はじめに
Kotoba Technologiesでインターンをしている東京工業大学 B4 横田研究室の藤井(@okoge_kaz)です。
Kotoba Technologiesは2023年7月に米国の博士号・教授職を持った創業者2人によって日米クロスボーダー体制で創業され、最先端NLP技術を用いて、日本及び非英語圏における実運用に向けた研究開発を行っています。今回は、社内で利用されているライブラリの一部を公開したため、使用方法等について解説を行います。
Llama 2を筆頭に数多くのモデルがリリースされていますが、推論(inference)してモデルの挙動を確かめることはできても、自前のデータで学習する方法についてはtransformers Trainerクラスを利用した手法を除き、コミュニティに知見として十分に共有されているとは言い難いと個人的には感じています。そこで今回、Kotoba Recipesをリリースするとともに環境構築方法、使用方法についても紹介することとしました。
Open Source として公開しましたので、どなたでも利用可能です。
Kotoba Recipes とは
概要
Kotoba Recipesとは、llama-recipesをもとに開発したtransformersが対応しているすべての言語モデルを継続事前学習または、指示チューニングすることが可能なライブラリです。
事前学習ライブラリとしてはMegatron-DeepSpeedや、GPT-NeoXが有名ですが、今回作成したKotoba Recipesは、すでに学習されたモデルから追加的に学習を行う際に学習を効率的に行えるようにサポートするライブラリです。
公式にサポートしているモデルは、Llama 2, Mistral 7Bのみですが、任意のtransformersが対応しているモデルを学習することが可能な設計になっています。公式サポート以外のモデルを学習する場合は、後述の拡張方法についての説明をご覧ください。
これを利用すれば、Llama 2から特定ドメインへ特化させたモデルを作成したり、日本語データを利用して英語で事前学習されたモデルに日本語を学習させて、日本語性能を上昇させたりすることが可能となります。
複数ノードを用いた分散学習をサポートしており、Llama 2 7B, 13B, 70Bを学習することが可能です。
また、Mistral 7BについてもA100 80GB 1nodeでの動作を確認しています。
特徴
本ライブラリの特徴は、実行時のargument引数だけで設定を変更して学習することができる点です。
HuggingFace TransformersのTrainerを利用したコードの場合、ある程度自分でコードを書く必要があるだけでなく、分散並列学習がし辛いという欠点があります。
(もちろんTrainerでも行えるのですが、Trainer自体のコードが複雑化している関係から個人的には使用感が良くないと思っています)
本ライブラリは、Tensor Parallel, Pipeline Parallelなどの分散学習技術ではなく、PyTorch FSDPを利用しています。そのため、任意のサイズのクラスターにて実行可能である点も魅力の一つです。
環境構築
ライブラリの概要が把握できたと思いますので、実際に使用するための準備に移ります。
環境構築方法について解説します。Python 3.9, 3.10, 3.11のいずれのバージョンでも動作するかと思いますが、以下ではPython 3.11.4で環境構築を行います。
まずはpythonの仮想環境を作成しましょう。
python -m venv <仮想環境名> で作成します。
そして仮想環境を有効化しましょう。
python -m venv .env
source .env/bin/activate
次にpip installにて必要なライブラリをインストールしていきます。requirements.txtにはcuda11.8に対応したPyTorchをinstallするように書いてあります。お使いの環境に合わせて適時 install versionを変更してください。
例:
- torch==2.1.0+cu118
+ torch==2.1.0+cu117
準備ができたら、早速 install していきましょう。以下のコマンドでインストールしてください。
上手くinstallができると、以下のようにpip installが進むはずです。
pip install -r requirements.txt
ABCI で環境構築をする場合
source /etc/profile.d/modules.sh
module load cuda/11.8/11.8.0
module load cudnn/8.9/8.9.2
module load nccl/2.16/2.16.2-1
module load hpcx/2.12
こちらを行ってください。問題なくインストールできるはずです。
FlashAttentionのインストール (Optional)
Ampere, Ada, HooperシリーズのGPUの場合は、Flash Attentionをインストールすることで高速化の恩恵にあずかることができます。具体的にはA100, H100, A6000 Ada, RTX 3090, RTX 4090などのGPUです。
以下の方法でinstallしてください。
pip install ninja wheel packaging
pip install flash-attn --no-build-isolation
使用方法
指示チューニング (Instruction Tuning)
Alpaca Datasetを利用して指示チューニングを行ってみましょう。
