スケーラブルなPython & AI分散処理を構築するフレームワーク「Ray」を試す
GitHubレポジトリ
RAY
Rayは、AIおよびPythonアプリケーションの拡張性を高めるための統一フレームワークです。Rayは、コアとなる分散実行環境と、MLコンピューティングを簡素化するAIライブラリセットで構成されています。
referred from https://github.com/ray-project/rayRay AI ライブラリについてさらに詳しく:
- Data: ML 用のスケーラブルなデータセット
- Train: 分散トレーニング
- Tune: スケーラブルなハイパーパラメータのチューニング
- RLlib: スケーラブルな強化学習
- Serve: スケーラブルかつプログラマブルなサービング
または、Ray Coreとその主要な抽象化についてさらに詳しく:
モニタリングとデバッグについて更に詳しく
- Ray Dashboard で Ray アプリケーションとクラスタをモニタリングします。
- Ray Distributed Debugger で Ray アプリケーションをデバッグします。
Ray はあらゆるマシン、クラスタ、クラウドプロバイダ、Kubernetes で動作し、コミュニティ統合のエコシステムが拡大しています。
pip install rayで Rayをインストールしてください。ナイトリービルドのwheelについては、インストールのページを参照してください。なぜ Ray なのか?
今日の機械学習のワークロードは、ますます計算集約的になっています。 ノートパソコンのようなシングルノードの開発環境は便利ですが、これらの要求を満たすには拡張性が十分ではありません。
Ray は、ラップトップからクラスタまで、Python および AI アプリケーションをスケーリングするための統一された方法です。
Ray を使用すると、ラップトップからクラスタまで、同じコードをシームレスにスケーリングできます。Ray は汎用に設計されており、あらゆる種類のワークロードを高いパフォーマンスで実行できます。アプリケーションが Python で書かれていれば、他のインフラストラクチャを必要とせずに Ray でスケーリングできます。

公式ドキュメント
ここで見つけた
Amazon EKS上のRay ServeによるWhisperストリーミング
Whisper Streamingは、Ray ServeをベースとしたASRソリューションで、ほぼリアルタイムの音声ストリーミングと書き起こしを可能にします。このシステムは、Huggingfaceの音声活動検出(VAD)とOpenAIのWhisperモデル(faster-whisperがデフォルト)を採用し、正確な音声認識と処理を実現しています。
Rayってなんぞや?からスタートして、色々探してみた。
このあたりを見ていると、どうやらKubernetes上にvLLMでモデルをデプロイとかができるみたい。
本来的には分散並列処理を簡単に使えるようにするものみたいだが、色々使える様子
ちょっと面白そう
Getting Started
Getting Startedに従って進める。でタスクに合わせて複数のQuick Startがあるのだが、
- MLワークロードのスケーリング:Ray Librariesクイックスタート
- 一般的なPythonアプリケーションのスケーリング:Ray Coreクイックスタート
- クラウドへのデプロイ:Ray Clustersクイックスタート
- アプリケーションのデバッグとモニタリング:デバッグとモニタリングのクイックスタート
まずはCoreから始めて、次にClustersをやれば良さそうに思うので、それで進める。
Ray Core Quickstart
Ray Coreは冒頭似合った通り、分散実行環境を提供する。Quickstartは2つ。
- Ray Tasksを使った関数の並列化
- Ray Actorsを使ったクラスの並列化
となっている。
Rayの開発元であるAnyscaleのクラウド上でも試せるようだが、まずはローカルのMacで試してみる。
作業ディレクトリ+Python仮想環境を作成
mkdir ray-test && cd ray-test
uv venv -p 3.12.8
rayをインストール
uv pip install -U "ray"
Installed 20 packages in 52ms
(snip)
+ ray==2.42.0
(snip)
まずTasks。
Rayは、任意の関数を個別のPythonワーカー上で非同期に実行することを可能にします。このような関数はRayリモート関数と呼ばれ、その非同期呼び出しはRay Tasksと呼ばれます。
import ray
# 既存のRayクラスタ、または新しいRayクラスタを起動して接続
ray.init()
# `@ray.remote` デコレータを追加することで、通常のPython関数が
# Rayのリモート関数になる
@ray.remote
def f(x):
return x * x
# Rayタスクは並列で実行される。すべての計算はバックグラウンドで実行され、
# Rayの内部イベントループによって駆動される
futures = [f.remote(i) for i in range(4)]
# 結果は`ray.get`で取得
print(ray.get(futures)) # [0, 1, 4, 9]
実行
uv run sample_task.py
クラスタがない場合はどうやらRayインスタンスが立ち上がって実行される様子。
2025-02-10 21:18:24,938 INFO worker.py:1841 -- Started a local Ray instance.
[0, 1, 4, 9]
処理が終わるとRayインスタンスはもう存在していなかった。
次にActors。
Actorsは、Ray APIの機能を(タスク)からクラスに拡張します。 Actorは本質的にはステートフルなワーカー(またはサービス)です。 新しいActorがインスタンス化されると、新しいワーカーが作成され、Actorのメソッドはその特定のワーカー上でスケジュールされ、そのワーカーの状態にアクセスしたり変更したりすることができます。
import ray
# 既存のRayクラスタ、または新しいRayクラスタを起動して接続
ray.init()
# `@ray.remote`デコレータを追加することで、CounterクラスのインスタンスがActorになる。
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
# 各Actorは、独自のPythonプロセスで実行される
counters = [Counter.remote() for i in range(4)]
[c.increment.remote() for c in counters]
futures = [c.read.remote() for c in counters]
# 結果は`ray.get`で取得
print(ray.get(futures)) # [1, 1, 1, 1]
実行
uv run sample_actor.py
こちらも同様
2025-02-10 21:28:44,095 INFO worker.py:1841 -- Started a local Ray instance.
