Ray on Vertex AI 入門
はじめに
こんにちは、クラウドエース データソリューション部の松本です。
普段は、データ基盤や MLOps を構築したり、Google Cloud 認定トレーナーとしてトレーニングを提供しております。
クラウドエース データソリューション部 について
クラウドエースのITエンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
今回は、Google Cloud の Vertex AI サービスの1つである Ray on Vertex AI についてご紹介いたします。
この記事はこんな人にオススメ
- Ray とは何かについて知りたい
- Ray on Vertex AI について知りたい
- LLM を含む機械学習ワークロードの実行基盤を検討している
Ray とは
Ray とは、機械学習ワークロードなどでのスケーリングを目的とした Python における並列分散処理のフレームワークです。Python の標準ライブラリとして、並列処理が可能な multiprocessing がありますが、これに比べて簡単に並列処理を Python ネイティブなコードで記述することができます。また、複数スレッド、複数コア、複数サーバでの実行が可能です。
Ray の利点
Ray の主な利点は以下の通りです。
-
分散処理を簡単に実装できる
Ray は直感的なAPIを提供しており、既存の Python コードに対して@ray.remoteのデコレータを付与するだけで、分散処理が可能になります。これにより、開発者はアプリケーションのロジックに集中できます。 -
分散処理用コードへの書き換えコストを抑える
一般的に、分散処理を行いたい場合は Hadoop、Spark、Apache Beam などのフレームワークが使用されますが、使用時は既存の Python コードからの書き換えが必要になります。Rayでは、そういった書き換えコストを最小限に抑えることが可能です。 -
機械学習のための豊富な組み込みライブラリを提供
Rayは、後述する Ray Tune(ハイパーパラメータチューニング)、RLlib(強化学習ライブラリ)、Ray Serve(モデルサービング)など、機械学習のための豊富な組み込みライブラリを提供しています。 -
シームレスなスケーラビリティと柔軟性
Rayは、単一のマシンからクラウド上の大規模クラスターまで、シームレスにスケールアップすることが可能です。これにより、開発者はアプリケーションのスケールに応じて、必要な計算リソースを柔軟に確保できます。さらに、Ray は機械学習、データ処理、リアルタイムアプリケーションなど、幅広い分散コンピューティングのユースケースに対応しています。
Ray の構成要素
Ray の構成要素について説明します。
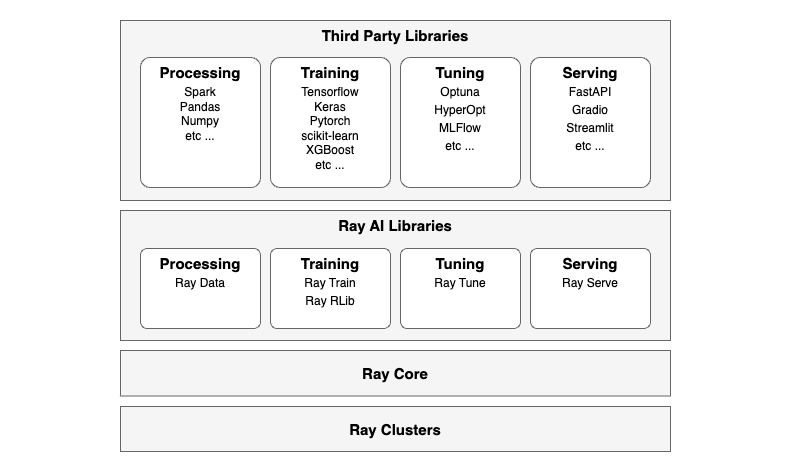
Ray の構成要素
Ray フレームワークは、以下のレイヤーで構成されています。
-
