実は単純?良品学習入門!
前回のお話
こんにちは!Adacotech(アダコテック)でエンジニアをしています、井上 耕太朗です。前回は以下の記事にてアダコテックのコア技術であるHLACについて解説しました!
そして今回はアダコテックのもう一つのキーワードでもある良品学習について解説しようと思います。ちょっと機械学習ワカルという方には『教師なし学習による異常検知』がズバリのアルゴリズムです。難しそうに見えますがコンセプトは単純で、「良品データのみを学習し、未知の不良(異常)を検知する」ことを目的とする機械学習手法の一つです。
教師なし学習と異常検知
教師なしとは?我が心の師は安西先生だけなんだが?という方もいると思いますが、教師なし学習は事前にアノテーションという「これは良品」「これは不良品」という正解情報を与えることなく機械学習モデルを作成する手順のことを意味します。そして異常検知とは普段と何かが違うことを検出する技術です。
一体明日のご飯もおかずも分からない我々にそんなことが可能なのでしょうか?ここではまず正常とは何かという根源的な問題から明らかにし、良品学習(教師なし異常検知)の実装までやっていこうと思います。
そもそも正常って何なんだ?
異常を知るためには正常とは何なのかを理解するところから始めなければいけませんが、人間は知能が高すぎるが故、既に正常/異常とは何たるかを言語化するまでもなく、誰の教えもなく認識することができます。まず見ていただきたいのは次の画像です。

図1: 異常のある画像
この画像には異常があるのですがどの部分が異常っぽいか皆さんには分かると思います。おおよそ人類の99.9%ぐらいはこの画像を見て赤い星が異常と思うことでしょう。しかし理由はなぜでしょうか?なぜ青い星は異常ではないのでしょうか?これらの問いに対し
- たった1つだけ色違いだから
と答えるならば、やはりあなたの知能は高すぎます。高すぎるが故、アウストラロピテクスから500万年にもおよぶ進化・学習時間によってカリカリにチューンナップされた脳で行われた偉業の数々を理解できていません。正常と異常を根底から理解するには、地球のことなど何もわからなかったけどマンモスの味は知っていたあの頃を思い出し、図1の範囲を少し広げた次の画像を見ていただきたいです。

図2: 図1の少し広い範囲の画像
図2は図1を少し広い範囲で見た図です。さて、このあたりから人類の5%と95%程度で意見が分かれそうな部分ですが、この画像で異常といえば青い星が異常と思う人が多いと思います。先程は赤い星が異常だと感じたのに、一体これはどういうことなのでしょうか?我々は判断を誤ったのでしょうか? さらに深淵に迫ってみましょう。

図3: 少し傾向が異なる異常のある画像
私にはあなたのニューロンの叫びが聞こえます。青い星が異常っぽい気配を感じますが、一際輝く異常な部分は以下の赤丸ではないでしょうか?

図3で異常っぽい部位
図3の例ではもしかしたら色の違いなんて実は異常ではなく、星の回転が異常なのかもしれません。
・・・
えっ、異常の答えを私に問うのですか?私は知りません! 5000兆円を目の前に積まれようが私は本当に知らないですし、知りようがないのです。どうしても図3で異常を定義するなら、やはり「回転した青い星」で良いのでは…?
"正常"とはデータ次第
嘘をつくんじゃない!いいから本当の異常を教えて!という方向けに図2からさらに全体を見渡した画像例を以下に示します。

図4: 図2のさらに外側の画像
何だか赤と青が異常っぽいと感じるならば、あなたの脳は健全です。
こんなの後出しジャンケンだよっ! というご指摘はごもっともですが、エンジニアやデータサイエンティストと呼ばれる人々が常に危惧(経験とも言う)しているのはこの現象なのです。 そして我々が良品学習に限らずあらゆるデータ解析において「最初になるべくたくさんのデータを用意してください」と泣いて懇願する理由です。あなたは部下や同僚に「ちょっとこのデータも追加でお願い♡」と軽い気持ちで分析をお願いしていませんか?もしかしたらそれはこれまでの大前提が崩れてしまうような黄色い星だったりする可能性があります。心当たりがあればいつか焼き肉でも奢ってあげてください!