[1, 1, 1, 1]
まあなんか分散して処理されているんだろうとは思うのだけど、これだけじゃ正直よくわからない。
んー、Anyscaleとかでクラスタを動かしたほうがいいのかなーという気がする。一応無料で始めれるようだし。
Ray Clusters Quickstart
Anyscaleにも興味が出つつも、できればローカルで動かしたいということで。
Getting StartedからRay Clustersの概要を見ると以下の環境へデプロイできる様子。
- クラウド
- 公式サポート
- AWS
- GCP
- コミュニティサポート
- Azure
- Aliyun
- vSphere
- 公式サポート
- Kubernetes
- 公式(KubeRay Operator)
KubernetesのRayCluster QuickstartはどうやらKindを使っている模様。これならとりあえず手元でも比較的簡単に動かせそう。
一旦これに従ってやってみることにする。Kindは以前に試してから久々に触る。Docker-in-Dockerなのでちょっとクセはあるのだけど、その分お手軽だしマルチクラスタも使えるので、お試しには良いと思う。
kubectl、kind、helmがなければインストール。MacだとHomebrewでインストールできる。
brew install kind kubectl helm
kind version
kind v0.26.0 go1.23.4 darwin/arm64
kubectl version
Client Version: v1.32.1
Kustomize Version: v5.5.0
helm version
version.BuildInfo{Version:"v3.17.0", GitCommit:"301108edc7ac2a8ba79e4ebf5701b0b6ce6a31e4", GitTreeState:"clean", GoVersion:"go1.23.4"}
ということでkindでクラスタを作成
kind create cluster --image kindest/node:latest
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.32.0) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community 🙂
kubectl cluster-info --context kind-kind
Kubernetes control plane is running at https://127.0.0.1:58164
CoreDNS is running at https://127.0.0.1:58164/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
kubectl get node
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready control-plane 54s v1.32.0
とりあえずクラスタが作成されコントロールプレーンが動いている。
KubeRay operatorをデプロイしていく。
Helmレポジトリ追加
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
helm repo update
最新は1.2.2みたいなので、バージョン指定はなくても良さそう。
helm search repo kuberay/kuberay-operator
NAME CHART VERSION APP VERSION DESCRIPTION
kuberay/kuberay-operator 1.2.2 A Helm chart for Kubernetes
デプロイ
helm install kuberay-operator kuberay/kuberay-operator --version 1.2.2
NAME: kuberay-operator
LAST DEPLOYED: Tue Feb 11 05:57:20 2025
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
kubectl get pod
NAME READY STATUS RESTARTS AGE
kuberay-operator-975995b7d-rrpmq 1/1 Running 0 31s
RayClusterのカスタムリソースをデプロイ
helm install raycluster kuberay/ray-cluster --set 'image.tag=2.9.0-aarch64'
NAME: raycluster
LAST DEPLOYED: Tue Feb 11 06:04:48 2025
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
kubectl get rayclusters
ここはちょっと時間がかかるが、以下のようになればOK。
NAME DESIRED WORKERS AVAILABLE WORKERS CPUS MEMORY GPUS STATUS AGE
raycluster-kuberay 1 1 2 3G 0 ready 2m59s
kubectl get pods --selector=ray.io/cluster=raycluster-kuberay
NAME READY STATUS RESTARTS AGE
raycluster-kuberay-head-t9d5l 1/1 Running 0 2m35s
raycluster-kuberay-workergroup-worker-5wzqs 1/1 Running 0 2m35s
最終的にはこんな感じ。
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/kuberay-operator-975995b7d-rrpmq 1/1 Running 0 12m
pod/raycluster-kuberay-head-t9d5l 1/1 Running 0 4m59s
pod/raycluster-kuberay-workergroup-worker-5wzqs 1/1 Running 0 4m59s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kuberay-operator ClusterIP 10.96.142.213 <none> 8080/TCP 12m
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 22m
service/raycluster-kuberay-head-svc ClusterIP None <none> 10001/TCP,8265/TCP,8080/TCP,6379/TCP,8000/TCP 4m59s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kuberay-operator 1/1 1 1 12m
NAME DESIRED CURRENT READY AGE
replicaset.apps/kuberay-operator-975995b7d 1 1 1 12m
NAME DESIRED WORKERS AVAILABLE WORKERS CPUS MEMORY GPUS STATUS AGE
raycluster.ray.io/raycluster-kuberay 1 1 2 3G 0 ready 4m59s
これでRayのクラスタ作成が完了。
ではクラスタ上でアプリケーションを動かす。やり方は2つ紹介されている。
- ヘッドpod上でRayジョブを動かす
- ray job submission SDKを使ってRayクラスタにRayジョブを投入する
ヘッドpodとはなんぞや?と思ってあらためてクラスタの構成を確認してみた。
Rayクラスタ
Rayクラスタは、単一のヘッドノードと、任意の数の接続されたワーカーノードで構成されます。
2つのワーカーノードを持つRayクラスタ。各ノードは、分散スケジューリングとメモリ管理を促進するRayヘルパープロセスを実行する。ヘッドノードでは、追加の制御プロセス(青で強調表示)が実行される。
referred from https://docs.ray.io/en/latest/cluster/key-concepts.htmlRayクラスタの設定で指定したアプリケーションの需要に応じて、ワーカーノードの数を自動的にスケーリングすることができます。 ヘッドノードがオートスケーラーを実行します。
ユーザーはRayクラスタ上でジョブを実行するように指示したり、ヘッドノードに接続して
ray.initを実行することで、対話的にクラスタを使用することができます。詳細はRayジョブをご覧ください。ヘッドノード
すべての Ray クラスタには、クラスタのヘッドノードとして指定されたノードが1つあります。ヘッドノードは、オートスケーラー、GCS、Ray ジョブを実行する Ray ドライバープロセスなど、クラスター管理を担当するシングルプロセスも実行している点を除いて、他のワーカーノードと同一です。Rayは、他のワーカーノードと同様に、ヘッドノード上でタスクやアクターをスケジューリングすることがあります。これは大規模クラスターでは望ましくありません。大規模クラスターにおけるベストプラクティスについては、「ヘッドノードの設定」を参照してください。
ワーカーノード
ワーカーノードは、ヘッドノードの管理プロセスを実行せず、Rayタスクやアクター内のユーザーコードの実行のみを担当します。また、分散スケジューリングに参加し、クラスターメモリー内のRayオブジェクトの保存と配布も行います。

ふむ、Kubernetesのコントロールプレーン&ワーカーノードと同じような関係性だと考えれば良さそう。
ということで、まず1つ目の、ヘッドpod上でRayジョブを動かす方法。
ヘッドpodを確認
export HEAD_POD=$(kubectl get pods --selector=ray.io/node-type=head -o custom-columns=POD:metadata.name --no-headers)
echo $HEAD_POD
raycluster-kuberay-head-t9d5l
ヘッドpod上でコマンドを実行。以下はクラスタリソースを表示するコマンド。
kubectl exec -it $HEAD_POD -- python -c "import ray; ray.init(); print(ray.cluster_resources())"
2025-02-10 14:35:54,448 INFO worker.py:1405 -- Using address 127.0.0.1:6379 set in the environment variable RAY_ADDRESS
2025-02-10 14:35:54,448 INFO worker.py:1540 -- Connecting to existing Ray cluster at address: 10.244.0.6:6379...