scripts/llama/instruction_tuning/llama2-7b-alpaca.shにサンプルスクリプトがあります。学習を行う前に、事前学習済みモデル(Llama 2)の用意とwandbのセットアップを行います。
1. wandb のセットアップ
上述の通りpip installを行っている場合はインストールせずに次の手順に進んでください。
pip install wandb
アカウントを作成していない方は、https://www.wandb.jp/ からアカウントを作成してください。
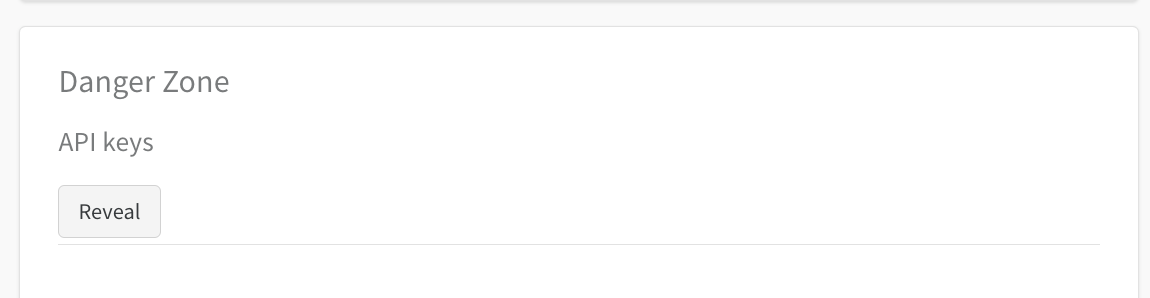
作成が完了したら https://wandb.ai/settings よりAPI keys のセクションにいき Revealを押してAPI keyが表示されたらAPI keyをコピーします。
次に、コマンドライン上で以下のコマンドを実行します。
> wandb login
API keyの入力を求められるので、先程コピーしたkeyをペーストして登録します。
2. Llama 2のcheckpointダウンロード
以下のリンクにアクセスします
Llama-2-7b-hf: https://huggingface.co/meta-llama/Llama-2-7b-hf
Llama-2-13b-hf: https://huggingface.co/meta-llama/Llama-2-13b-hf
同意が必要なので、手続きを行います。
手続きが完了したあとしばらくするとメールが届き、その後手順通りに作業をするとアクセスできるようになります。
アクセスできるようになりましたら、Files and versions から
clone Reposiotry をクリックします。
以下のようにコマンドが表示されるので、モデルの重み(checkpoint)をダウンロードしたいdirecotryで表示されているようにコマンドを入力します。
実践
準備が完了したら、サンプルスクリプトの--model_name, --tokenizer_nameのパスを自分の環境に合わせて修正してください。また、--wandb_entity, --wandb_projectについても自分の環境に合わせて変更してください。
scripts/llama/instruction_tuning/llama2-7b-alpaca.sh
#!/bin/bash
#$ -l rt_AF=2
#$ -l h_rt=3:00:00
#$ -j y
#$ -o outputs/llama/7b/
#$ -cwd
# module load
source /etc/profile.d/modules.sh
module load cuda/11.8/11.8.0
module load cudnn/8.9/8.9.2
module load nccl/2.16/2.16.2-1
module load hpcx/2.12
# switch virtual env
source .env/bin/activate
# distributed settings
export MASTER_ADDR=$(/usr/sbin/ip a show dev bond0 | grep 'inet ' | awk '{ print $2 }' | cut -d "/" -f 1)
export MASTER_PORT=$((10000 + ($JOB_ID % 50000)))
echo "MASTER_ADDR=${MASTER_ADDR}"
# hostfile
if [[ "$SGE_RESOURCE_TYPE" == "rt_F" ]]; then
export NUM_GPU_PER_NODE=4
NODE_TYPE="v100"
elif [[ "$SGE_RESOURCE_TYPE" == "rt_AF" ]]; then
export NUM_GPU_PER_NODE=8
NODE_TYPE="a100"
else
echo "Unrecognized SGE_RESOURCE_TYPE: $SGE_RESOURCE_TYPE"
fi
NUM_NODES=$NHOSTS
NUM_GPUS=$((${NUM_NODES} * ${NUM_GPU_PER_NODE}))
mkdir -p ./hostfile
HOSTFILE_NAME=./hostfile/hostfile_${JOB_ID}
while read -r line; do
echo "${line} slots=${NUM_GPU_PER_NODE}"
done <"$SGE_JOB_HOSTLIST" >"$HOSTFILE_NAME"
# debugging flag
export LOGLEVEL=INFO
export NCCL_DEBUG=WARN
export NCCL_DEBUG_SUBSYS=WARN
export PYTHONFAULTHANDLER=1
export CUDA_LAUNCH_BLOCKING=0
# training settings
NUM_EPOCHS=1
# batch size
BATCH_SIZE=8
GLOBAL_BATCH_SIZE=1024
GRADIENT_ACCUMULATION_STEPS=$((GLOBAL_BATCH_SIZE / (BATCH_SIZE * NUM_GPUS)))
if (($GRADIENT_ACCUMULATION_STEPS < 1)); then
echo "Error: Gradient Accumulation Steps is less than 1. Exiting."
