Style-Bert-VITS2の使い方メモ
はじめに
今回は、完全に自分用にStyle-Bert-VITS2(SBV2)でのTTSに関して記載します。
インストール方法や使い方などを記載できればと思っています。
(間違っている場所があれば、ご指摘いただけますと幸いです)
自分用ではありますが、新しく学ぶ方の手助けになればと思い、詳細に記載しました。
また、公式のドキュメントとしては下記の記事が提供されています。
非常に参考になるので、私の記事を読むよりは、まずはそちらから読むことをお勧めします。
また、わかることが増えるにつれて更新していこうと思います。
(追記:
2024年6月24日:ユーザ辞書に関して更新
2024年6月26日:pythonのバージョン指定について更新
)
Style-Bert-VITS2とは
Style-Bert-VITS2(SBV2)とはText to Speech(TTS)と呼ばれる、テキストの文字から音声波形を生成するモデルです。
非常に高性能なモデルで、開発者様がデモも用意してくださっているので、ぜひお試しください。
インストール方法
上記のリポジトリをクローンしてください。右上の「code」という緑のボタンからダウンロードしても良いですし、下記コマンドでcloneしても良いです
git clone https://github.com/litagin02/Style-Bert-VITS2.git
環境構築
大前提として、pythonのバージョンは3.10もしくは3.11を想定します。
pythonのバージョン指定
pythonのバージョンはpyenvで指定します。
pyenv自体の導入については下記をご覧ください。
pyenvが導入できていれば、下記のコマンドでpythonのバージョンを指定できます。
pyenv install 3.10.14 #もしくは3.11.9など
pyenv local 3.10.14 #もしくはpyenv global 3.10.14
これでpythonのバージョンが指定できます。
pyenv globalはシステム全体に、このバージョンを反映させたい時に利用してください。
pyenv localは現在のカレントディレクトリでのみ、このバージョンを反映させたい場合に利用します。
下記コマンドを実行して、pythonのバージョンが変更されているかを確認してください。
python -V
# Python 3.10.14
必要なパッケージのインストール
続いて、必要なパッケージをインストールするために仮想環境を構築します
venvで仮想環境を構築します。
venvはpython公式の仮装環境のため、pythonが利用可能であれば導入の必要なく利用できます。
cd Style-Bert-VITS2-master
python -m venv env
source env/bin/activate
pip install -r requirements.txt
python initialize.py
最後のスクリプトを実行することで、各種重み情報を取得できます。
事前準備
使いたいモデルをダウンロードして、下記のように、フォルダに格納してください。
workspace/
├ model_assets/
| └ {model_name}
| ├ xxxx.safetensors
| ├ config.json
| └ style_vectors.npy
└ main.py
{model_name}は音声モデルの名前です。
音声モデルは、例えばBoothなどから取得することができます。。
「Style-Bert-VITS2」などで検索してみてください。
また、defaultのモデルとして「あみたろ」さんのモデルも用意されています。
あみたろさんは、上記のサイトでさまざまな声素材を提供してくださっており、その音声素材を利用して、SBV2の開発者様が学習したモデルが提供されています。
(モデルの重み自体はpython initialize.pyを実施した際に、SBV2のリポジトリのmodel_assetsフォルダにamitaroとして保存されますので、そのままご利用いただけます。)
SBV2の使い方
WebUIでの使い方
WebUIで利用する場合は、下記のスクリプトを実行してください。
python app.py
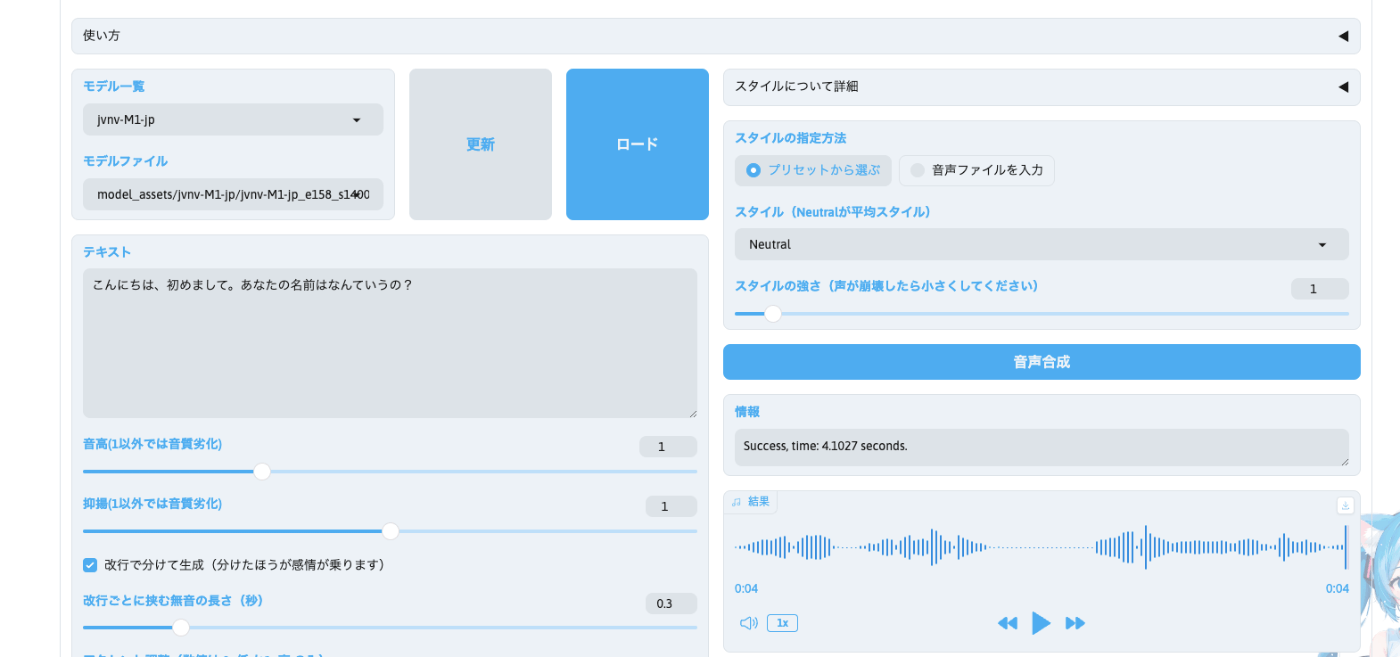
するとブラウザ上で、上記のような画面が表示されます(少し下にスクロールしたら表示されます)。
下記の手順で処理を実施してください。
- 「モデル一覧」からモデルを選択してください。
-
model_assetsに保存されているモデルから選択できます。 - 「モデルファイル」が複数ある場合は、そちらも選択できます
- モデルがない場合は、右の「更新」ボタンを押してみてください。
-
- 「テキスト」を入力してください。
- ここに入力されたテキストを合成音声で読み上げます。
- 後述する「改行で分けて生成」を有効にすることをオススメするため、一文ごとに改行して入力することをオススメします。
- パラメータを設定してください
- 「音高」を変更すると声のピッチを変更できます。基本は1を推奨します。
- 「抑揚」を変更すると声の抑揚を変更できます。基本は1を推奨します。
- 「改行で分けて生成」のチェックボックスはONにすることをオススメします。
- SBV2では、「テキスト」を言語モデルであるBertに入力して、得られた特徴量をVITS2モデルに入力します。この特徴量は一度にモデルに入力される文章全体の特徴をベクトルとして表現し、その特徴量に応じてSBV2は感情込めてテキストを発話します。したがって、一文単位で区切って生成することで、一文ごとに適した感情で読み上げてくれるようになります。
- 「改行ごとに挟む無音の長さ」を設定してください。
- 基本的にdefaultのままで問題ありません。生成された音声を聞いて、空白時間が気になる場合は変更してみてください。
- 「アクセント」を設定してください。(任意)