Ray Clusters: 複数の計算ノード(マシンまたはインスタンス)を組み合わせて構成されるクラスタです。ノード上で並行してタスクを実行することで、高いスケーラビリティとパフォーマンスを実現します。ワークロードを Google Cloud、AWS、Azure のクラウドやオンプレミスにデプロイでき、Ray クラスタ マネージャーを使用して、Kubernetes や YARN などのクラスタで Ray を実行します。
-
Ray Core: Rayフレームワークの基盤部分であり、分散実行エンジンの中核機能を提供します。Ray Core API を通じて分散実行エンジンにアクセスし、分散コンピューティングタスクを簡単に実装できます。
-
Ray AI Libraries: Ray Core で動作するライブラリであり、以下の機械学習ワークロード機能を提供します。また、Ray の API により Third Party Libraries の機械学習ライブラリやデータ処理ライブラリと簡単に統合できます。
Ray のクラスタ構成
Ray のクラスタ構成について説明します。
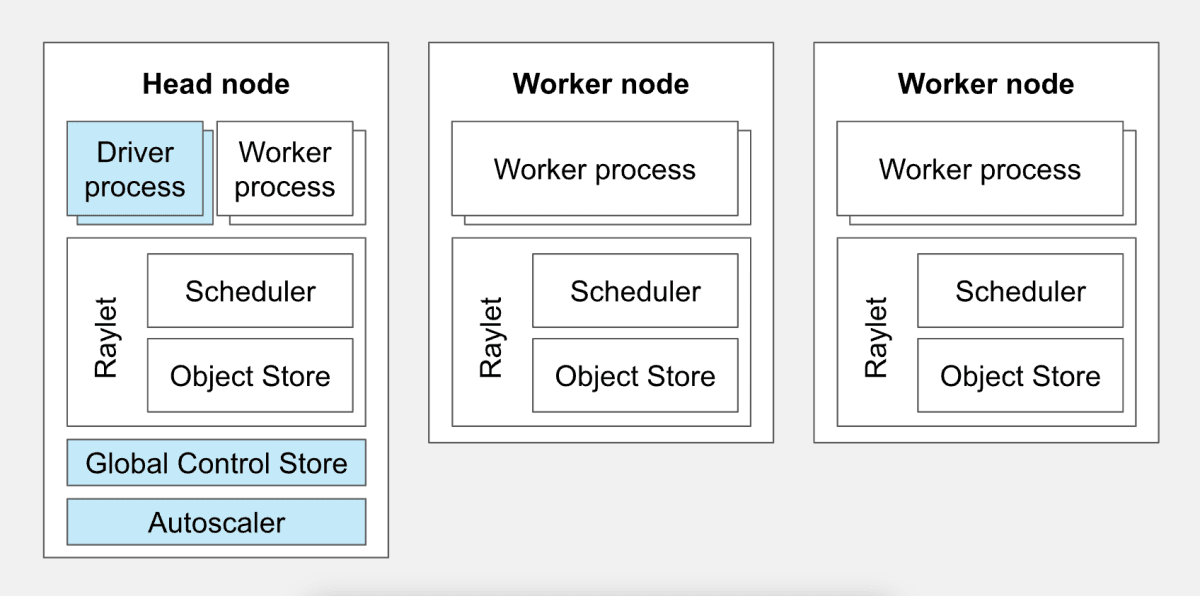
Ray のクラスタ構成
(出典:Ray Clusters Overview)
Ray クラスタを構成する個々のマシンまたはインスタンスを ノード (node) と呼びます。Ray のノードには ヘッドノード (Head node) と ワーカーノード (Worker node) が存在し、それぞれの役割は以下の通りです。
- ヘッドノード(Head node): Ray クラスタにおける管理ノードです。クラスタの管理、タスクのスケジューリング、リソースの割り当てなどの役割を担います。
- ワーカーノード(Worker node): 実際の計算タスクやデータ処理タスクを実行するためのノードです。クラスタ内のヘッドノードから割り当てられたタスクを受け取り、処理を実行します。
また、各ノードには以下の構成要素があります。
-
ノード(ヘッドノードまたはワーカーノード)
-
Worker process:Ray クラスタ上で実際にタスク(関数の実行)やアクター(状態を持つオブジェクトのインスタンス)の実行を行うプロセスです。 -
Raylet:Ray クラスタの各ノード上で動作するデーモンプロセスであり以下で構成されます。-
Scheduler:ノード上で実行されるタスクを管理およびスケジューリングします。 -
Object Store:Raylet 内で実行されるタスクによって生成されたデータ(オブジェクト)を管理します。
-
-
-
ヘッドノードのみ
-
Driver Process:コード内で定義されたタスクやアクターを Ray クラスタ上で分散実行するための指示を出します。 -
Global Control Store (GCS):クラスタのメタデータや状態情報を管理し、ノード間での情報共有を行います。 -
Autoscaler:処理負荷やタスクの量に応じて、必要に応じてワーカーノードを自動的にスケールアウトまたはスケールインし、使用するリソースを最適化します。
