RAGを超えたCRAGを実装する。~ そしてRAGのその先へ ~ LangGraphでのTypescriptのコードサンプル付き
TL;DR
- CRAGはRAGの改良版です
- 指定したドキュメントに関連する内容があったら、知識を洗練する!なかったらWeb検索しに行けばいいんやん、関連してるかわからんやったらどっちもやろ!
- 論文によるとSelf-RAGなどと比べると精度は基盤モデルに依存しないのがいい点
- CRAGの実装にはLangGraphを使うと実装できる
- 「知識を洗練するフェーズ」と「質問とドキュメントの関連が曖昧な時のフロー」は実装から抜いています。(拡張可)
- LangChain全体的に型がちゃんとしてないので、ドキュメントしっかりみた方がいい。
はじめに
みなさんは生成AI系のプロダクトを作るときには何を使用していますか?
私はLangChainを使っています。
かなり機能も豊富で、ドキュメントも充実しています。
そんな生成AI系のプロダクトの機能として最近よく耳にするのがRAGです。
RAGは Retrieval-Augmented Generation の略で、超絶ざっくり説明すると、
質問に対して与えられたドキュメントやDBから関連しそうなものを検索して、その内容から回答を生成する
ようなことを言います。以下はよく見る図ですね。
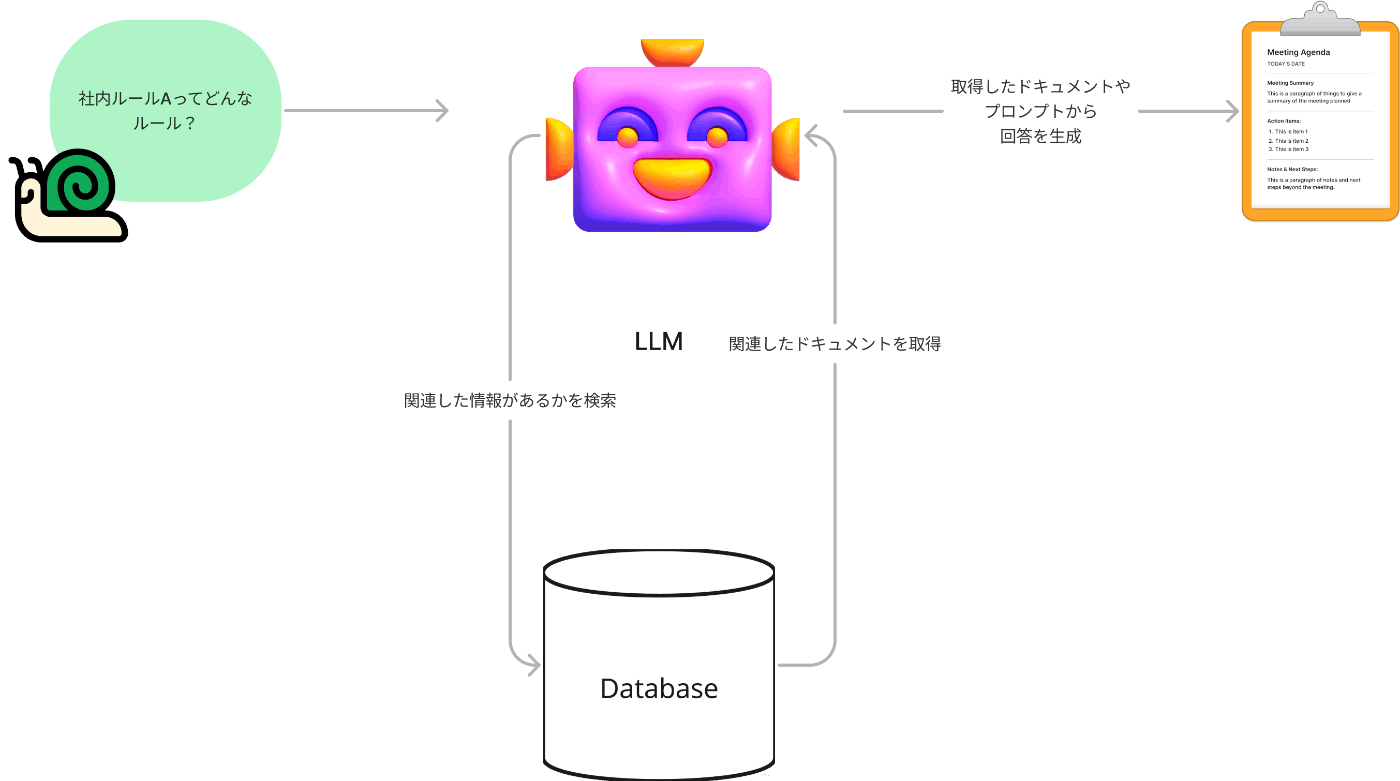
利用シーンとして
- 社内の情報など学習されていない or 学習させたくないドキュメントやデータから回答を作成する。
- 基盤モデルの学習に入っていない最新の情報を取り入れた回答を生成する。
などです。
私は学習データの数が少ない、学習されていないなどが原因で起こるハルシネーションを回避するための手法として使われているようないんしょうを持っています。(そんなに詳しくないので流してください)
ただRAGを使ったからといって上記のようなことを精度よくできるというわけではありません。
今回はこのRAGをさらに改善するSelf-Reflective RAGの手法の一つCRAGの紹介とLangGraphでの実装の紹介をしたいと思います。
※私はアプリの開発は基本Typescriptで行なっているので、今回はLangChainjsで実装しています。