- 改行で分けない場合にのみ使えますが、発話の読みと音の高低(高い:1、低い:0)を指定できます。
- 利用する場合は、「改行で分けて生成」のチェックボックスはOFFにして、「アクセント調整を使う」のチェックボックスをONにしてください。
- 「Language」を設定してください。
- 基本的にはdefaultのままで問題ありません。
- 英語や中国語を発話させたい場合は、設定してください
- ただし
JP-Extraモデルを利用している場合は、日本語以外選択できません。
- ただし
- 「話者」を設定してください。
- 基本的にはdefaultのままで問題ありません。
- 複数話者で学習させたモデルを利用する場合は、ここから話者を選択できます。
- 「詳細設定」を設定してください(任意)
- 基本的にはdefaultで問題ありません。
- 「Length」を変更すると全体的な発話の速さを変更できます
- 例えば
0.9に設定すると、全体的な発話時間が0.9倍になります。
- 例えば
- 「Assist text」を設定してください(任意)
- 基本的には不要です。
- 「Assist text」を設定すると、入力された文字に対応するBert特徴量が抽出され、元の文章のBert特徴量と混ざります。
- 混ざる強さは「Assist textの強さ」で設定され、値が
1だと、Assist textのBert特徴量のみが残り、0.5だと半々で混ざり合います。 - (参照)
/style_bert_vits2/nlp/japanese/bert_feature.py
- 「スタイル」を指定してください(任意)
- 基本的にはDefaultで設定されている下記の設定で問題ありません。
- 「スタイルの指定方法」→「プリセットから選ぶ」
- モデルフォルダの中の
style_vectors.npyを参照して、必要なstyle vectorを抽出して、利用します。 - 学習時にstyle分けを実施して学習したモデルの場合、スタイルを選択することで、そのスタイルに合わせた話し方で発話してくれるようになります。
- モデルフォルダの中の
- 「スタイル」→
Neutral - 「スタイルの強さ」→
1- 1以上に設定すると、発話音声が崩壊する可能性があります。最適な値はモデルにより異なるため、いろいろ試してみてください。
- 「スタイルの指定方法」→「プリセットから選ぶ」
- 「スタイルの指定方法」で「音声ファイルを入力」を選択した場合、アップロードした音声ファイルからstyle vectorを抽出して、利用します。
- 基本的にはDefaultで設定されている下記の設定で問題ありません。
- 「音声合成」をクリックしてください。
- CPUの場合は少し待ちますが、そのうち発話内容が生成されます。
- 生成された発話内容は、結果ブロックの右上のアイコンからダウンロードが可能です。
JP-Extraに関しては、SBV2の開発者様が詳しく解説している記事がございますため、そちらも併せてご覧ください。
既存のモデルでTTS(モジュールの利用)
下記で必要なモジュールをインストールします。
pip install numpy==1.26.4
pip install style-bert-vits2
pip install sounddevice
pip install fastapi\[all\]
(再掲)
モデルの重みを./model_assetsに格納してください。
下記を参考にしてください。
workspace/
├ model_assets/
| └ {model_name}
| ├ xxxx.safetensors
| ├ config.json
| └ style_vectors.npy
└ main.py
下記のコードを実行すると「こんにちは」と発話させることができます。
(https://github.com/litagin02/Style-Bert-VITS2/blob/master/library.ipynb
上記の公式実装を参考にしています。)
from style_bert_vits2.nlp import bert_models
from style_bert_vits2.constants import Languages
from pathlib import Path
from style_bert_vits2.tts_model import TTSModel
import sounddevice as sd
bert_models.load_model(Languages.JP, "ku-nlp/deberta-v2-large-japanese-char-wwm")
bert_models.load_tokenizer(Languages.JP, "ku-nlp/deberta-v2-large-japanese-char-wwm")
#モデルの重みが格納されているpath
model_file = "jvnv-F1-jp/jvnv-F1-jp_e160_s14000.safetensors"
config_file = "jvnv-F1-jp/config.json"
style_file = "jvnv-F1-jp/style_vectors.npy"
assets_root = Path("model_assets")
#モデルインスタンスの作成
model = TTSModel(
model_path=assets_root / model_file,
config_path=assets_root / config_file,
style_vec_path=assets_root / style_file,
device="cpu",
)
#「こんにちは」と発話
sr, audio = model.infer(text="こんにちは")
#再生
sd.play(audio, sr)
sd.wait()
上記コードの「こんにちは」の部分を変更することで、話す内容を変更することができます。
また、新しい話者のモデル重みを保存して、下記の部分のPathを変更することで、他の声で発話させることができます。
