Dia-1.6BをOpenAI互換APIサーバで使える「Dia-TTS-Server」を試す
以前試したDia-1.6B
これをFastAPIでラップしてOpenAI互換APIとして使えるらしい
GitHubレポジトリ
READMEから概要的なところだけ抜粋
Dia TTSサーバー: Web UI付きOpenAI互換API、長文処理 & 音声内蔵
強力なNari Labs製Dia TTSモデルをセルフホストできる、機能強化FastAPIサーバーです!直感的なWeb UI、柔軟なAPIエンドポイント(OpenAI互換の
/v1/audio/speechを含む)、リアルな対話生成([S1]/[S2])、改良されたボイスクローン、大規模テキストを知的に分割処理し、43種類の内蔵ボイスとシード機能による一貫性・再現性の高い音声生成をサポートします。速度向上とVRAM削減を実現しました。デフォルトで効率的なBF16 SafeTensorsを使用し、VRAMを削減し推論を高速化。元の
.pthウェイトにも対応。NVIDIA GPU(CUDA)で高速動作し、CPUフォールバックも可能です。
referred from https://github.com/devnen/Dia-TTS-Server🗣️ 概要: 強化されたDia TTSの活用
元のNari Labs製Dia 1.6B TTSモデルは、話者交替や非言語音(
(laughs)や(sighs)など)を含む現実的な対話音声を生成できる驚異的な能力を備えています。本プロジェクトはその基盤を拡張し、FastAPIベースの堅牢なサーバーを提供することで、Diaをはるかに簡単に利用・統合できるようにします。私たちは次の方法でセットアップと運用の複雑さを解消します:
- OpenAI互換APIエンドポイントを備え、OpenAI形式のAPIを期待するツールでもDia TTSを利用可能。
- モダンなWeb UIを提供。実験、プリセット読み込み、リファレンス音声管理、生成パラメータ調整が容易。インターフェースデザインはLex-au氏 Orpheus-FastAPIプロジェクトに着想を得て、Dia TTS用に直感的なレイアウトとUXを適用。
- 大規模テキスト処理: 長文入力を文構造と話者タグに基づき知的に分割し、逐次処理後に音声をシームレスに結合。
- 定義済みボイス: 一貫した出力を得るため、43種の厳選ボイスを用意。クローン設定不要。
- 改良されたボイスクローン: 自動オーディオ処理とトランスクリプト取り扱い(ローカル
.txtファイルまたは実験的Whisperフォールバック)を組み込んだパイプライン。- 一貫した生成: 「定義済みボイス」または「ボイスクローン」モードを、任意で固定整数 Seed と併用し、複数生成やテキスト分割間で声を一定に保つ。
- 元の
.pthウェイトと、安全かつモダンなSafeTensorsの両方をサポート。デフォルトはBF16 SafeTensors版で、VRAMを約半分に削減し速度を向上。- GPU (CUDA)自動検出とCPUフォールバック。
- 主な設定は
config.yaml、初期セットアップ/リセットには.envを使用。- Docker対応で、容易にコンテナ化デプロイ。
このサーバーは、Diaの高度なTTS機能を安定的かつ大規模テキストにも対応してシームレスに活用するためのゲートウェイです。
✅ 機能
- Diaの基本機能(Nari Labs Dia経由):
* 🗣️[S1]/[S2]タグを用いたマルチスピーカー対話生成。
* 😂(laughs)、(sighs)、(clears throat)など非言語音を含める。
* 🎭 参照オーディオプロンプトによるボイスクローン。- 強化されたサーバー & API:
* ⚡ 高性能FastAPIフレームワークで構築。
* 🤖 OpenAI互換APIエンドポイント(/v1/audio/speech)で容易に統合(seedも対応)。
* ⚙️ カスタムAPIエンドポイント(/tts)はDia生成パラメータをすべて公開(seed、split_text、chunk_size、transcript対応)。
* 📄 Swagger UI(/docs)によるインタラクティブAPIドキュメント。
* 🩺 ヘルスチェックエンドポイント(/health)。- 高度な生成機能:
* 📚 大規模テキスト処理: 文と話者タグに基づき長文をチャンクに分割し、それぞれで音声を生成後にシームレス結合。split_textとchunk_sizeで設定。
* 🎤 定義済みボイス:./voicesディレクトリの43種から選択し、クローン設定不要で一貫出力。
* ✨ 改良されたボイスクローン: 自動オーディオ処理とトランスクリプト処理(ローカル.txtまたはWhisperフォールバック)。バックエンドがトランスクリプト前置きを処理。
* 🌱 一貫した生成: 定義済みボイスまたはクローンモードで、固定整数Seedを使用してチャンク間や複数リクエストで声を統一。
* 🔇 オーディオ後処理: サイレンストリミング、内部ポーズ修正、長い非発声音・アーティファクト除去を自動実行。- 直感的なWeb UI:
* 🖱️ Lex-au氏 Orpheus-FastAPIを参考にしたモダンで使いやすいインターフェース。
* 💡 プリセット:ui/presets.yamlから動的に例文と設定を読み込み。ファイル編集でカスタマイズ可能。
* 🎤 参照オーディオアップロード:.wav/.mp3ファイルを簡単にアップロードしてクローン利用。
* 🗣️ ボイスモード選択: 定義済みボイス、ボイスクローン、ランダム/対話モードを選択。
* 🎛️ パラメータ制御: CFG Scale、Temperature、Speed、Seedなど生成設定をスライダー・入力で調整。
