LLMを使ってPDFをMarkdownに変換する「Zerox OCR」を試す
やや周回遅れ感あるが。
GitHubレポジトリ
Zerox OCR
AIによるドキュメント読み込み用の超シンプルなOCR方法。ドキュメントは結局、視覚的な表現を目的としたものです。複雑なレイアウトや表、チャートなども含まれています。視覚モデルを使うのは理にかなっています!
一般的な流れ:
- ファイルを入力する(pdf、docx、画像など)
- そのファイルを一連の画像に変換する
- 各画像をGPTに渡してMarkdownで出力するように依頼
- 各応答を集約してMarkdownとして返す
ホストされたバージョンを試してみてください:https://getomni.ai/ocr-demo
Getting Started
SDKはNodeとPythonがあるが、今回はPythonで。あと、Python-3.11以上なので、Colabだと試せない(ColabはPython-3.10)ので、今回はローカルのJupyterLabで試す。
作業ディレクトリ作成
mkdir zerox-test && cd zerox-test
JupyterLabをDockerで起動
docker run --rm \
> -p 8888:8888 \
> -u root \
> -e GRANT_SUDO=yes \
> -v .:/home/jovyan/work \
> quay.io/jupyter/minimal-notebook:latest
以降の作業はJupyterLab上で。
まず、PDFを扱うためのOSライブラリとしてpoppler-utilsをインストール
!sudo apt update && sudo apt install -y poppler-utils
ZeroxのPythonパッケージであるpy-zeroxをインストール
!pip install py-zerox
Zeroxは内部でLiteLLMを使用しているので、APIキーの設定が必要になる。今回はOpenAIを使う。OpenAIのAPIキーをセット。
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass('OPENAI_API_KEY')
使用するPDFは、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを使用させていただく。
PDFをダウンロード。
!wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
こんな感じで実行。なお、LiteLLMなので他のモデルプロバイダを使う場合はそれぞれの指定に従えば良さそう。
from pyzerox import zerox
import json
import asyncio
# notebookの場合は必要
import nest_asyncio
nest_asyncio.apply()
# モデルの定義
model = "gpt-4o-mini"
# モデルによっては追加のキーワード引数が必要な場合がある。その場合はここで指定。
kwargs = {}
# システムプロンプト
custom_system_prompt = None
# メインの非同期エントリーポイントの定義
async def main():
# 読み込むPDFの指定。ローカルファイルパスとURLに対応
file_path = "r5_doukou.pdf"
# ページの指定
# None: 全ページ
# intまたはlist(int): 特定のページ番号を指定、1から始まる
select_pages = None
# Markdownファイルの出力先ディレクトリ
output_dir = "./output_test"
result = await zerox(
file_path=file_path,
model=model,
output_dir=output_dir,
custom_system_prompt=custom_system_prompt,
select_pages=select_pages,
**kwargs
)
return result
# 実行
result = asyncio.run(main())
出力先ディレクトリにMarkdownが出力される。
!ls -lt output_test
total 48
-rw-r--r-- 1 jovyan users 47613 Nov 20 01:47 r5_doukou.md
pythonでも結果を受け取っているので確認。参考までに元PDFを一部引用する。
1ページ目

print(result.pages[0].content)
# 令和5年度 神戸市観光動向調査結果について
## 調査目的
本調査は、来神観光客の特質と神戸市内の観光動向を把握し、今後の観光政策の参考とすることを目的に実施。
## 調査方法
調査員が対象面にてアンケート項目を聞き取る形で実施。
## 調査日
1. 令和5年 5月13日(土)・20日(土)※
2. 令和5年 9月 9日(土)
3. 令和5年 11月25日(土)・12月2日(土)※
4. 令和6年 2月10日(土)・17日(土)・24日/3月30日(土)※
※国等により、一部の調査地点については指定して実施。
## 調査地点
| 地区 | NO | 調査地点 | サンプル数 |
|--------|----|---------------------------------------|-------------|
| 北野 | 1 | 北野町広場 | 246 |
| | 2 | 北野工房のまち | 154 |
| | 3 | 南京町広場 | 218 |
| | 4 | 総合インフォメーションセンター | 198 |
| | 5 | 旧居留地 | 201 |
| | 6 | 神戸市役所リープウエイハーブ園山麓駅 | 203 |
| | 7 | 自然環境教育館 | 205 |
| | 8 | 王子動物園内 | 235 |
| | 9 | 県立美術館 | 217 |
| 市街地 | 10 | きよみち広場 | 208 |
| | 11 | 神戸空港港上階展望ロビー | 212 |
| | 12 | 1KEIファント | 192 |
| | 13 | 龍虎寺(兵庫大仏) | 147 |
| | 14 | 兵庫津梁ミュージアム | 204 |