model_file = "jvnv-F1-jp/jvnv-F1-jp_e160_s14000.safetensors"
config_file = "jvnv-F1-jp/config.json"
style_file = "jvnv-F1-jp/style_vectors.npy"
また、defaultのモデルとして「あみたろ」さんのモデルも用意されています。
あみたろさんは、上記のサイトでさまざまな声素材を提供してくださっており、その音声素材を利用して、SBV2の開発者様が学習したモデルが提供されています。
(モデルの重み自体はpython initialize.pyを実施した際に、SBV2のリポジトリのmodel_assetsフォルダにamitaroとして保存されますので、そちらを自分のmodel_assetsフォルダにコピーして、利用してください。)
「あみたろ」さんの学習済みモデル利用の場合は下記のようにPATHを設定してください。
model_file = "amitaro/amitaro.safetensors"
config_file = "amitaro/config.json"
style_file = "amitaro/style_vectors.npy"
既存のモデルでTTS(スタイルの変更)
「あみたろ」さんのモデルなど、既存のdefaultモデルには、スタイルと呼ばれる「感情表現」を設定することができることが多いです。
例えば「あみたろ」さんのモデルではNeutralと01~04までのスタイルが存在します。
このスタイルを変更することで、発話される音声の声色(特に含まれる感情)が変わります。
何もスタイルを指定しない場合は、デフォルトとしてNeutralが指定されます。
スタイルを指定する場合は、下記の通りに実行します
sr, audio = model.infer(text="こんにちは",style = "01")
そのほかのinferメソッドの引数
TTSmodelクラスのinferメソッドの通常の使い方は下記です。
sr, audio = model.infer(text="こんにちは")
一方、inferメソッドにはその他のさまざまな便利な引数が存在します。
下記にTTSmodelクラスのinferメソッドのコードに記載されている引数の説明文を引用させていただきます。
(長いので格納させていただきます。)
inferメソッドの引数説明の引用
Args:
text (str): 読み上げるテキスト
language (Languages, optional): 言語. Defaults to Languages.JP.
speaker_id (int, optional): 話者 ID. Defaults to 0.
reference_audio_path (Optional[str], optional): 音声スタイルの参照元の音声ファイルのパス. Defaults to None.
sdp_ratio (float, optional): DP と SDP の混合比。0 で DP のみ、1で SDP のみを使用 (値を大きくするとテンポに緩急がつく). Defaults to DEFAULT_SDP_RATIO.
noise (float, optional): DP に与えられるノイズ. Defaults to DEFAULT_NOISE.
noise_w (float, optional): SDP に与えられるノイズ. Defaults to DEFAULT_NOISEW.
length (float, optional): 生成音声の長さ(話速)のパラメータ。大きいほど生成音声が長くゆっくり、小さいほど短く早くなる。 Defaults to DEFAULT_LENGTH.
line_split (bool, optional): テキストを改行ごとに分割して生成するかどうか (True の場合 given_phone/given_tone は無視される). Defaults to DEFAULT_LINE_SPLIT.
split_interval (float, optional): 改行ごとに分割する場合の無音 (秒). Defaults to DEFAULT_SPLIT_INTERVAL.
assist_text (Optional[str], optional): 感情表現の参照元の補助テキスト. Defaults to None.
assist_text_weight (float, optional): 感情表現の補助テキストを適用する強さ. Defaults to DEFAULT_ASSIST_TEXT_WEIGHT.
use_assist_text (bool, optional): 音声合成時に感情表現の補助テキストを使用するかどうか. Defaults to False.
style (str, optional): 音声スタイル (Neutral, Happy など). Defaults to DEFAULT_STYLE.
style_weight (float, optional): 音声スタイルを適用する強さ. Defaults to DEFAULT_STYLE_WEIGHT.
given_phone (Optional[list[int]], optional): 読み上げテキストの読みを表す音素列。指定する場合は given_tone も別途指定が必要. Defaults to None.
given_tone (Optional[list[int]], optional): アクセントのトーンのリスト. Defaults to None.
pitch_scale (float, optional): ピッチの高さ (1.0 から変更すると若干音質が低下する). Defaults to 1.0.
intonation_scale (float, optional): 抑揚の平均からの変化幅 (1.0 から変更すると若干音質が低下する). Defaults to 1.0.