* 💾 設定管理:config.yamlのサーバー設定と生成デフォルトをUIで閲覧・保存。
* 💾 セッション永続: 最後に使用した設定をconfig.yaml経由で保存。
* ✂️ チャンク制御: テキスト分割の有効/無効とチャンクサイズ調整。
* ⚠️ 警告モーダル: チャンク処理時の声の一貫性や生成品質に関する任意警告。
* 🌓 ライト/ダークモード: テーマ切替をローカル保存。
* 🔊 オーディオプレーヤー: 生成音声をWaveSurfer.jsで再生・ダウンロード。
* ⏳ ロードインジケータ: チャンク処理状況を含むステータス表示。- 柔軟 & 効率的なモデル管理:
* ☁️ Hugging Face Hubからモデルを自動ダウンロード。
* 🔒 安全な**.safetensorsウェイト読み込み対応(デフォルト)。
* 💾 元の.pth**ウェイト読み込み対応。
* 🚀 BF16 SafeTensorsをデフォルト採用し、メモリフットプリントを約半減し推論速度を向上(参考: ttj/dia-1.6b-safetensors)。
* 🔄config.yamlでモデル形式/バージョンを簡単切替。- パフォーマンス & 設定:
* 💻 GPU加速: NVIDIA CUDAを自動使用、CPUフォールバック。典型VRAM使用量~7GB。
* 📊 ターミナル進捗: テキストチャンク処理時tqdm進捗バーを表示。
* ⚙️ 主設定はconfig.yaml、初期シードは.env。
* 📦 標準Python仮想環境を使用。- Docker対応:
* 🐳 DockerとDocker Composeによるコンテナ化デプロイ。
* 🔌 NVIDIA GPU Container Toolkit統合でGPU加速。
* 💾 モデル、参照音声、定義済みボイス、出力、設定向け永続ボリューム。
* 🚀 ワンコマンドセットアップ&起動(docker compose up -d)。🔩 システム要件
- OS: Windows 10/11 (64-bit) または Linux(Debian/Ubuntu推奨)。
- Python: 3.10以降(ダウンロード)。
- Git: リポジトリクローン用(ダウンロード)。
- インターネット: 依存関係とモデルのダウンロードに必要。
- (オプション・推奨)性能向上用:
- NVIDIA GPU: CUDA対応(Maxwell世代以降)。NVIDIA CUDA GPUs参照。最適化VRAM~7GBだが多いほど良い。
- NVIDIAドライバ: 最新版(ダウンロード)。
- CUDA Toolkit: PyTorchビルドに合うバージョン(例: 11.8, 12.1)。
- (Linuxのみ):
libsndfile1:soundfileが必要。sudo apt install libsndfile1ffmpeg:openai-whisperが必要。sudo apt install ffmpeg
📜 ライセンス
本プロジェクトはMIT Licenseの下でライセンスされています。
なお、Diaそのものは日本語には非対応
インストール方法は以下の3つ
- Python環境を作成、パッケージをインストールの上、サーバを起動
- Dockerコンテナを使う
docker composedocker run
推奨はdocker composeのようなので、これで進める。なお、環境はUbuntu-22.04(RTX4090)。
レポジトリクローン
git clone https://github.com/devnen/dia-tts-server.git && cd dia-tts-server
初期設定はオプションらしい。このあたりに説明がある。
設定メモ
- サーバーはコンテナ内
/app/config.yamlを設定ファイルとして使用。- 初回起動時
/app/config.yamlが存在しない場合、コードのデフォルトと.envの変数(Compose利用時)が合成されて生成。- 初回以降の設定変更方法:
- Web UIの設定ページを使用。
- コンテナ内
config.yamlを編集(例:docker compose exec dia-tts-server nano /app/config.yaml)。server/model/paths変更後はdocker compose restart dia-tts-serverで再起動が必要。UI状態変更は即保存。
んー、なんか微妙な気が・・・普通に設定ファイルをボリュームでマウントしたほうが良くないかな?と思うんだけど、まあそういう流儀みたいなので。
一応、.envの雛形を見ておく(コメント部分は日本語に翻訳した)
# .env - Dia TTS サーバーの初期設定シード
# 重要: このファイルは、config.yaml が存在しない場合に「のみ」、
# サーバーの最初の起動時に使用されます。
# config.yaml が作成されると、設定はそこで管理されます。
# ここでの変更は、既存の config.yaml を持つ実行中のサーバーには影響しません。
# 以降の変更は、Web UI を使用するか、config.yaml を直接編集してください。
# --- サーバ設定 ---
HOST='0.0.0.0'
PORT='8003'
# --- パス設定 ---
# これらのパスは、初期設定の config.yaml に記述されます。
DIA_MODEL_CACHE_PATH='./model_cache'
REFERENCE_AUDIO_PATH='./reference_audio'
OUTPUT_PATH='./outputs'
