【python】zeroxのAI OCR試してみる!
はじめに
以下のGithubリポジトリで公開されているzeroxというライブラリにより、マルチモーダルLLMを活用したOCRができるとのことで試してみました。
python×streamlitでpdfファイルをアップロードして、テキスト化するまでをこの記事では説明します。
ライブラリについて、隅々まで把握したわけではないですが、自分が調べてわかった内容などをまとめますので、同じライブラリを活用して、資料をテキスト化したい方の参考になれば幸いです。
テキスト化を試す
zeroxを利用したテキスト化を試すだけなら以下のサイトで、pdfをテキスト化できます。 表なども割といい感じにマークダウン形式でテキスト化してくれたりするので、資料をテキスト化してLLMに渡す際に使えそうな感じがします。精度についてはこの記事では細かく検証しないので、各人で確かめていただけたらと思います。
zeroxライブラリの概要について
実行環境
以下2つに対応したライブラリが存在するので、JS・TSやPythonで利用することができます。
- Node.js
- Python
この記事ではPythonを使った場合について解説していきます。
テキスト化がサポートされているファイル拡張子
私が試したところ、pdfファイルのみテキスト化できました。
READMEではpdf以外もテキスト化できそうで、以下をインストールしたらdocxやxlsxなど様々なファイルをテキスト化できそうだったので、試してみましたができませんでした。
- libreoffice
- graphicsmagick
pdf以外でもテキスト化するために追加で必要な手順を知っている方がいれば、教えていただけると助かります。
利用できるモデル
zeroxでは複数のマルチモーダルなモデルを利用して資料をテキスト化することができます。なので、OpenAIのgpt4o、googleのgemini、AnthropicのClaudeなどのモデルを使ってテキスト化が可能です。
複数モデルを利用可能にするために、以下のLiteLLMというライブラリを内部で利用しているようで、こちらでサポートされているマルチモーダルモデルは利用できそうです。
ライブラリの使い方
正直ライブラリのREADMEを見てもらえればすぐにわかるくらい簡単です。
ステップごとに簡単に説明します。
1.必要なもののインストール
pythonの環境はある前提かつPCはmacの場合の話をします。
popplerをシステムにインストールして、パスを通します。macの場合は以下でインストール&パスが通った状態になりました。
brew install poppler
→こちらでpdfを画像に変換するので必須のソフトウェアになります。
次に、今回紹介しているライブラリpy-zeroxを以下コマンドでインストールします。
pip install py-zerox
2.モデルを利用するための情報を設定する
どのモデルを使ってテキスト化するか、またそのモデルを利用するためのAPIキーなどを設定する必要があります。
これは公式のREADMEにもいくつか例が載っていますが、gpt4o-miniを利用する場合は以下のように必要な情報を定義しています。
###################### Example for OpenAI ######################
model = "gpt-4o-mini" ## openai model
os.environ["OPENAI_API_KEY"] = "" ## your-api-key
os.environで環境変数としてAPIキーを設定しており、同じ名前で設定すれば自動でこれをOpenAIのAPIキーとして利用してくれるように裏側でなっています。
3.テキスト化する
以下も公式のREADMEから大事な部分だけをコピペさせていただきました。
result = await zerox(file_path=file_path, model=model, output_dir=output_dir,custom_system_prompt=custom_system_prompt,select_pages=select_pages, **kwargs)
