表現力が高い対話音声生成TTS「Dia-1.6B」を試す
GitHubレポジトリ
Nari Dia-1.6B
referred from https://github.com/nari-labs/diaDia は Nari Labs が開発した 16 億パラメータのText-to-Speechモデルです。
Dia はトランスクリプトから極めてリアルな対話音声を直接生成 します。音声条件付けにより感情やトーンを制御できます。また、笑い声・咳・咳払いなどの非言語的な発話も生成可能です。
研究促進のため、学習済みモデルのチェックポイントと推論コードを公開しています。モデルの重みは Hugging Face にホストされています。現在、生成をサポートする言語は英語のみです。
比較デモとして、ElevenLabs Studio および Sesame CSM-1B との比較を行った デモページ も用意しています。
- (更新)ZeroGPU Space が稼働中です!今すぐ こちら でお試しください。HF チームのサポートに感謝します :)
- 新機能やコミュニティサポートのために Discord サーバー に参加してください。
- より大きな Dia バージョンで遊ぶ:面白い会話を生成し、コンテンツをリミックスして友人と共有しましょう。🔮 早期アクセス用 待機リスト に参加してください。

生成ガイドライン
- 入力テキストは適度な長さを維持してください
- 5 秒未満に相当する短すぎる入力は不自然に聞こえます。
- 20 秒を超える長すぎる入力は不自然に速い発話になります。
- README に記載の非言語タグを節度を持って使用してください。未掲載タグや過度な使用は異常なアーティファクトを生む可能性があります。
- 入力テキストは必ず
[S1]で開始し、以降は[S1]と[S2]を交互に使用してください(例:[S1]...[S1]... は不可)。- 音声プロンプト(ボイスクローン)を用いる場合は、以下の手順を厳守してください:
- クローン対象音声のトランスクリプトを、生成テキストの前に配置する。
- トランスクリプト内の
[S1],[S2]タグを正しく用いる(単一話者なら[S1]..., 二人なら[S1]...[S2]...)。- クローン対象音声の長さは 5〜10 秒が最適(1 秒 ≈ 86 トークン)。
- 音声終端品質向上のため、生成テキスト末尾に
[S1]または[S2](直前の話者タグ)を置くこと。
特徴
[S1],[S2]タグによる対話生成(laughs),(coughs)などの非言語生成
- 以下の非言語タグは認識されますが、予期しない出力になる場合があります。
(laughs), (clears throat), (sighs), (gasps), (coughs), (singing), (sings), (mumbles), (beep), (groans), (sniffs), (claps), (screams), (inhales), (exhales), (applause), (burps), (humming), (sneezes), (chuckle), (whistles)- ボイスクローン。詳しくは
example/voice_clone.pyを参照。
- Hugging Face Space では、クローンしたい音声をアップロードし、スクリプト前にそのトランスクリプトを置いてください。フォーマットを満たしていれば、モデルはスクリプトの内容のみを出力します。
💻 ハードウェアと推論速度
Dia は GPU (pytorch 2.0+, CUDA 12.6) でのみテスト済みです。CPU 対応は今後追加予定です。初回実行時は Descript Audio Codec のダウンロードも行われるため時間がかかります。
RTX 4090 でのベンチマーク結果は以下のとおりです。
精度 実時間係数(コンパイルあり) 実時間係数(コンパイルなし) VRAM bfloat16x2.1 x1.5 ~10GB float16x2.2 x1.3 ~10GB float32x1 x0.9 ~13GB 今後、量子化版も追加予定です。
ハードウェアが無い場合や、より大規模なモデルを試したい場合は こちら の待機リストに参加してください。
🪪 ライセンス
本プロジェクトは Apache License 2.0 の下でライセンスされています。詳細は LICENSE ファイルをご覧ください。
🔭 TODO / 今後の課題
- ARM アーキテクチャおよび MacOS 向け Docker 対応
- 推論速度の最適化
- メモリ効率向上のための量子化対応
ローカルのUbuntu-22.04(RTX4090・CUDA-12.4)で試す
レポジトリクローン
git clone https://github.com/nari-labs/dia.git && cd dia
で、app.pyを立ち上げればGradioのWeb UIが起動するのだが、自分の環境はLAN内のリモートサーバなので、GRADIO_SERVER_NAME=0.0.0.0をつける
GRADIO_SERVER_NAME=0.0.0.0 uv run app.py
エラー
ImportError: libcusparseLt.so.0: cannot open shared object file: No such file or directory
どうやらこれみたい
aptで検索してみると出てくる
apt search cuSPARSELt
libcusparselt-dev/不明 0.7.1.0-1 amd64
CUSPARSE Lt native dev links, headers
libcusparselt0/不明 0.7.1.0-1 amd64
CUSPARSE Lt native runtime libraries
インストール
sudo apt install libcusparselt0
再度実行するも今度は・・・
ImportError: libnccl.so.2: cannot open shared object file: No such file or directory
これもaptにあった(というかNVIDIAのaptレポジトリが追加してある)
apt search libnccl2
libnccl2/不明 2.26.5-1+cuda12.9 amd64
NVIDIA Collective Communication Library (NCCL) Runtime
sudo apt install libnccl2
これで実行できた。
GRADIO_SERVER_NAME=0.0.0.0 uv run app.py
モデルがダウンロードされるので少し時間がかかる
Using device: cuda
Loading Nari model...