# Path for predefined voices is now set in config.py defaults
# 事前定義された音声のパスは config.py のデフォルトで設定されるようになりました。
# PREDEFINED_VOICES_PATH='./voices'
# --- モデルソース設定 ---
# Defaulting to BF16 safetensors. Uncomment/modify to seed config.yaml differently.
# デフォルトでは BF16 safetensorsを使用します。config.yaml のシード設定を変更するには、
# コメントを解除または変更してください。
DIA_MODEL_REPO_ID='ttj/dia-1.6b-safetensors'
DIA_MODEL_CONFIG_FILENAME='config.json'
DIA_MODEL_WEIGHTS_FILENAME='dia-v0_1_bf16.safetensors'
# 例:完全精度のsafetensorsを使用
# DIA_MODEL_REPO_ID=ttj/dia-1.6b-safetensors
# DIA_MODEL_WEIGHTS_FILENAME=dia-v0_1.safetensors
# 例: Nari Labs のオリジナルの .pth モデルを使用
# DIA_MODEL_REPO_ID=nari-labs/Dia-1.6B
# DIA_MODEL_WEIGHTS_FILENAME=dia-v0_1.pth
# --- Whisper 文字起こし設定 ---
# リファレンスの .txt ファイルがない場合の自動文字起こしのモデル名。
WHISPER_MODEL_NAME='small.en'
# --- デフォルトの生成パラメータ ---
# これらは、config.yaml の "generation_defaults"セクションの初期値を設定します。
# 後で UI("Save Generation Defaults"ボタン)または config.yaml を編集して変更できます。
GEN_DEFAULT_SPEED_FACTOR='1.0'
GEN_DEFAULT_CFG_SCALE='3.0'
GEN_DEFAULT_TEMPERATURE='1.3'
GEN_DEFAULT_TOP_P='0.95'
GEN_DEFAULT_CFG_FILTER_TOP_K='35'
# ランダムなシード値の場合は-1
GEN_DEFAULT_SEED='42'
# 現在は config.py のデフォルトで管理されるようになっています。
# GEN_DEFAULT_SPLIT_TEXT='True'
# GEN_DEFAULT_CHUNK_SIZE='120'
# --- UIの状態 ---
# UI 状態(最後のテキスト、選択内容など)は .env から初期化されません。
# config.py で定義されたデフォルト値で開始され、config.yaml に保存されます。
日本語で使うとかなら多少変更するところはあるかもしれないが(例えばWhisperのモデルとか)、そもそもDiaは現時点では日本語に対応していないので、特に設定しなくてもデフォルトにおまかせすれば良さそう。
ということで今回は.envファイルの作成はスキップする。業務で使うとかの場合には運用も絡んできそうなので適宜検討すればよいと思う。
docker-compose.yamlも簡単に見ておく。
version: '3.8'
services:
dia-tts-server:
build:
context: .
dockerfile: Dockerfile
ports:
- "${PORT:-8003}:${PORT:-8003}"
volumes:
# 永続的なデータ用にローカルディレクトリをコンテナにマウント
- ./model_cache:/app/model_cache
- ./reference_audio:/app/reference_audio
- ./outputs:/app/outputs
- ./voices:/app/voices
# config.yaml をマウントしないこと - アプリにコンテナ内で作成させる
# --- GPU アクセス設定 ---
# 最新の方法(最近の Docker/NVIDIA 設定に推奨)
devices:
- nvidia.com/gpu=all
device_cgroup_rules:
- "c 195:* rmw" # 一部の NVIDIA コンテナツールキットのバージョンに必要
- "c 236:* rmw" # 一部の NVIDIA コンテナツールキットのバージョンに必要
# レガシー方式(古い Docker/NVIDIA向けの代替設定方法)
# 上記の"devices"ブロックが機能しない場合は、上記のブロックをコメントアウトし、
# この下の"deploy"ブロックのコメントを解除。両方を同時に使用しないこと
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# count: 1 # または、特定の GPU を指定(例:"device=0,1")。
# capabilities: [gpu]
# --- GPU アクセス設定 ここまで ---
restart: unless-stopped
env_file:
# 初期設定のシード用に .env ファイルから環境変数をロード
- .env
environment:
# コンテナ内で Hugging Face のダウンロードを高速化
- HF_HUB_ENABLE_HF_TRANSFER=1
# GPUのケイパピリティを設定(レガシー方式をコメント解除した場合に必要になる場合がある)
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=compute,utility
んー、普通に.env読むようになっているな。これだとこのまま起動するとエラーになるはず。とりあえず.envを雛形から作成する。
cp env.example.txt .env
あと、デフォルトだとコンテナをビルドするようだが、ビルド済イメージが公開されているのでそちらを使うようにする。
(snip)
services:
dia-tts-server:
# build以下をコメントアウト
#build:
# context: .
# dockerfile: Dockerfile
# imageの指定を追加
image: ghcr.io/devnen/dia-tts-server:latest
では起動。
docker compose up
エラー。どうやら自分の環境ではGPUアクセス時の設定はレガシー方式にしないといけないみたい。
Error response from daemon: could not select device driver "cdi" with capabilities: []
ということで修正
(snip)
#devices:
# - nvidia.com/gpu=all
#device_cgroup_rules:
# - "c 195:* rmw"
# - "c 236:* rmw"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
(snip)
再度docker compose upするも、エラー・・・
Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running prestart hook #0: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: requirement error: unsatisfied condition: cuda>=12.8, please update your driver to a newer version, or use an earlier cuda container: unknown
CUDAのバージョンを上げたくはないなぁ・・・Dockerfileを見てみる。
あー、これか。自分の環境はCUDA-12.4。調べてみるとCUDA-12.4.1のUbuntuベースのイメージがある。
Dockerfileをこれに書き換える。
FROM nvidia/cuda:12.4.1-runtime-ubuntu22.04
で、docker-composeでビルド済みイメージをpullするのではなく、ローカルでビルドするようにする。つまりここは元の設定に戻ったことになる。
(snip)
services:
dia-tts-server:
build:
context: .
dockerfile: Dockerfile
#image: ghcr.io/devnen/dia-tts-server:latest
再度docker compose up。今回はコンテナイメージのビルドが行われるので、結構な時間がかかる。
docker compose up
今度は起動したみたい
dia-tts-server-1 | INFO: Application startup complete.
dia-tts-server-1 | INFO: Uvicorn running on http://0.0.0.0:8003 (Press CTRL+C to quit)
dia-tts-server-1 | 2025-05-22 10:16:12,863 [INFO] server: Attempting to open browser at http://localhost:8003/
ブラウザで8003版ポートにアクセスするとWebUIが表示される
/docsでAPIドキュメントが確認できる
ではまずWeb UIから生成してみる。上の方から設定内容を見ていく。
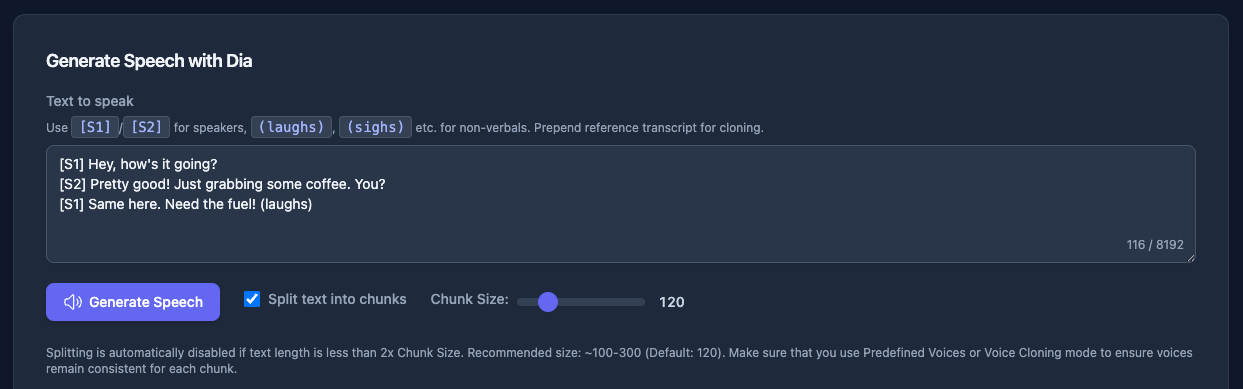
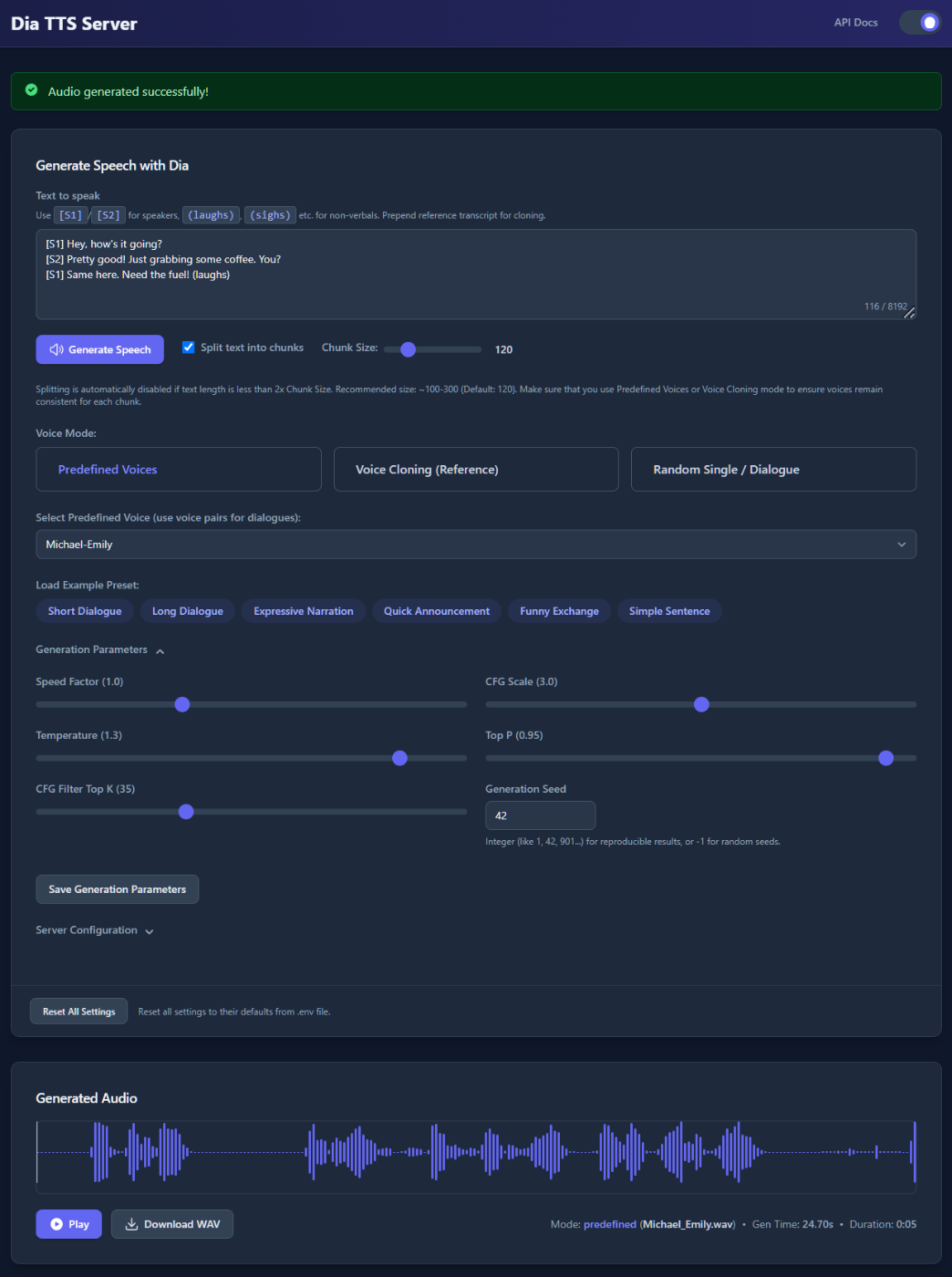