2025-02-10 14:35:54,453 INFO worker.py:1715 -- Connected to Ray cluster. View the dashboard at http://10.244.0.6:8265
{'node:__internal_head__': 1.0, 'CPU': 2.0, 'node:10.244.0.6': 1.0, 'object_store_memory': 762132479.0, 'memory': 3000000000.0, 'node:10.244.0.7': 1.0}
次にもう1つの、ray job submission SDKを使ってRayクラスタにRayジョブを投入する方法。こちらはRayがジョブリクエストを受け付けているダッシュボードポート(デフォルトは8265)経由でRayクラスタにジョブを投入する。このためにKubeRay operatorはヘッドpod向けのkubernetesのserviceを設定してくれる。
kubectl get service raycluster-kuberay-head-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
raycluster-kuberay-head-svc ClusterIP None <none> 10001/TCP,8265/TCP,8080/TCP,6379/TCP,8000/TCP 92m
ポートフォワードする
kubectl port-forward service/raycluster-kuberay-head-svc 8265:8265
別のターミナルからジョブを投入する。Ray CoreのクイックスタートでインストールしたパッケージにCLIが含まれているのでそれを使う。
uv run ray --help
Usage: ray [OPTIONS] COMMAND [ARGS]...
Options:
--logging-level TEXT The logging level threshold, choices=['debug',
'info', 'warning', 'error', 'critical'],
default='info'
--logging-format TEXT The logging format.
default="%%(asctime)s\t%%(levelname)s
%%(filename)s:%%(lineno)s -- %%(message)s"
--version Show the version and exit.
--help Show this message and exit.
Commands:
attach Create or attach to a SSH session to a Ray cluster.
check-open-ports Check open ports in the local Ray cluster.
cluster-dump Get log data from one or more nodes.
cpp Show the cpp library path and generate the bazel...
dashboard Port-forward a Ray cluster's dashboard to the...
debug Show all active breakpoints and exceptions in the...
disable-usage-stats Disable usage stats collection.
down Tear down a Ray cluster.
enable-usage-stats Enable usage stats collection.
exec Execute a command via SSH on a Ray cluster.
get Get a state of a given resource by ID.
get-head-ip Return the head node IP of a Ray cluster.
get-worker-ips Return the list of worker IPs of a Ray cluster.
install-nightly Install the latest wheels for Ray.
job Submit, stop, delete, or list Ray jobs.
list List all states of a given resource.
logs Get logs based on filename (cluster) or resource...
memory Print object references held in a Ray cluster.
metrics
microbenchmark Run a local Ray microbenchmark on the current...
monitor Tails the autoscaler logs of a Ray cluster.
rsync-down Download specific files from a Ray cluster.
rsync-up Upload specific files to a Ray cluster.
stack Take a stack dump of all Python workers on the...
start Start Ray processes manually on the local machine.
status Print cluster status, including autoscaling info.
stop Stop Ray processes manually on the local machine.
submit Uploads and runs a script on the specified cluster.
summary Return the summarized information of a given...
timeline Take a Chrome tracing timeline for a Ray cluster.
up Create or update a Ray cluster.
uv run ray job submit --address http://localhost:8265 -- python -c "import ray; ray.init(); print(ray.cluster_resources())"
のだが・・・
RuntimeError: The Ray jobs CLI & SDK require the ray[default] installation: `pip install 'ray[default]'`
どうもextrasの指定が必要な様子。パッケージを再インストール。
uv pip install -U ray[default]
再度実施
uv run ray job submit --address http://localhost:8265 -- python -c "import ray; ray.init(); print(ray.cluster_resources())"
ob submission server address: http://localhost:8265
-------------------------------------------------------
Job 'raysubmit_Gyy2XyPbgsSgFspM' submitted successfully
-------------------------------------------------------
Next steps
Query the logs of the job:
ray job logs raysubmit_Gyy2XyPbgsSgFspM
Query the status of the job:
ray job status raysubmit_Gyy2XyPbgsSgFspM
Request the job to be stopped:
ray job stop raysubmit_Gyy2XyPbgsSgFspM
Tailing logs until the job exits (disable with --no-wait):
2025-02-10 14:47:32,528 INFO worker.py:1405 -- Using address 10.244.0.6:6379 set in the environment variable RAY_ADDRESS
2025-02-10 14:47:32,528 INFO worker.py:1540 -- Connecting to existing Ray cluster at address: 10.244.0.6:6379...
