メモ: Style-Bert-VITS2でモデルマージ
以下にとてもわかり易くまとめられているが、
自分なりに違いを理解したいのでドキュメント等を読みつつ整理してみる。なお、実際に試してないので、試してみて違ったら書き換える予定。
なお、WebGUIはserver_editor.pyとapp.pyがあるが、モデルマージができるのはapp.pyのほう。
デフォルトだとローカルホストのみの待受となるが、自分はLAN内のUbuntuサーバで使用しているので、--hostオプションを使用。
python app.py --host 0.0.0.0
通常マージ

- 必要なモデル数: 2(A・B)
- マージに使用するモデル(AとB)の各要素をどの程度の割合でマージ後モデル(C)に反映させるか?を指定する
- 声質
- 声の高さ
- 話し方(抑揚・感情表現)
- 話す速さ・リズム・テンポ
球面線形補間のオプションを有効にすると、より自然なマージになる、らしい。
差分マージ

- 必要なモデル数: 3(A・B・C)
- マージに使用する2モデル(B・C)間の差分(Cと比較して抽出されたBの特徴)を、各要素ごとにマージ対象モデル(A)にどの程度で反映させるか?を指定する
- ただし、割合を1にしたとしても差分で完全に置き換えられてしまうことはなく、モデルAの各要素の特徴はそのまま残る
加重和
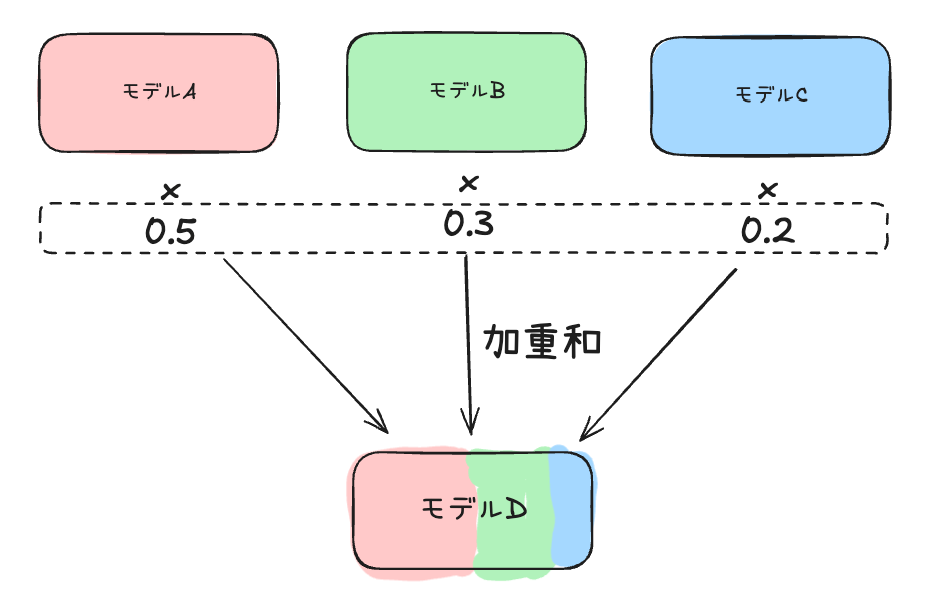
- 必要なモデル: 3(A・B・C)
- 各モデル(A・B・C)の全要素をどの程度の重みでマージ後モデル(D)に反映させるか?を指定する
これだけだと単に通常マージのモデル数は多いが細かく設定できない簡易版のように思えるが、WebGUIの説明にもあるように
a + b + c = 0とすると(たとえば A - B)、話者性を持たないヌルモデルを作ることができ、「ヌルモデルとの和」で結果を使うことが出来ます(差分マージの材料などに)
ということで、「ヌルモデル」を作ったりすることができる。
「ヌルモデル」は、差分マージででてきた「差分」のみを指し、それ単体ではTTSモデルとしては動作しないが、後述する「ヌルモデルマージ」を使うと、モデルに特徴だけを追加することができる、ということの様子。
これは実際に試してみないとわからないけど、多分こういうことではないかと思っている。