前提
- RAGに関する知識を持ってる
- LangChainを使ったことがある
CRAGとは?
RAGをよりパフォーマンス+堅牢にしたいというをモチベーションに作られたのがCRAG(Corrective Retrieval-Augmented Generation )です。
RAGの精度は検索する文書+プロセスにかなり依存しています。
検索する文書やデータがそもそも品質が悪ければRAGの精度は下がりますし、質問に対して関連度の高い文書が見つからなければハルシネーションを起こしかねないです。
RAGの精度を上げる系の技術ブログを読んだりしていると、やはりしばしば検索のプロセスを改善している記事を見かけます。この辺りで最近一番おもしろかった技術ブログを載せておきます。めちゃくちゃ勉強になるので読んでみてください。
CRAGも同様に検索プロセスを改善することで生成する回答を堅牢で正確なものにしようとしています。
プロセスとしては以下の図をみてください。
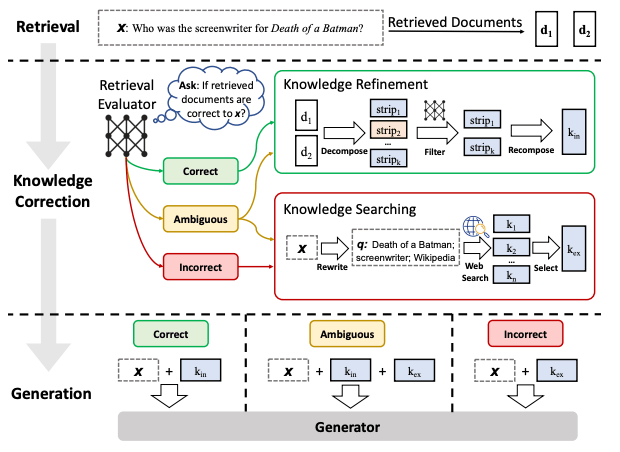
(Referenced by https://arxiv.org/pdf/2401.15884.pdf)
プロセスとしては、
-
持っているドキュメントに検索しに行く
-
検索したドキュメントから取得した内容が、関連しているか、してないかを判定する。
-
知識をより洗練する。
- 取得した内容が関連していない → 文脈を補足するためにウェブベースの文書検索を実行する。そのために質問をWeb検索用に最適化+Webで検索して知識を補強!
- 取得した内容が関連している → 取得してきたドキュメントを分割して、各分割に対して評価して無関係なものは除去!
- 取得した内容が関連してるか微妙 → 知識の洗練とWebでの情報取得の両方を行う。
-
回答を生成する。
- 取得した内容が関連していない → 質問+Webで検索して知識で回答を生成
- 取得した内容が関連している → 質問+洗練した知識で回答を生成
- 取得した内容が関連してるか微妙 → 質問+Webで検索して知識+洗練した知識で回答を生成
簡単にいうと、
RAGに指定した文書に関連する内容があったら、知識を洗練する!なかったらWeb検索しに行けばいいんやん、関連してるかわからんやったらどっちもやろ!
