ずんだもん読み上げに感情を与える(Bert-VITS2のkey別マージ)

この記事は本家Bert-VITS2のモデルをマージする方法を説明しています。Style-Bert-VITS2を使う場合は付属マージツールから面倒なことをすることなくマージできます。
宣伝
- Style-Bert-VITS2のチュートリアル解説動画を作りました
- discordサーバー「AI声づくり研究会」によく出没しています
概要
Bertを組み合わせることで入力テキストに応じて感情豊かな読み上げ音声の生成が可能な Bert-VITS2 というTTS(Text-to-Speech、読み上げ音声合成)のライブラリがあります。
詳しくは
参照。
Bert-VITS2を使ってずんだもんの通常の声音のみを学習させたずんだもんのモデルと、感情豊かな別のモデルをうまくマージすることで、ずんだもんの声のまま感情豊かに読み上げることが出来るモデルを作ることができたので、その実験と、手っ取り早いマージツールの共有記事です。
宣伝
discordサーバー「AI声づくり研究会」によく出没しています:
簡単にインストールできてスタイル指定もかなり可能なBert-VITS2 v2.1改造を作りました(2023-12-31のアップデートでマージに対応しました、APIサーバーもあるよ)
各verの詳しい技術的な構造や比較など
結果
前半が通常のずんだもん、後半がマージで感情を手に入れたずんだもんです。
前半はよく聞く感じだと思いますが、後半でちゃんと怒りや悲しみの感情が入った演技をしている感じが分かると思います。もとのずんだもんのデータセットには怒りや悲しみの声音や演技等は全く入っていません。
使ったデータセット等
使ったBert-VITS2のバージョンは2.1です。
元となるずんだもんのモデル
- 東北ずん子プロジェクト 研究者向けマルチモーダルデータベース の「ずんだもん ITAコーパス 朗読324」
- 前処理:2秒未満の発話や発話前の無音区間等を除去し、合計280ファイルで合計約18分のデータに。
- 聞けば分かりますが、既存のTTS向けに、一定の感情・声音・テンポですべてを台本通り読み上げた感じであり、感情はおそらく意図的に排除されています。
そもそも18分のデータセットでBert-VITS2を使えば音質もよくかなり質が高いずんだもん読み上げを作ることができること自体がすごいです、が動画の前半のように、よく聞くずんだもんのような、良くも悪くも一定に原稿を読み上げる感じがあると思います。
マージした感情豊富なモデル
- JVNVコーパス: 日本語の感情音声のデータセットです。
- このF2を学習したZuntanさんの10kステップのモデルをお借りしました。
細かいことはいいのでマージしたい
実験により(後で詳述)、モデルの中の重みの中で
- 声音・話者性(その人の声かどうか)
- 感情表現・抑揚
- 話すリズム・テンポ
が入っている重みのkeyがかなり明確にわかったので、それを取っ替えたり指定した割合で混ぜるための簡易的なツールを作りました。
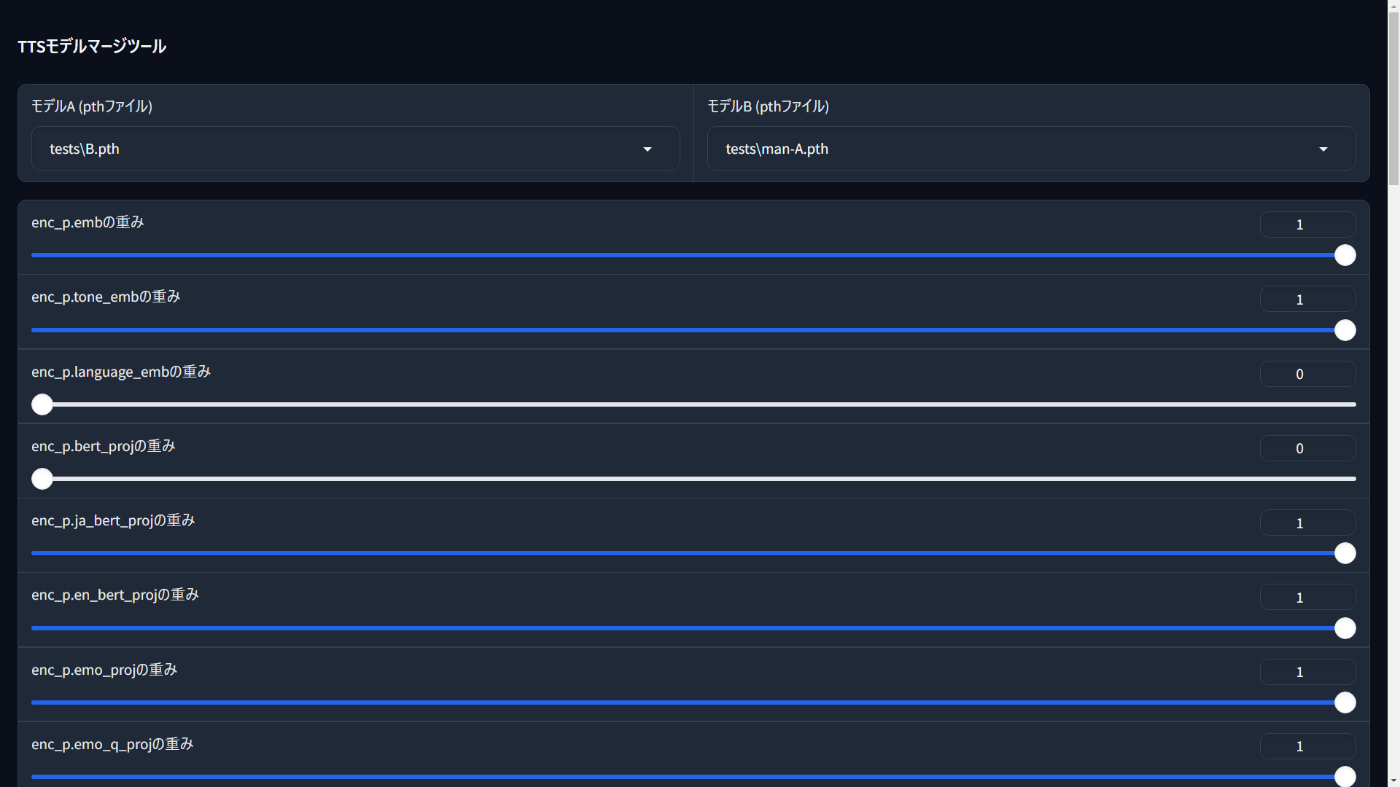
使い方は、これをBert-VITS2が入っているところにsimple_merge.pyという名前で保存して、仮想環境からpython simple_merge.pyでWebUIが立ち上がります。

使い方は、mergeフォルダを作ってそこに2つのモデルを入れて、片方のモデルのconfig.jsonも入れておけば使えます。3つの要素について0-1でマージでき、0でモデルA、1でモデルBになります。
上の感情豊かなずんだもんモデルは、上からモデルAをずんだもん、モデルBをJVNVコーパスモデルにして、0, 1, 1のレシピでマージしたものです。
詳細な実験レポート
やったこと
Bert-VITS2のバージョンによってモデル構造が微妙に違います、実験は2.1で行いました(が2.2モデルでもマージの効果は同じ感じのようです)。