-
Ray Core API による分散処理
Ray Core API による分散処理について説明します。

Ray Core API による分散処理
Ray では以下の Ray Core API により分散処理を可能にします。
-
Tasks(タスク): 任意の Python 関数に対して
@ray.remoteのデコレータを適用することで、関数単位で非同期での分散処理が可能になります。このような関数はRay リモート関数と呼ばれ、その非同期呼び出しは Ray タスクと呼ばれます。 -
Actors(アクター): 任意の Python クラスに対して
@ray.remoteのデコレータを適用することで、オブジェクトをアクターとして分散処理が可能になります。アクターは、メソッド呼び出しを通じて非同期に操作でき、各アクターインスタンスは専用のプロセスで実行されます。これにより、複数のアクター間で状態を共有したり、並列にタスクを実行したりすることが可能になります。 -
Objects(オブジェクト): 任意のオブジェクト(データ)を
ray.putにより 特定ノードの Object Store に格納し、そのオブジェクトを別のノードからray.getにより参照することができます。これにより、オブジェクトをノード間で共有しながらの分散処理が可能です。なお、 Object Store 内のオブジェクトを共有する際は、ゼロコピー共有と呼ばれる 共有メモリ の仕組みが利用されます。
Ray のジョブ実行
Ray のジョブ実行について説明します。
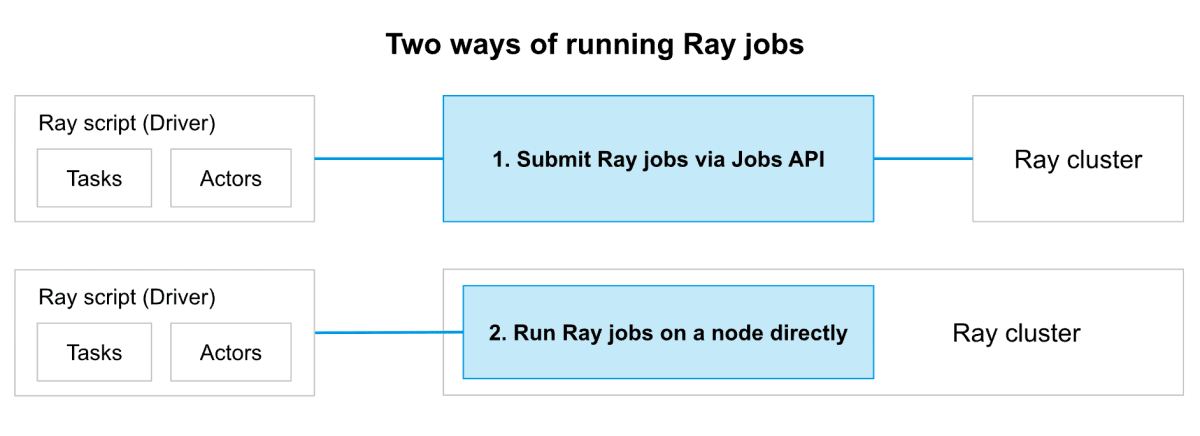
Ray クラスタにおけるジョブの実行方法
(出典:Ray Clusters Overview)
Ray クラスタで Ray ジョブを実行するには 以下の 2 つの方法があります。
- Ray Jobs API を使用してジョブを送信する(推奨)
- インタラクティブな開発のために、Ray クラスタの任意のノードでドライバー スクリプトを直接実行する
基本的には 1 の方法が推奨されており、Ray Jobs API によってジョブ送信や状態監視などのジョブ管理が容易になることや、リソースの過剰な割り当てや不足を避けてスケーラビリティを高めるなどのメリットがあるためです。
※ インタラクティブな開発をしたい場合は 2 の方法を選択する場合もありますが、本番環境や大規模な運用では、運用管理などの観点から 1 の方法の方が適しています。
Ray on Vertex AI とは
Ray on Vertex AI は、Google Cloud の Vertex AI プラットフォーム上で Ray フレームワークを実行するためのサービスです。
Ray on Vertex AI の構成要素
(出典:Ray on Vertex AI の概要)
Ray on Vertex AI には以下の利点があります。
-
Ray 環境の構築と管理が容易