少し話がそれましたが、いよいよ我々が直感的に感じる正常や異常という概念がいかに流動的なものかお気づきかもしれません。読者の方もこれまでの画像で経験したように、正常や異常は常に対象の分布次第で判断が容易に変わってしまうのです。
- 図1を見れば赤い星が異常っぽい
- 図2を見れば青い星が異常っぽい
- 図3を見れば回転した青い星が異常っぽい
- 図4を見れば青と赤の星が異常っぽい
そしてこれがまさしくあなたの脳内の無意識下で行われた良品学習なのです。
良品学習って何してる?
これまでの図1~4の画像を振り返って我々の感じる"正常"や"異常"とは入力次第でいかようにも変わることを実感していただけたと思いますが、我々の脳内で何が行われていたのでしょうか?それには無意識化で行われた処理を言語化していく必要があります。それぞれの図に対して自分であれば以下のように判断しますが、これがおおよそ平均的な人類の思考パターンではないでしょうか?
- 図1: 青い星が多数派なのだから、そこに赤い星が入るのは変だ
- 図2: 今度は赤い星が多数派になるのだから、青い星が変かもしれない
- 図3: 多くの星の角度が同じなのに、一つだけ回転しているのは変だ
- 図4: 黄色い星が多数派なので、赤と青い星が例外的に存在するのかもしれない
あえて太字で言いたいことを言わせる感じですが、ここはご納得いただける部分だとおもいます。要するに人間は大局観を瞬時に割り出し、多数派とは異なる傾向を考えて正常と異常を分けています。 だんだんプログラム化できそうな気がしてきたのではないでしょうか?つまりおおよそ以下の手順を踏んでいるはずです。
- データの特徴を洗い出す
- 特徴から多数派の特徴を分析し、それに該当するものを正常として認識
- 逆に少数派の特徴を持つものを異常として認識
なかなか大変そうなのでPythonに手を出したくなってしまいますが、今回はよりお手軽な体験として現代オフィスの3種の神器の一つであるExcel(スプレッドシートでもOK)で異常検知を実装してみましょう!
Excel/スプレッドシートで簡単異常検知!
ここからは以下のスプレッドシートを元に話を進めます。
手元で再現したい方はコピーを作成して自由に編集してください。
データの特徴を洗い出す
何はともあれ分析に掛ける前に各画像から特徴を取り出さなくてはなりません。
できればHLACといきたいところですが、いきなり多次元データを扱うのは混乱するので、こちらでおおよそ図1で取り出せそうな特徴を書き出してみました。
- 星の頂点数
- 星の角度
- 星の色(光の三原色で表現)
だいたいこんなものではないでしょうか?
星の頂点数とか不要じゃない? という感想をお持ちの方は、すでに脳内で良品学習完了済みのニュータイプなので、ここはぐっとこらえてオールドタイプの話を聞いてください。これをテーブルで表現すると...
表1: 図1の特徴をデータ化した表
| ID | 頂点数 | 角度 | 赤 | 緑 | 青 |
|---|---|---|---|---|---|
| 1 | 5 | 290 | 0 | 0 | 1 |
| 2 | 5 | 270 | 0 | 0 | 1 |
| 3 | 5 | 350 | 0 | 0 | 1 |
| 4 | 5 | 270 | 0 | 0 | 1 |
| 5 | 5 | 350 | 0 | 0 | 1 |
| 6 | 5 | 270 | 0 | 0 | 1 |
| 7 | 5 | 280 | 1 | 0 | 0 |
のようになります。色は1(有)と0(無)で表現してみました。かなりテキトーに書き出しましたが、こんなものでいけるのでしょうか...?
多数派を平均で表現してみる
多数派が正常(良品)的な扱いをしたいのであれば平均は最も一般的な統計手法でしょう。ここでは先程の表1から各特徴の平均からの距離で異常検知っぽいことができないかトライしていみたいと思います。
数式から理解したいんだという方がこの記事を見ているか定かではありませんが、念の為以下に数式は載せておきます。ある列のデータを
上は縦棒
さて、役者はそろったので早速計算してみましょう!例としてスプレッドシートで計算してみます。スプレッドシートだとAVERAGE関数で好きな部分の平均値を計算することができます。
例としてA1~A10の平均値を計算する場合、
=AVERAGE(A1:A10)
表1だと平均値は以下のようになります。
| 頂点数 | 角度 | 赤 | 緑 | 青 |
|---|---|---|---|---|
| 5.00 | 297.14 | 0.14 | 0.00 | 0.86 |
ではこの平均値を使って平均からの差を計算してみましょう!