Returns:
tuple[int, NDArray[Any]]: サンプリングレートと音声データ (16bit PCM)
上記に整理した引数はよく使うため、一度確認してみると良いと思います。
スタイルを変更するだけでなく、複数話者の音声が学習されているモデルであれば、話者を切り替えることができます。
また、発話音声の速度やピッチ、抑揚の調整、音素の読みやアクセントトーンまで別途与えることも可能です。
辞書登録
辞書登録を行うことで、特殊な読み方や特殊なアクセントなどを設定することができます。
下記のようにフォルダを作り、ファイルを格納してください。
dict_dataフォルダは、元のSBV2リポジトリに存在するため、それをそのままコピーしてくることをお勧めします。
workspace/
├ model_assets/
| └ {model_name}
| ├ xxxx.safetensors
| ├ config.json
| └ style_vectors.npy
├ dict_data/
| ├ user.dic
| └ default.csv
└ main.py
その後、コードを下記のように変更してください。
(長いので格納します)
python:main.py
from style_bert_vits2.nlp import bert_models
from style_bert_vits2.constants import Languages
from pathlib import Path
from style_bert_vits2.tts_model import TTSModel
import sounddevice as sd
from style_bert_vits2.nlp.japanese.user_dict import update_dict
update_dict(default_dict_path = Path("dict_data/default.csv"), compiled_dict_path = Path("dict_data/user.dic"))
bert_models.load_model(Languages.JP, "ku-nlp/deberta-v2-large-japanese-char-wwm")
bert_models.load_tokenizer(Languages.JP, "ku-nlp/deberta-v2-large-japanese-char-wwm")
#モデルの重みが格納されているpath
model_file = "jvnv-F1-jp/jvnv-F1-jp_e160_s14000.safetensors"
config_file = "jvnv-F1-jp/config.json"
style_file = "jvnv-F1-jp/style_vectors.npy"
assets_root = Path("model_assets")
#モデルインスタンスの作成
model = TTSModel(
model_path=assets_root / model_file,
config_path=assets_root / config_file,
style_vec_path=assets_root / style_file,
device="cpu",
)
#「こんにちは」と発話
sr, audio = model.infer(text="こんにちは")
#再生
sd.play(audio, sr)
sd.wait()
前回、提示したコードからの変更点は下記の部分
from style_bert_vits2.nlp.japanese.user_dict import update_dict
update_dict(default_dict_path = Path("dict_data/default.csv"), compiled_dict_path = Path(dict_data/user.dic))
このコードを実行することでdefault.csvに格納された辞書を読み込んで、TTSさせることが可能になります。
また辞書は下記のように設定します
xumas,,,8609,名詞,固有名詞,一般,*,*,*,xumas,クリスマス,クリスマス,3/5,*
www,,,8609,名詞,固有名詞,一般,*,*,*,www,クサ,クサ,2/2,*
上記では造語であるxumasを「クリスマス」と発話させたり、wwwを「草」と発話させるような辞書です。
