競馬のデータ解析・可視化いろいろ
netkeibaのレース結果の更新タイミングについて
上記ではレースデータのスクレイピングを以下のURLに対して行っている。
https://db.netkeiba.com/race/レースID
こういう画面。
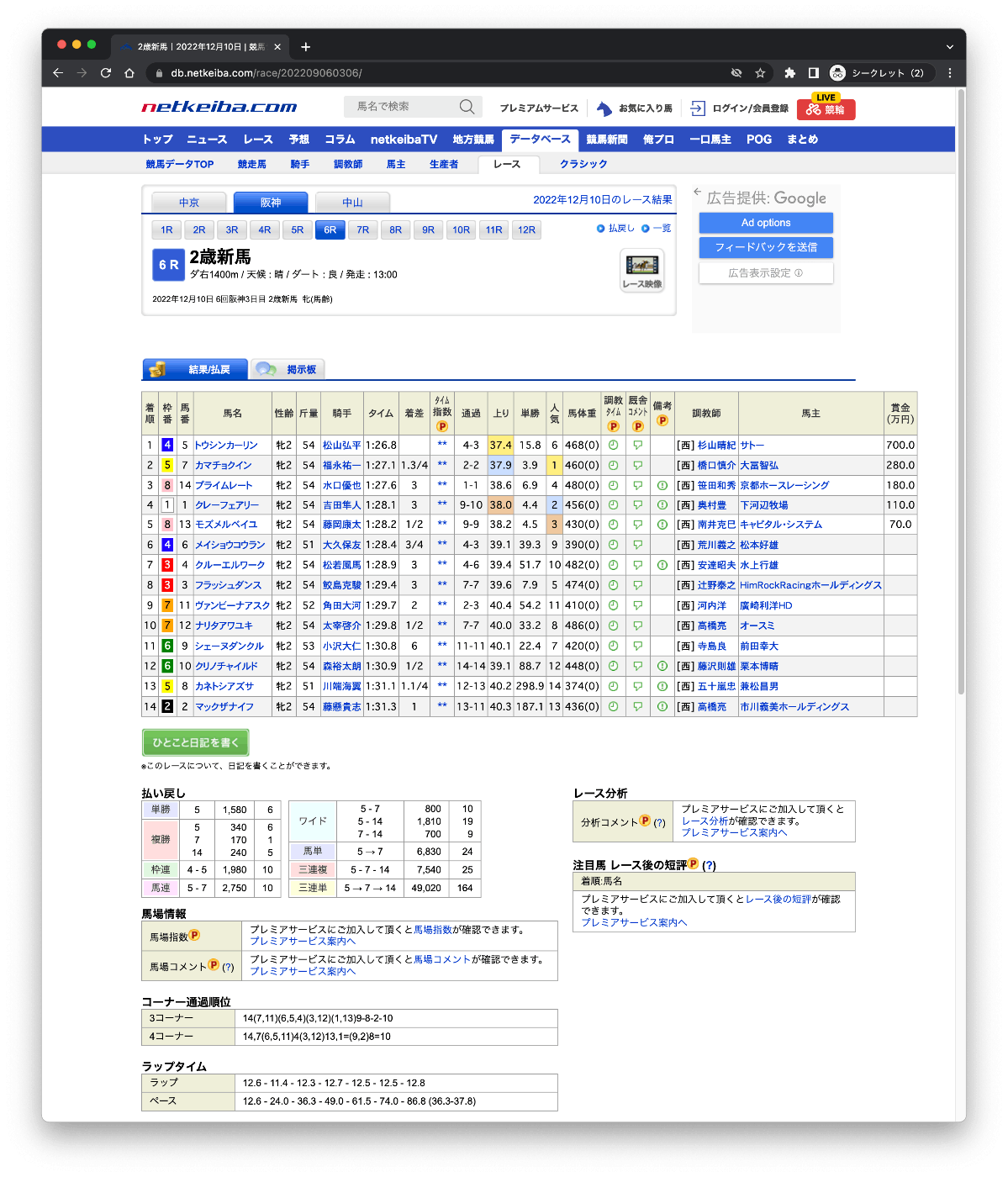
ただし、開催「直後」の結果は上記には反映されず、こちらのURLのみになる様子。
https://race.netkeiba.com/race/result.html?race_id=レースID&rf=race_list
こういう画面。

開催直後に https://db.netkeiba.com/race/レースIDにアクセスするとこうなる

ということで以下のようなケースだと最初のzennの記事のコードではデータが取れない。
- 日曜の予想のために、土曜の結果を踏まえたい。
- 開催が終わったらすぐ解析したい。
またHTMLの構造も異なっているので修正が必要。
Results.scrape()を修正してみた。
class raceResults:
@staticmethod
def scrape(race_id_list):
"""
レース結果データをスクレイピングする関数(race.netkeiba.com用)
ex) https://race.netkeiba.com/race/result.html?race_id=202307010611
Parameters:
----------
race_id_list : list
レースIDのリスト
Returns:
----------
race_results_df : pandas.DataFrame
全レース結果データをまとめてDataFrame型にしたもの
"""
#race_idをkeyにしてDataFrame型を格納
race_results = {}
race_results_tairetsu = {}
race_results_pace = {}
for race_id in tqdm(race_id_list):
time.sleep(1)
try:
url = f"https://race.netkeiba.com/race/result.html?race_id={race_id}&rf=race_list"
#メインとなるテーブルデータを取得
df = pd.read_html(url)[0]
# 上記以外はスクレイピングする
html = requests.get(url)
html.encoding = "EUC-JP"
soup = bs4.BeautifulSoup(html.text, "html.parser")
# レース名
df["race_name"] = soup.find("div", attrs={"class": "RaceName"}).text.replace('\n', '')
# レースの種類、コースの長さ、天気・馬場
race_info01 = soup.find("div", attrs={"class": "RaceData01"}).text
infos = race_info01.splitlines()
race_type_distance = infos[1].split(' / ')[1]
m = re.match(r'(\D)(\d+)m', race_type_distance)
df["race_type"] = m.group(1).replace('ダ','ダート').replace('障','障害')
df["course_len"] = m.group(2)
weather = infos[2].replace('/ 天候:','')
df["weather"] = weather
ground_state = infos[3].replace('/ 馬場:','').replace('稍','稍重')
df["ground_state"] = ground_state
# 日付・クラス
title = soup.find("title").text
date = re.search(r'^.* (\d+年\d+月\d+日) .*', title).group(1)
df["race_date"] = date
# 条件
jyoken = soup.find("div", attrs={"class": "RaceData02"}).find_all("span")[3].text
jyoken = jyoken.replace('サラ系','')
df["jyoken"] = jyoken
# クラス
uclass = soup.find("div", attrs={"class": "RaceData02"}).find_all("span")[4].text
# オープンの場合はグレード情報を取得する
if uclass == "オープン":
grade = re.search(r'\(([^)]+)\)', title.split("|")[0])
if grade:
if grade.group(1) == "L":
df["class"] = f"{uclass}({grade.group(1)})"
else:
df["class"] = grade.group(1)
else:
df["class"] = uclass
else:
df["class"] = uclass
#馬ID、騎手IDをスクレイピング
horse_id_list = []