なお、
- A, B, C が全て通常モデルで、通常モデルを作りたい場合は、
a + b + c = 1となるようにするのがよいと思います。a + b + c = 0とすると(たとえば A - B)、話者性を持たないヌルモデルを作ることができ、「ヌルモデルとの和」で結果を使うことが出来ます(差分マージの材料などに)- 他にも、
a = 0.5, b = c = 0などでモデルAを謎に小さくしたり大きくしたり負にしたりできるので、実験に使ってください。
等が記載されているので、
- 通常のTTSモデルとして使うなら係数の合計は1
- ヌルモデルとして使うなら係数の合計を0
にするという感じみたい。0 < a+b+ c < 1の場合にはどうなるのだろうか?まあそれも試してみて、というところ。
ヌルモデルマージ
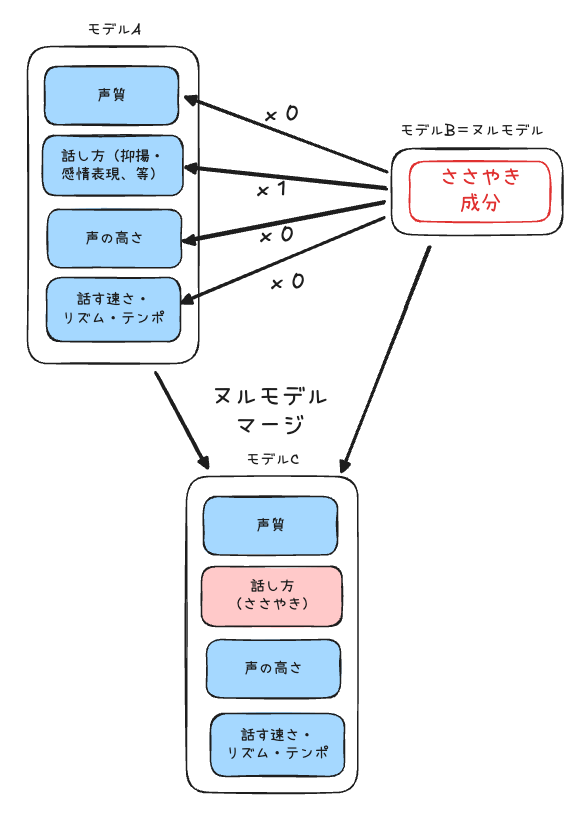
- 必要なモデル: 2(A・B)
- モデルAは通常モデル、モデルBはヌルモデルである必要がある
- モデルB(ヌルモデル)の各要素をそれぞれどの程度の重みでモデルAに反映して、マージ後モデル(C)を作成するか?を指定する
- ただし、重みを1にしたとしても差分で完全に置き換えられてしまうことはなく、モデルAの各要素の特徴はそのまま残る
要素ごとの重みは指定できるけど、ヌルモデルが持つ特徴が各要素の何に最も影響するのか?にもよって変わりそうな気がする。
これも試してみないとわからないな。
あと、例えば「口調を変えたい」ということであれば、モデルが対応しているならば「スタイル」を使うのが最も簡単だし、音声ファイルをリファレンスとして使うこともできる。
モデルマージするのがよいか、スタイルも含めて学習させるのが良いか、音声ファイルでのスタイル適用がよいか、は考えるポイントになりそう。
試したらまた追記する
一通り試してみたけど、大体あってそう。
個人的には、モデルとスタイルの管理をどうするのがよいのか、のプラクティスが知りたい。
- 音声ファイルのリファレンスを使ってスタイルをゼロショットで適用してみたけど、自分が試した限り効果はいまいちだった。
- モデルマージの効果は高いが、スタイルのような使い分けをしようと思うと、管理上の難しさが出てくる。
- 最初からスタイル用の音声を用意して学習させるのが色んな意味で理想的ではある。