config.json: 100%|███████████████████████████████████████████████| 941/941 [00:00<00:00, 3.11MB/s]
model.safetensors: 6%|██▏ | 367M/6.44G [00:39<10:48, 9.37MB/s]
以下が表示されればOK
Launching Gradio interface...
* Running on local URL: http://0.0.0.0:7860
ブラウザでアクセスすると以下のような画面が出力される。
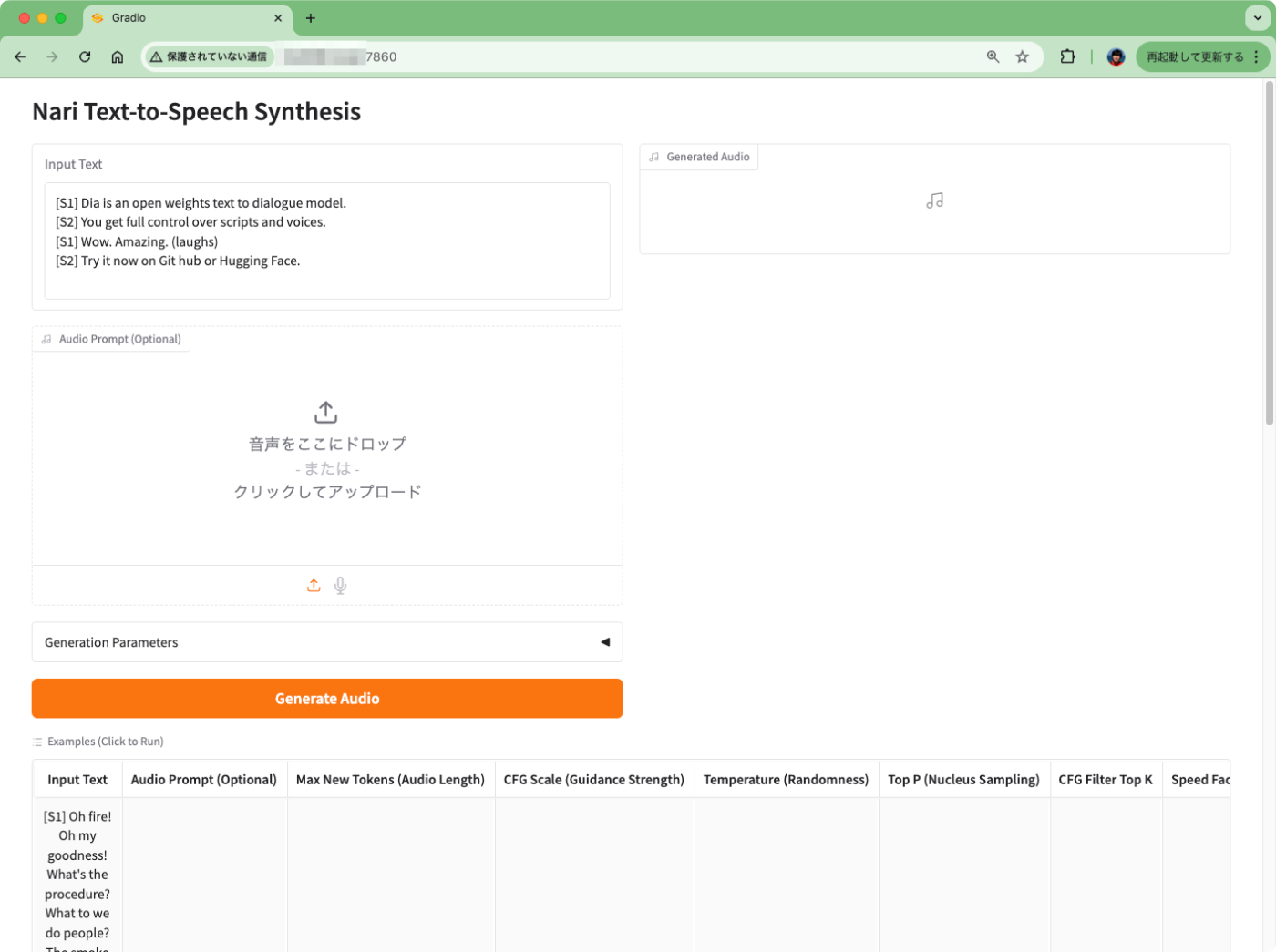
Diaでは文字起こししたいテキストを対話形式で記述する。デフォルトだとこんな感じ。
[S1] Dia is an open weights text to dialogue model.