2025-02-10 14:47:32,532 INFO worker.py:1715 -- Connected to Ray cluster. View the dashboard at http://10.244.0.6:8265
{'CPU': 2.0, 'node:10.244.0.6': 1.0, 'object_store_memory': 762132479.0, 'memory': 3000000000.0, 'node:__internal_head__': 1.0, 'node:10.244.0.7': 1.0}
------------------------------------------
Job 'raysubmit_Gyy2XyPbgsSgFspM' succeeded
------------------------------------------
今度はうまくいったみたい。
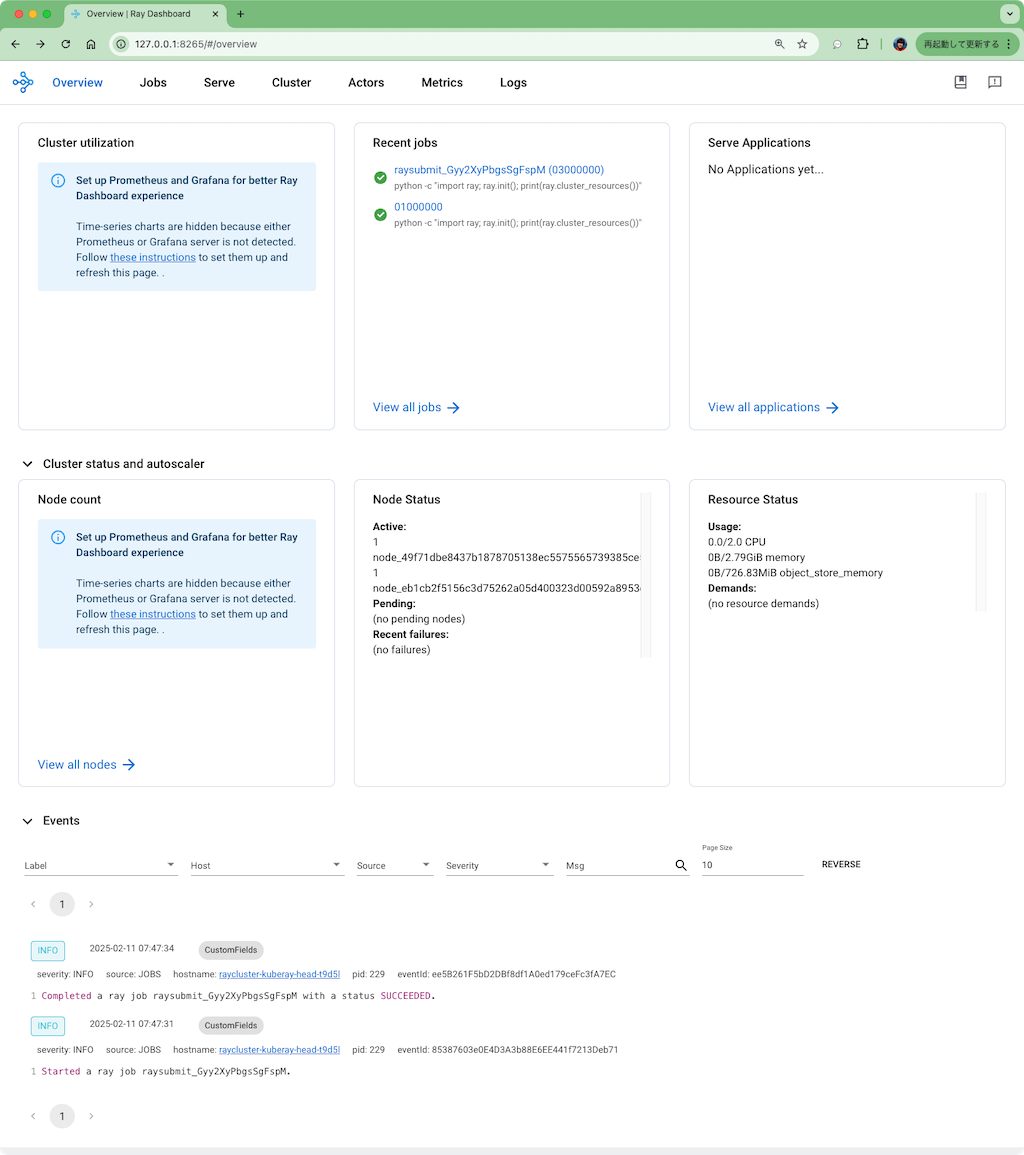
上で書いた通りジョブの投入先ポートはダッシュボード用でもあるので、ブラウザでアクセスすることができ、先程のジョブ実行結果などが確認できる様子。

ドキュメントにはお片付けの手順も記載されている。
ここまでのまとめ
実際のユースケース的なところまではピンときていないが、とりあえず雰囲気的なものはなんとなく感じたので、冒頭でリストアップしたRayのいろいろな記事をあらためて見直してみようと思う。
あと以下にユースケース別のサンプルがあるので、このあたりを参考にするのも良さそう。
とりあえず次はRay Serveでモデル推論環境のデプロイを試す。
Ray Serve
Ray Serveは、オンライン推論APIを構築するためのスケーラブルなモデル提供ライブラリです。Serveはフレームワークに依存しないため、PyTorch、TensorFlow、Kerasなどのフレームワークで構築されたディープラーニングモデルから、Scikit-Learnモデル、任意のPythonビジネスロジックまで、単一のツールキットですべてを提供できます。レスポンスストリーミング、動的リクエストバッチ処理、マルチノード/マルチGPU提供など、大規模言語モデルを提供する際に役立つ機能やパフォーマンス最適化がいくつかあります。
Ray Serveは特にモデルの構成化や多数のモデルの提供に適しており、複数のMLモデルとビジネスロジックから構成される複雑な推論サービスをすべてPythonコードで構築できます。
Ray ServeはRayの上に構築されているため、簡単に多数のマシンにスケールし、GPUの小数点以下単位など柔軟なスケジューリングのサポートを提供します。これにより、リソースを共有し、多数の機械学習モデルを低コストで提供できます。
ということでQuick Start。まずはローカルのMacで。
作業ディレクトリを作成してPython仮想環境を作成。最近はuvを使っている。
mkdir ray-serve-work && cd ray-serve-work
uv venv -p 3.12.8
パッケージインストール
uv pip install "ray[serve]"
Installed 60 packages in 124ms
(snip)
+ ray==2.42.1
(snip)
hello worldなサンプルアプリ
import requests
from starlette.requests import Request
from typing import Dict
from ray import serve
# 1: `@serve.deployment`デコレータで、Ray Serveアプリケーションを定義
@serve.deployment
class MyModelDeployment:
def __init__(self, msg: str):
# モデルの状態を初期化: 非常に大きなニューラルネットの重みをロードするなど。
self._msg = msg
async def __call__(self, request: Request) -> Dict:
# モデルの推論を実行
return {"result": self._msg}
app = MyModelDeployment.bind(msg="ハロー、ワールド!")
# 2: アプリケーションをローカルにデプロイ
serve.run(app, route_prefix="/")
# 3: アプリケーションにクエリを送信し、結果を表示
print(requests.get("http://localhost:8000/").json())
実行
uv run ray_serve_hello_world.py
2025-02-13 01:06:43,722 INFO worker.py:1832 -- Started a local Ray instance. View the dashboard at http://127.0.0.1:8265
INFO 2025-02-13 01:06:44,721 serve 38242 -- Started Serve in namespace "serve".
(ProxyActor pid=38260) INFO 2025-02-13 01:06:44,689 proxy 127.0.0.1 -- Proxy starting on node f3f06ce509ad578be60c16e35b7c4a256c0486788c55e797d80b7166 (HTTP port: 8000).
(ProxyActor pid=38260) INFO 2025-02-13 01:06:44,718 proxy 127.0.0.1 -- Got updated endpoints: {}.
(ServeController pid=38259) INFO 2025-02-13 01:06:44,745 controller 38259 -- Deploying new version of Deployment(name='MyModelDeployment', app='default') (initial target replicas: 1).