Ray on Vertex AI を使用することで、インフラストラクチャの管理や構成の複雑さが軽減されます。Ray on Vertex AI では、クラスタのセットアップ、管理、スケーリングが自動化され、開発者はアプリケーションの開発に集中できます。また、Google Cloud のセキュリティ、モニタリング、ロギングの機能を活用することで、アプリケーションの運用と保守が容易になり、セキュリティやパフォーマンスの問題に迅速に対応できます。 -
シームレスなスケーラビリティ
Ray on Vertex AIを使用すると、Google Cloud の強力なインフラストラクチャ上で Ray クラスタを簡単にスケールアップまたはスケールダウンできます。大規模なデータセットの処理や複雑なモデルのトレーニングが必要な場合でも、必要に応じて迅速にリソースを確保し、高い計算能力を利用することができます。 -
他の Google Cloud サービスとの統合
Ray on Vertex AI は、BigQuery や Vertex AI Predictions、Vertex AI Notebooks(Workbench, Colab Enterprise)など、他の Google Cloud サービスと統合されており、大規模なデータセットに対して効率的なアクセスや処理が可能になります。また、Vertex AI Feature Store や Vertex AI Model Monitoring などの MLOps 関連サービスへのアクセスも可能になります。
Ray on Vertex AI のアーキテクチャ
Google Cloud 公式ドキュメント では、Ray on Vertex AI に関する以下のアーキテクチャが紹介されています。
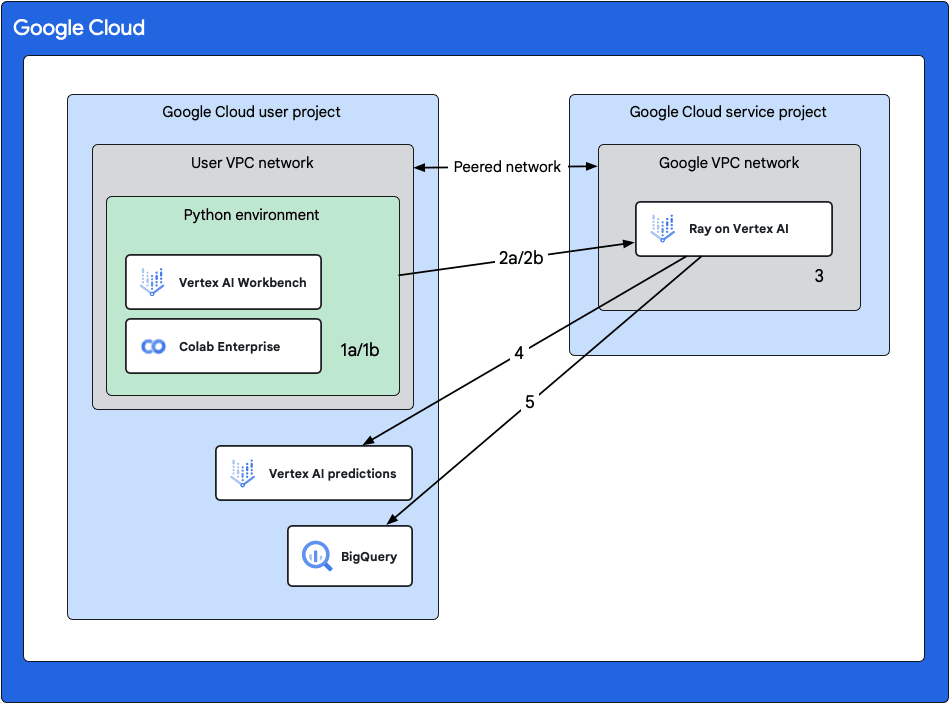
Ray on Vertex AI のアーキテクチャ
(出典:Ray on Vertex AI の概要)
上図における各操作は以下の通りです。
-
Vertex AI 上での Ray クラスタの作成
以下どちらかの方法で、Ray クラスタを作成できます。- 1a. コンソールを使用して Vertex AI に Ray クラスタを作成する
- 1b. Vertex AI SDK for Python を使用して Vertex AI に Ray クラスタを作成する
-
Ray クラスタへの接続
Vertex AI Workbench または Colab Enterprise で使用している VPC ネットワークと Ray on Vertex AI の VPC ネットワーク 間で VPC ピアリング ネットワークを形成し、以下どちらかの方法で Vertex AI 上の Ray クラスタに接続します。- 2a. Colab Enterprise を使用する
- 2b. Vertex AI Workbench ノートブックを使用する
-
Ray クラスタでのアプリケーション開発とモデルのトレーニング
Ray クラスタにてアプリケーションを開発し、以下の方法でモデルのトレーニングのジョブ実行が可能です。- Vertex AI Workbench または Colab Enterprise のノートブックで Vertex AI SDK for Python を使用して、Ray のジョブを実行する