exit 1
fi
# optimizer
LR=1e-4
LR_MIN=1e-5
LR_DECAY=0.80
LR_WARMUP=0.05
LR_DECAY_STYLE="cosine"
WEIGHT_DECAY=0.1
# seed
SEED=42
# dataset
NUM_WORKERS_DATALOADER=2
# checkpoint path
CHECKPOINTS_PATH=/bb/llm/gaf51275/llama/checkpoints/llama-2-7b-gbs_${GLOBAL_BATCH_SIZE}-${NODE_TYPE}_${NHOSTS}
mkdir -p $CHECKPOINTS_PATH
# run
mpirun -np $NUM_GPUS \
--npernode $NUM_GPU_PER_NODE \
-hostfile $HOSTFILE_NAME \
-x MASTER_ADDR=$MASTER_ADDR \
-x MASTER_PORT=$MASTER_PORT \
-bind-to none -map-by slot \
-x PATH \
python examples/finetuning.py \
--enable_fsdp \
--low_cpu_fsdp \
--peft_method None \
--mixed_precision \
--pure_bf16 \
--num_epochs $NUM_EPOCHS \
--model_name /groups/gaf51217/fujii/finetune/llama2/Llama-2-7b-hf \
--tokenizer_name /groups/gaf51217/fujii/finetune/llama2/Llama-2-7b-hf \
--batch_size_training $BATCH_SIZE \
--gradient_accumulation_steps $GRADIENT_ACCUMULATION_STEPS \
--lr $LR \
--lr_min $LR_MIN \
--lr_warmup $LR_WARMUP \
--lr_decay $LR_DECAY \
--lr_decay_style $LR_DECAY_STYLE \
--weight_decay $WEIGHT_DECAY \
--fsdp_activation_checkpointing \
--seed $SEED \
--dataset "alpaca_dataset" \
--num_workers_dataloader $NUM_WORKERS_DATALOADER \
--save_model \
--save_optimizer \
--save_interval_iteration 100 \
--save_checkpoint_path $CHECKPOINTS_PATH \
--load_checkpoint_path $CHECKPOINTS_PATH \
--use_mpi \
--use_fast_kernels \
--run_validation \
--wandb_entity "okoge" \
--wandb_project "llama-recipes-oss" \
--wandb_name "llama2-7b-gbs_${GLOBAL_BATCH_SIZE}-lr_${LR}-lrmin_${LR_MIN}-alpaca_dataset"
準備が整ったので job script を投入しましょう。サンプルスクリプトはABCI用になっているので、お使いの環境(AWS ParallelCluster, 研究室サーバーなど)に合わせて変更してください
jobを投入してしばらく待つとwandbに以下のような結果が得られます。
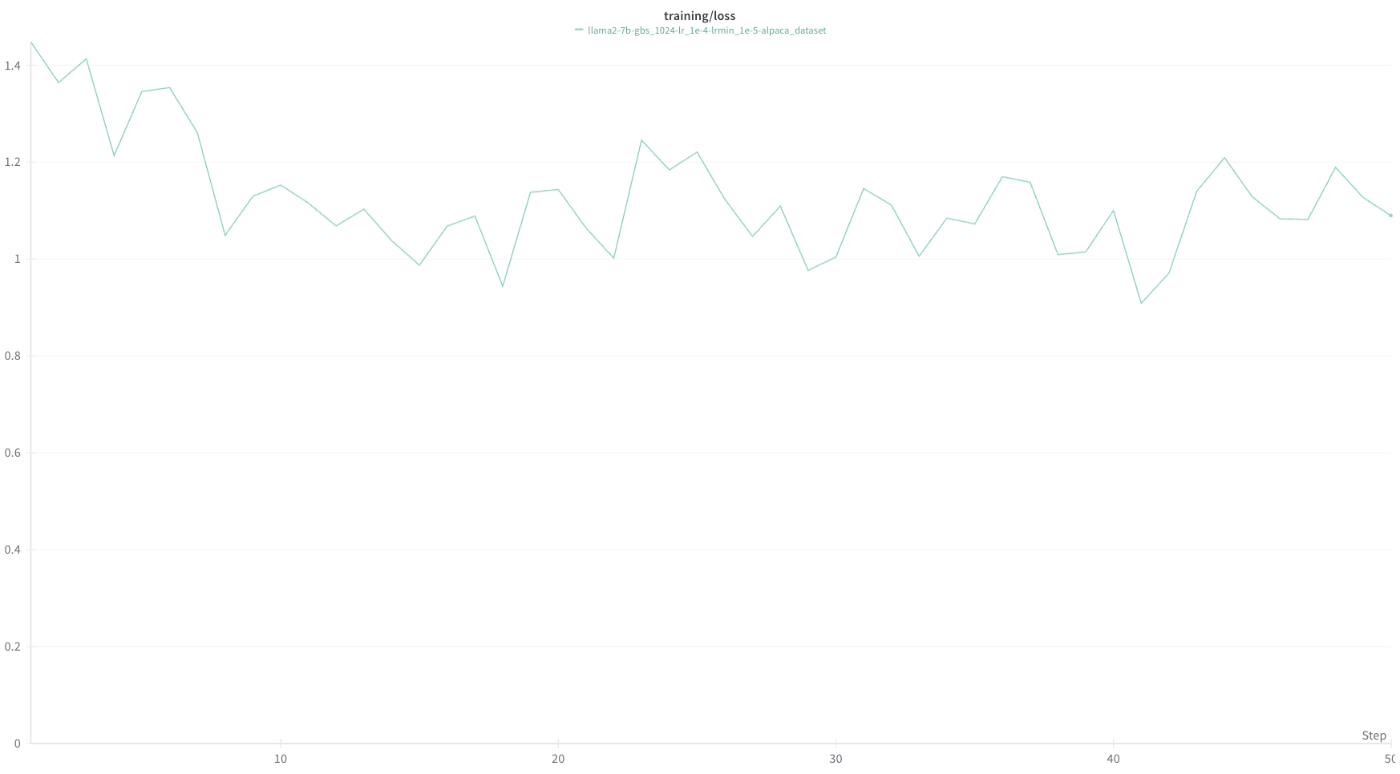
wandbには様々な数値が記録されています。Loss, Perplexityだけでなく、otpimizer stateや、learning rateの推移(下図)、1秒間に何Token処理したか(tokens_per_sec)などが記録されています。
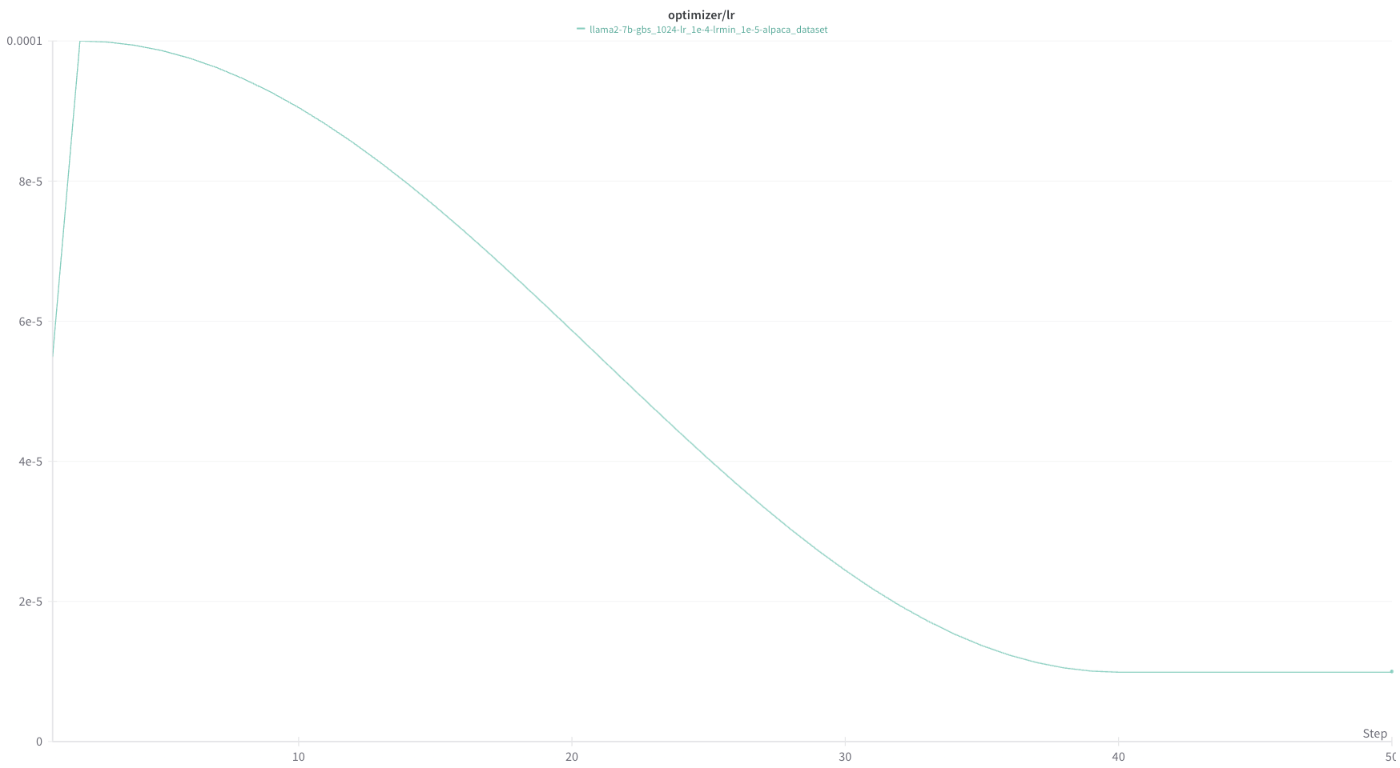
