Polarsに入門してみる
とりあえず自分的には
- Pandasある程度使えるようになってきたけどIndexちょっと難しすぎる。
- ローカルのdevcontainerとかで動かしてるけど、結構重い。
- 自作の競馬データの解析ツールをPandasから移行したいが、plotlyとかstreamlitとか使ってるのでちょっとビビってる
ということで、見た感じは良さげなので、まずは入門してみる。
Jupyter Labでやります
$ pip install jupyterlab ipywidgets
$ jupyter-lab --ip='0.0.0.0'
インストール
!pip install polars
で、ちょっとかんたんにスクレイピングしたデータで遊んでみたい。
pandasライクに書いてみるとpd.read_htmlがあるのかなーと思いきや
Thank you for your suggestion. I think, though, that html parsing is out-of-scope for Polars, and best left to dedicated libraries like beatifulsoup and lxml, which is what Pandas is using internally anyways. What benefits would an integration have over calling a html parser separately? Also, please note that although Polars is similar to Pandas, both are DataFrame librariers after all, it is in no way meant to be a drop-in replacement for Pandas, so suggestions for new features will be judged based on their own merit.
残念。でもまあわかる。
ということでPolarsにはPandasから移行するためのメソッドが用意されているので、これを使う。
まずpandasとスクレイプ周りのパッケージを追加。カーネルリスタート必要かも。
!pip install pandas lxml pyarrow html5lib bs4
from_pandasを使う。
import polars as pl
import pandas as pd
pd_df = pd.read_html("https://db.netkeiba.com/race/202306030811/")[0]
pl_df = pl.from_pandas(pd_df)
pl_df
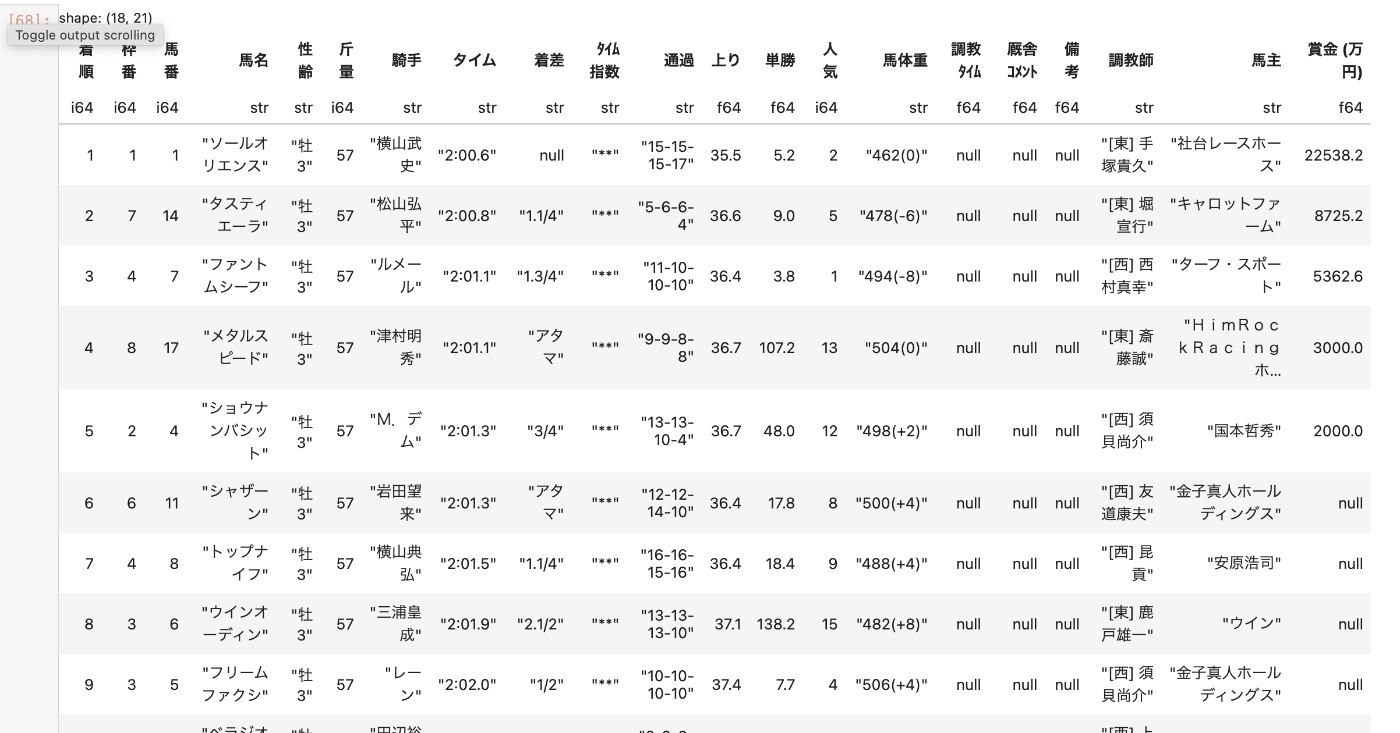
結果
列の型が見えているのが良い。
イレギュラーなやつ。
import polars as pl
import pandas as pd
pd_df = pd.read_html("https://db.netkeiba.com/race/202306030807/")[0]
pl_df = pl.from_pandas(pd_df)
pl_df

「除外」が含まれているので、"着順"がstr、「タイム」「着差」がnullになっている。
全然polarsとは関係ないけど、よく見ると取れてない列がある。変な独自タグのせいみたい。この辺も踏まえて、requestsを使ってみる。
import polars as pl
import pandas as pd
import requests
import re
url = "https://db.netkeiba.com/race/202306030811/"
r = requests.get(url)
r.encoding = 'euc-jp'
r = re.sub(r'</?diary_snap(_cut)?>', '', r.text)
df = pl.from_pandas(pd.read_html(r)[0])
df