ってことです。
CRAGのパフォーマンスは?
赤枠で囲われている部分だけ今回は追っていきます。
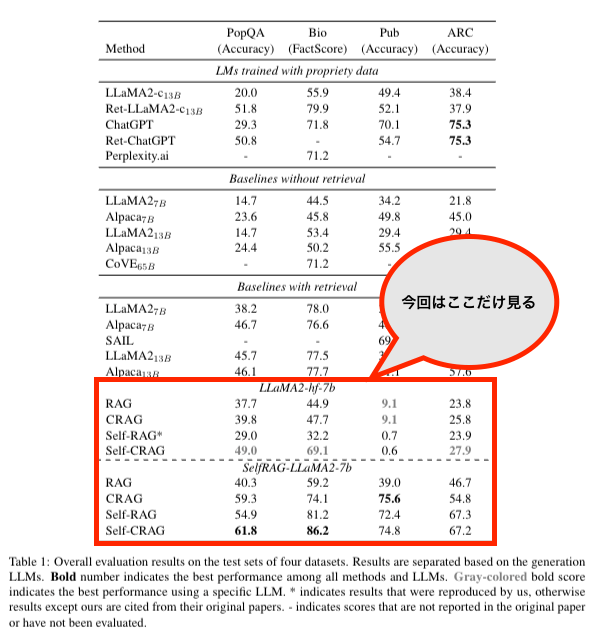
(Referenced by https://arxiv.org/pdf/2401.15884.pdf)
二つの言語モデルの上で評価されていますが、CRAGはRAGに比べると精度が上がっていることがわかりますね。
論文中の表ではデータセットごとにまとめられていますが、もっとざっくりしたテーブルにします。
| LLaMA2-hf-7b | SelfRAG-LLaMA2-7b |
|---|---|
| CRAGはどのデータセットに対してもSelfCRAGに次いで二番目に良さそう | データセットがPubの時はCRAGが一番、それ以外は二番か、三番 |
論文中ではこのテーブルをみて、LLMが変わってもCRAGはCompetitiveなパフォーマンスが出てるから、良さそうと書いてます。
この理由を以下のように書いています。
The reason for these results is
that Self-RAG needs to be instruction-tuned using
human or LLM annotated data to learn to output
special critic tokens as needed, while this ability
is not learned in common LLMs. CRAG does not
have any requirements for this ability.
日本語訳:Self-RAGでは、必要に応じて特別な批評トークンを出力する方法を学習するために、人間またはLLMの注釈付きデータを使用してインストラクションチューニングを行う必要があるためです。この能力は一般的なLLMでは自然に身につくものではありません。 -一方、CRAG にはこの能力の要件がないため、さまざまな LLM ジェネレータへの適応性が高まります
正直データだけ見たら「そうかなあ?🧐」となってましたが理由を見ると納得感がある気がします。
CRAGをLangGraphで実装する。
ではそんなCRAGを実装していきましょう.
全体の実装はこちら
使うのはLangChainから出てるモジュールの一つであるLangGraphを使用します。
細かい説明はしませんが、今回書くコードで大体どのように書けばいいかはわかると思います!