このtokens_per_secなどの数値を見ながら、最適な学習オプションを探索し、効率的な学習を行うことが可能になります。
継続事前学習 (Continual Pre-Training)
先程は指示チューニングを行いましたが、次は継続事前学習(Next Token Prediction)を行ってみましょう。
Wikidumpから適切に整形して、以下のような形にしてください。

このようなデータに整形できたら、学習準備のために以下を行います。
(公開されているkotoba-recipesを利用している場合は、追加実装の必要はありません。)
独自データセットの作成
src/llama_recipes/datasets/wikipedia_dataset.pyにファイルを作成します。
import json
import torch
from torch.utils.data import Dataset
from transformers import PreTrainedTokenizer
from typing import Type
from llama_recipes.configs.datasets import wikipedia_dataset
from pathlib import Path
import os
class WikipediaDataset(Dataset):
def __init__(
self,
dataset_config: Type[wikipedia_dataset],
tokenizer: PreTrainedTokenizer,
partition: str = "train",
) -> None:
# keys: alignment_score, instruction, input, output, lang_pair
self.data_file_path: str = (
dataset_config.train_data_path if partition == "train" else dataset_config.val_data_path
)
self.max_words: int = dataset_config.context_size
self.tokenizer: PreTrainedTokenizer = tokenizer
dataset_dir = Path(self.data_file_path).parent
index_cache_dir = dataset_dir / ".index_cache"
os.makedirs(index_cache_dir, exist_ok=True)
index_file_path = index_cache_dir / str(os.path.basename(self.data_file_path)).replace(".jsonl", ".idx")
self.index_file_path: str = str(index_file_path)
try:
with open(self.index_file_path, "r", encoding="utf-8") as f:
self.indexes: list[int] = [int(line.strip()) for line in f]
except Exception as e:
print(f"index file error: {e}")
exit(1)
def __len__(self) -> int:
return len(self.indexes)
def __getitem__(self, index: int) -> dict[str, torch.Tensor]:
IGNORE_INDEX = -100
with open(self.data_file_path, "r", encoding="utf-8") as file:
offset: int = self.indexes[index]
file.seek(offset)
try:
line = file.readline()
except Exception as e:
print(f"index={index}, offset={offset}, error={e}")
exit(1)
try:
ann: dict[str, str] = json.loads(line)
except Exception as e:
print(f"index={index}, offset={offset}, line={line}, error={e}")
exit(1)
text: str = ann['text']
encoded_text: list[int] = self.tokenizer.encode(text=text)
encoded_text.append(self.tokenizer.eos_token_id) # type: ignore
encoded_text_tensor = torch.tensor(encoded_text)
padding_size: int = self.max_words - encoded_text_tensor.size(0)
if padding_size > 0:
padding = torch.zeros(padding_size, dtype=torch.long)
encoded_text_tensor = torch.cat((encoded_text_tensor, padding))
elif padding_size < 0:
encoded_text_tensor = encoded_text_tensor[:self.max_words]
input_ids: torch.Tensor = encoded_text_tensor
labels: torch.Tensor = encoded_text_tensor.clone()
labels[0:-1] = labels[1:].clone()
labels[-1] = IGNORE_INDEX
attention_mask: torch.Tensor = torch.ones(self.max_words, dtype=torch.long)
attention_mask[encoded_text_tensor == 0] = 0
return {
"input_ids": input_ids,
"labels": labels,
"attention_mask": attention_mask,
}
次にsrc/llama_recipes/configs/datasets.pyに
@dataclass
class wikipedia_dataset:
dataset: str = "wikipedia_dataset"
context_size: int = 4096
train_split: str = "train"
test_split: str = "val"
train_data_path: str = ""
val_data_path: str = ""
を追加します。さらにsrc/llama_recipes/datasets/__init__.py, src/llama_recipes/datasets/__init__.py, src/llama_recipes/utils/dataset_utils.pyに以下を追加します。
from llama_recipes.datasets.grammar_dataset.grammar_dataset import get_dataset as get_grammar_dataset
from llama_recipes.datasets.alpaca_dataset import InstructionDataset as get_alpaca_dataset
from llama_recipes.datasets.samsum_dataset import get_preprocessed_samsum as get_samsum_dataset
+ from llama_recipes.datasets.wikipedia_dataset import WikipediaDataset as get_wikipedia_dataset
from llama_recipes.datasets import (
get_grammar_dataset,
get_alpaca_dataset,
get_samsum_dataset,
+ get_wikipedia_dataset,
)
...