どちらも、辞書を設定せずに、この単語を読ませようとすると、アルファベットをそのまま一文字ずつ読むような挙動をします。
それぞれ設定方法を説明します。(私もあまりよくわかっていないので、分かる範囲で説明します)
- まずは、設定する単語を左から1マス目に入力します
- 上記で言うと
xumasやwwwに相当します。 - ここでは全角文字で入力してください。(半角文字だと機能しませんでした)
- 上記で言うと
- 続いて「コスト」を左から4つ目に入れます。
- コストの概念を理解するのは難しいので、基本的には、似た種類の単語のコストを同じものを入れると良いです。
- 例えば、固有名詞であれば
8609など - 厳密には、品詞の種類などによってこの数値の最適値は変わります。
- 例えば、固有名詞であれば
- 詳細には、下記のコードにより制御されます。
style_bert_vits2/nlp/japanese/user_dict/part_of_speech_data.py- ここの
cost_candidatesとして指定されている数値のうち、小さい数値を辞書に入れるほど、SBV2が発話する際の辞書通りに発話する優先度が上がります。 - 例えば固有名詞の
8609は配列の5番目の要素のため、優先度は10段階中の5になる。 - 一方で
−988を設定すると優先度は10になり、必ず辞書通りに発話されます。- 必ずこの単語を辞書通りに話させたいなら、優先度を10に設定しても良いと思いますが、文脈によって変わる場合は優先度5くらいに設定しておき、試行錯誤しながら優先度を調整していくと良いと思います。
- コストの概念を理解するのは難しいので、基本的には、似た種類の単語のコストを同じものを入れると良いです。
- 左から5,6,7,8番目には、単語の品詞の種類を入力します
- こちらも下記のコードを参考に設定するか、辞書の他の例を参考に記載すると良いです
style_bert_vits2/nlp/japanese/user_dict/part_of_speech_data.py
- こちらも下記のコードを参考に設定するか、辞書の他の例を参考に記載すると良いです
- 左から9,10番目には
*を入れてください。よくわかっていないです。- 下記の2つらしいです。よくわかっていないです。
- inflectional_type
- inflectional_form
- 下記の2つらしいです。よくわかっていないです。
- 左から11番目には、1番目と同じ単語を入れてください。
- 左から12,13番目には、1番目の単語の読み方をカタカナで入力してください。
- 左から14番目には、アクセントの場所を入力します。
- {アクセントの場所}/{音素数}になります。
- 例えば「クリスマス」の場合は「ス」にアクセントがきます。したがって、5音素中3番目にアクセントが来るため
3/5と記載します
- 左から15番目には
*と入れてください。- 「アクセント結合規則」を表すらしいですが、
*で問題なく動作します。
- 「アクセント結合規則」を表すらしいですが、
以上に従って、辞書を作成することで、読み方やアクセントを操作することができます。
モデルの学習
モデルの学習に関しても、SBV2の開発者様が非常に使いやすいツールを提供してくださっています。
公式としては、下記で学習の方法を解説してくださっておりますため、基本的にはそれで十分かと思います
また、Google Colabでの学習用サンプルも用意していただいております。
無料版では学習は難しいため、Colab Proなどの利用を検討してください。
上記はver2.5での動作コードです。都度、最新バージョンのファイルを利用してください。
複数話者での学習
ここでは2話者での学習を考えます。
下記に再度、学習用のドキュメントを提示します。
2話者で学習させるために上記のドキュメントから少しだけ変更を行います。
2.Preprocessを実施前にDataフォルダの中身は下記のようになっていると思います
/
├ Data/
| └ {model_name}
| ├ raw/
| | ├ 001.wav
| | ├ 002.wav
| | ...
| | └ xxx.wav
| |
| └ esd.list
|
├ model_assets
...
└ xxx