Excelであるとスプレッドシートであろうと単純にマイナス記号で計算できますが、参照を固定したいセルが例えばA1の場合、$A$1とすると右下ドラッグ技でも参照がずれないので便利です。
例: =B1-$A$1
表2: 図1の特徴の平均からの差
| 頂点数 | 角度 | 赤 | 緑 | 青 |
|---|---|---|---|---|
| 0.00 | -7.14 | -0.14 | 0.00 | 0.14 |
| 0.00 | -27.14 | -0.14 | 0.00 | 0.14 |
| 0.00 | 52.86 | -0.14 | 0.00 | 0.14 |
| 0.00 | -27.14 | -0.14 | 0.00 | 0.14 |
| 0.00 | 52.86 | -0.14 | 0.00 | 0.14 |
| 0.00 | -27.14 | -0.14 | 0.00 | 0.14 |
| 0.00 | -17.14 | 0.86 | 0.00 | -0.86 |
よく見ると平均からの差が0の列があります。これは平均と完全一致という意味なので、データに全く変化がない部分を意味します。なるほど平均からの差を見れば判断に必要なさそうな変数を省けそうなことが分かってきました!いよいよ教師なし異常検知の偉業を達成できそうです!
さて上記の表では平均に近いものの値が小さくなることから、逆に行の総和が大きいものは平均群から遠い物のはずで、要は多数決っぽいものが実現できてるはずです。各行には正負の値が混在しているので、平方和あるいは絶対値(ABS)をとれば完全な距離になります。Excelのご都合上SUMSQして平方根を取るほうが楽に書けるので、これを使用して各行の平均からの距離の合計を計算したグラフは以下のとおりです。

図6: 合計平均距離のプロット
あれ・・・なんか思ってたんとちょっと違う・・・
このままでは大きく回転したID3と5が異常っぽいことになります。そうです、このプロットは表2からも明らかなように、回転による影響がバカデカ過ぎるのです。
そんなことを言われても回転による異常だって考えられるわけで、色変化と回転のどちらの影響が大きいかなど感覚的に決めようもありません。
多数派を標準化距離で表現してみる
先程の計算ではそれぞれの値の平均からの距離を測定することで、各列での正常/異常のスコア化は正しい状態でした。しかし、それは単純に他のスコアと合算すると、もともとの評価値の値の大きさなどで他列の影響がかき消されることになります。
つまり、先程の平均距離作戦ではデータの中心(ド平均な存在)は確実に0となり、そこの評価は回転であろうが色であろうが変わりません。問題はそこからの距離の部分で、回転では0~360度に回転するので、数値上でも同様に0~360の幅がありえます。一方で色では有り無しを0と1で表現しているので、数値上の変化は0~1の幅でしかありえません。つまり平均から1度回転するのも、色変化もほぼ同列に評価されていたのです。
もっと身近な例えでいくと、普段より唐揚げを1つ多く食べるのと、カツ丼を1つ多く食べるのでは、同じ1でも重みが違うので、1カツ丼が何唐揚げに相当するのかバランスを取る必要があります。カロリー換算で揃えるというのも方法の一つではありますが、それでは今回のような色と角度といった全く異なる指標間でのバランスがわかりません。しかし、統計学にはこの一見無茶に思える比較を成立させる素敵な方法、標準化(正規化という人も多い) があります。

データを標準化する
先程の唐揚げとカツ丼を例にしてみましょう。「普段よりN個多く食べる」という事象に重み付けをする場合、多くの人がどの程度食べられるのかというデータはかなり大きな意味を持つことは直感的に理解できると思います。ではここに10人の無作為に抽出した日本人に唐揚げとカツ丼を限界まで食べさせた人道的なのか非人道的なのかよくわからないデータベースがあるとしましょう。
| ID | 唐揚げ(個) | カツ丼(杯) |
|---|---|---|
| 1 | 10 | 1.5 |
| 2 | 8 | 1.0 |
| 3 | 15 | 2.2 |
| 4 | 11 | 1.0 |
| 5 | 22 | 4.0 |
| 6 | 6 | 0.8 |
| 7 | 12 | 1.5 |
| 8 | 10 | 1.0 |
| 9 | 18 | 2.0 |
| 10 | 9 | 1.8 |
| ※カツ丼の小数点以下の余りはスタッフがおいしくいただきました。 |