DATASET_PREPROC = {
"alpaca_dataset": partial(get_alpaca_dataset, max_words=2048),
"grammar_dataset": get_grammar_dataset,
"samsum_dataset": get_samsum_dataset,
"custom_dataset": get_custom_dataset,
+ "wikipedia_dataset": partial(get_wikipedia_dataset)
}
index_cacheの利用方法
数B token程度のデータセットになるとJSONLデータをすべて以下のように読み込む形では、時間がかかってしまいます。そこで事前にindexファイルを作成し、効率的にrandomアクセスが可能なようにします。
json.load(open(dataset_config.data_path))
私の環境で実際に使用したindexファイルを作成するためのjob scriptはtools/pre-process/scripts/index.shになります。(注意: GPUは使用しませんん)
以下のように.index_cacheが作成されます。
> ls -la
4096 Nov 28 15:57 .
drwxrws--- 7 user_name group_name 4096 Oct 8 02:46 ..
drwxr-s--- 2 user_name group_name 4096 Nov 28 16:00 .index_cache
-rw-rwx--- 1 user_name group_name 6144560051 Oct 5 02:13 merged_train_0.jsonl
実際の学習
以上の手順で準備が完了したので、実際に学習を行ってみましょう。
scripts/llama/next_token/llama2-7b-wikipedia.shにサンプルスクリプトがあります。こちらを各自の環境に合わせて変更してください。
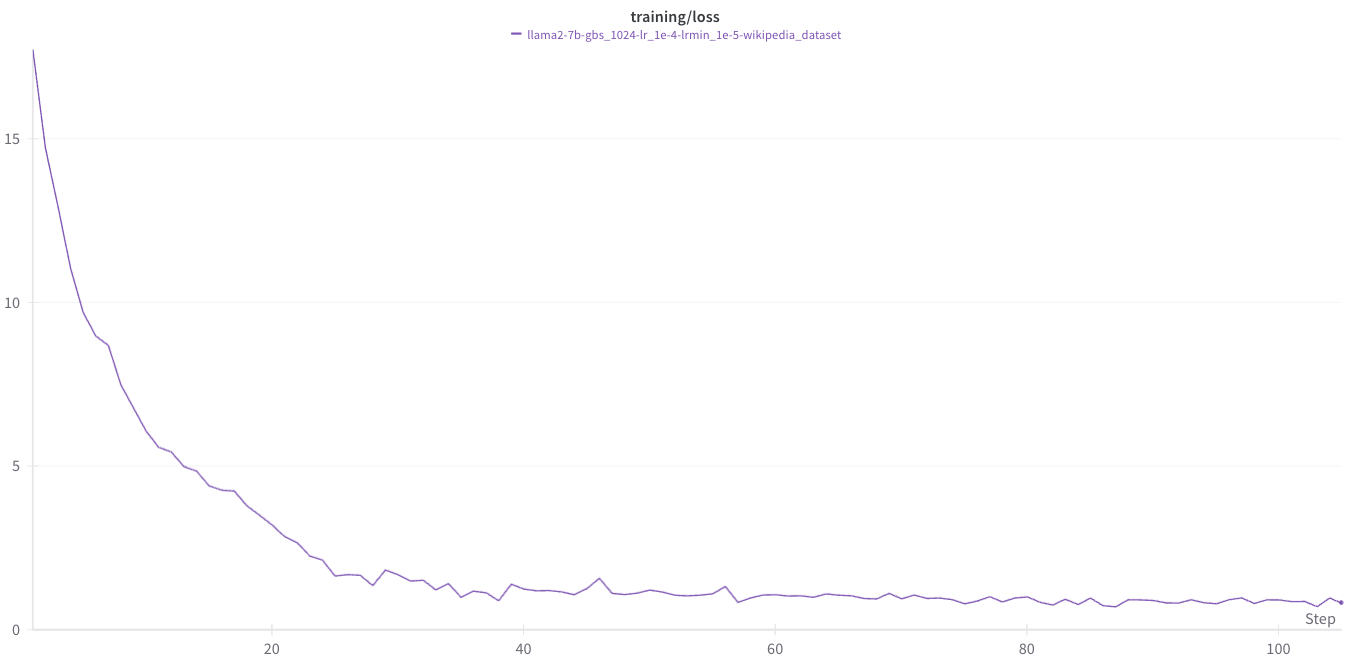
しばらくすると以下のようなLoss curveが得られます。
checkpoint convert
checkpointをHuggingFace形式にconvertして、transformersから読み込めるようにするにはtools/checkpoint-convert/convert_ckpt.pyを利用します。(後述するhttps://github.com/iwiwi/epochraft-hf-fsdp のスクリプトを参考に作成しました)
checkpoint convertを行なうための具体的な使用方法についても、scriptを用意していますので、適時それぞれの環境に合わせて変更してください。
tools/checkpoint-convert/scripts/convert.sh
#!/bin/bash
#$ -l rt_AF=1
#$ -l h_rt=10:00:00
#$ -j y
#$ -o outputs/convert/
#$ -cwd
# module load
source /etc/profile.d/modules.sh
module load cuda/11.8/11.8.0
module load cudnn/8.9/8.9.2
module load nccl/2.16/2.16.2-1
module load hpcx/2.12
set -e
# swich virtual env
source .env/bin/activate
# distributed settings
export MASTER_ADDR=$(/usr/sbin/ip a show | grep inet | grep 192.168.205 | head -1 | cut -d " " -f 6 | cut -d "/" -f 1)
export MASTER_PORT=$((10000 + ($SLURM_JOBID % 50000)))
echo "MASTER_ADDR=${MASTER_ADDR}"
# fsdp
start=600
end=800