2話者で学習するためにはrawフォルダの中に2話者分の音声ファイルを同時に入れることとesd.listの中にも2話者分の情報を入れる必要があります。
例えば下記のような形です。
001-A.wav|speaker-A|JP|おはようございます。
002-A.wav|speaker-A|JP|こんにちは。
003-A.wav|speaker-A|JP|いただきます。
・・・
098-B.wav|speaker-B|JP|ごちそうさまでした。
099-B.wav|speaker-B|JP|さようなら。
100-B.wav|speaker-B|JP|おやすみなさい。
上記のような形を準備した後に「2.Preprocess」から実行することで、2話者モデルを学習することができる。
ちなみに(おそらくですが)「esd.list」において、上に置いた話者のidが0になると思われます。
上記の例では、「speaker-A」の話者idが0、「speaker-B」の話者idが1となります。
複数スタイルでの学習
通常の学習では、基本であるNeutralのスタイルしか学習されないですが、下記を実施することで、Neutralに加え、別のstyleを学習させることができます。
2.Preprocessを実施前にDataフォルダの中身を下記のように設定します。
/
├ Data/
| └ {model_name}
| ├ raw/
| | ├ style01/
| | | ├ 001.wav
| | | ├ 002.wav
| | | ...
| | | └ xxx.wav
| | └ style02/
| | ├ 001.wav
| | ├ 002.wav
| | ...
| | └ xxx.wav
| └ esd.list
|
├ model_assets
...
└ xxx
このようにrawフォルダの中身をstyleごとにサブディレクトリを用意して、その中に該当の音声ファイルを格納することによって、Neutralに加えてstyle01とstyle02のスタイルも作成できます。
また、rawフォルダの中身が変更されたため、esd.listも変更になります。
下記の通り、ファイル名がサブディレクトリも含む形に変更になります。
style01/001.wav|speaker-A|JP|おはようございます。
style01/002.wav|speaker-A|JP|こんにちは。
・・・
style01/100.wav|speaker-A|JP|いただきます。
style02/001.wav|speaker-A|JP|ごちそうさまでした。
style02/002.wav|speaker-A|JP|さようなら。
・・・
style02/100.wav|speaker-A|JP|おやすみなさい。
モデルマージ
SBV2では非常に簡単にモデル同士のマージを行うことができます。
モデルマージを行うことで、いろんな機能をマージ元モデルに付与することができます。
例えば、マージ元モデルに、抑揚の強いモデルをマージすることで抑揚を付与したり、
日本語で学習したモデル(日本語特化モデルではなく)に対して、英語で学習したモデルをマージすることで、英語の発話を流暢にすることができたりします。
マージに関して、開発者様が中身の解説をしてくださっておりますため、下記の記事も併せてご覧ください。
(ver2.6.0では)モデルマージは下記の種類がございます。
(モデルAとモデルB、モデルCなどのマージを考えます。)
- 通常モデルマージ
new_model = (1 - weight) * A + weight * B
- 差分モデルマージ
new_model = A + weight * (B - C)
- 加重和
-
new_model = a * A + b * B + c * C- ただし、
a,b,cは実数で、0を指定すると全くマージに反映されません。
- ただし、
-
- ヌルモデルマージ
-
new_model = A + weight * B-
Bは通常「ヌルモデル」が前提となります。- 「ヌルモデル」でなくても良いがうまくいかない可能性がある
- 「ヌルモデル」とは、上の「加重和」によるマージにおいて、下記を満たすものです。
a + b + c = 0
-
-
下記で解説します。
通常モデルマージ
モデルマージに関してはWebUIを利用します。下記のスクリプトを実行してください。
元のSBV2のリポジトリをカレントディレクトリとして実行してください。