(ProxyActor pid=38260) INFO 2025-02-13 01:06:44,746 proxy 127.0.0.1 -- Got updated endpoints: {Deployment(name='MyModelDeployment', app='default'): EndpointInfo(route='/', app_is_cross_language=False)}.
(ProxyActor pid=38260) INFO 2025-02-13 01:06:44,749 proxy 127.0.0.1 -- Started <ray.serve._private.router.SharedRouterLongPollClient object at 0x10cd97440>.
(ServeController pid=38259) INFO 2025-02-13 01:06:44,847 controller 38259 -- Adding 1 replica to Deployment(name='MyModelDeployment', app='default').
INFO 2025-02-13 01:06:45,839 serve 38242 -- Application 'default' is ready at http://127.0.0.1:8000/.
INFO 2025-02-13 01:06:45,839 serve 38242 -- Deployed app 'default' successfully.
{'result': 'ハロー、ワールド!'}
(ServeReplica:default:MyModelDeployment pid=38254) INFO 2025-02-13 01:06:45,864 default_MyModelDeployment s69qbh4p 00b98aaa-c9db-444b-b28a-1532ac2f1985 -- GET / 200 2.5ms
ログを見る限り、インスタンス作成→アプリデプロイ→リクエストして結果取得、という流れに見える、なるほど。
その他の例として、
- 複数のRay Serveアプリケーションを定義してデプロイ
- FastAPIアプリをデプロイ
- Transformerモデルをデプロイして感情分析
などが記載されている。
Getting Started
Quickstartはほんの触りのようなので、Getting Startedでより細かいところを見ていく。以下のような流れになっている。
- 機械学習モデルをRay Serveのデプロイメントに変換する
- Ray ServeアプリケーションをHTTP経由でローカルにテストする
- 複数の機械学習モデルを一つのアプリケーションにまとめる
- TransformersのPipelineで翻訳と要約を行う
せっかくモデル推論環境も提供できるならGPU環境でやりたい、ということで、以下の環境で試すこととする。
- Ubuntu-22.04
- RTX4090
- CUDA-12.6
環境作成は上と同じ。
mkdir ray-serve-work && cd ray-serve-work
uv venv -p 3.12.8
CLIの操作もあるので、説明の簡単のため、今回はactivateして進める。
source .venv/bin/activate
パッケージインストール
pip install "ray[serve]" transformers requests torch
Installed 89 packages in 3.02s
(snip)
+ ray==2.42.1
(snip)
+ requests==2.32.3
(snip)
+ torch==2.6.0
(snip)
+ transformers==4.48.3
(snip)
まず、Ray Serveを使わずに、モデルを使って「翻訳」を行うコード。
import torch
from transformers import pipeline
class Translator:
def __init__(self):
self.model = pipeline(
"text-generation",
model="google/gemma-2-2b-jpn-it",
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
def translate(self, text: str) -> str:
messages = [
{"role": "user", "content": f"次の英文を日本語に翻訳しなさい: {text}"},
]
outputs = self.model(messages, return_full_text=False, max_new_tokens=1024)
translation = outputs[0]["generated_text"].strip()
return translation
translator = Translator()
translation = translator.translate("Hello world!")
print(translation)
実行。
python model.py
こんにちは世界!
これをRay Serveアプリにするためには以下のように変更する。別ファイルにしてある。
from starlette.requests import Request
import ray
from ray import serve
import torch
from transformers import pipeline
# `@serve.deployment`デコレータでTranslatorクラスをRay Serveの
# デプロイメント(Deploymentオブジェクト)に変換
@serve.deployment(
# デプロイメントのプロセス数を指定。リクエストはこの数のプロセスに分散される。
num_replicas=2,
# 各レプリカの設定オプション
# - num_cpus: 各レプリカが予約するCPUの論理個数。少数点で指定。
# - num_gpus: 各レプリカが予約するGPUの論理個数。少数点で指定。
# - resources: CPU/GPU以外のリソースを指定する場合に使用
ray_actor_options={"num_cpus": 0.2, "num_gpus": 0}
)
class Translator:
def __init__(self):
self.model = pipeline(
"text-generation",
model="google/gemma-2-2b-jpn-it",
model_kwargs={"torch_dtype": torch.bfloat16},
#device="cuda" # デコレータが処理するのでこの指定は不要
)
def translate(self, text: str) -> str:
messages = [
{"role": "user", "content": f"次の英文を日本語に翻訳しなさい: {text}"},
]
outputs = self.model(messages, return_full_text=False, max_new_tokens=1024)
translation = outputs[0]["generated_text"].strip()
return translation
# デプロイメントはStarletteのRequestオブジェクトを受け取り、
# この __call__メソッドが呼ばれる。
# JSON形式のデータを受け取り、translateメソッドに転送して、リクエストを処理する
async def __call__(self, http_request: Request) -> str:
english_text: str = await http_request.json()
return self.translate(english_text)
# デプロイメントと引数をバインドして、Ray Serveアプリケーションとして定義
translator_app = Translator.bind()
Ray Serveのデプロイメントは、クラスをラップしてJSONリクエストを受信できるHTTP APIサーバのプロセスを起動するようなイメージ。なので、
-
@serve.deploymentデコレータをクラスに付与して、デプロイメントオブジェクトに変換。- ここで渡すパラメータで、いくつのプロセスを立ち上げるのか、CPU/GPUなどのリソースをどれぐらい割り当てるのか、などを設定できる
- デプロイメントオブジェクトにはHTTPリクエストを受信して処理にルーティングさせるための
__call__メソッドを追加する必要がある - 最後にデプロイメントに、クラスのコンストラクタに渡す引数を
bind()して、Ray Serveアプリケーションとして定義する
という変更になる。
これを実行するにはserve runコマンドを使う。serve runコマンドは、モジュール:アプリケーションを引数として取るので、今回の場合だとserve_quickstart:translator_appとなる。
serve run serve_quickstart:translator_app
2025-02-13 11:41:00,852 INFO scripts.py:494 -- Running import path: 'serve_quickstart:translator_app'.
/work/ray-serve-work/.venv/lib/python3.12/site-packages/transformers/utils/hub.py:128: FutureWarning: Using `PYTORCH_TRANSFORMERS_CACHE` is deprecated and will be removed in v5 of Transformers. Use `HF_HOME` instead.
warnings.warn(
2025-02-13 11:41:02,889 INFO worker.py:1832 -- Started a local Ray instance. View the dashboard at http://127.0.0.1:8265
INFO 2025-02-13 11:41:03,931 serve 2775552 -- Started Serve in namespace "serve".
