Qwen3-VL で自動アノテーションツール作ってみた
Qwen3-VL をローカルで使用して、任意のクラスに対応した自動アノテーションツールを作ってみました。
この記事では、コーディングエージェントを活用したこのツールの作り方と、Qwen3-VL のアノテーション性能について確認します。
背景
Qwen3-VL の cookbook のひとつに 2D 物体検出があります。
VLM としては Gemini 2.0 で最初に追加された機能ですが、 YOLO 等の物体検出モデルに必要な構造(矩形の後処理等)をまったく経由せずにモデルから直接出力されるのに驚いた記憶があります。
そんな機能がローカルで実現できるということで、個人情報を含む物体検出モデル(顔認識など)のアノテーションにとても役に立つのでは、と考えました。
ツール作成
まずは、今回作ったツールについて説明します。
環境
環境としては、API サーバー・フロントエンドのウェブサーバーどちらも ubuntu 24.04 + RTX4090 (24GB) を使っています。(機材の都合で同じマシンに立ち上げていますが、フロントエンド側には GPU は不要です)
API
まず、 vLLM を使って Qwen3-VL が使える API を立てます。今回はこちらの記事の手順をそのまま使用させていただきました。
uv venv -p 3.12
. .venv/bin/activate
uv pip install vllm
vllm serve \
QuantTrio/Qwen3-VL-30B-A3B-Instruct-AWQ \
--dtype half \
--gpu-memory-utilization 0.9 \
--kv-cache-dtype fp8 \
--max-model-len 16384 \
--max-num-seqs 1 \
--host 0.0.0.0 \
--port 8000
30B の AWQ モデル(主に 4bit 量子化)なので、 20GB ほど使っていることが確認できます。

フロントエンド
次に、この API を使って物体検出を行うアプリケーションを作成します。今回は、ほぼすべてのコードを Qwen-Code (Qwen3-Coder-480B + さくらの AI Engine) に書いてもらいました。
入力トークン数は 5,678,704 、出力トークン数は 85,729 ということで、従量課金の場合 191.8 円で作ることができました。281回のリクエストが発行されたので、月3000回の無料枠で同じ規模のアプリが10個作れる計算です。
かかった時間は3時間ほどでした。完全放置の vibe coding というわけではなくて、かなり対話的に手出しをしています。(試してませんが SOTA なエージェント、たとえば gpt-5-codex とかだともっと自律的に動いてくれるはず…)
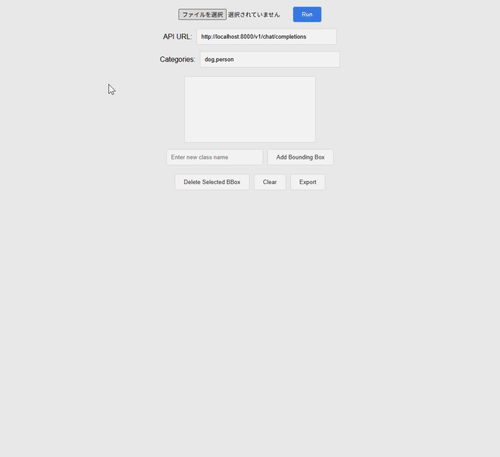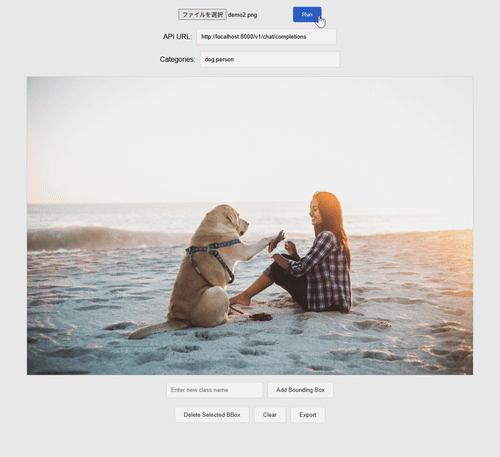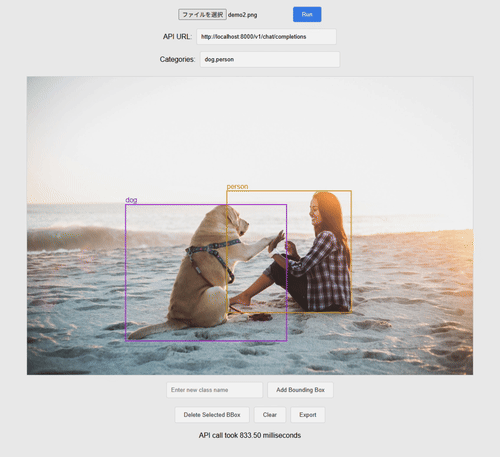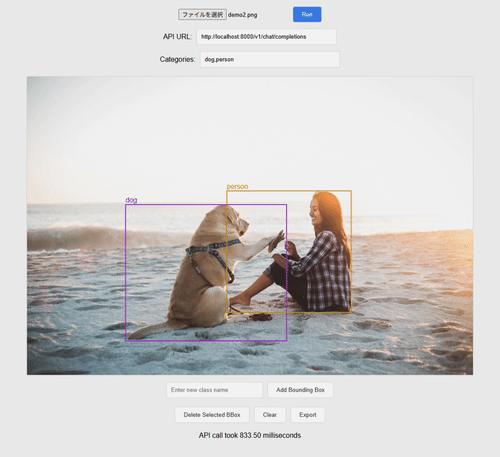
UI と動作の例はこんな感じです。ファイルを選択して、API の URL と検出したいカテゴリを入れて Run ボタンを押すと、そのカテゴリに応じた検出枠が出力されます。
簡易的なアノテーションツールとして使えるように、出力結果の手動修正やエクスポート機能も入れてみました。