python app.py
すると下記のブラウザが開き、下記の画像のような画面が表示されるかと思います。

こちらの上部にある「マージ」のタブを選択してください。
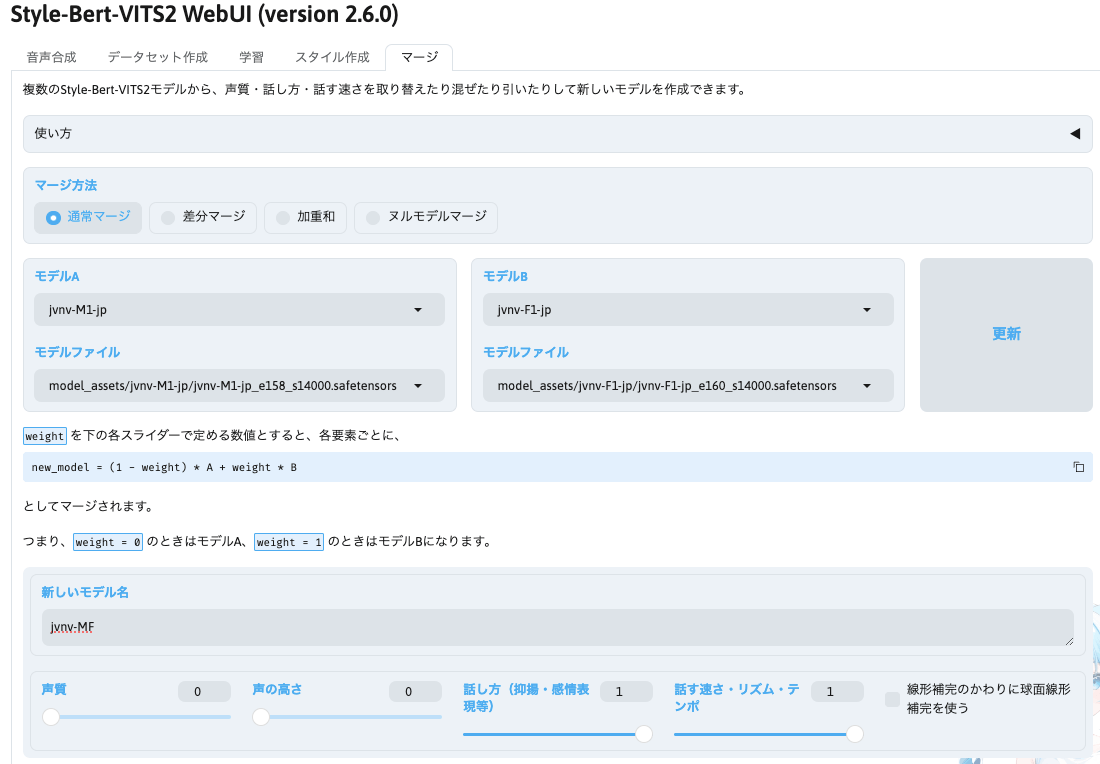
(画面はver.2.6.0の画面になりますが、「通常マージ」に関しては使い方は同じになります。それ以外のマージに関してはver2.6以前のversionのSBV2では利用できません)
下記の通り作業を行います。
- 「マージ方法」を選択します
- ここでは「通常マージ」を選択します
- 「モデルA」と「モデルB」を設定します
- それぞれ
assets_modelsに格納されているモデルを選択できます。 - モデルがない場合は、右の「更新」ボタンを押してみてください。
- それぞれ
- 「新しいモデル名」を入力してください。
- なんでも良いです。何と何をマージしてできたのかがわかる名前になっているとわかりやすいです。
- パラメータを設定してください。
- それぞれの項目で0から1の範囲で重みを指定できます。
- 0に設定するとモデルAの重みと全く同じ
- 1に設定するとモデルBの重みを全く同じ
- 0.5に設定するとモデルAとモデルBの重みの平均になります。
- 下記のパラメータを設定できます。
- 声質
- 声の高さ
- 話し方(抑揚・感情表現等)
- 話す速さ・リズム・テンポ
- 画像の例では、声質や声の高さはモデルAのまま、モデルBの話し方や話す速さに変更するようなマージ設定をしています。
- それぞれの項目で0から1の範囲で重みを指定できます。
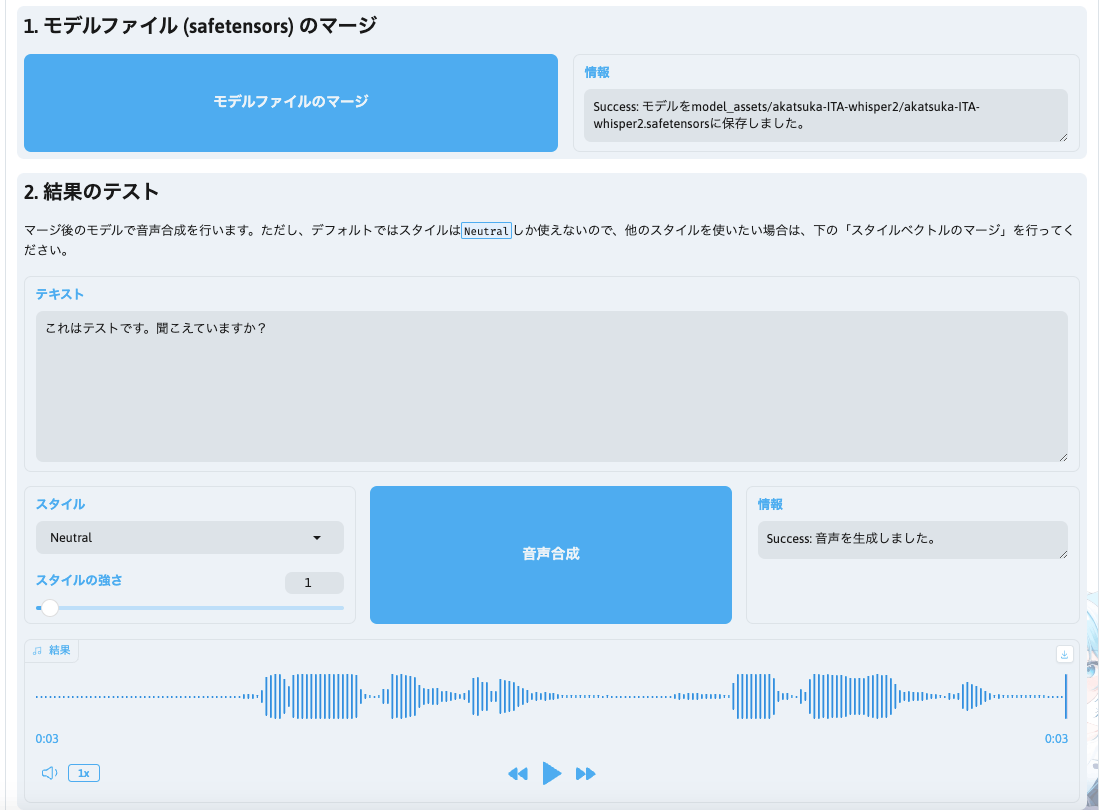
- 「モデルファイルのマージ」のボタンをクリックしてください。
- 右の情報欄にて保存場所が記載されます
- 「結果のテスト」を実施できます(任意)
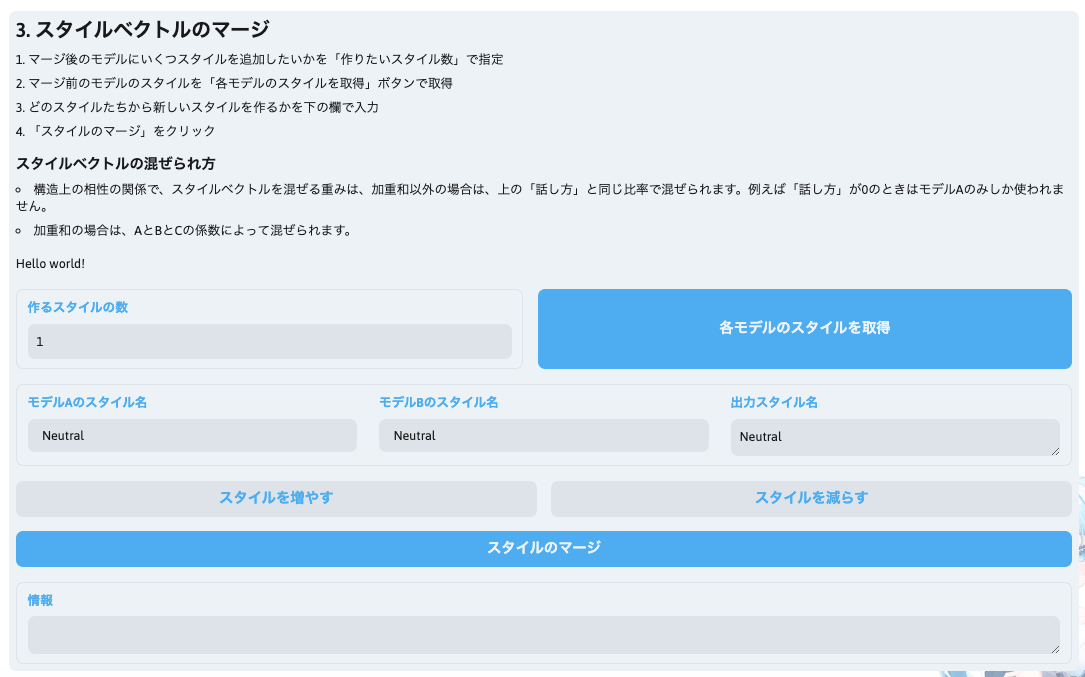
- 「スタイルベクトルのマージ」ができます(任意)
- マージ元モデルに複数のスタイルがある場合は、スタイル同士のマージも可能です。
- 下記の形で実行してください。(WebUIから引用)
- マージ後のモデルにいくつスタイルを追加したいかを「作りたいスタイル数」で指定
- マージ前のモデルのスタイルを「各モデルのスタイルを取得」ボタンで取得
- どのスタイルたちから新しいスタイルを作るかを下の欄で入力
- 「スタイルのマージ」をクリック
以上で通常マージは完了です。
マージしたモデルに関してはmodel_assetsフォルダに、自分で設定したモデル名のフォルダとして保存されています。
そのフォルダの中には、必要な3つのファイルに加え、マージ情報が記載されているrecipe.jsonが保存されています。
(基本的には使わないですが、今後モデルを再現したい場合に参照できます)
差分モデルマージ(ver.2.6.0以降)
続いて、ver2.6.0以降にて実装された差分モデルマージについて解説します。
基本的な使い方は「通常マージ」と同様です。
差分としては、
- 「マージ方法」にて「差分マージ」を選択する
- モデルはA,B,Cの3つを設定する必要があり、それぞれのモデルは下記の式でマージされる
new_model = A + weight * (B - C)
- 上記の式からもわかるように、重みを1にしてもAの要素はそのまま保たれます。
- 要素ごとのパラメータは全て1を設定してください。
- 私の少ない試行回数では、全て1にするのが一番ささやきが反映されました。
差分マージで実施していることを直感的に解説します。
下記のようなモデルがあることを仮定します
モデルA:Aさんの通常コーパス読み上げ音声で学習されたモデル
モデルB:Bさんの「ささやき」コーパス読み上げ音声で学習されたモデル(ささやきモデル)
モデルC:Bさんの通常コーパス読み上げ音声で学習されたモデル
ここで「タスクベクトル」と言う考え方を導入します。
タスクベクトルは、タスクの学習を表すベクトルです。タスクの学習や忘却 (unlearning) をタスクベクトルの算術により実現できます。
例えば、LLMの分野では「Chat Vector」と言う技術で使われています。 (chat Vectorの解説は上記の記事がわかりやすいです。)
ここでやっていることは、
「英語で学習されたchat機能つきLLM」ー「英語で学習されたベースLLM」