もしわからなければ、それは私の配慮が足りないです。すいません。
今回の実装はLangChain(Python版)が出してるCRAGの実装例をもとに実装しました。
いきなりですが、LangGraphでの実装を考えるにあたってまず考えるべきは、どのようなグラフを構築するかです。
CRAGは以下のようなグラフ構造を構築します。論文とは若干フローが違いますが、LangChainが出しているブログがこれで実装しているので今回はこのグラフフローで実装します。
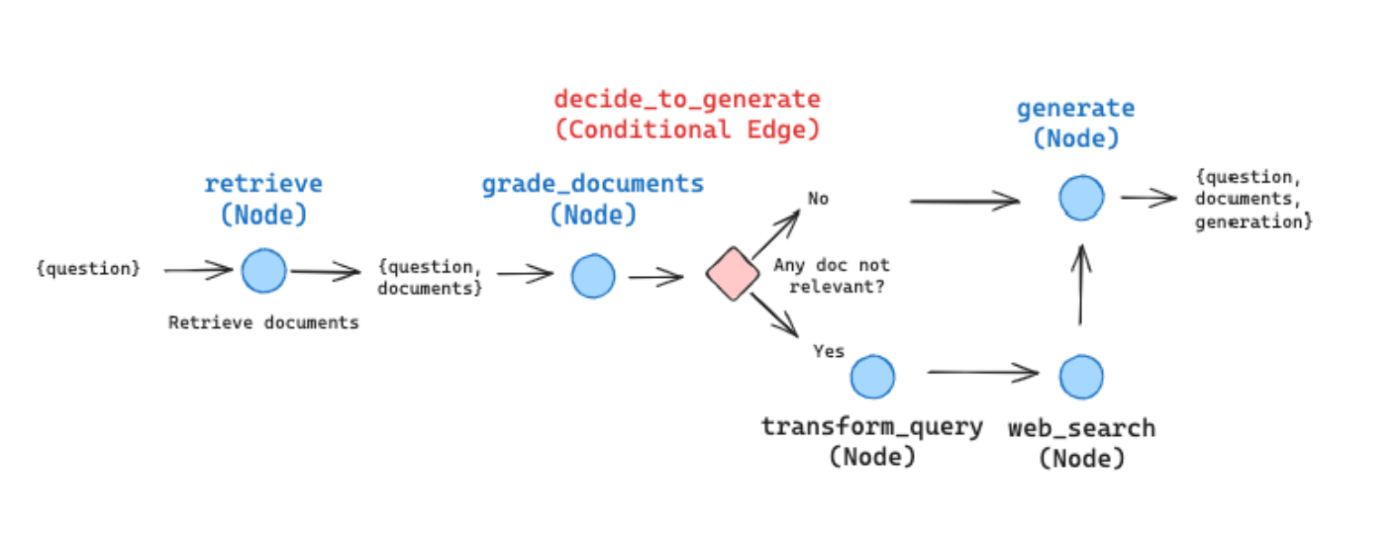
(Referenced by https://blog.langchain.dev/agentic-rag-with-langgraph/)
ブログにも書かれているのですが、今回は論文の内容から以下の実装は抜いています。
We will skip the knowledge refinement phase as a first pass. It represents an interesting and valuable form of post-processing, but is not essential for understanding how to lay out this workflow in LangGraph.
- 知識洗練のフェーズ
- 関連があいまいな状態のフロー (これは明示して書かれていないがグラフフローからは抜かれてる。)
ただどんな今回の実装からの拡張は難しくないので興味ある方はやってみてください。
どんなノードを作るか
ノード1(retrieve). 持っているドキュメントに検索しに行く
ノード2(grade_documents). 検索したドキュメントから取得した内容が、関連しているか、してないかを判定する。
ノード3(transform_query). 質問をWeb検索用に最適化
ノード4(web_search). Webで検索してその内容から回答を生成!
ノード5(generate). それを使って回答生成!
グラフの実装の簡単なイメージ
- グラフを定義するためのワークフローを作成
- 以下の5つのノードを追加
retrieve、grade_documents、transform_query、web_search、generate - 各ノード間のエッジを定義する。
- 実行を開始するためのエントリーのノードを決定
- コンパイルして、実行!