[S2] You get full control over scripts and voices.
[S1] Wow. Amazing. (laughs)
[S2] Try it now on Git hub or Hugging Face.
日本語に翻訳するとこんな感じ。
[S1] Dia は、オープンウェイトのテキストから対話モデルです。
[S2] スクリプトや音声は完全に制御できます。
[S1] すごい。素晴らしいですね(笑)。
[S2] Github または Hugging Face で今すぐお試しください。
プロンプトの書き方については、READMEの「特徴(Features)」と「生成ガイドライン(Generation Guidelines)」に記載があるが、基本的に
- 対話なので
[S1]から初めて[S2]と交互になるように書く。- 同じ話者が連続するような書き方はできない。
- プロンプトは短くても長くてもダメ。
- 非言語タグはリストにあるもの以外は使ってはダメ、また過剰に使いすぎてもダメ。
という感じで、結構条件が厳しい。あと音声クローンについてはより注意が必要なようだが、これは後ほど。
まずはデフォルトで生成してみる。

約13秒かかった。結果は右側に表示される。

実際に生成されたもの。ややオーバーラップ気味だったりして非常にリズムが良い。
再度生成してみた結果が以下。聴き比べるとわかるが1回目とは生成内容が変わっている。つまり毎回異なる結果となる。
他にもサンプルが2つ用意されている。1つ目のサンプル。

[S1] Oh fire! Oh my goodness! What's the procedure? What to we do people? The smoke could be coming through an air duct!
[S2] Oh my god! Okay.. it's happening. Everybody stay calm!
[S1] What's the procedure...
[S2] Everybody stay fucking calm!!!... Everybody fucking calm down!!!!!
[S1] No! No! If you touch the handle, if its hot there might be a fire down the hallway!
日本語訳
[S1] うわ、火事!?なんてこった!どうすればいいんだよ!?俺たちはどうすればいいんだ!?煙が空調ダクトから来てるかもしれないぞ!
[S2] まじか!本当に起きてる!みんな落ち着いて!!!
[S1] どうすればいいんだ…
[S2] 全員マジで落ち着けって!!落ち着けえええ!!!
[S1] だめだ!ノブ触るな!熱かったら、廊下の先が火事ってことだ!!
実際に生成したもの。非言語タグも使ってなくて文章だけで、これだけ臨場感があるものが生成されるのはすごい。
もう一つの例。こちらは音声プロンプト、つまり音声クローンの例。
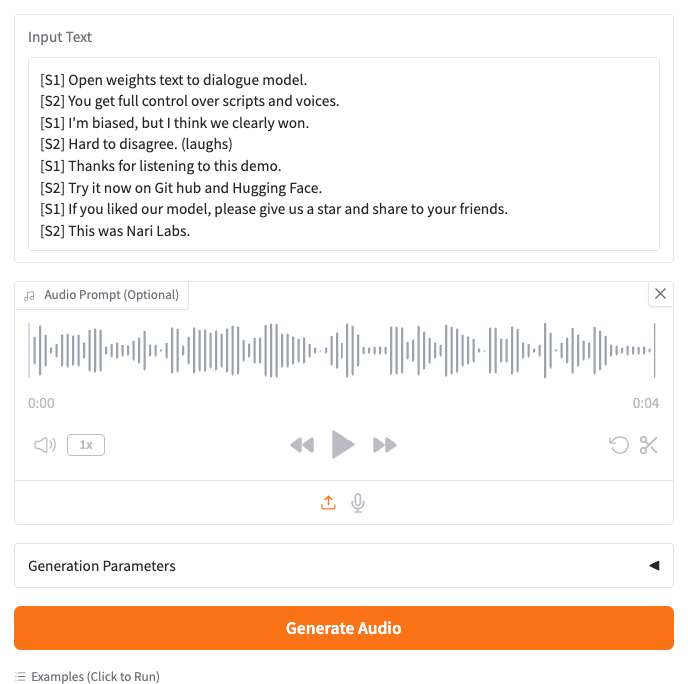
[S1] Open weights text to dialogue model.
