your company's expense)
- 本書に関するお問い合わせはお下記で配担当者までご連絡ください (For inquiries about this document, contact the designated contact below)
Contact: 担当: 菅業部 見本太郎 (Contact: Sales Department, Kimoto Taro)
Now, need to present all these details clearly, translating the Japanese terms into English where needed, but keeping the original text structure.</think><answer>The invoice (御請求書) details are as follows:
Header Information
- Invoice Title: 御請求書
- Invoice Number: INV-2024-0820
- Issuing Company: 模範商事株式会社 (Modan Shoji Kabushiki Kaisha)
- Address: 〒100-0001 東京都千代田区見本町1-1
- Phone: 03-1234-5678, FAX: 03-1234-5679
- Recipient: 範例工業株式会社 (Example Kogyo Kabushiki Kaisha)
Itemized List (Table)
Item Quantity Unit Price Total Amount 特送和紙 (A4サイズ) (Special A4-sized washi paper) 1000 ¥50 ¥50,000 高級墨 (松煙) (Premium ink) 20 ¥2,000 ¥40,000 笺セット (各種) (Various stationery sets) 50 ¥1,000 ¥50,000 Subtotal: ¥140,000
Tax (10%): ¥14,000
Total Amount: ¥154,000Notes
- 支払いは請求書発行日より30日以内にお願いいたします。 (Payment is requested within 30 days from the invoice issuance date.)
- 抵送手数料は貴社負担でお願いいたします。 (Delivery fees are at your company’s expense.)
- 本書に関するお問い合わせはお下記で配担当者までご連絡ください。 (For inquiries about this document, contact the designated contact below.)
Contact
担当: 菅業部 見本太郎 (Contact: Sales Department, Kimoto Taro)
This invoice outlines the purchase of stationery items, including their quantities, prices, and total cost, along with payment and contact details.</answer>
中国語の漢字になってしまっているところはあるけども、ほぼ完璧ではなかろうか。
VRAM消費の推移はこんな感じ。

モデルロード後は突発的に上昇したりせずにある程度安定して推移してると思うので、これなら24GBでも使えそう。画像を多く処理するとどんどん増えていくとは思うけど。
まとめ
それなりにVRAMを必要とするので、単にOCR用途で使うだけならば、VRAM消費がより少なくてある程度精度があるモデルも他にあると思う。自分が過去試した中で軽量+日本語文字認識力が高かかったのはこのあたりかな。
OCRとかドキュメント系のソリューションもいろいろあるし。
ただ、GLM-4.1V-9B-Thinkingはその名の通りReasoningモデルなので、単なる画像認識・OCRよりもなんかこう「理解している」感が出るのが良い。マルチターンでこのあとのやり取りを続けるとそれが活きてきそうな気がする。
日本語に関しては入出力に対応していないけども、モデル自体は、日本の知識・日本語の文字読解力を両方バランスよく持ってるように思えた。ここを両方備えてるモデルは少ないかもしれない。Sarashina2-visionがそれかなと思うけど、GLM-4.1V-9B-Thinkingと同じぐらいVRAM使う+Reasoningモデルではない、ということを考えると、GLM-4.1V-9B-Thinkingが日本語化されると嬉しい。