increment=200
for ((i = start; i <= end; i += increment)); do
ITERATION=$i
FORMATTED_ITERATION=$(printf "iter_%07d" $ITERATION)
CHECK_POINT_PATH=/path/to/${FORMATTED_ITERATION}/model.pt
OUTPUT_PATH=/path/to/instruction/initial/normal/hf_checkpoint
echo "convert ${CHECK_POINT_PATH} to ${OUTPUT_PATH}"
mkdir -p $OUTPUT_PATH
BASE_MODEL_CHECKPOINT=/path/to/llama2/Llama-2-7b-hf
mpirun -np 8 \
--npernode 8 \
-x MASTER_ADDR=$MASTER_ADDR \
-x MASTER_PORT=$MASTER_PORT \
-bind-to none -map-by slot \
-x PATH \
python tools/convert_ckpt.py \
--model $BASE_MODEL_CHECKPOINT \
--ckpt $CHECK_POINT_PATH \
--out $OUTPUT_PATH
done
checkpoint upload to HF
HuggingFace形式に変換したcheckpointをモデルHubにuploadしてみましょう。
以下のスクリプトを利用することで簡単にモデルをuploadできます。
import os
import argparse
from huggingface_hub import HfApi, create_repo
parser = argparse.ArgumentParser()
parser.add_argument("--ckpt-path", type=str)
parser.add_argument("--repo-name", type=str)
parser.add_argument("--branch-name", type=str, default="main")
args = parser.parse_args()
converted_ckpt: str = args.ckpt_path
repo_name: str = args.repo_name
branch_name: str = args.branch_name
try:
create_repo(repo_name, repo_type="model", private=True)
except Exception as e:
print(f"repo {repo_name} already exists! error: {e}")
pass
files = os.listdir(converted_ckpt)
api = HfApi()
if branch_name != "main":
try:
api.create_branch(
repo_id=repo_name,
repo_type="model",
branch=branch_name,
)
except Exception:
print(f"branch {branch_name} already exists, try again...")
print(f"to upload: {files}")
for file in files:
print(f"Uploading {file} to branch {branch_name}...")
api.upload_file(
path_or_fileobj=os.path.join(converted_ckpt, file),
path_in_repo=file,
repo_id=repo_name,
repo_type="model",
commit_message=f"Upload {file}",
revision=branch_name,
)
print(f"Successfully uploaded {file} !")