- Ray Job CLI や Vertex AI SDK for Python、Ray ダッシュボードを使用して、Vertex AI の Ray クラスタに Ray ジョブを送信する
-
Vertex AI Predictions での予測実行
予測のために、トレーニング済みモデルをオンライン Vertex AI エンドポイントにデプロイし、リクエストを送ることで予測実行します。 -
BigQuery でのデータ管理
BigQuery を使用してデータを管理します。
Ray on Vertex AI の料金
Ray on Vertex AI の料金は、使用するコンピューティングリソースや Vertex AI に Ray クラスタを作成するときに選択したマシン構成に基づいて課金されます。Google Cloud 公式ドキュメント には、プレビュー版と一般提供(GA)で異なる課金となることが記載されています。
- プレビュー版:カスタム トレーニング モデルと同じレート で課金されます。
- 一般提供(GA):Vertex AI での Ray の料金 が適用されます。
また、Ray クラスタ以外の課金として以下が発生します。
- Vertex AI で Ray クラスタを使用してタスクを実行する場合、ログが自動的に生成され、Cloud Logging の料金 に基づいて課金されます。
- オンライン予測用のエンドポイントにモデルをデプロイする場合は、Vertex AI オンライン予測の料金 に基づいて課金されます。
- Vertex AI の Ray と BigQuery を使用する場合は、BigQuery の料金 に基づいて課金されます。
実装方法
今回は、Vertex AI 上での Ray クラスタの構築と Ray Jobs API によるジョブの実行方法について、ご紹介します。
事前準備
事前準備として、まず以下の API 有効化 を行います。
- Vertex AI API
- Compute Engine API
- Service Networking API
以下を参考に Vertex AI Workbench または Colab Enterprise の VPC ネットワーク と Ray on Vertex AI 環境の Google 共有 VPC ネットワークの間に、VPC ネットワーク ピアリングを設定します。
なお、VPC ネットワーク ピアリング 設定後は下図のような構成になります。
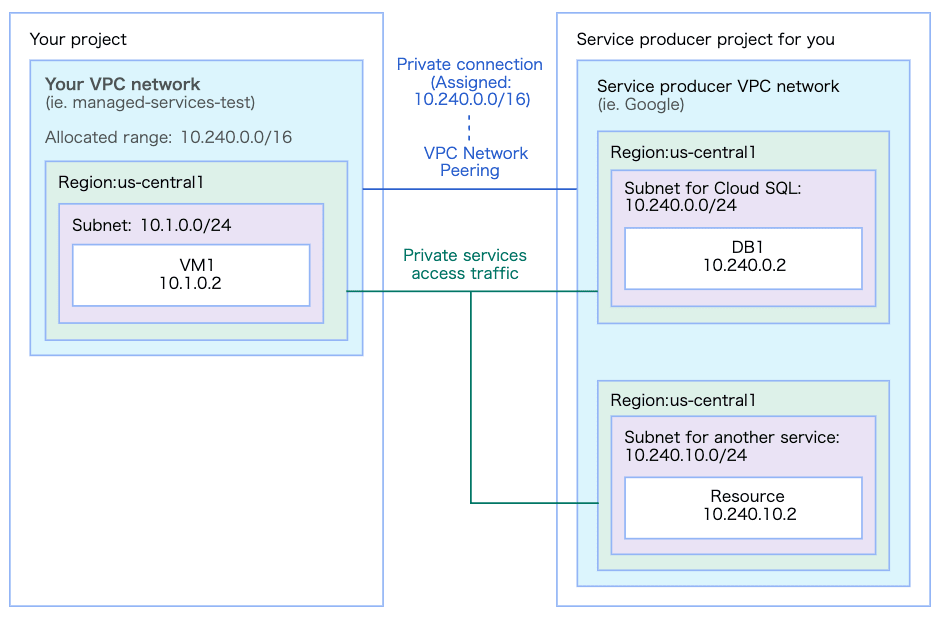
VPC ネットワーク 構成
Ray クラスタの作成
今回は Ray on Vertex AI のコンソール上から Vertex AI で Ray クラスタを作成 します。
コンソールのナビゲーションメニューから [Vertex AI] > [Vertex AI での Ray] を選択し、[クラスタを作成] をクリックします。