horse_a_list = soup.find("table", attrs={"summary": "全着順"}).find_all(
"a", attrs={"href": re.compile("^https://db.netkeiba.com/horse")}
)
for a in horse_a_list:
horse_id = re.findall(r"\d+", a["href"])
horse_id_list.append(horse_id[0])
jockey_id_list = []
jockey_a_list = soup.find("table", attrs={"summary": "全着順"}).find_all(
"a", attrs={"href": re.compile("^https://db.netkeiba.com/jockey")}
)
for a in jockey_a_list:
jockey_id = re.findall(r"\d+", a["href"])
jockey_id_list.append(jockey_id[0])
df["horse_id"] = horse_id_list
df["jockey_id"] = jockey_id_list
#インデックスをrace_idにする
df.index = [race_id] * len(df)
race_results[race_id] = df
#存在しないrace_idを飛ばす
except IndexError:
continue
except AttributeError: #存在しないrace_idでAttributeErrorになるページもあるので追加
continue
#wifiの接続が切れた時などでも途中までのデータを返せるようにする
except Exception as e:
print(e)
break
#Jupyterで停止ボタンを押した時の対処
except:
break
#pd.DataFrame型にして一つのデータにまとめる
race_results_df = pd.concat([race_results[key] for key in race_results])
return race_results_df
あと以下も追加してる。
- レース名を取得
- 条件を取得
- ◯歳以上とか
- 競走馬クラスを取得
- 新馬
- 未勝利
- ◯勝クラス
- オープン
- オープン(L)
- G◯
元のクラス名とは別名にしておいて呼び出すところを変えれば切り替えもかんたんにできる。
ただし、db.~とrace.〜では以下の違いがあるので注意。
- ジョッキーや厩舎の表記が異なる。
- ジョッキーは、
db.~だとフルネーム、race.〜だと短縮表記っぽい。 - 厩舎も、
db.~だと[栗]山田太郎みたいになるけど、race.〜だと何も考えずにスクレイプすると栗東山田太みたいになる
- ジョッキーは、
あと気づいたこと。
-
race.〜からdb.~への更新のタイミングは厳密にはわからないけど、すくなくとも月曜15:00段階では更新されてない。開催翌週のどこかでは更新されるはず。 - 競走馬の過去走(
https://db.netkeiba.com/horse/競走馬ID)にも開催直後のレースはすぐには追加されない。上と同じタイミングだと思う。 -
race.〜の各競走馬ごとの「コーナー追加順」もすぐには反映されないけど、こちらはdb.~ほどタイムラグはなくて、厳密に見てはいないけど少なくとも開催当日の夜には反映されている気がする。
レース結果を元に解析する場合、以下の2つの方法がある
https://race.netkeiba.com/race/result.html?race_id=レースIDhttps://db.netkeiba.com/race/レースID/
(db.*のほうにしかない)有料部分を除けば、だいたい同じ内容なのだが、いくつか違いがある。
1つ目は上の書いてあるとおり、更新タイミングが違う。
https://race.netkeiba.com/race/result.html?race_id=レースIDのほうは、
- レース直後に一部を除いて反映される。反映されないのは各馬ごとの「コーナー通過順」
- 「コーナー通過順」は月曜日夜には反映される。
https://db.netkeiba.com/race/レースID/の方は
- レース結果は月曜日夜まで反映されない。各出走馬の戦績(
https://db.netkeiba.com/horse/馬ID/)も同じ。
この辺はタイミングの問題だけで、例えばタイムリーに土曜の夜に解析する必要があるとかだと前者しかない(かつ各馬のコーナー通過順はコーナー通過順位表記を元に仮で出す必要がある)かないかだけだと思う。
2つ目は、地方・海外のレースが過去戦績に含まれていてこの結果を取得する場合に大きな違いが出る。
いずれの場合も、https://race.netkeiba.com/race/result.html?race_id=レースIDでは満足なデータが取れない場合が多く、https://db.netkeiba.com/race/レースID/のほうが比較的マシ。
この点には注意すべし。
変な独自タグでpd.read_htmlが使えない場合がある
メモ
JRAの馬場情報更新タイミング
自分の認識ではこんな感じ。
- 金(開催前日):金曜正午ぐらいに更新される
- 土日(開催当日): 当日AM9:00頃までには更新されている