ミニマムだと、一番上のテキストボックス内に対話のテキストを入力して「Generate Speech」をクリックするだけ。Diaでは基本的に 「2人の対話」 の形で音声を生成するので、それぞれの話者の発話を[S1] ... / [S2] ... と入力する。あと、(laughs) や '(sigh)` などの 「非言語タグ」 を使うことで、よりリアルな発話表現を行える。
あと、Dia-TTS-Serverならでは、の機能として、長文のテキストが入力された場合には、ここの発話をチャンクで生成して最後に結合するということができるみたい。ただ、個人的には、Diaの場合は「対話」というコンテキストがあるからこそリアルな表現になると思っていて、チャンク分割するということはこのコンテキストが分断されるのでは?=対話のリアルさに影響があるのではないか?という気がするのだが、どうだろうか?ここは後で確認してみたい。
次に音声モード。

発話する際の音声を以下の3つから設定できる
- Predefined Voices: 事前定義された音声の組み合わせから選択
- Voice Cloning (Reference): リファレンスとなる音声データを使用して、音声クローンを行う
- Random Single / Dialogue: ランダムな音声を使用
元々のDiaの実装では、音声は都度都度生成されるたびに変わるもので、これを維持したい場合には音声クローンを使用する必要があった。このPredefined Voices、事前定義済み音声から選択できるというのはDia-TTS-Serverならではの機能だと思う(内部的にはリファレンス音声のペアを使っているのではないだろうか?)。なお、事前定義済み音声のペアはこれだけ用意されている。

Voice Cloneでは、音声データをアップロードして、その音声を使って生成を行う。

ここも少し工夫されているようで、毎回リファレンス音声を送信することなく、一度アップロードしたら繰り返し使えるようになっているみたい。