以下の画面にて、クラスタの [名前] と [リージョン] を指定し、[続行] をクリックします。
以下の画面にて、ククラスタのコンピュティング設定として [Ray バージョン] と ヘッドノートの [マシンタイプ]、[ディスクタイプ]、[ディスクサイズ] などを指定します。
(※ 今回は全てデフォルトのままとします。)
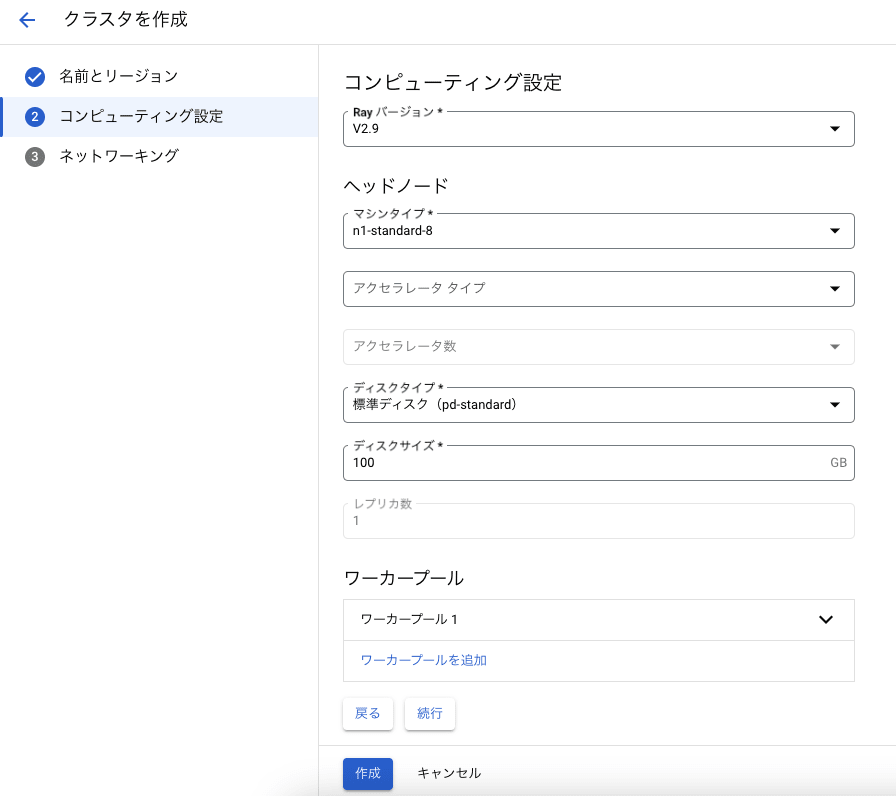
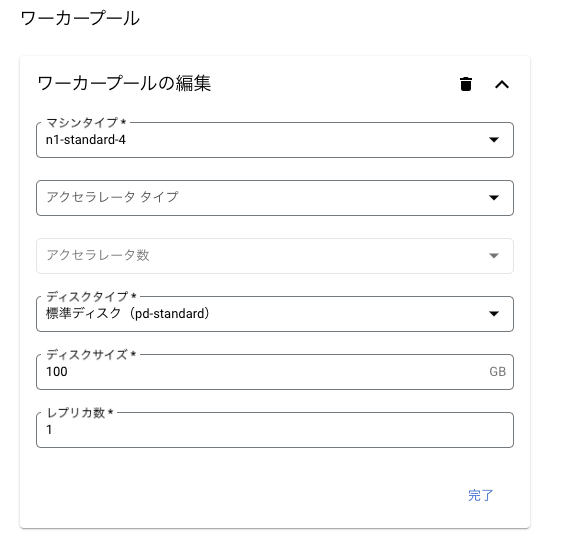
ワーカープールに関してもマシンタイプ等の設定が可能です。
(※ 今回は全てデフォルトのままとします。)
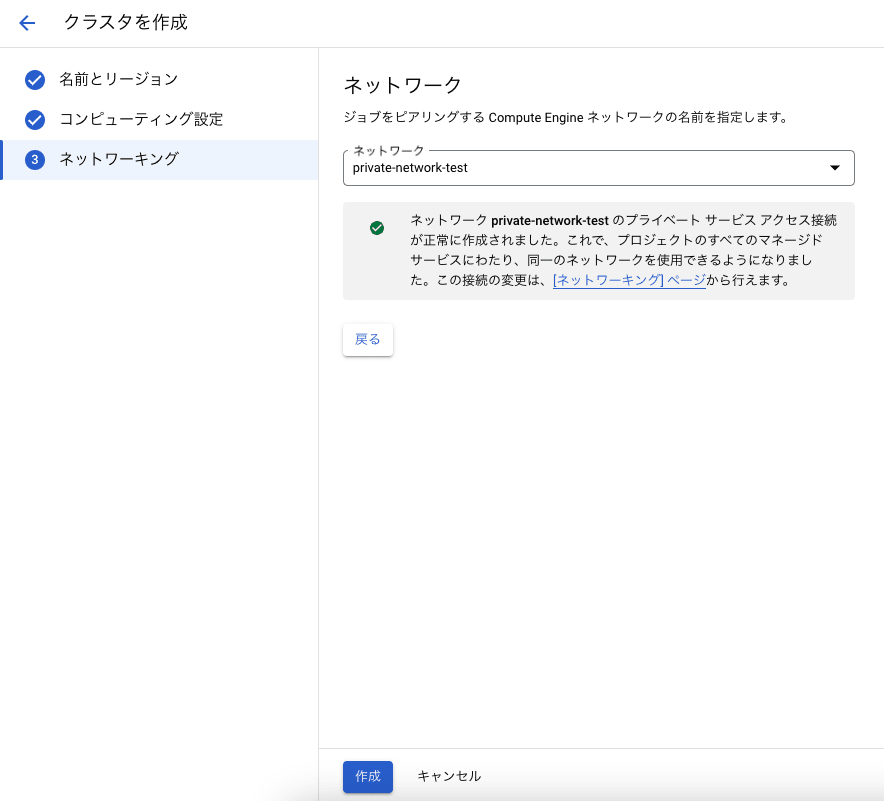
以下の画面にて、事前準備にて作成した VPC ネットワーク ピアリング を設定済みの VPC ネットワーク(Vertex AI Workbench / Colab Enterprise のネットワーク)を指定し、作成をクリックします。
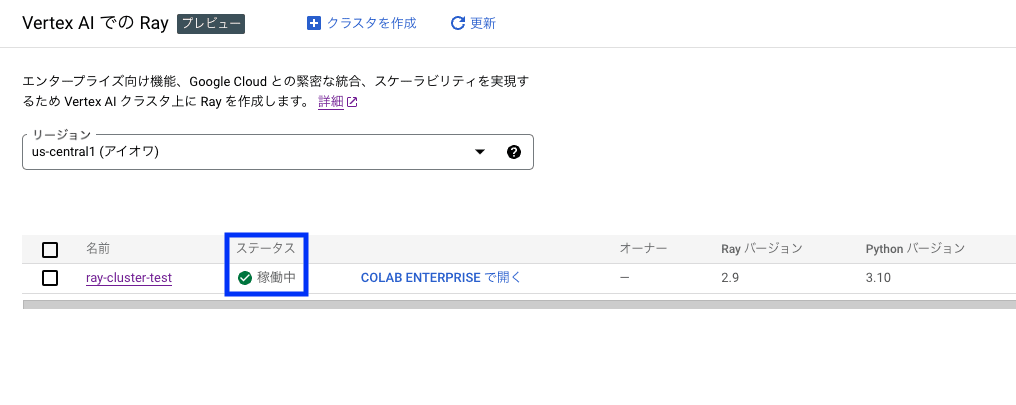
Ray クラスタの作成が完了し、コンソールにて該当クラスタのステータスが 稼働中 となっていることを確認します。
Ray のジョブ実行
以下を参考に Ray のジョブを実行する方法をご紹介します。
Ray のジョブ実行は Vertex AI Workbench または Colab Enterprise から可能ですが、今回は Colab Enterprise を選択します。
Ray on Vertex AI のコンソールにて、該当クラスタにおける [CLAB ENTERPRISE で開く] をクリックします。
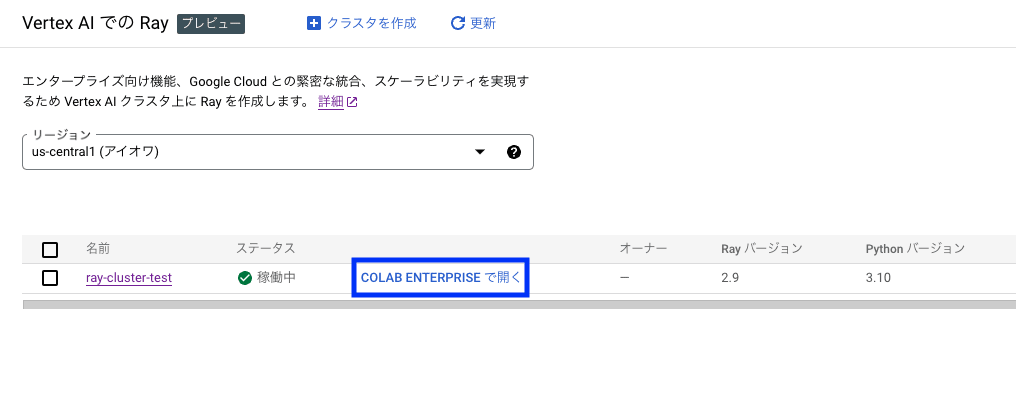
開いた Colab Enterprise にて、以下コードを含む my_script.py を作成し、Colab Enterprise のローカル環境に格納します。
import ray
import time
@ray.remote
def hello_world():
return "hello world"
@ray.remote
def square(x):
print(x)
time.sleep(100)
return x * x
ray.init()
print(ray.get(hello_world.remote()))
print(ray.get([square.remote(i) for i in range(4)]))
その後、以下のコードを Colab Enterprise 上で実行します。
import ray
import vertex_ray
from ray.job_submission import JobSubmissionClient
from google.cloud import aiplatform # Necessary even if aiplatform.* symbol is not directly used in your program.