- まず推論に使われるpthファイルにどういう重みが入っているのかkey一覧を出力させる
import torch
model = torch.load("G_1000.pth", map_location="cpu")
for k in model["model"].keys():
print(k)
結果:
enc_p.emb.weight
enc_p.tone_emb.weight
enc_p.language_emb.weight
enc_p.bert_proj.weight
...(以下1000項目以上)
本家のモデル圧縮ツール を使って削ったモデルから取得すればいいですが、それでも大量にあります。
- いくつかコンポーネントごとにまとめる
本当の意味でのkey別層別マージなら第n層とかまで考えるべきですがとてもそこまで余裕がないので、大雑把なコンポーネントごとにまとめます。大体まとめると次の感じ:
keys = [
"enc_p.emb",
"enc_p.tone_emb",
"enc_p.language_emb",
"enc_p.bert_proj",
"enc_p.ja_bert_proj",
"enc_p.en_bert_proj",
"enc_p.emo_proj",
"enc_p.emo_q_proj",
"enc_p.encoder.spk_emb_linear",
"enc_p.encoder.attn_layers",
"enc_p.encoder.norm_layers_1",
"enc_p.encoder.ffn_layers",
"enc_p.encoder.norm_layers_2",
"enc_p.proj",
"dec.conv_pre",
"dec.ups",
"dec.resblocks",
"dec.conv_post",
"dec.cond",
"flow.flows",
"sdp",
"dp",
"emb_g",
]
機械学習に詳しい人はたぶんこのkey名からどういうものかは分かるかもしれませんが、自分は何も知らないので分かりません。
- 上のkeyに対して割合を指定してマージして実験できるやつを作り、2つの全く違うモデル(女性モデルと男性モデル)とを指定し、すべてを女性モデルに降った状態から各keyを男性モデル全振りにしたとき、どこがどう変わるか調査
終わり。
結果
役割が明確ないくつかのkeyは特定できた。
-
enc_p、特にその中のenc_p.encoder、特にその中のenc_p.encoder.ffn_layers: 文章に対する抑揚や語尾の上がり方や全体のイントネーションや感情表現などが入っている -
dec、特にその中のdec.resblocks: 声音、話者性(ただし声の高さは別) -
flow: 声の高さ -
dpsdp: これはduration predictorのはずで、音素の長さを決めるやつのはずなので、話速や喋り方のテンポ等(一定だったり緩急をつけたりとか)
上に上げたシンプルマージツールは、声音はdec(話者性)とflow(声の高さ)、感情表現はenc_p、テンポはdpとsdpについてマージするやつとなります。
噂だとVITSやVITS2ではflowが話者性を制御すると聞いたことがあるんですが、実験した感じだとflowは声の高さのみ、話者性はdecにかなり入っているみたいです。Bertと組み合わせていることも関係あるのかも?詳しい人がいたら教えてください。
応用
この記事のメインテーマのように、
- 「ある話者Aと別の話者Bについて、声音はA、喋り方はB」
というような別のモデルを作ることができるのは面白いことだと思います。
またもちろん声音のマージや喋り方のマージをしていろいろ面白いことも出来ると思います。
さらに、少数の学習データセット(とくに今回の場合みたいに感情表現があまり無いデータセット)のみからも、感情表現が豊かなモデルが作れるのは、個人的にすごいことなんじゃないかと思います。
みなさんもいろいろ実験してみてください。
Discussion