Corrective Retrieval Augmented Generation(CRAG)
Pineconeブログがわかりやすくてよい
LangChainでの実装
LlamaIndexでの実装
説明がわかりやすくて良い
プロセスとしては、
- 持っているドキュメントに検索しに行く
- 検索したドキュメントから取得した内容が、関連しているか、してないかを判定する。
- 知識をより洗練する。
- 取得した内容が関連していない → 文脈を補足するためにウェブベースの文書検索を実行する。そのために質問をWeb検索用に最適化+Webで検索して知識を補強!
- 取得した内容が関連している → 取得してきたドキュメントを分割して、各分割に対して評価して無関係なものは除去!
- 取得した内容が関連してるか微妙 → 知識の洗練とWebでの情報取得の両方を行う。
- 回答を生成する。
- 取得した内容が関連していない → 質問+Webで検索して知識で回答を生成
- 取得した内容が関連している → 質問+洗練した知識で回答を生成
- 取得した内容が関連してるか微妙 → 質問+Webで検索して知識+洗練した知識で回答を生成
簡単にいうと、
RAGに指定した文書に関連する内容があったら、知識を洗練する!なかったらWeb検索しに行けばいいんやん、関連してるかわからんやったらどっちもやろ!
ってことです。
Self-RAGもそうだけども、ポイントは最終的な生成の根拠をより最適化・改善しようというもの。
LlamaIndexのnotebookに従ってやってみる。ローカルのjupyter labで。
検索にはTavilyAIが使用されるので、あらかじめアカウント作成してAPIキーを取得しておく。無料でも1000リクエスト/月はできるみたい。
パッケージインストール。
!pip install \
llama-index-llms-openai \
llama-index-embeddings-openai \
llama-index-tools-tavily-research \
llama-index-packs-corrective-rag \
llama-index-readers-file \
llama-index-callbacks-arize-phoenix \
python-dotenv
余談
- なるほど、LlamaIndexの新しいパッケージ構成、こういう絞り方で指定するのがやはり良い気がする。
-
llama-indexパッケージででインストールするといくつかのインテグレーションパッケージがセットになってインストールされる。 - 無駄なパッケージがあるとはいわないけど、商用とかでやるなら当然こちらのほうが良さそうではある。
- coreパッケージは依存で入るだろうから、必要なものにllms-openaiとembeddings-openai入れれば、まあだいたいのケースでいけそう。
-
- 今回はArize Phoenixでトレーシングを追加する。
- CRAGのLlamaPack、全くといっていいほど出力がないので、何が起きてるか全然わからないため。
- 個人的に思ったのは、Packを作って提供するならば、どういう動きになるかをわかりやすく出力できるよう、
verboseを追加して欲しい。。。
- あと今回はPackもパッケージでいれる。カスタマイズできないデメリットはあるけど、動かすだけなら
from llama_index.packs.corrective_rag import CorrectiveRAGPackで読み込めるので簡単。
.envを作成しておいて、OpenAI とTavilyのAPIキーをセット。
OPENAI_API_KEY=XXXXXXXXXX
TAVILY_API_KEY=XXXXXXXXXX
from dotenv import load_dotenv
load_dotenv(verbose=True)
Arise Phoenixでトレーシングを有効化。URLが表示されたらブラウザで開いておく。
import phoenix as px
from llama_index.core import set_global_handler
px.launch_app()
set_global_handler("arize_phoenix")
ではRAGのドキュメント作成。コンテンツはこちらを使用。
from pathlib import Path
import requests
from llama_index.core import SimpleDirectoryReader
# Wikipediaからのデータ読み込み
wiki_titles = ["オグリキャップ", "タマモクロス"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page["extract"]
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
documents = SimpleDirectoryReader("data").load_data()
ドキュメントとTavilyのAPIキーを渡して、CorrectiveRAGPackのインスタンスを作成。
from llama_index.packs.corrective_rag import CorrectiveRAGPack
corrective_rag = CorrectiveRAGPack(documents, tavily_ai_apikey=os.environ['TAVILY_API_KEY'])
ではクエリ。
response = corrective_rag.run("オグリキャップの主な勝ち鞍は?", similarity_top_k=5)
print(response)
オグリキャップの主な勝ち鞍は、重賞12勝(うちGI4勝)であり、その中には第41回(1991年)のダイイチルビー、第42回(1992年)のヤマニンゼファーなどが含まれています.