# 以下の定数を実行環境に合わせて変更する
PROJECT_ID="PROJECT_ID"
REGION="REGION"
CLUSTER_NAME="CLUSTER_NAME"
CLUSTER_RESOURCE_NAME='projects/{}/locations/{}/persistentResources/{}'.format(PROJECT_ID, REGION, CLUSTER_NAME)
client = JobSubmissionClient("vertex_ray://{}".format(CLUSTER_RESOURCE_NAME))
job_id = client.submit_job(
# Entrypoint shell command to execute
entrypoint="python my_script.py",
# Path to the local directory that contains the my_script.py file.
runtime_env={
"working_dir": "./",
"pip": ["numpy",
"xgboost",
"ray==2.9.3", # pin the Ray version to prevent it from being overwritten
]
}
)
# Ensure that the Ray job has been created.
print(job_id)
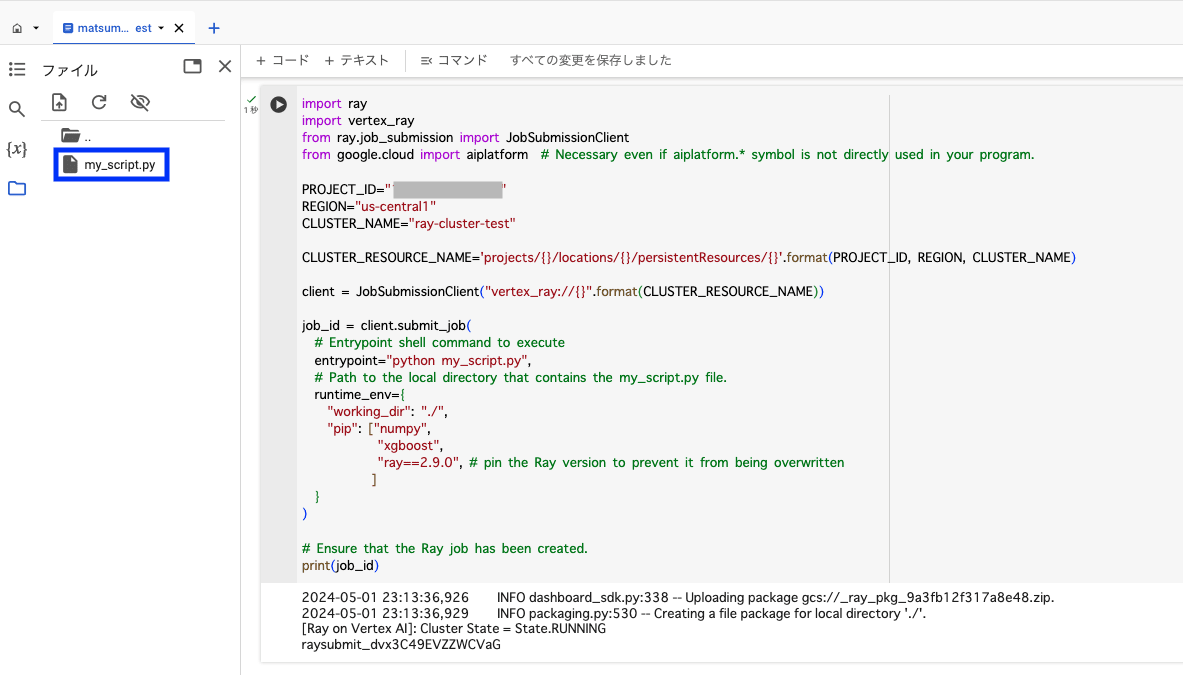
Colab Enterprise の画面上では、以下のようにファイルが格納され、コードが実行された状態になります。
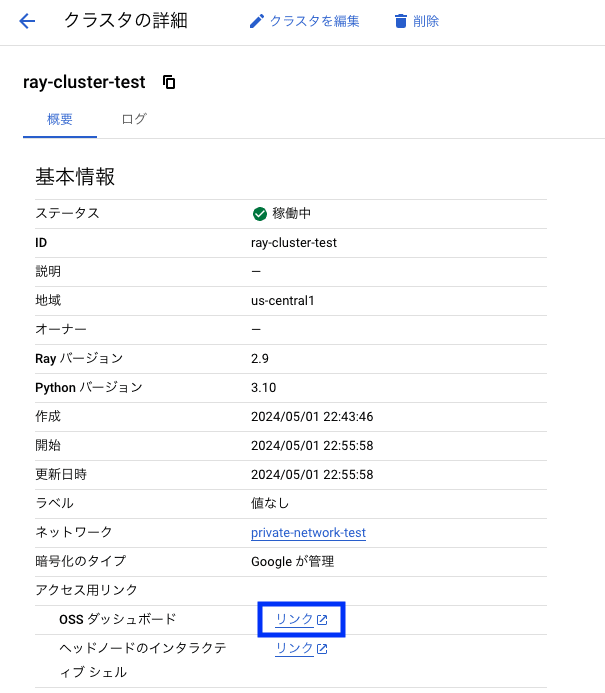
クラスタの詳細から [OSS ダッシュボード] の [リンク] をクリックし、Ray Dashboard を開きます。