先程の平均距離ではそれぞれの列に対して平均を求め(データの中心を求める)、多数派を表現していました。 今回も一旦計算してみると、
| ID | 唐揚げ(個) | カツ丼(杯) |
|---|---|---|
| 1 | -2.1 | -0.18 |
| 2 | -4.1 | -0.68 |
| 3 | 2.9 | 0.52 |
| 4 | -1.1 | -0.68 |
| 5 | 9.9 | 2.32 |
| 6 | -6.1 | -0.88 |
| 7 | -0.1 | -0.18 |
| 8 | -2.1 | -0.68 |
| 9 | 5.9 | 0.32 |
| 10 | -3.1 | 0.12 |
このようになります。こうしてみると、唐揚げとカツ丼には平均からの幅が大きく異なることがわかります。そしてこの幅をある規格に合わせることができれば、互いの1の価値を表現できます。 ここで広く一般的に用いられるブレ幅指標が標準偏差と呼ばるものです。
標準偏差
計算内容としては、『あるデータ群の平均からの差の二乗の平均の平方根』を求めることになり、ざっくりと『平均差分』的な概念に相当します。エクセルやスプレッドシートでは簡単にSTDEV関数で計算できます。
平均(AVERAGE)と同様に標準偏差を求めると、唐揚げ4.9個、カツ丼0.9杯となります。これは多くの人が平均からこの標準偏差の範囲で限界値がぶれていることを示します。唐揚げとカツ丼の平均はそれぞれ12.1個と1.7杯なので、唐揚げは7.2個~17個、カツ丼は0.8杯~2.6杯がおおよその範囲となります。何となくですが、あなたの男女混合の知人たちの限界量の振れ幅も多くはこの範囲に収まるのではないでしょうか?また、この幅を知ったことで、カツ丼を平均より1杯多く食べる人が唐揚げを平均よりどれぐらい多く食べることに相当するか? という問にも答えることができるはずです。これは標準偏差同士の割り算で
もうこれであなたもトリビアの泉が企画できるでしょう。今回のデータを元にすれば「カツ丼を平均より1杯多く食べられる人は、唐揚げを平均より5.2個多く食べられる(より正確には希少度的な価値が等価)」ということになります。

標準偏差で何だかいい感じに唐揚げとカツ丼のブレ幅がわかったので、これで先程の平均を引いた表を割ってみれば、いい感じに幅の揃った表ができるはずです。実際に計算してみると、以下のようになります。
| ID | 唐揚げ(個) | カツ丼(杯) |
|---|---|---|
| 1 | -0.43 | -0.19 |
| 2 | -0.84 | -0.72 |
| 3 | 0.59 | 0.55 |
| 4 | -0.23 | -0.72 |
| 5 | 2.03 | 2.46 |
| 6 | -1.25 | -0.93 |
| 7 | -0.02 | -0.19 |
| 8 | -0.43 | -0.72 |
| 9 | 1.21 | 0.34 |
| 10 | -0.63 | 0.13 |
このようにデータを標準化することで、異なる指標のものを比較することができます。たとえばID3の人は唐揚げとカツ丼を平均を同等程度上回る量を食べていますが、ID9の人はカツ丼よりも唐揚げを非常に多く食べていることがわかります。お米でお腹がいっぱいになるパターンの人かもしれません。
さて、では表1から標準偏差を求めると、以下のようになります。
| 頂点数 | 角度 | 赤 | 緑 | 青 |
|---|---|---|---|---|
| 0.00 | 34.11 | 0.35 | 0.00 | 0.35 |
そしてこれらの標準偏差で表2を割ると、次の表3が得られます。
表3: 図1の特徴の標準化距離
| 頂点数 | 角度 | 赤 | 緑 | 青 |
|---|---|---|---|---|
| 0.00 | -0.19 | -0.38 | 0.00 | 0.38 |
| 0.00 | -0.74 | -0.38 | 0.00 | 0.38 |
| 0.00 | 1.43 | -0.38 | 0.00 | 0.38 |
| 0.00 | -0.74 | -0.38 | 0.00 | 0.38 |
| 0.00 | 1.43 | -0.38 | 0.00 | 0.38 |
| 0.00 | -0.74 | -0.38 | 0.00 | 0.38 |
| 0.00 | -0.47 | 2.27 | 0.00 | -2.27 |
最終的に表3の各行の合計距離をプロットすると…

図7: 合計標準化距離のプロット
このように赤色のID7が大勢と異なることを標準化距離で表現できました!