では何をやっているのかをArize Phoenixでみてみる。全体はこんな感じ。
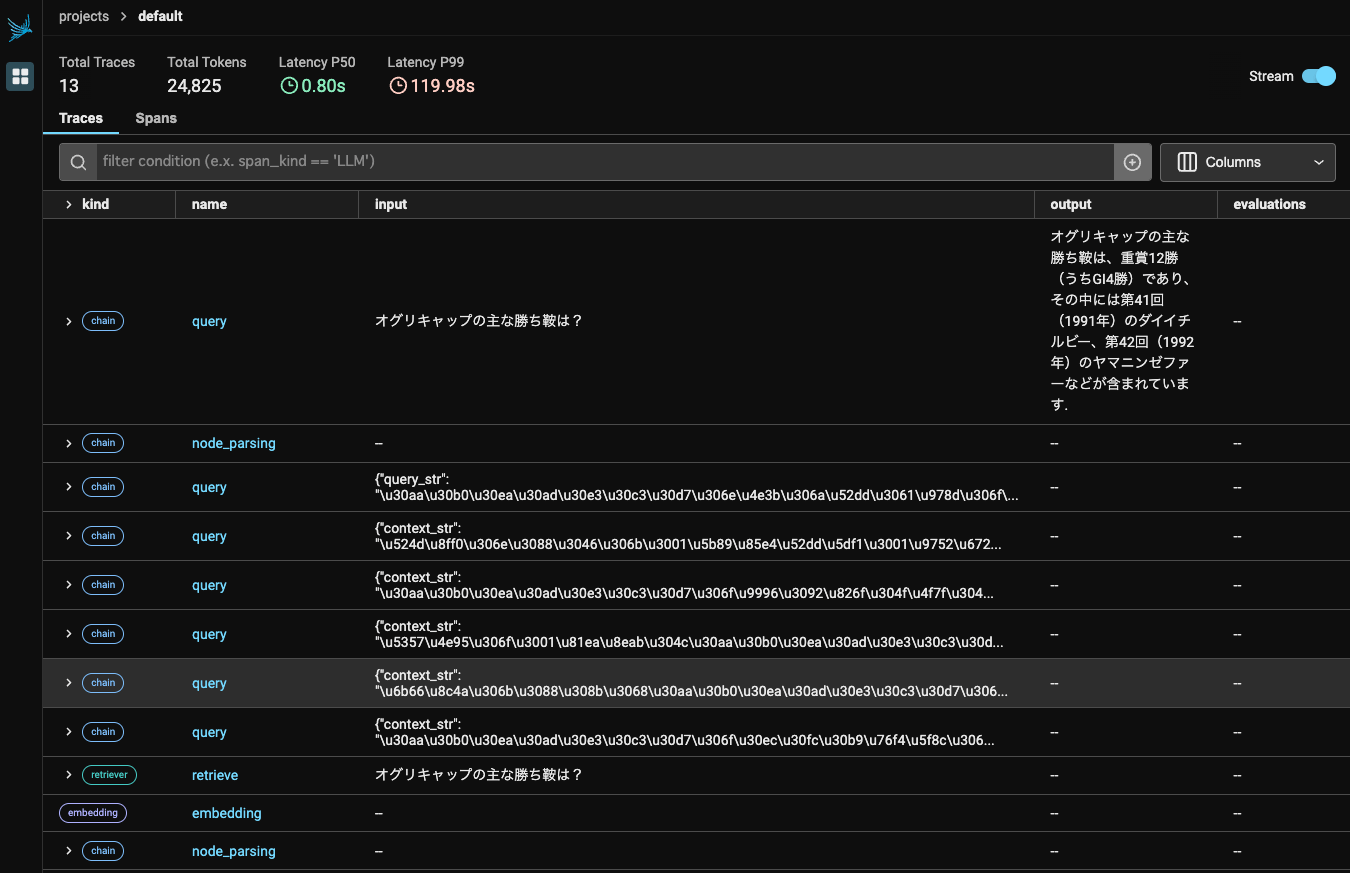
細かく見ていくと、まず最初にドキュメントをチャンクに分割してembeddingsを生成してベクトルインデックスを作成。

次にクエリでベクトルインデックスを検索。ここで5件の検索結果が得られている。

各検索結果ごとに、クエリに対して適切な検索結果なのか?をLLMに判定してYes/Noを下す。


なお、今回は5件の検索結果はすべてNoだった。
検索結果にNoが含まれている場合は、クエリを検索しやすい形に変換する。
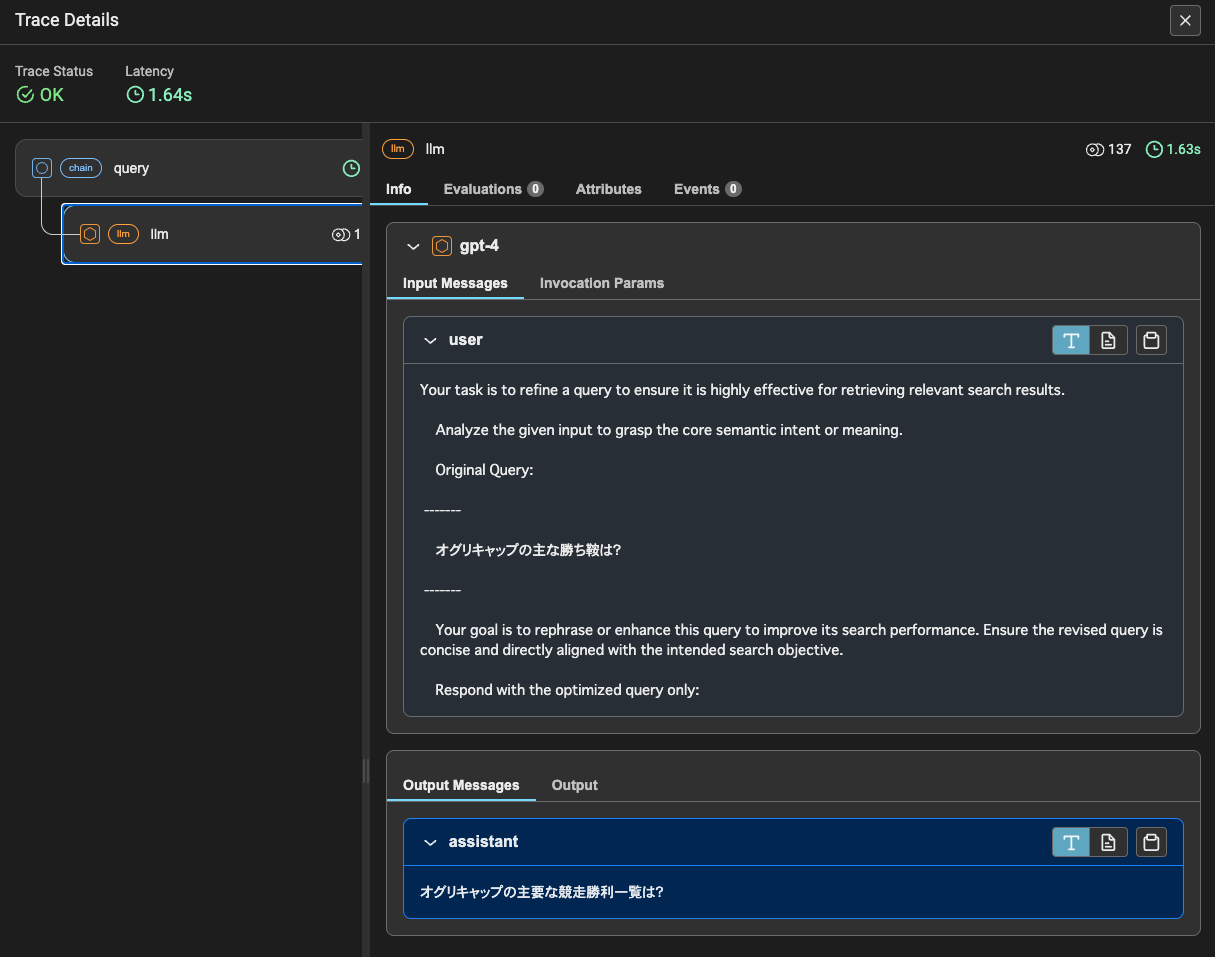
で、ここからはログも出ないし、トレーシングの情報も全部カバーできてないように思えるので、雑にコード読んだ感じからの推測藻含めて、なのだけども、
- 先ほど書き換えたクエリでTavily APIで検索
- 取得した検索結果をチャンクに分割