// Define a new graph
const workflow = new StateGraph({
channels: agentState,
});
workflow.addNode(
'retrieve',
new RunnableLambda({ func: retrieveDocuments }),
);
workflow.addNode(
'grade_documents',
new RunnableLambda({ func: gradeDocuments }),
);
workflow.addNode(
'transform_query',
new RunnableLambda({ func: transformQuery }),
);
workflow.addNode('web_search', new RunnableLambda({ func: webSearch }));
workflow.addNode('generate', new RunnableLambda({ func: generateAnswer }));
// 条件付きエッジを追加します。この例では、'grade_documents' ノードから 'generate' または 'transform_query' への分岐を行います。判定は `decideToGenerate` によって行われます。
workflow.addConditionalEdges('grade_documents', decideToGenerate, {
generate: 'generate',
transform_query: 'transform_query',
});
// 通常のエッジを追加します。'retrieve' から 'grade_documents' へ進みます。
workflow.addEdge('retrieve', 'grade_documents');
//'transform_query' から 'web_search' へ、そして 'web_search' から 'generate' へと進みます。
workflow.addEdge('transform_query', 'web_search');
workflow.addEdge('web_search', 'generate');
// 最後に、generateで処理は終了します。
workflow.addEdge('generate', END);
// エントリポイントを設定します。
workflow.setEntryPoint('retrieve');
const app = workflow.compile();
const inputs = {
keys: {
question: 'Explain how the different types of agent memory work?',
documents: [],
},
};
console.log('Invoking workflow');
const result = (await app.invoke(inputs)) as { keys: Keys };
これが定義できていれば、あと二つ考えるだけで実装は終了です。それが
- ノード間の値の受け渡しのための型定義
- ノードが実行する関数
ノード間の値の受け渡しのための型定義
常にquestionとdocumentsは持っている状態で、場合によっては、generateしてものを入れれるようにしたり、検索するかどうかのフラグをいれたりします。
基本的にはノードのinputもoutputもKeys型で受け渡しをするようにします。
type Keys = {
question: string;
documents: Document[];
[key: string]: any;
};
const agentState = {
// _ では前回までの状態が入っていますが、使わないので_にしてます。
keys: {
value: (_, keys: Keys) => {
return keys;
},
//デフォルトの値はできるだけ入れるようにしましょう。
default: () => ({ question: '', documents: [] }),
},
};
ノードが実行する関数
ノード1(retrieve). 持っているドキュメントに検索しに行く
Retrieverを事前にセットアップしておきます。
それを元にgetRelevantDocumentsを使うことで質問に関連する部分を検索できます。
// 各ノードで実行する関数を定義します。
const retrieveDocuments = async (state: { keys: Keys }) => {
console.log('retrieve documents');
const { question } = state.keys;
//事前に定義したretrieverから関連するドキュメントを取得する
const retrieverResult = await retriever.getRelevantDocuments(question);
const response = {
keys: {
question: question,
documents: retrieverResult,
},
};
return response;
};
Retrieverのセットアップはこちら
private async setupRetriever() {
console.log('Setting up retriever');
const urls = [
'https://lilianweng.github.io/posts/2023-06-23-agent/',
'https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/',
'https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/',
];
const docsPromises = urls.map((url) =>
new PlaywrightWebBaseLoader(url).load(),
);
const docs = await Promise.all(docsPromises);
const docsList: string[] = ([] as string[]).concat(
...docs.map((docArray) => docArray.map((doc) => doc.pageContent)),
);
// Split documents
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 3000,
chunkOverlap: 300,
});
const docSplits = await splitter.createDocuments(docsList);
const store = await MemoryVectorStore.fromDocuments(
docSplits,
this.embeddings,
);
const retriever = store.asRetriever();
console.log('Retriever setup complete');
return retriever;
}
ノード2(grade_documents). 検索したドキュメントから取得した内容が、関連しているか、してないかを判定する。
PythonでのCRAGの実装では、 Pydanticをつかっていてjs版ではどれが代替するものかわからなかったですが、LangChainjsが自前で持ってるEvaluatorを使って関連しているかどうかを判定しています。
もし、曖昧判定も入れるのであればこのノードを修正することになると思います。
const gradeDocuments = async (state: { keys: Keys }) => {
console.log('grade documents');
const { question, documents } = state.keys;
// 評価基準を設定します。ここでは、'relevant', 'irrelevant', 'ambiguous' の3つのカテゴリを持つ例を示します。
// Criteria Evaluatorをロードします。
const evaluator = await loadEvaluator('criteria', {
criteria: 'relevance',
});
// 文書とクエリを使用して評価を実行します。
//documentはstate.messagesから取得する.0番目以外のメッセージを取得する
const evalResult = (await evaluator.evaluateStrings(
{
input: question, // クエリ
prediction: formatDocumentsAsString(documents), // 評価する文書
},
{ callbacks: [this.tracer] },
)) as {
reasoning: string;
value: 'Y' | 'N';
score: number;
};
console.log('eval', evalResult.value, evalResult.reasoning);
let search = false;
if (evalResult.value === 'N') {
search = true;
}
return {
keys: {
documents: documents,
question: question,
run_web_search: search,
},
};
};
これ書いててめっちゃ思ったのが、私の書き方が悪いのもあるのですがイマイチLangChainの型がうまいこと発揮されなくてすこしつらみがあります。
例えば evaluator.evaluateStringsの戻り値の型が
{
reasoning: string;
value: 'Y' | 'N';
score: number;
};
で返ってきて欲しいのに、ChainValuesで返ってきていて使いにくいです。
今回は無理やりasで型アサーションして定義し直してますがどう書くのが正しいのでしょうか?