コラム: 標準偏差
標準偏差とは、データが正規分布と呼ばれる数値分布を形成すると仮定したときに全体の約7割が観測可能な範囲です。このあたりの詳細は中心極限定理という統計の根本理論などと関連していますが、簡単にまとめると『たくさんデータを無作為に集めると、どのような母集団(データ群)でもある平均値と標準偏差で表現可能な正規分布に従う』という大変便利な定理です。もし多くのデータ数を集めても全く正規分布に従わないものがあれば、元のデータ群が変化しているのか、無作為抽出のつもりが無作為になっていないのか。とあるガチャの排出率が怪しいときには多くの人の排出までのガチャ回数からこの分布を調べて… おっとこんな深夜にお客さんとは珍しい
主成分分析でよりスマートな正常を表現する
さて、我々はデータの平均そして標準化という術を得ることで、ある程度正常の範囲を前知識(教師)無しで表現できるようになりました。これらの手法は正規分布が発見された1800年代の技術で、さらにその約100年後に今日でも盛んに利用される主成分分析と呼ばれる手法が発明されます。今回は令和最新版ならぬこの明治最新版の主成分分析の解説で良品学習を締めくくりたいと思います。
標準化距離の不足部分
標準化距離では各パラメータごとに値の中心とその振れ幅を規格化することで、パラメータ1つずつの正常っぽさからの距離を算出し、合算していました。しかしこれでは複数パラメータから総合的に判断して正常/異常となるような事象に対応できません。
たとえば昨今流行りのスマートウォッチには様々なセンサが付属し、心拍数計測や歩数計の機能がついていたりしますが、心拍数が急激に上昇することと、歩数計のカウントが急激に上昇することが同時に起こっているなら、それはおそらく正常でしょう。ただし、歩数計のカウントは全く変わらないのに心拍数が急激に上昇する、あるいは心拍数はそのままで歩数計だけが急激に上昇するのであれば何らかの異常の可能性があります。
この場合、心拍数と歩数計の間には運動という概念を介して関連があるため、お医者さんは心拍数と歩数計のグラフを並べてみたところで変に思うことはありませんが、スマートウォッチが各指標の標準化距離だけで判断すれば、ほぼ24時間どこかのタイミングでアラートを出すようなポンコツウォッチになってしまいます。
さて、このような問題を解決する術があるのでしょうか?先程関連があるの部分でピンとくる方がいれば、あなたはもうデータサイエンティストです。そう、HLACにも使われる相関がこの問題を解決します。
共分散行列との再会
共分散行列という単語を聞いてブラウザバックするのは待ってください!
前回のお話で相関を理解したあなたであれば、共分散(covariance) は相関を算出するまでに出てきたお話です。
あるデータ
と X があるとき、その相関 Y は以下の式で計算できます。 \rho
\rho=\frac{\mathrm{cov}(X,Y)}{\sigma_X\sigma_Y}=\frac{平均(Xの平均からの差\times Yの平均からの差)}{Xのばらつき\times Yのばらつき}
要は2パラメータあったとき、それぞれのパラメータの平均からの差(標準偏差)同士の積の平均です。 共分散は2パラメータ間の増減傾向の一致度を測る指標なので、例えばAとBパラメータが共に増える/減るときに共分散は正の方向に、AとBが互いに異なる増減傾向にある場合は負の方向に大きくなります。ではこの共分散はともかく、共分散の行列とはどういうことなのでしょうか?