INFO 2025-02-13 11:41:03,931 serve 2775552 -- Connecting to existing Serve app in namespace "serve". New http options will not be applied.
(ProxyActor pid=2775897) INFO 2025-02-13 11:41:03,905 proxy 192.168.XX.XX -- Proxy starting on node f33bc67185abb04361806b4e5a018d717e60d21ecd374df99fb69968 (HTTP port: 8000).
(ProxyActor pid=2775897) INFO 2025-02-13 11:41:03,926 proxy 192.168.XX.XX -- Got updated endpoints: {}.
(ServeController pid=2775894) INFO 2025-02-13 11:41:03,970 controller 2775894 -- Deploying new version of Deployment(name='Translator', app='default') (initial target replicas: 2).
(ProxyActor pid=2775897) INFO 2025-02-13 11:41:03,974 proxy 192.168.XX.XX -- Got updated endpoints: {Deployment(name='Translator', app='default'): EndpointInfo(route='/', app_is_cross_language=False)}.
(ProxyActor pid=2775897) INFO 2025-02-13 11:41:04,000 proxy 192.168.XX.XX -- Started <ray.serve._private.router.SharedRouterLongPollClient object at 0x73c4841ea960>.
(ServeController pid=2775894) INFO 2025-02-13 11:41:04,076 controller 2775894 -- Adding 2 replicas to Deployment(name='Translator', app='default').
(ServeReplica:default:Translator pid=2775899) /work/ray-serve-work/.venv/lib/python3.12/site-packages/transformers/utils/hub.py:128: FutureWarning: Using `PYTORCH_TRANSFORMERS_CACHE` is deprecated and will be removed in v5 of Transformers. Use `HF_HOME` instead.
(ServeReplica:default:Translator pid=2775899) warnings.warn(
Downloading shards: 100%|██████████| 2/2 [00:00<00:00, 26800.66it/s]
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
Loading checkpoint shards: 100%|██████████| 2/2 [00:00<00:00, 13.15it/s]
(ServeReplica:default:Translator pid=2775899) Device set to use cpu
INFO 2025-02-13 11:41:07,048 serve 2775552 -- Application 'default' is ready at http://127.0.0.1:8000/.
INFO 2025-02-13 11:41:07,048 serve 2775552 -- Deployed app 'default' successfully.
デプロイメントが起動して、http://127.0.0.1:8000/ で待ち受けるようになる。
これにアクセスしてみる。
curl -X POST http://127.0.0.1:8000/ \
-H "Content-Type: application/json" \
-d '"It'\''s a beautiful day today. It'\''s perfect for watching horse racing."'
今日は美しい日ですね。馬レースを見るのに最適な日です。
Pythonでも。
import requests
english_text = "It's a beautiful day today. It's perfect for watching horse racing."
response = requests.post("http://127.0.0.1:8000/", json=english_text)
japanese_text = response.text
print(japanese_text)
python model_client.py
今日は美しい日ですね。馬レースを見るのに最適な日です。
複数のデプロイメントを1つのRay Serveアプリケーションとして構成してデプロイすることもできる。
まず、Ray Serveを使わずに、モデルを使って「要約」を行うコード。
import torch
from transformers import pipeline
class Summarizer:
def __init__(self):
self.model = pipeline(
"text-generation",
model="google/gemma-2-2b-jpn-it",
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
def summarize(self, text: str) -> str:
messages = [
{"role": "user", "content": f"次の文章を簡潔に要約しなさい: {text}"},
]
outputs = self.model(messages, return_full_text=False, max_new_tokens=1024)
summary = outputs[0]["generated_text"].strip()
return summary
summarizer = Summarizer()
# ref: wikipedia: オグリキャップ
# https://ja.wikipedia.org/wiki/%E3%82%AA%E3%82%B0%E3%83%AA%E3%82%AD%E3%83%A3%E3%83%83%E3%83%97
text = """\
オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。
1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、
1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。1988年度のJRA賞最優秀4歳牡馬、
1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬。1991年、JRA顕彰馬
に選出。愛称は「オグリ」「芦毛の怪物」など多数。「スーパー・スター」と評された。
中央競馬時代はスーパークリーク、イナリワンの二頭とともに「平成三強」と総称され、自身と騎手である
武豊の活躍を中心として起こった第二次競馬ブーム期において、第一次競馬ブームの立役者とされる
ハイセイコーに比肩するとも評される高い人気を得た。その人気は競馬ファンのみならず一般の大衆にも
波及し、社会現象を巻き起こした。日本競馬史上において、特に人気を博した競走馬の一頭である。
"""
summary = summarizer.summarize(text)
print(summary)
python summary_model.py
オグリキャップは、日本の競走馬で、1987年に笠松競馬場でデビュー。中央競馬に移籍後、重賞12勝(うちGI4勝)を記録し、1991年にはJRA顕彰馬に選出された。 「平成三強」の一員として、第二次競馬ブーム期に高い人気を博し、社会現象を巻き起こした。
これをRay Serveのデプロイメントに変換して、先ほどの翻訳とも組み合わせて、
- 英文を要約
- 英文を日本語に翻訳
というパイプラインのRay Serveアプリケーションにする。
from starlette.requests import Request
import ray
from ray import serve
# 他のデプロイメントと通信するためのハンドルであるDeploymentHandleをインポート
from ray.serve.handle import DeploymentHandle
import torch
from transformers import pipeline
# 翻訳機能を提供するTranslatorクラス
@serve.deployment(ray_actor_options={"num_cpus": 0.2, "num_gpus": 0.2})
class Translator:
def __init__(self):
self.model = pipeline(
"text-generation",
model="google/gemma-2-2b-jpn-it",
model_kwargs={"torch_dtype": torch.bfloat16}
)
def translate(self, text: str) -> str:
messages = [
{"role": "user", "content": f"次の英文を日本語に翻訳しなさい: {text}"},
]
outputs = self.model(messages, return_full_text=False, max_new_tokens=1024)
translation = outputs[0]["generated_text"].strip()
return translation
# 要約機能を提供するSummarizerクラス
@serve.deployment(ray_actor_options={"num_cpus": 0.2, "num_gpus": 0.2})
class Summarizer:
# コンストラクタでTranslatorをDeploymentHandleとして受け取る
def __init__(self, translator: DeploymentHandle):
# Translatorのハンドルを保持
self.translator = translator