こちらのscriptの仕様例はtools/model-upload/upload.shにあります。
新しいTransformersモデルを学習する場合
現在、公開しているライブラリでサポートしているのは LLaMA, LLaMA-2, Mistral 7Bのみです。
しかし、他のモデルでも以下のファイルを変更すれば学習可能です。
from transformers import LlamaConfig, LlamaForCausalLM, MistralForCausalLM
from llama_recipes.configs import train_config
from typing import Type
from llama_recipes.utils.distributed import is_rank_0
import torch
def get_model(train_config: Type[train_config], use_cache: bool = False) -> LlamaForCausalLM | MistralForCausalLM:
"""return CausalLM model
Args:
train_config (Type[train_config]):
use_cache (bool, optional):
Raises:
NotImplementedError: currently only supports LlamaForCausalLM and MistralForCausalLM
Returns:
LlamaForCausalLM | MistralForCausalLM: PyTorch model
"""
if "Llama" in train_config.model_name:
if train_config.enable_fsdp and train_config.low_cpu_fsdp:
"""
for FSDP, we can save cpu memory by loading pretrained model on rank0 only.
this avoids cpu oom when loading large models like llama 70B, in which case
model alone would consume 2+TB cpu mem (70 * 4 * 8). This will add some communications
overhead.
"""
if is_rank_0():
model = LlamaForCausalLM.from_pretrained(
train_config.model_name,
load_in_8bit=True if train_config.quantization else None,
device_map="auto" if train_config.quantization else None,
use_cache=use_cache,
)
else:
llama_config = LlamaConfig.from_pretrained(train_config.model_name)
llama_config.use_cache = use_cache
with torch.device("meta"):
model = LlamaForCausalLM(llama_config)
else:
model = LlamaForCausalLM.from_pretrained(
train_config.model_name,
load_in_8bit=True if train_config.quantization else None,
device_map="auto" if train_config.quantization else None,
use_cache=use_cache,
)
return model # type: ignore
elif "Mistral" in train_config.model_name:
mistral_max_length: int = 4096
sliding_window: int = 4096
model = MistralForCausalLM.from_pretrained(
train_config.model_name,
load_in_8bit=True if train_config.quantization else None,
device_map="auto" if train_config.quantization else None,
use_cache=use_cache,
sliding_window=sliding_window,
max_position_embeddings=mistral_max_length,
use_flash_attention_2=True,
)
return model # type: ignore
else:
raise NotImplementedError("model not implemented")
上記のコードのように、サポート対象外のモデルが渡された場合は NotImplemntedError が発火するようになっています。そのため、 elif "Mistral" in train_config.model_name:のelifブロックの下に
elif "Mistral" in train_config.model_name:
mistral_max_length: int = 4096
sliding_window: int = 4096
model = MistralForCausalLM.from_pretrained(
train_config.model_name,
load_in_8bit=True if train_config.quantization else None,
device_map="auto" if train_config.quantization else None,
use_cache=use_cache,
sliding_window=sliding_window,
max_position_embeddings=mistral_max_length,
use_flash_attention_2=True,
)
return model # type: ignore
+ elif "gpt-2" in train_config.model_name:
のように追加して、モデルを読み込む箇所を追加すれば、新しいモデルの学習を行うことができます。
類似ライブラリ
開発を行う際に、私が非常に参考にさせていただいたリポジトリです。
HuggingFace Trainerのような使用感で利用できるだけでなく、GPT-NeoXのconfigファイルのように学習の設定をYAMLファイルに記すことができます。
我々のKotoba Recipes同様にTransformersで利用可能な言語モデルを学習できるように設計されているので非常に有用なライブラリです。
shell scriptに学習設定などもまとめたい場合は、Kotoba Recipesを利用し、YAMLファイルとshell scriptに分割して管理したい場合はepochraft-hf-fsdpを利用するといった形で利用者の好みに合わせて利用頂けます。
さいごに
この記事では PyTorch FSDP を利用した分散学習ライブラリである Kotoba Recipesの使用方法について説明しました。
今回の記事で分散並列学習に興味が湧いた方は、大規模モデルを支える分散並列学習のしくみ Part 1 をご覧ください。
本記事では使用方法を中心に解説しましたが、ライブラリを構成しているPyTorch FSDP, BetterTransformerなどについて解説を行う記事を執筆予定です。
また、社内ではLlama, Mistral 以外のモデルについても学習できるように拡張を行い、学習できることを検証済みです。こちらについても、追加で記事を執筆することを検討中です。
Kotoba Technologies では、大規模言語モデルの実用化を中心に幅広い研究開発を行っています。
今回の記事で興味が湧いた方は私や、CEOの小島さん、CTOの笠井さんのX(Twitter) のDMからでもお気軽にご連絡ください。

Discussion