- このチャンクごとにREFINE QAテンプレートを使って、最初のクエリを使って、最終回答を生成する。
という流れになってるように見える。

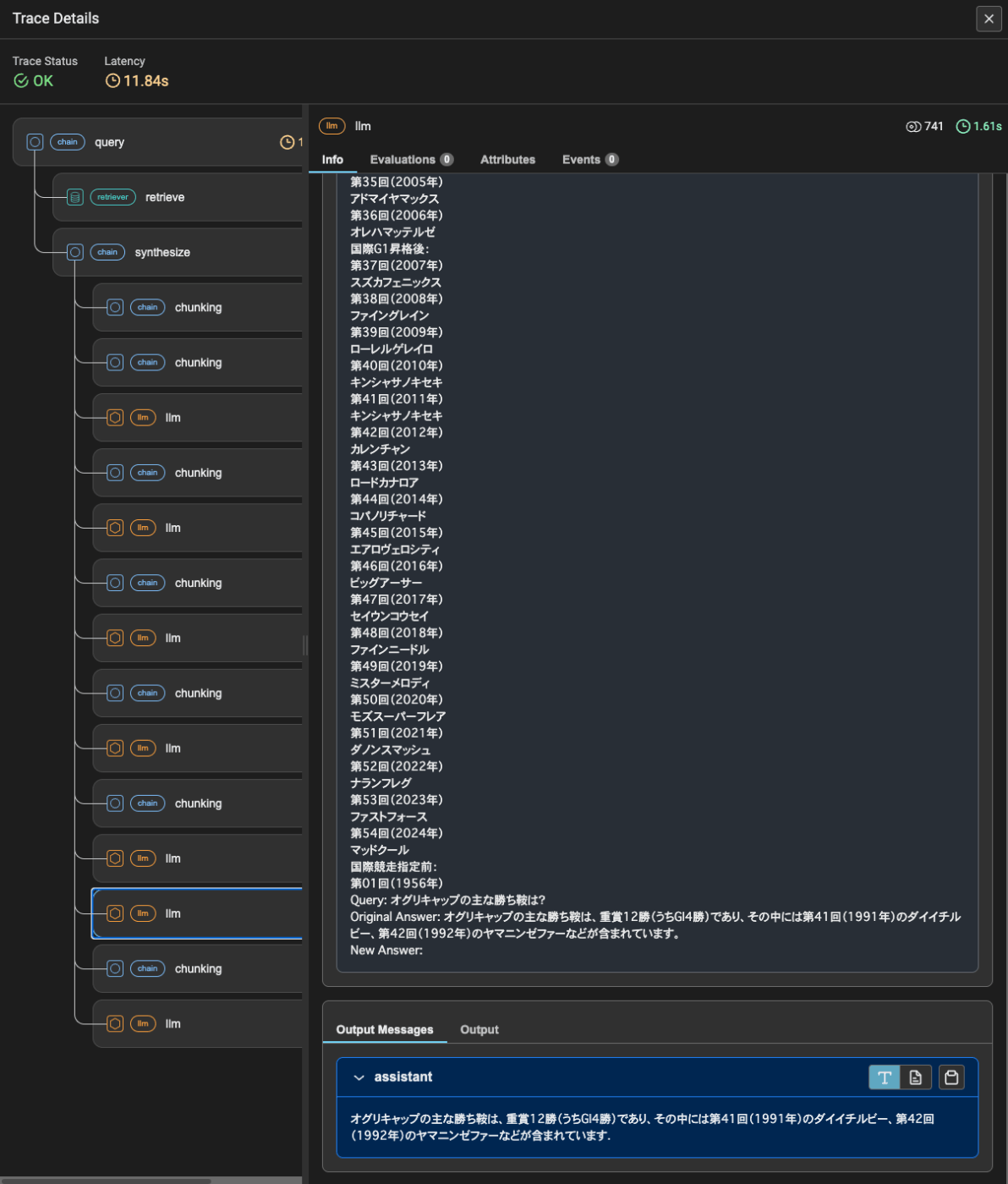
まあ最終的な回答はあっていないんだけどね、これはLlamaPackのCRAG実装に依るところもあるとは思う。
- 今の実装はドキュメントしか渡せない。チャンク分割とかもデフォルトでしかできない。当然ながら最初のretrievalの精度が低い
- 今回はYes/No判定では全部Noだった。実際にはYesのものは最終的な回答生成の根拠に使用されるはずだと思うので、そこが0になってしまったので、Tavilyに完全に依存した形になってしまっている。
- プロンプトも全部英語でPackの外からいじれない。日本語にしたら精度上がるか?と言われると微妙ではあるけども。