| 神戸港 | 15 | 神戸海洋博物館前及び周辺 | 200 |
| | 16 | 中央世界中央ターミナル周辺 | 208 |
| | 17 | うみへモザイク | 201 |
| | 18 | ハーバーランド総合インフォメーション前 | 213 |
| | 19 | 六甲摩耶 | 209 |
| 六甲・摩耶 | 20 | 摩耶山広場 | 200 |
| | 21 | 六甲山牧場内 | 215 |
| | 22 | 六甲ガーデンテラス内 | 211 |
| 有馬 | 23 | 有馬温泉観光案内所 | 214 |
| | 24 | 有馬の湯前 | 216 |
| 須磨・舞子 | 25 | 六甲有馬ロープウェイ有馬温泉駅 | 232 |
| | 26 | 須磨離宮公園 | 202 |
| | 27 | 舞子すさみ公園(舞子海上プロムナード)| 230 |
| | 28 | 舞子フラワー・フラワーパーク大沢園内 | 235 |
| | 29 | 神戸三田プレミアム・アウトレット | 215 |
| | | 合計 | 6,250 |
4ページ目
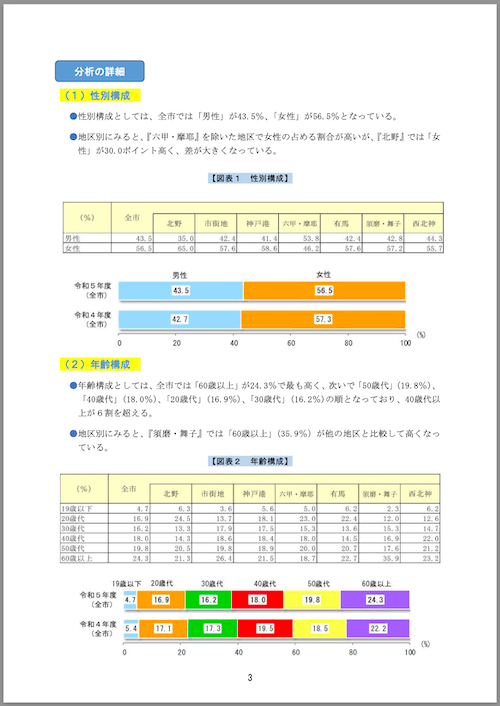
print(result.pages[3].content)
# 分析の詳細
## (1) 性別構成
- 性別構成としては、全市では「男性」が43.5%、 「女性」が56.5%となっている。
- 地区別にみると、「六甲・摩耶」を除いた地域で女性の占める割合が高いが、「北野」では「女性」が30.0ポイント高く、差が大きくなっている。
【図表1 性別構成】
| | 全市 | 北野 | 市街地 | 神戸港 | 六甲・摩耶 | 有馬 | 霞丘・舞子 | 西北神 |
|-----|--------|--------|--------|--------|-------------|--------|------------|--------|
| 男性 | 43.5% | 35.0% | 42.4% | 41.4% | 53.8% | 42.4% | 44.3% | 44.3% |
| 女性 | 56.5% | 65.0% | 57.6% | 58.6% | 46.2% | 57.6% | 55.7% | 55.7% |
| | 令和5年度 (全市) | 令和4年度 (全市) |
|-----|------------------|------------------|
| 男性 | 43.5% | 42.7% |
| 女性 | 56.5% | 57.3% |
## (2) 年齢構成
- 年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、「40歳代」(18.0%)、「20歳代」(16.9%)、 「30歳代」(16.2%)の順となっており、40歳代以上が6割を超える。
- 地区別にみると、「須磨・舞子」では「60歳以上」が(35.9%)が他の地区と比較して高くなっている。
【図表2 年齢構成】
| | 全市 | 北野 | 市街地 | 神戸港 | 六甲・摩耶 | 有馬 | 霞丘・舞子 | 西北神 |
|-----|--------|--------|--------|--------|-------------|--------|------------|--------|
| 19歳以下 | 4.7% | 6.3% | 7.6% | 6.7% | 1.9% | 6.3% | 3.6% | 3.9% |
| 20歳代 | 16.9% | 20.0% | 16.2% | 18.6% | 16.3% | 17.4% | 18.8% | 16.3% |
| 30歳代 | 16.2% | 15.7% | 16.2% | 18.2% | 15.8% | 15.4% | 20.0% | 17.3% |
| 40歳代 | 18.0% | 21.3% | 18.6% | 19.1% | 18.8% | 19.8% | 19.4% | 18.7% |
| 50歳代 | 19.8% | 22.0% | 19.6% | 21.2% | 21.6% | 19.0% | 19.4% | 20.0% |
| 60歳以上 | 24.3% | 15.0% | 17.5% | 16.2% | 24.2% | 22.2% | 35.9% | 25.0% |
| | 令和5年度 (全市) | 令和4年度 (全市) |
|-----|------------------|------------------|
| 19歳以下 | 4.7% | 5.4% |
| 20歳代 | 16.9% | 16.9% |
| 30歳代 | 16.2% | 16.2% |
| 40歳代 | 18.0% | 18.0% |
| 50歳代 | 19.8% | 19.8% |
| 60歳以上 | 24.3% | 24.3% |
出力としてはとてもきれい。この元文書、1ページ目はテキストで読める表なのだが、4ページ目は表の画像が埋め込んである。このあたりもちゃんと解釈できているし、グラフ画像もなんとか表現しようとしているところはさすがLLMという感じ。
ただし、細かい数値が異なっていたり、書かれていないことが追加されていたりと、チラホラとハルシネーションしてたりするところもある。ここはモデル性能にもよるかもしれないが。
まとめ
とてもお手軽に使えるのは良い。出力されるMarkdownもきれいで良い。
精度については、Zerox OCRという名前ではあるものの、OCRライブラリのインストールは求められていないし、"OCR-ing"とあることからも実際にはOCRはしていないのだろうと思う。つまりLLMの性能に依存することになると思う。
個人的な経験則だと、この手の処理はGeminiが良いかな?という感はある。
popplerはページ単位で画像に変換するのに使っているのだね。
ちょっと前にLLMで読めないPDFとかチラホラ見つけたのだけど、popplerだといけるのかな?
PDFの読み取りはその作りで結構左右されそうという感を持ったので、この手のPDF解析ツールはやってみないとわからないというスタンスになりつつある。ある程度問題なく読み取れることが確認できているものを定型的・大量にやるとかなら良いかなと思う。論文とかがあってそう。
Zerox OCRをラップして、構造化情報を抽出するDocumindというのがある。ただしNodeだけっぽい。