self.model = pipeline(
"text-generation",
model="google/gemma-2-2b-jpn-it",
model_kwargs={"torch_dtype": torch.bfloat16}
)
def summarize(self, text: str) -> str:
messages = [
{"role": "user", "content": f"次の文章を簡潔に要約しなさい: {text}"},
]
outputs = self.model(messages, return_full_text=False, max_new_tokens=1024)
summary = outputs[0]["generated_text"].strip()
return summary
# HTTPリクエストを処理するメインのエントリーポイント
async def __call__(self, http_request: Request) -> str:
english_text: str = await http_request.json()
# テキストを要約
summary = self.summarize(english_text)
# remote()で、他のデプロイメントのメソッドを非同期で呼び出すことができる。
# ここでは、要約結果をTranslatorデプロイメントに渡して翻訳
translation = await self.translator.translate.remote(summary)
return translation
# Translatorをコンストラクタの引数としてバインドし、それをSummarizerのコンストラクタ引数としてバインドする。
# これにより、要約と翻訳がつながるグラフとなる
app = Summarizer.bind(Translator.bind())
翻訳のRay Serveアプリに、要約をデプロイメントして追加し、いくつか修正している。
-
__call__は、Ray Serveアプリのリクエストを受けるエントリーポイントとなるので、複数デプロイメントがある場合にはどれか1つに実装する。今回は要約側のデプロイメントがこれを受け持つ。 - デプロイメントから別のデプロイメントを呼ぶには
DeploymentHandleを使う- 要約デプロイメントに、翻訳デプロイメントを
DeploymentHandleとして渡すことで、要約デプロイメントの中から翻訳デプロイメントを呼び出すことができるようになる - 別のデプロイメントを呼び出す場合には
remote()メソッドで非同期で呼び出す
- 要約デプロイメントに、翻訳デプロイメントを
- 最後に、依存するデプロイメントをまずバインドして、それをさらにデプロイメントにバインドして、アプリケーションとして定義する
という感じ。
ではこれを実行。
serve run serve_quickstart_composed:app
アクセスしてみる。
import requests
# ref: wikipedia - Oguri Cap
# https://en.wikipedia.org/wiki/Oguri_Cap
text = """\
Oguri Cap (Japanese : オグリキャップ, 27 March 1985 – 3 July 2010) was a Japanese thoroughbred racehorse,
sired by Dancing Cap. Oguri Cap was inducted into the Japan Racing Association Hall of Fame in 1991.
In May 1987 Oguri Cap made his debut at Kasamatsu Racecourse in Gifu Prefecture. After winning 9 starts
in 11 races, including 7 consecutive victories and 4 stakes wins, he was transferred to the ownership
of Chuo Horse Racing inJanuary 1988 and recorded 13 more wins including four Grade I stakes, two Grade
II stakes, and four Grade III stakes. Some of his biggest wins include the Mile Championship (G1),
2 wins in the Arima Kinen (Grand Prix) (G1), and a win in the Yasuda Kinen (G1). He also racked up
victories in the New Zealand Trophy (G2), Takamatsunomiya Kinen (G2), and 2 wins in the Mainichi Ōkan (G2).
In 1988 Oguri Cap won JRA Best Three-Year-Old Colt and in 1990 he won JRA Best Older Male Horse and
Japanese Horse of the Year. Nicknames include "Oguri" and the "Grey-Haired Monster".
"""
response = requests.post("http://127.0.0.1:8000/", json=text)
result = response.text
print(result)
python model_client.py
結果。ちょっとイマイチだけど、小さめのモデルなのでしょうがないかも。
**おぐり・カプ**は、1985年から2010年まで活躍した日本の Thoroughbred馬です。
彼は、9勝を含む7連勝と4つのステークス勝利を記録した後、1988年にChuo Horse Racingの所有者に移籍しました。その後、Grade Iステークスを含む13勝を記録しました。彼の主な勝利には、Mile Championship (G1)、Arima Kinen (G1)の2勝、Yasuda Kinen (G1)の勝利などがあります。
1988年にはJRA Best Three-Year-Old Colt、1990年にはJRA Best Older Male Horse、そして日本馬の年間最優秀馬に輝きました。
ログを見ると要約・翻訳がそれぞれ実行されていて、パイプラインが機能していることがわかる。
(ServeReplica:default:Summarizer pid=2790740) INFO 2025-02-13 12:56:00,728 default_Summarizer 3vw3pe9o f276bf57-8d63-4f35-ace1-bd3fec8a184b -- POST / 200 4056.5ms
(ServeReplica:default:Translator pid=2790736) INFO 2025-02-13 12:56:00,727 default_Translator n9vvubnr f276bf57-8d63-4f35-ace1-bd3fec8a184b -- CALL / OK 2037.6ms
デプロイメントの構成についてより詳しくは以下
Ray Serveアプリケーションの本番環境Rayクラスターへのデプロイについては以下
ざっと見た感じ
- Ray Serveアプリケーションのコードを書く
-
serve runでローカルで起動してテスト
-
- Ray Serveアプリコードから設定ファイルを生成
-
serve buildで、アプリコードからデプロイ用設定ファイルを生成する
-
- Rayクラスタにデプロイ
-
serve deployで設定ファイルとコードをデプロイ
-
という感じっぽい。
上で作成したRay Serveアプリケーションから設定ファイルを生成してみる。
serve build serve_quickstart_composed:app -o serve_config.yaml
2025-02-13 13:07:55,484 INFO scripts.py:840 -- The auto-generated application names default to `app1`, `app2`, ... etc. Rename as necessary.
生成されたファイルはこんな感じ。実際にはなんか空行が無駄に多い感じで出力されたので、説明の簡単のためちょっと編集した。
# This file was generated using the `serve build` command on Ray v2.42.1.
proxy_location: EveryNode
http_options:
host: 0.0.0.0
port: 8000
grpc_options:
port: 9000
grpc_servicer_functions: []
logging_config:
encoding: TEXT
log_level: INFO
logs_dir: null
enable_access_log: true
applications:
- name: app1
route_prefix: /
import_path: serve_quickstart_composed:app
runtime_env: {}
deployments:
- name: Translator
ray_actor_options:
num_cpus: 0.2
num_gpus: 0.2
- name: Summarizer
ray_actor_options:
num_cpus: 0.2
num_gpus: 0.2
今回のコードだとTransformersやPyTorchなどの依存パッケージがあるのだけど、このあたりは自分で追記する必要がある様子。
(snip)
runtime_env:
pip:
- torch==2.6.0
- transformers==4.48.3
(snip)
Rayクラスタは上の方でやった時にクラウドかKubernetesが必要だと思ってのだけど、CLIでローカルクラスタを起動することができるみたい?
ray start --head
使用状況を共有するかを確認される。嫌なら10秒以内に止めないと有効になるらしい・・・。まあ、--disable-usage-statsで無効化できるのだけど。
Enable usage stats collection? This prompt will auto-proceed in 10 seconds to avoid blocking cluster startup. Confirm [Y/n]: Y
こんな感じで起動したみたい。
Local node IP: 192.168.XX.XX
--------------------
Ray runtime started.