の指揮に基づいてLLMの重みパラメータを計算すると、「chat機能」と言うタスクを成立させるための重みベクトルが得られるため、それを「chat機能ベクトル」とすると
「日本語で学習されたベースLLM」+「chat機能ベクトル」をLLMの重みパラメータにて計算することで、「日本語で学習されたベースLLM」にchat機能を付与することができると言う技術になります。
SBV2においても、同様の計算が可能です。
モデルBからモデルCを引き算したモデルは、「ささやき」タスクのタスクベクトルになります。
従って、それをモデルAに足し算することで、Aさんの「ささやき」モデルが得られることになります。
これにより、理論上、どんなモデルに対しても、自分の好きなタスクをさせることができるようになります。
加重和(ver.2.6.0以降)
これも「通常マージ」とほぼ同じです。
差分としては、
- 「マージ方法」にて「加重和」を選択する
- モデルはA,B,Cの3つまで設定することができ、それぞれのモデルは下記の式でマージされる
new_model = a * A + b * B + c * C- TIPSとしてWEB UIから引用します。
-
A, B, Cが全て通常モデルで、通常モデルを作りたい場合は、a + b + c = 1となるようにするのがよいと思います。 -
a + b + c = 0とすると(たとえばA - B)、話者性を持たないヌルモデルを作ることができ、「ヌルモデルとの和」で結果を使うことが出来ます(差分マージの材料などに) - 他にも、
a = 0.5, b = c = 0などでモデルAを謎に小さくしたり大きくしたり負にしたりできるので、実験に使ってください。
-
- 係数は要素ごとには設定できません。
ヌルモデルマージ(ver.2.6.0以降)
ここではヌルモデルというものを利用します。
(ヌルモデル以外のモデルのマージにも利用できますが、音声が崩壊する可能性があります)
「ヌルモデル」の定義をWebUIより引用します。
「ヌルモデル」を、いくつかのモデルの加重和であってその係数の和が0であるようなものとします(例えば
C - Dなど)。
従って、「差分モデルマージ」の章で説明した「タスクベクトル」そのものを指します。
「タスクベクトル」を保存しておけば、いろいろなモデルに対して、「ヌルモデルマージ」を簡単に実施することができます。
また、SBV2の開発者様が「ささやき」のヌルモデルを用意してくださっておりますため、そちらをダウンロードして利用することもできます。
こちらで用意してくださっています。
ダウンロードは下記にて実施できます
git lfs install
git clone https://huggingface.co/litagin/sbv2_null_models
もしくは、Hugging Faceのページから1ファイルずつダウンロードすることも可能です。
ダウンロードした後、whisper1_nullとwhisper2_nullのフォルダをmodel_assetsフォルダに格納してください。
個人的には(試行回数が少ないですが)、whisper1_nullのヌルモデルでマージしたほうがよりささやき感があるモデルに仕上がりました。
(私は男性話者のモデルにマージをしたので、whisper2_nullは相性が悪かったのかもしれません)
では「通常マージ」との差分を説明します。
- 「マージ方法」にて「ヌルモデルマージ」を選択する
- モデルAをベースモデル、モデルBをヌルモデルで設定し、下記の式の通りマージする
new_model = A + weight * B
- 上記の式からもわかるように、重みを1にしてもAの要素はそのまま保たれます。
- 要素ごとのパラメータは全て1を設定してください。
- 私の少ない試行回数では、全て1にするのが一番ささやきが反映されました。
まとめ
ここまでで、SBV2についての使い方についてまとめさせていただきました。
Web UIでの使い方とモジュールとしての使い方の両面についてまとめさせていただきました。
間違っていることがございましたら、ご指摘いただけますと嬉しいです。
また、本記事が皆様の手助けになれば幸いです。
Discussion
細かいのですが、WebUIでの使い方の中の「「スタイル」→Nuetral」は「「スタイル」→Neutral」ではないかと思います。
ありがとうございます!修正させていただきました。