共分散行列とは、先程の共分散をすべてのパラメータ同士で計算したものです。難しく考える必要はありません、本当に単純にすべての組み合わせで共分散を計算すれば共分散行列になります。ExcelであればCOVAR関数で計算可能で、例えば表3の共分散行列は以下のようになります。
表4: 表3の共分散行列
| 頂点数 | 角度 | 赤 | 緑 | 青 | |
|---|---|---|---|---|---|
| 頂点数 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 角度 | 0.00 | 1.00 | -0.21 | 0.00 | 0.21 |
| 赤 | 0.00 | -0.21 | 1.00 | 0.00 | -1.00 |
| 緑 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 青 | 0.00 | 0.21 | -1.00 | 0.00 | 1.00 |
行列の対角成分に特に大きな意味はありませんが、着目すべきはそれ以外の部分です。例えば赤と青の関係を見ると-1となっており、これらは完全に増減傾向が反転したパラメータということがわかります。一方で角度と色では±0.21とあまり関連度が高くなさそうな傾向が見えています。
さて、人生二週目な方はもうお気づきかもしれませんが、実はこの共分散行列が人間の考えるような正常空間そのものだったりします。というのも、別傾向のデータが入力された時点で共分散行列の値は変化し、正常空間がデータ傾向に対して適応的に変化してくためです。
たとえば青い星のデータのみで共分散行列を計算すると以下のようになります。
表5: 青い星のみで計算した共分散行列
| 頂点数 | 角度 | 赤 | 緑 | 青 | |
|---|---|---|---|---|---|
| 頂点数 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 角度 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 |
| 赤 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 緑 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 青 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
この表5が意味するところは、色の共分散はすべて0 = 色は全く変化しないということを表現しています。だんだん共分散行列の表現力が人間の思考力と遜色ないことがわかってきたのではないでしょうか。
共分散行列を元にデータをスコア化するには?
先程の共分散行列で正常をよりスマートに表現できるようになったのはいいのですが、次に困るのはそこからの逸脱度の計算です。新しいデータを追加するたびに共分散行列を再計算してその変動具合を測るというのも1つの手ですが、もっとスマートでエレガントな手法が固有値・固有ベクトルを求める手法です。
固有値・固有ベクトルと聞いて古傷がある方もない方もご安心ください!まず固有値問題の振り返りからですが、固有値問題とはある正方行列
これは数学の先生が再試という名の休憩時間を得るための難問のようにも思え、ちょっと何言ってるのか意味わからないですね。この式は日本語に直すと、「ある行列の線形変換後に大きさだけが変わるベクトルとその大きさを計算したい」 という何とも変態的な願望です。線形変換というのも割と意味わかりませんが、これはあるルールに従った掛け算と考えてください。たとえばある二次元座標を定義するxとyがそれぞれ1として、yの値だけ2倍にするといった操作が線形変換です。
一体こんなものを求めて何になるというのでしょうか?
実はこの固有値問題の価値は手元にペンが一本あれば雰囲気がわかると思います。手でペンの根本をもっててきとーにフリフリしたとき、その先端の動きは線形変換的な感じになります。イメージとしては次の図のような動きです。
| 3次元空間を動く点までのベクトル | 2つの視点を考える |
|---|---|
 |
 |
視界を二次元平面としたとき、ある角度からこのフリフリをみると先端が直線的な動きをすると思います。たとえば上の図ではAとBから見た動きは下の図のようになります。
| A(2次元で表現可能) | B(1次元で表現可能) |
|---|---|
 |
 |
視点Aはペンの動きを録画しただけのような感じですが、視点Bは1次元的な動きになっています。この視点Bを求めることが固有値問題を解くことに相当します。この視点Bを表現するのが固有ベクトル、そこから見える点の動き幅が固有値です。