- Tavilyが果たしてretrievalを補完する検索機能として実用に足りうるのかがわからない。トレーシングで取得してきた内容を見る限りは、結局同じソース(Wikipedia)を使っているように見えるし、ここでもチャンク分割はイマイチな印象を受ける。
理屈としては、なるほど、Self-RAGと考え方は同じに思える。retrievalの精度が足りないのを補完する考え方ではあるのだけども、じゃあ元々のretrievalの精度は適当でも良いか?というとそういうわけではないように思えるので、少なくとも一定レベルで精度を上げれるようにチャンク分割とかはコントロールできるような実装にしておいたほうがいいと思う。
LlamaPackは、ショウケース的なところもあるのである程度雑な実装になっててもしょうがないと思うけど、やっぱり実装はきちんとやらないとダメだなーという感じ。複雑なことをやっているわりにログが全然出てないのも実運用だと難しいしね。
これを参考に自分で実装するというのが正しいあり方ではある。
あと、これ最初のYes/No判定のモデルはgpt-4でPackの中にハードコーディングされているのだよね。ここの判定の精度が低いとダメなのは理解するんだけども、検索結果の数だけgpt-4で問い合わせすることになる。。。
ここはSelf RAGにも言えることだけど、検索精度を高めるためにLLMを使った処理を追加する以上は、コストとレスポンス時間が増えることを考慮しておく必要はある。
あとなんとなく思ったのは、こういう複雑なものをやるならば、LangChainでLangGraph使ってフロー的に実装するほうが筋は良さそうかな。
LlamaIndexにも似たような概念としてQuery Pipelineはあるのだけど、ちょっとLangGraphに比べると柔軟性が足りない感がある。特にエージェントまで考えた場合に、Query Pipelineはループできないのが弱いし、やるとするならばエージェントモジュールと組み合わせるようなのだけど、それだとちょっと複雑になってしまうし、Query Pipelineの可視化からもそこは外れてしまって、見通しが悪くなる気がする。