ランダムは単にランダムになるだけなので割愛。
Load Example Presetは対話台本のサンプルを呼び出すだけ。

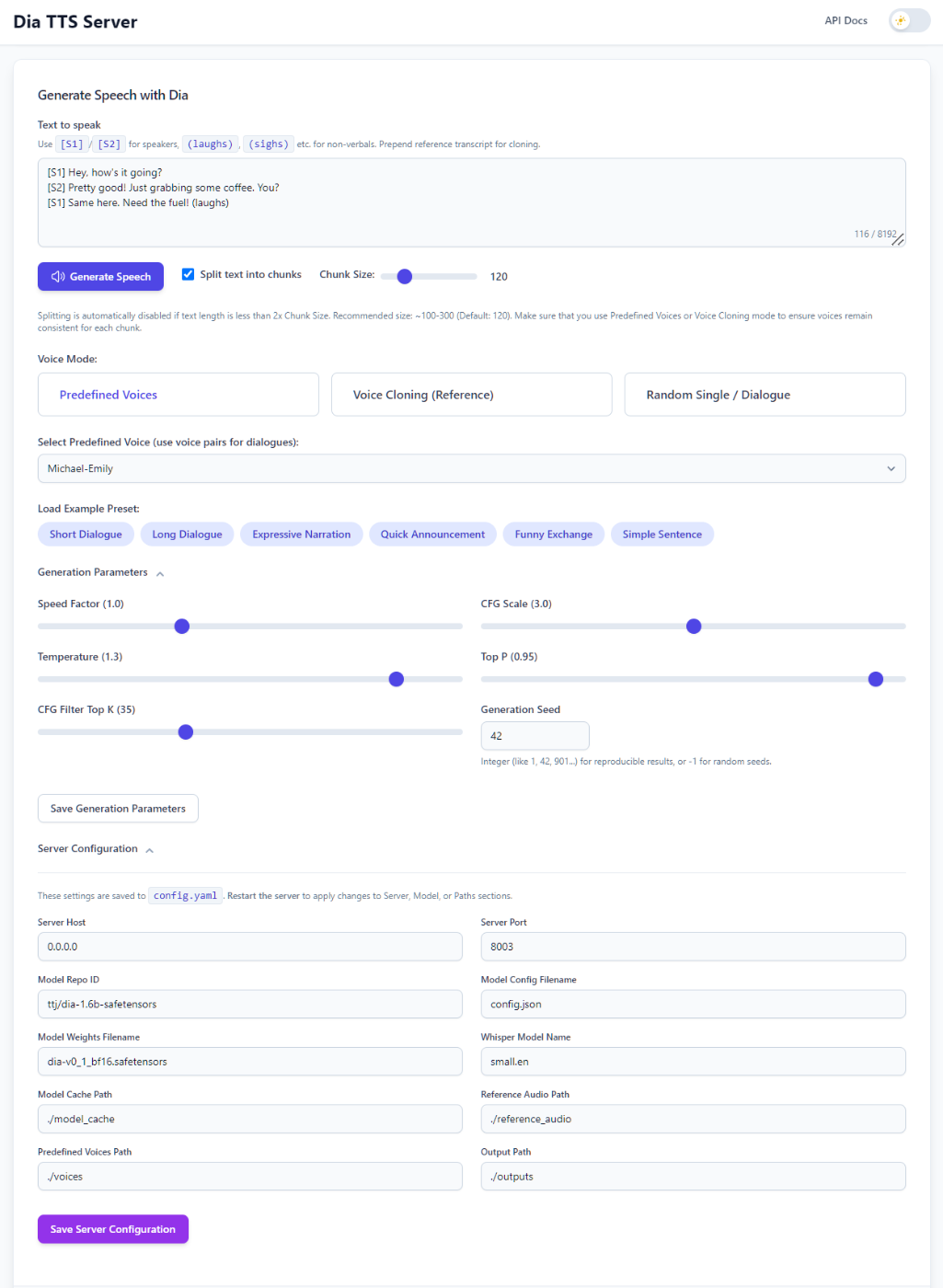
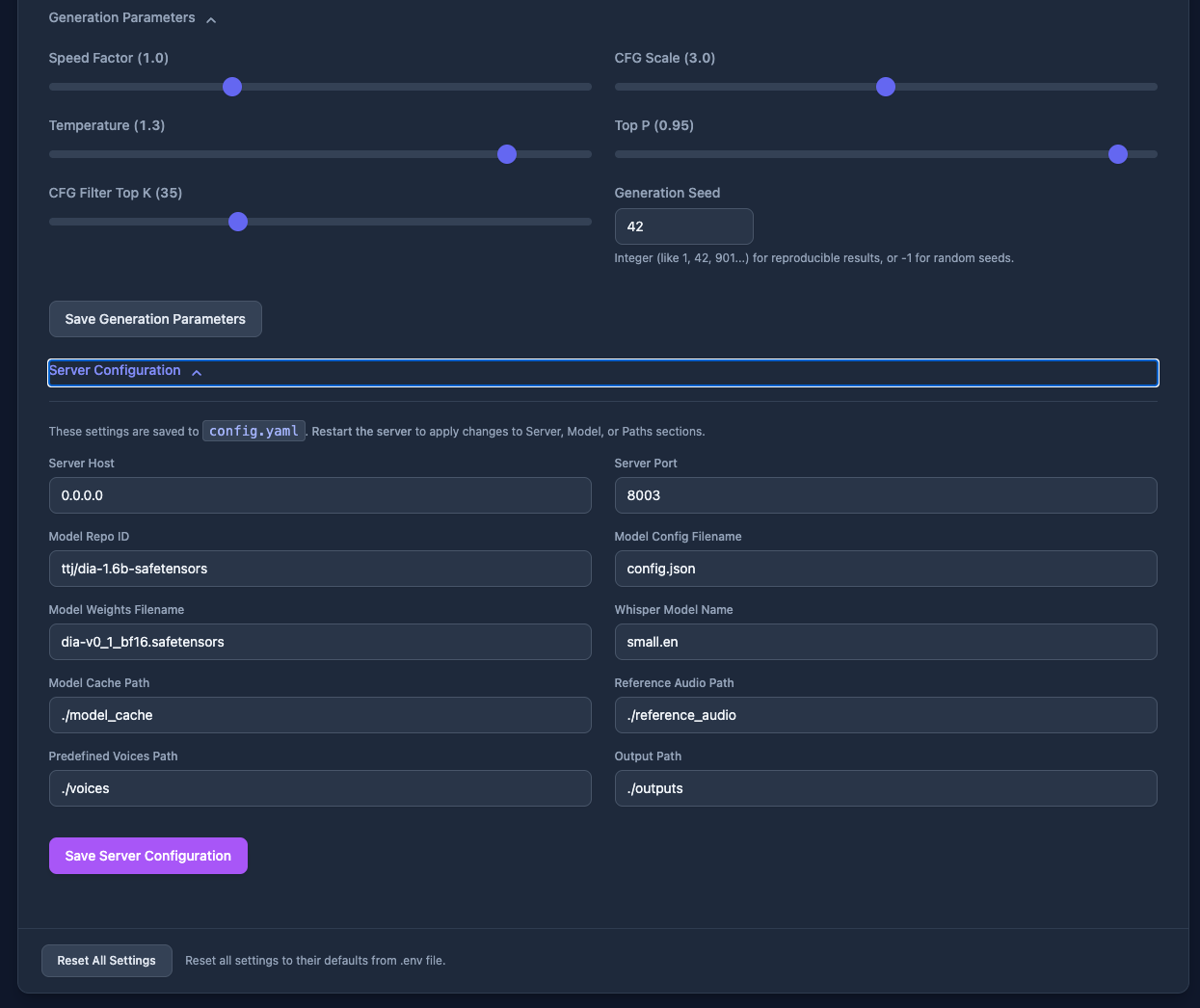
Generatin ParametersやServer Configurationは、生成に関するサーバの細かい設定。ここも一度設定したら保存しておく機能があるところはDia-TTS-Server固有の機能となっている。なかなか細かい配慮だな。
では最初に戻って生成してみる。文章はデフォルトのものをそのまま使う。「Generate Speech」をクリック。
注意書きが出てくる。
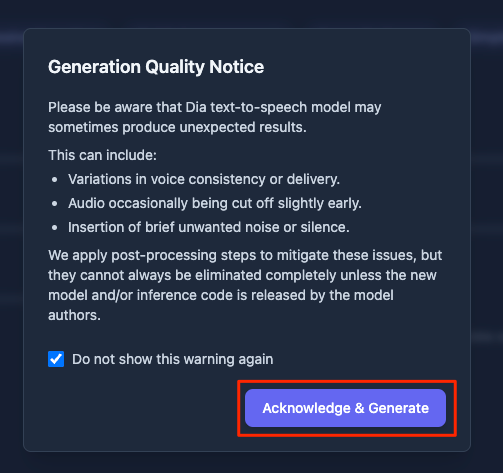
以前試した際に、Diaが生成するる音声は非決定論的で一貫性はないものと認識している。また、生成結果に稀に不備があることがある(個人的には非言語タグが機能しないケースはそれなりにあると思う)、かなと言う気もするので、それらに対する注意なのだと思う。
次に進むと生成が開始される

5秒ぐらいで生成された。結果は以下のように表示され、その場で聞くこともできるし、ダウンロードすることもできる。
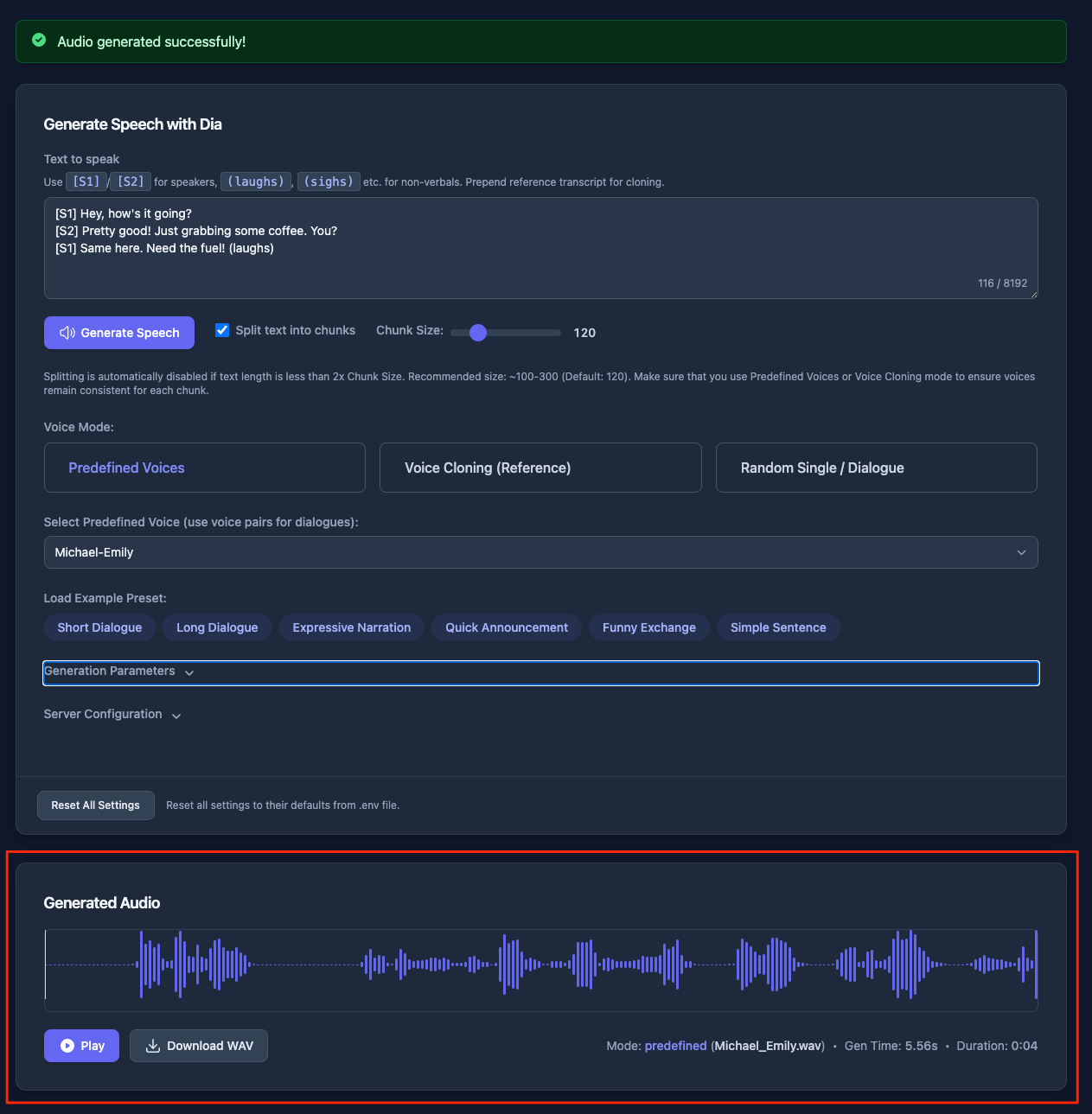
実際に生成されたものはこちら。なんかテンション高いのとちょっと妙に早口感があるな。
まあこのあたりはパラメータを調整していけばいいと思う。 パラメータで発話速度を遅くすると、音声を引き伸ばして低音になる感じだなぁ。うーん、Diaを直接試したときにはこんなことはなかったと思うのだけど・・・もう少し調べてみる。
なんか発話速度が安定しない気がするなぁ・・・・Dia本体を試したときと同じテキストで生成させると、Dia本体の時の発話時間の半分ぐらいで生成される(つまり早口)ようなケースが多い気がする。