ConventinalEdgeに使う分岐用の関数のセットアップはこちら
const decideToGenerate = (state: { keys: Keys }) => {
const { run_web_search } = state.keys;
// If there is no function call, then we finish
if (!run_web_search) {
console.log('decide to generate');
return 'generate';
}
console.log('decide to transform query');
return 'transform_query';
};
ノード3(transform_query). 質問をWeb検索用に最適化
そのままの質問だとWebで検索にヒットしない可能性があるので、LLMでWeb検索用に最適化した質問に変換しましょう。
const transformQuery = async (state: { keys: Keys }) => {
const { question, documents } = state.keys;
const chain = PromptTemplate.fromTemplate(
`You are generating questions that is well optimized for retrieval. \n
Look at the input and try to reason about the underlying sematic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question: `,
).pipe(this.model);
const response = await chain.invoke(
{ question: question },
{ callbacks: [this.tracer] },
);
console.log('transform query:', response);
// questionを最適化したものに置き換える。
return { keys: { documents: documents, question: response.content } };
};
ノード4(web_search). Webで検索してその内容から回答を生成!
最適化した質問を使ってWeb検索。今回はLangGraphのドキュメントにも出てきたTavilySearchを使用します。以下から登録してAPIキーを取得しておいてください。
const webSearch = async (state: { keys: Keys }) => {
console.log('web search');
const { question, documents } = state.keys;
const tools = [
new TavilySearchResults({
maxResults: 1,
apiKey: process.env.TAVILY_API_KEY,
}),
];
this.toolExecutor = new ToolExecutor({
tools,
});
//toolsをFunction Callingに変換し、modelにバインドする
// これをすることで、modelはtoolsを呼び出すことができる
const toolsAsOpenAIFunctions = tools.map((tool) =>
convertToOpenAIFunction(tool),
);
this.model = model.bind({
functions: toolsAsOpenAIFunctions,
});
const response = (await this.toolExecutor.invoke(
{
tool: 'tavily_search_results_json',
toolInput: question,
log: '',
},
{ callbacks: [this.tracer] },
)) as string;
//responseをパースして、Documentに変換する。型がデフォルトでついてないので辛い。
const parsedResponse = JSON.parse(response);
const webResults = parsedResponse
.map((d: any) => d['content'])
.join('\n');
const webResultsDocument = new Document({ pageContent: webResults });
documents.push(webResultsDocument);
return { keys: { documents: documents, question: question } };
};
ノード5(generate). 最後に回答を生成!
よくあるタイプの回答生成のコードです。特に解説はしないです。
// Define the function that calls the model
const generateAnswer = async (state: { keys: Keys }) => {
console.log('generate answer');
const { question, documents } = state.keys;
const prompt = PromptTemplate.fromTemplate(
`
Please answer the following questions according to the instructions on the following information.
{context}
Question: {question}
`,
).pipe(this.model);
const response = await prompt.invoke(
{
context: formatDocumentsAsString(documents),
question: question,
},
{ callbacks: [this.tracer] },
);
console.log('generated answer ', response);
// We return a list, because this will get added to the existing list
return {
keys: {
documents: documents,
question: question,
generation: response.content,
},
};
};
最後に
今回はLangGraphを用いてCRAGの実装を進めていきました。
CRAG自体の実装はとてもよくわかりましたが、ただ正直これで精度がよくなっているかどうかは実装してもイマイチわかりませんでした。
検証も兼ねて精度検証ってどうするの?みたいなところを書いていければなと思っています。
参考文献
-
Corrective Retrieval Augmented Generation
https://arxiv.org/pdf/2401.15884.pdf -
Self-Reflective RAG with LangGraph
https://blog.langchain.dev/agentic-rag-with-langgraph/ -
🦜🕸️LangGraph.js
https://js.langchain.com/docs/langgraph
Discussion