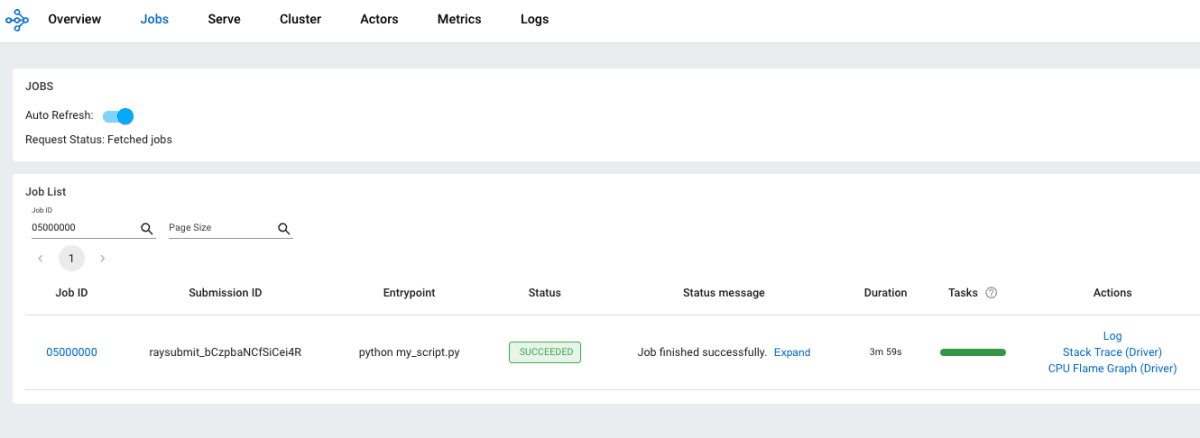
Ray Dashboard の Jobs 画面より、ジョブの実行結果を確認することが可能です。
なお、Ray Dashboard の操作等について詳しく知りたい方は Ray 公式ドキュメント をご参考ください。
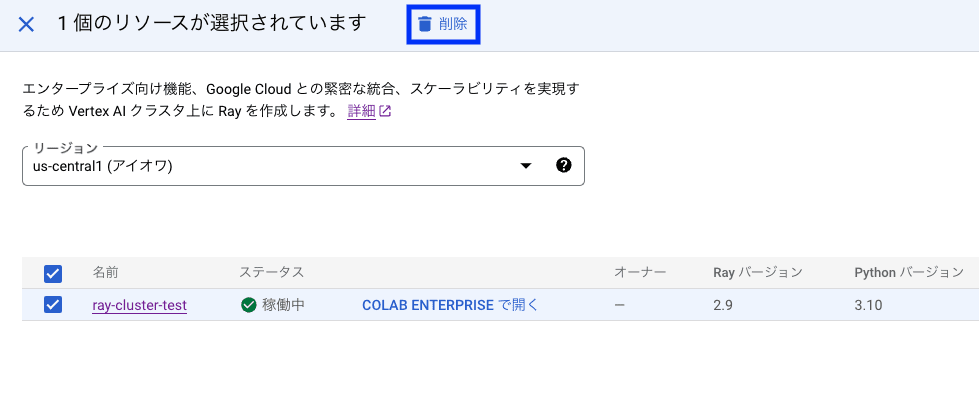
Ray クラスタを削除したい場合は、Ray on Vertex AI のコンソールにて、以下のように該当のリソースを選択して [削除] をクリックしてください。
参考
まとめ
今回は、Google Cloud の Vertex AI サービスの1つである Ray on Vertex AI についてご紹介いたしました。
Ray は、既存の Python コードに対して @ray.remote のデコレータを付与するだけで簡単に分散処理の実装ができ、機械学習のための豊富な組み込みライブラリの提供やシームレスなスケーラビリティなどによって、機械学習ワークロードの実行に適したフレームワークであると言えます。
さらに、Rayを Vertex AI 上で利用することでクラスタの構築や管理が容易になり、他の Google Cloud サービスとの統合により大規模なデータへのアクセスや処理が可能となります。
また、LLM のような高度な機械学習モデルにおいても、Ray はそのスケーラビリティと分散処理の容易さにより最適な実行環境を提供します。つまり、LLM アプリケーション開発においても Ray は非常に有用であると言えます。
もし、LLM を含む機械学習モデルの開発において、スケーラビリティと分散処理の実装の容易さを求めていましたら、Ray on Vertex AI をぜひご活用ください!
Discussion