どのモデルを使うかやテキスト変換したいファイルへのパスなどをパラメータとして、zerox関数を実行します。設定できるパラメータは色々あるので、詳しくはREADMEをご確認ください。
4.レスポンスを処理する
zerox関数のレスポンスとしてZeroxOutputオブジェクトが返されます。READMEから抜粋すると以下のような構造になっており、各ページごとにcontentにテキスト化された内容が入ります。
ZeroxOutput(
completion_time=9432.975,
file_name='cs101',
input_tokens=36877,
output_tokens=515,
pages=[
Page(
content='~~~~~~',
content_length=2333,
page=1
)
]
)
あとはこのレスポンスからcontent部分を取り出すなど、多少の処理を行う必要があるかと思います。
streamlitでテキスト変換アプリをサクッと作る
pythonではstreamlitというライブラリを使ってサクッとデモ用のwebアプリを作ることが可能です。streamlitについては詳しく解説しないので、興味のある方は以下の公式サイトなどをご確認ください。 streamlitでwebアプリとして試せるようにしたのは、zeroxライブラリの使い方への理解が深められことと、異なるモデルを利用した場合のテキスト化の精度の違いを簡単に検証できるからです。
画面挙動
今回、私はgeminiとgpt4o系で計4つのモデルを利用できるようにサイドメニューで選択できるようにしました。
↓ファイルをアップロードして、テキスト変換実行をクリックすると結果が下に表示されます。
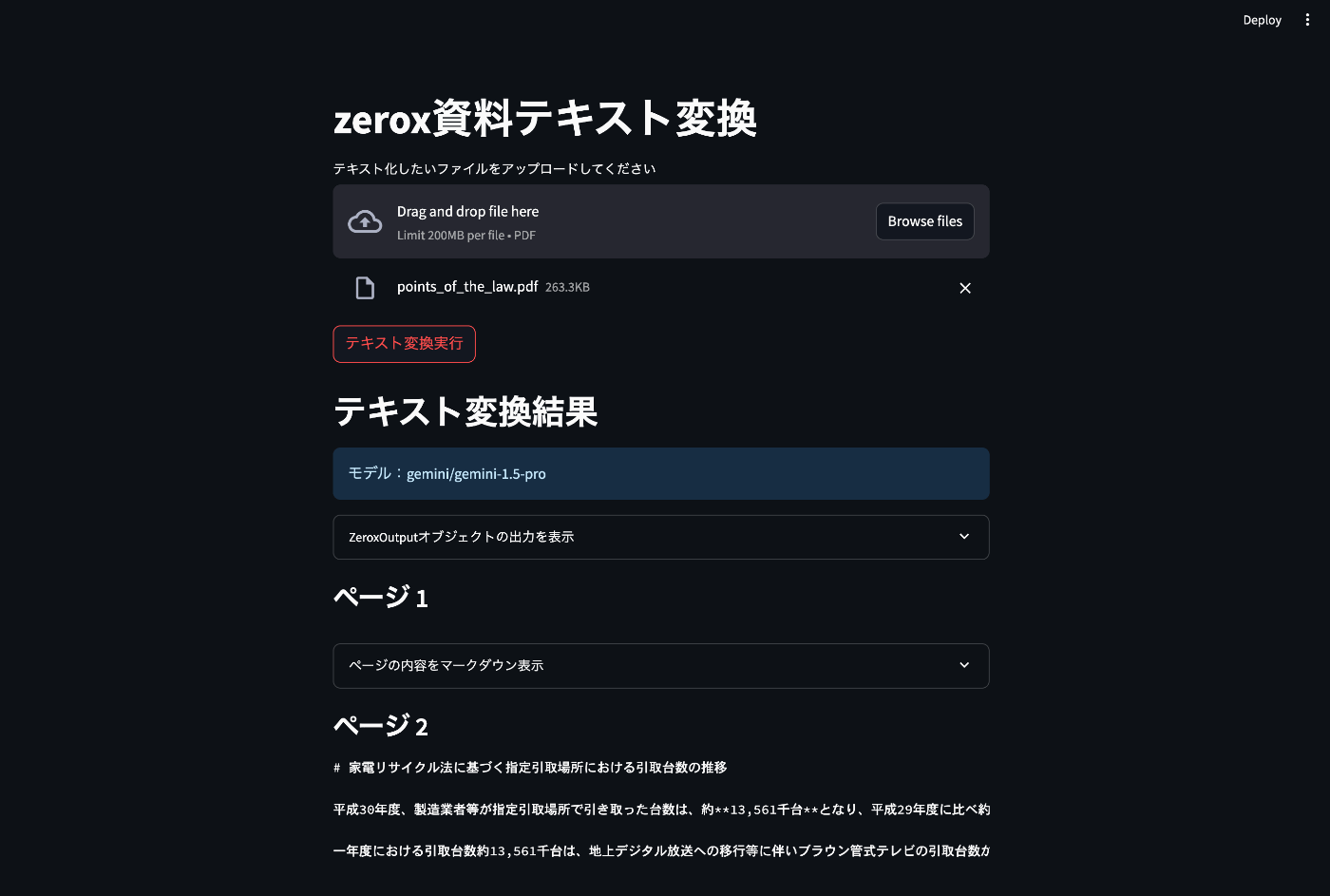

ライブラリの挙動を理解するためや、テキスト化の精度を確認するためにも以下の3パターンで結果を確認できるようにしています。
- 1.ZeroxOutputの内容
- 2.contentのテキストそのまま(ページごと)
- 3.contnntのマークダウンを見やすく画面表示(ページごと)
私としてはLLMに与えるテキストとしての精度を一番確認したかったので、2番以外は折りたたみにして、クリックしたら内容が確認できるようになっています。
実際のコード
他の検証も混ざったリポジトリなのですが、以下リポジトリにコードをあげています。 ↓今回関係しそうなファイルは以下のファイルになります。このコードで上の画面の動いている部分は全て実装されています。
zerox.pyファイルの内容
import asyncio
import os
import streamlit as st
from dotenv import load_dotenv
from pyzerox import zerox
from pyzerox.core.types import ZeroxOutput
load_dotenv(override=True)
st.title("zerox資料テキスト変換")
## オプションを定義
model_options = [
"gemini/gemini-1.5-flash",
"gemini/gemini-1.5-pro",
"gpt-4o-mini",
"gpt-4o",
]
## セレクトボックスをサイドバーに作成
selected_model_option: str = st.sidebar.selectbox(
"モデルを選択してください:", model_options
)
# ファイルアップロード機能を追加
uploaded_file = st.file_uploader(
"テキスト化したいファイルをアップロードしてください", type=["pdf"]
)
if uploaded_file is not None and st.button("テキスト変換実行"):
with st.spinner("テキスト変換中..."):
# ファイルの拡張子を取得
file_extension = uploaded_file.name.split(".")[-1].lower()
# 一時ファイルとして保存(拡張子付きで)
temp_filename = f"temp_file.{file_extension}"