[S2] You get full control over scripts and voices.
[S1] I'm biased, but I think we clearly won.
[S2] Hard to disagree. (laughs)
[S1] Thanks for listening to this demo.
[S2] Try it now on Git hub and Hugging Face.
[S1] If you liked our model, please give us a star and share to your friends.
[S2] This was Nari Labs.
日本語訳
[S1] オープンウェイトのテキスト対話モデルです。
[S2] スクリプトも声も、全部あなたの自由にコントロールできますよ。
[S1] ちょっと贔屓目かもしれないけど、これはもう、明らかに私たちの勝ちだよね。
[S2] 異論はないね(笑)
[S1] このデモを聞いてくれてありがとう。
[S2] 今すぐGitHubとHugging Faceで試してみてください。
[S1] もしこのモデルを気に入ってくれたら、スターを付けて、お友達にもぜひシェアしてくださいね。
[S2] 提供は Nari Labs でした。
で、上の画像にあるように、音声プロンプトが与えられている。プロンプトの音声ファイルははレポジトリにある。
で、これは上の対話スクリプトの冒頭2行を読み上げたものとなっている。
[S1] Open weights text to dialogue model.
[S2] You get full control over scripts and voices.
(snip)
で生成すると残りの部分が生成されるということ。
"I'm biased..."からの対話が生成されているのがわかる。ただ、声は少し音声プロンプトとは違うところがあるかなぁという気がしないでもない。
なお、VRAM使用量はこんな感じ
Sat May 17 13:18:35 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
| 31% 61C P0 223W / 450W | 10800MiB / 24564MiB | 96% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
対話形式でリアルな表現ができるのはいいのだけど、単に単一話者でシンプルに発話させたい場合はどうすればいいか?
単純に[S1]に発話させたいテキストを記述すればよさそう?