--------------------
Next steps
To add another node to this Ray cluster, run
ray start --address='192.168.XX.XX:6379'
To connect to this Ray cluster:
import ray
ray.init()
To submit a Ray job using the Ray Jobs CLI:
RAY_ADDRESS='http://127.0.0.1:8265' ray job submit --working-dir . -- python my_script.py
See https://docs.ray.io/en/latest/cluster/running-applications/job-submission/index.html
for more information on submitting Ray jobs to the Ray cluster.
To terminate the Ray runtime, run
ray stop
To view the status of the cluster, use
ray status
To monitor and debug Ray, view the dashboard at
127.0.0.1:8265
If connection to the dashboard fails, check your firewall settings and network configuration.
では先ほどのRay Serveアプリをデプロイしてみる。
serve deploy serve_config.yaml
2025-02-13 13:24:23,561 INFO scripts.py:252 -- Deploying from import path: 'serve_config.yaml'.
2025-02-13 13:24:23,567 SUCC scripts.py:346 --
Sent deploy request successfully.
* Use `serve status` to check applications' statuses.
* Use `serve config` to see the current application config(s).
serve statusで確認。
serve status
proxies:
34589d6b90945aa3cee5db4dcebf4da0171a7fc59513b368379507ef: HEALTHY
applications:
app1:
status: DEPLOYING
message: ''
last_deployed_time_s: 1739422353.1517043
deployments: {}
target_capacity: null
しばらく待っていると変わる。以下のような感じになればOKっぽい。
proxies:
34589d6b90945aa3cee5db4dcebf4da0171a7fc59513b368379507ef: HEALTHY
applications:
app1:
status: RUNNING
message: ''
last_deployed_time_s: 1739422353.1517043
deployments:
Translator:
status: HEALTHY
status_trigger: CONFIG_UPDATE_COMPLETED
replica_states:
RUNNING: 1
message: ''
Summarizer:
status: HEALTHY
status_trigger: CONFIG_UPDATE_COMPLETED
replica_states:
RUNNING: 1
message: ''
target_capacity: null
1つ前で使ったクライアントスクリプトで試してレスポンスが変えればOK。
python model_client.py
**おぐり・カプ**は、1985年から2010年まで活躍した日本の Thoroughbred馬です。
彼は、9勝を含む7連勝と4つのステークス勝利を記録した後、1988年にChuo Horse Racingの所有者に移籍しました。その後、Grade Iステークスを含む13勝を記録しました。彼の主な勝利には、Mile Championship (G1)、Arima Kinen (G1)の2勝、Yasuda Kinen (G1)の勝利などがあります。
1988年にはJRA Best Three-Year-Old Colt、1990年にはJRA Best Older Male Horse、そして日本馬の年間最優秀馬に輝きました。
サラッと成功したように見えているが、デプロイが成功するまでには少し手こずった。これは自分の環境起因だと思うけど、一応メモ。
- デプロイされるRay Serveアプリケーションも仮想環境を作成して実行しているようで、"No module named pip"とかデプロイ失敗した。
- 確認してみたらuvで作った仮想環境の中にpipが存在しておらず(pipコマンドがなく、おそらく自分が実行してたのはpyenvのpipと思われる)、仮想環境内で
pip install -U pipした。 - もう少しuvを知らねばならぬ・・・
- 確認してみたらuvで作った仮想環境の中にpipが存在しておらず(pipコマンドがなく、おそらく自分が実行してたのはpyenvのpipと思われる)、仮想環境内で
- Transformers、PyTorchのバージョンを指定せずにデプロイしたらエラーになったのでバージョン指定した。
Could not find a version that satisfies the requirement transformer (from versions: none)
まとめ
発端は、以下のポスト。
これを見て、Kubernetes上にLLMアプリなりモデルエンドポイントをデプロイできるようなフレームワーク的なものは他にないのかなー?ということで、いろいろ調べてて見つけたのが今回のRayだった。新しいフレームワークなのかな?と思ったけど、MLOps的なアプローチで実は数年前からすでに存在していたみたい。
ボリュームがあるので、当然全部試すことはできていないのだけど、うまく使えば、データセットの作成、モデルの学習・チューニング、モデル推論や汎用Pythonアプリの(分散)実行環境、なんかをオールインワンで、かつ、Kubernetes上でスケーラブルな環境構築ができる、のかもしれないね。
ただそれなりに学習コストは高そうではある。
あと、自分はマルチエージェントの実行環境としてKubernetesへのデプロイ、というのが頭にあるのだけど、ここまで触った限りの印象だとそういうより複雑なコントロールフローにはまだ想定されていない印象を持った。
マルチエージェントの場合、各エージェントやRAGやコード実行等のコンポーネントは個々にデプロイするのが良いと思うので、これはRayでもできると思う。ただ、それらをフローとして制御するコントローラ的なものが必要になる。この部分については、上で見たようなRay Serveのアプリケーションコードだとちょっと不便かもしれなくて、LangGraphやLlamaIndex Workflowみたいなフレームワークのほうが向いているように思う。このあたりの、LLMエージェントアプリの構成・コード・デプロイをシームレスに組み合わせたものがあればなー、と感じていて、Rayについてはアプリケーション部分がやや足りないと言うか、見てるレイヤーが下な印象を持っている。
以下の記事(ちゃんと読んでいないが)のように、学習・チューニング→モデル実行環境、まではいいと思うけど、より複雑なアプリケーションまではカバーできないかなというところ。やってやれなくはないと思うけど、シームレスではなくなりそう。
上のポストにある通り、「LLM deployment」であって「LLM App deployment」にはまだ遠い感。
もう少し調べてみるか。