with open(temp_filename, "wb") as f:
f.write(uploaded_file.getbuffer())
# ファイルパスを設定
file_path = temp_filename
# 非同期関数を定義
async def process_file():
result: ZeroxOutput = await zerox(
file_path=file_path, model=selected_model_option
)
return result
# 非同期関数を実行
try:
zeroxoutput_result: ZeroxOutput = asyncio.run(process_file())
except Exception as e:
# エラー発生した際は、エラー内容を表示し、streamlitの処理を停止
st.error(f"エラーが発生しました: {e}")
st.error("エラー内容を確認し、再度実行してください")
st.stop()
# 結果を表示
st.markdown("## テキスト変換結果")
st.info(f"モデル:{selected_model_option}")
with st.expander("ZeroxOutputオブジェクトの出力を表示"):
st.markdown(zeroxoutput_result)
# 全てのページを順番に表示
for i, page in enumerate(zeroxoutput_result.pages):
st.markdown(f"### ページ {i+1}")
st.text(page.content)
with st.expander("ページの内容をマークダウン表示"):
st.write(page.content)
# 一時ファイルを削除
os.remove(temp_filename)
zeroxライブラリの仕組みを理解する(推測含む)
一部推測も入りますが、zeroxライブラリがどのような仕組みになっているかを少しだけ話していこうと思います(簡単にですが、内部のコードを確認しました)。
処理の流れ
やっていることは以下の流れで、すごくシンプルだと思います。
- pdfがページごとに画像に変換される
→ここで、popplerが利用される - テキスト化するプロンプトと共に画像をマルチモーダルなモデルに処理させる
→記事投稿時点では画像に変換しないとモデルが処理できないので、このような方法を取っている
→ここでLiteLLMを用い、複数のマルチモーダルなモデルを切り替え可能
画像をテキスト化するときのシステムプロンプト
画像をテキスト化する際のシステムプロンプトとしては以下が使われていそうでした。
DEFAULT_SYSTEM_PROMPT = """
Convert the following PDF page to markdown.
Return only the markdown with no explanation text.
Do not exclude any content from the page.
"""
英語を日本語にすると以下のような指示を与えています。指示としてはとてもシンプルですね。これを使えばChatGPTなどで同様の精度で画像をテキスト変換することも可能そうだなと思いました。
- Convert the following PDF page to markdown.
→PDFページをマークダウン形式に変換することを指示しています。 - Return only the markdown with no explanation text.
→マークダウンのみを返すように指示しています。
→説明文や補足などは含めないように指定しています。 - Do not exclude any content from the page.
→ページの内容を全て含めるように指示しています。
最後に
pdf以外のテキスト化がうまくいかなかったことだけ残念ですが、zeroxを使ったpdfのテキスト化を試すことができました。いろんな資料をテキスト化することで生成AIによって活用できる幅も広がると思いますので、精度も確認しながら有用なら今後使っていきたいライブラリだなと思いました。
Discussion