生成させたもの
ただ、Diaの場合、一貫性はないので毎回音声が異なる結果となってしまう。その場合は音声クローンを使えば良さそう。
以下は以前Kokoro TTSを使って生成させた音声
Good morning. It's a beautiful day today. On days like this, I feel like going to the horse races.
これを音声プロンプトして設定して、テキストにも上記を記述しつつ、続きに生成させたいテキストを追加する。
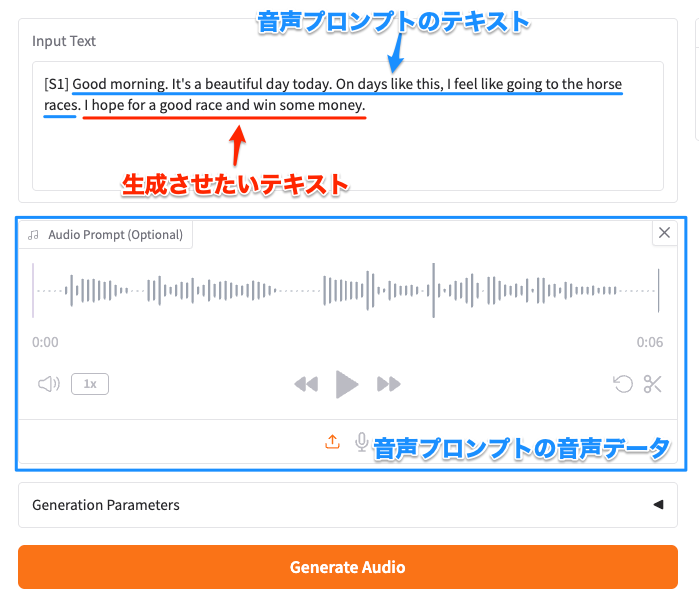
こんな感じで生成。
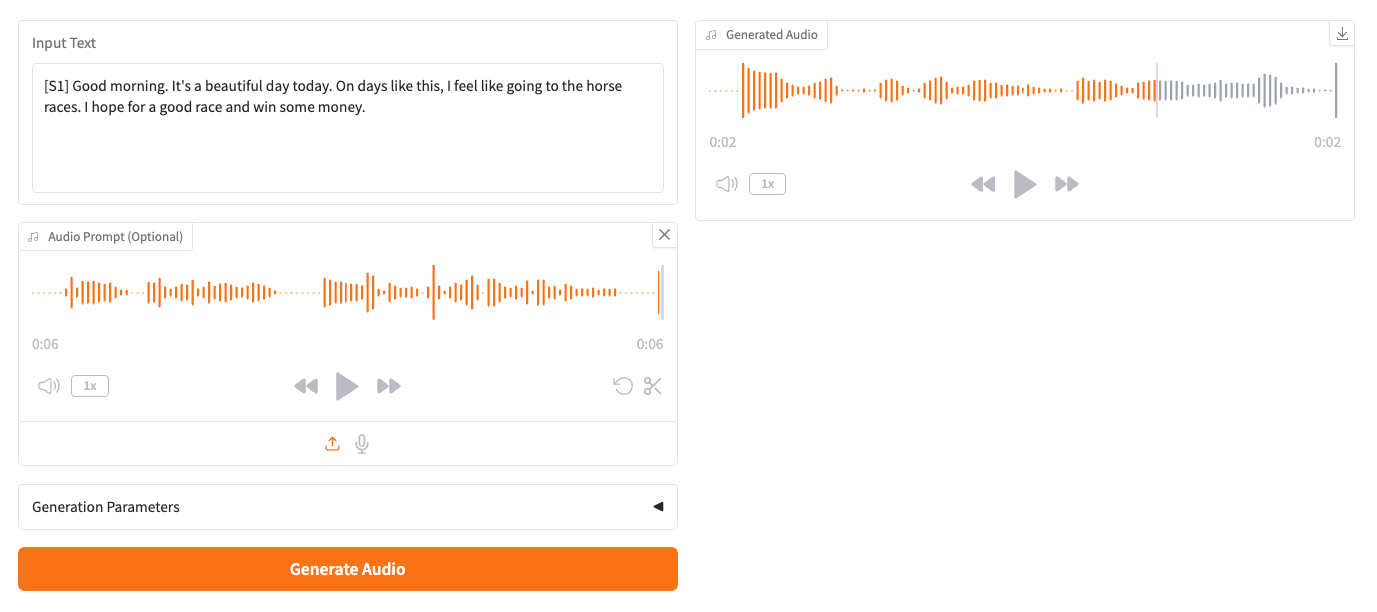
実際に生成されたもの。すこーしだけ違うような気もするが、似た感じにはなっている。
なお、追加した文章に、感嘆詞をつけたり、非言語タグは使わないほうが良さそう。ぜんぜん違う音になる。
Pythonでも生成はできる。インストールしたレポジトリで以下のようなスクリプトを書いて、
import soundfile as sf
from dia.model import Dia
model = Dia.from_pretrained("nari-labs/Dia-1.6B")
text = "[S1] Dia is an open weights text to dialogue model. [S2] You get full control over scripts and voices. [S1] Wow. Amazing. (laughs) [S2] Try it now on Git hub or Hugging Face."
output = model.generate(text)
sf.write("simple.mp3", output, 44100)
実行
uv run sample.py
音声ファイルが生成される。
FastAPIでAPIサーバ化する場合にはこちらが良さそう、と思ったら、すでに実装している人がいた
Macの場合はMLX使うのが良さそう。量子化バージョンもある。
まとめ
非常に表現力が高くて、評判通りという印象。すごいね。
ただ、対話形式で生成するという点はsesami/csm-1bとも似ていて、シンプルなTTSとして考えると少しクセがあるというか使い方を考える必要はある。その場合には、上の方でも少し記載したが、単一話者で音声クローン、になると思う。
現時点では英語でしか使えないので、日本語が使えるようになることを期待・・・
参考