Dia本体のIssueでも発話速度が早すぎるというのが上がってる。発話速度を変えるとピッチも変わってしまうというのも今回感じたのと同じ。ただ、自分が試したときにはそうは感じなかったけどな。試行回数が少なくて気づかなかった可能性はあるのかも。
とりあえず進める。
/docsでAPIドキュメントが見れる。/v1/audio/speechがOpenAI互換のエンドポイントで、/ttsがより細かく制御できる独自のエンドポイントになっている。
OpenAI互換の方をcurlで試してみる。
time curl -X POST "http://rtx4090.local:8003/v1/audio/speech" \
-H "Content-Type: application/json" \
-d '{
"input": "Hello, this is a test of the Dia text to speech system.",
"voice": "Connor.wav",
"response_format": "wav",
"speed": 1.0,
"seed": 42
}' \
--output output.wav && afplay output.wav
発話速度が早いのはこちらでも同じだなぁ。
改めて本家の方も再度生成してみたけど、どっちも速いな。気持ちだけDia-TTS-Serverのほうが速いように思えるけど、本家のSpeed Factorは0.95だった。あまり下げすぎるとピッチも下がるので0.9ぐらいにするのが良さそう。
まとめ
少し構築のところで変更せざるを得なかったけど、それでもだいぶお手軽にDiaのリアルな発話がAPIでできるのは良いね。発話スピードが早すぎるのはDia公式でも認識してるみたいだから、そのうち改善されることを期待したい。