視点Bの素晴らしさといえば筆舌に尽くし難いですが、視点Bは本来3次元情報である空間座標をたった1次元の大小で表現できる大変希少な視点なのです。これは言い換えればある多次元データ群に対して説明性の高い情報を1次元とりだしたということになります。勘違いしてはならないのは、3つある情報のうち2つを削除したのではなく、3つを考慮した上で1つのスコアとして統合しています。
そうこれこそが主成分分析です。さっそくこれを先程の共分散行列に適用し、説明性の高いイケてる固有ベクトルを求め、スコア化に挑みたいと思います。
固有値・固有ベクトルをべき乗法で求める
固有値・固有ベクトルが分かれば、正方行列の何だか素晴らしく説明性の高い表現空間が見つかることがわかりました。そこで共分散行列の固有値・固有ベクトルを求めたいわけですが、一体どうすれば…
Pythonを使えば0.1秒以内に答えが出てくる便利パッケージ(scikit-learn)があるのですが、ここは1つ古典的な方法で行列の固有値・固有ベクトルを求めてみましょう。方法の名前はべき乗法と呼ばれる方法で、簡単にまとめると線形変換マシマシにしてドデカいベクトルが出てくればそれが固有値、そして固有ベクトルになるという手法です。
やることは至って単純で、1回目の
Excelでの書き方を説明すると案外ボリューミーなので、ここは冒頭のスプレッドシートを参考にしてください。最終的に表4の共分散行列から得られる最初の固有ベクトル(第1主成分ともいう)は以下のようになります。
| 頂点数 | 角度 | 赤 | 緑 | 青 |
|---|---|---|---|---|
| 0.00 | 0.26 | -0.68 | 0.00 | 0.68 |
これが意味するところは先程のイケてる1次元化に関する情報で、この比率でデータを積和すれば、表4の共分散行列で表現される情報で重要なものがピックアップできます。内容を見てみると、まず頂点数と緑は0で情報量として意味を成さないことがわかります。また角度は0.26と赤や青の±0.68より小さく、あまり重要ではないことがうかがえます。
では実際に各列の積和(SUMPRODUCT)を計算してプロットすると以下のようになります。

図8: 第1主成分のスコア
やはりID7の赤色はかなり普通ならざるものであることがわかります。
同じ要領で共分散行列から第1主成分の情報を取り除き、もう一度べき乗法にかけて固有ベクトルを求めると、第1主成分ほどではないがそこそこ有用な第2主成分を求めることができます。以下に第2主成分を求めた結果を示します。
| 頂点数 | 角度 | 赤 | 緑 | 青 |
|---|---|---|---|---|
| 0.00 | -0.97 | -0.18 | 0.00 | 0.18 |

図9: 第2主成分のスコア
第2主成分では一転して角度が-0.97と非常に重要視されています。それもそのはず、色情報の次に値が変動しているのは角度しかないからです。
最後に第1と第2主成分の合計得点のプロットを示します。
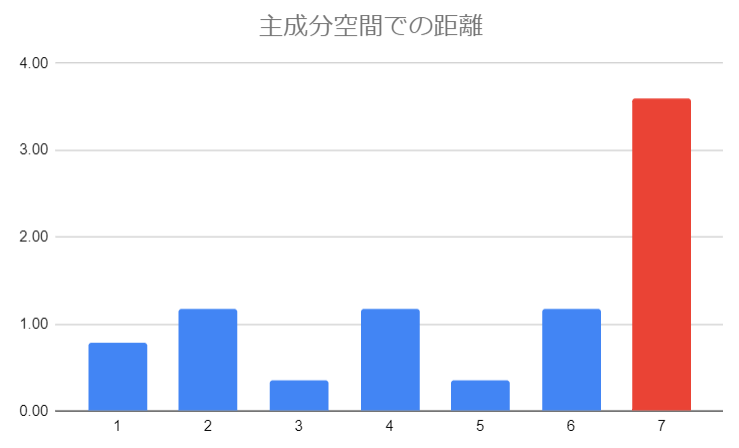
そんなに標準化距離と変わらないと感じる方もいるかもしれませんが、データの次元数の圧縮という効果は実はかなり偉大なことで、以下のようにもともと5次元のデータを2次元プロットとして表現することが可能となります。

図10: 主成分空間での座標
図から明らかなように、赤と青の点には座標で大きな差があり、一本の線を引けば簡単に分離できそうなこともわかりますね! これは線形判別という手法になります。
まとめ: 良品学習って?
いかがだったでしょうか!
今回は正常とは何かという部分から、データに対して適応的な良品学習手法について原始的な手法から近代的な手法まで一通り紹介しました。
正常という概念は常に入力の多数派によって変わることを起点とし、人間の事前知識なしで良品学習(異常検知) を実現するには、正常をいかに柔軟に表現できるかが鍵となることを説明しました。今回紹介した3手法には以下の特徴があります。
- 平均距離による正常表現 (単一パラメータでの正常定義ができる)
- 標準化距離による正常表現 (複数パラメータでの単純な正常定義ができる)
- 主成分分析による正常表現 (複数パラメータ間の関係も含めた正常定義ができる)
良品学習に限らず、どれも統計の基本的な手法なので皆さんの身近な課題にも応用できる部分は多いと思います。ぜひご活用ください!
メンバー募集中です!
HLACを活用した事業に興味が出てきましたか?であれば一度弊社代表のノートをご確認ください!
Wantedlyにてエントリーも受付中です!
Discussion