実際に使うときは、複数画像のバッチ処理や特定形式(COCO形式など)でのエクスポートが必要になると思われますが、今回は簡単な検証用なのでこれで十分と判断しました。
動作確認
このツールを使って、 cookbook に含まれる画像を中心にいくつかの画像で性能を確認してみます。
精度
まずは cookbook に挙げられていた最初の例を見てみます。認識対象のカテゴリを plate/dish, scallop, wine bottle, tv, bowl, spoon, air conditioner, coconut drink, cup, chopsticks, person と指定して実行すると次の画像が得られました。

いくつか検出ミスはありますが、多くのオブジェクトが正しく検出できていることがわかります。
- 検出漏れ
- 左上のベリーが載った透明なお皿
- 右上のホタテが載った黒いお皿
- 中央のロブスターが載った銀色のお皿
- 誤検出
- 右上端の影に黄土色(
personラベル)の矩形 - 中央のびんに水色(
wine bottleラベル)の矩形
- 右上端の影に黄土色(
- 過検出(これは NMS をすれば問題ない)
- 右下・左下のコップ
位置精度としては、やはり数ピクセル程度の誤差がどの矩形にも見られます。ただ、一からアノテーションする場合にもまず矩形を描画してクラス等のラベルを指定し、それから位置を微修正して完成、という流れになると思うので、最後の仕上げ以外がすべて終わっていると思うとかなりの効率化になるのではと思いました。
バックエンドが VLM なので、クラスを自由に変更できるのが強みです。たとえば、同じ画像・同じモデルのまま検出対象クラスを shrimp, lobster, fish とすると次の結果が得られます。

意図通りに正しく検出できていることが分かります。
次に、空撮した画像の検出を試してみます。クラスは car, bus, truck, bicycle とします。

ほとんどの車が検出できていますが、影の部分を拾ってしまうことがありアノテーションとしては微妙でしょうか。また bicycle はかなり小さいオブジェクトなので見逃されがちです。
クラスを white_car, black_car, colored_car にして色ごとにラベリングしてみます。意図通りに検出されている枠もありますが、先ほどに比べるとかなりミスが目立ちます。 cookbook では出力の json フォーマットを(たとえば {"label": "car", "color": "white"} などと)指定させるプロンプト例があるのですが、こちらの方法のほうが精度が上がるのかもしれません。

次に、麻雀牌の画像を認識できるか試してみます。クラスを block のみにすると次のような結果が得られました。

同じクラス指定ですが、ときどき全体を1個の矩形で囲うような失敗をすることがありました。COCO 等では crowd label としてこのような形式のラベルを付けることがあり、その影響と思われます。(通常、麻雀牌の英訳は tile ですが、 tile クラスとすると block に比べて成功率が低かったです。タイルというよりブロックの形として見ているようでした)

クラスを block_1_circle,block_2_circles,block_3_circles,...,block_9_circles,block_unknown としたところ、次のような結果になりました。成功率はあまり高くないですが筒子の見分けもある程度はできるようで、特にクラスとして明に指定しておらず ... で表現した block_4_circles (4p) が検出枠として出ているのが面白いです。

最後に、ずんだもんのイラスト を使って、日本ローカルなキャラクターの検出を試してみます。 zundamon, shikokumetan, tohokukiritan カテゴリとして実行すると次のようになりました。

(枠の色は偶然ですが)キャラクター名・矩形位置ともに正しく検出できていることが分かります。こういったキャラクターの情報もある程度は識別できるようです。
速度
前節で精度を確認するのと同時に、 API 呼び出しの開始から終了までの(クライアント側の)時間を測定しました。
裏では LLM と同じように文字列として順次推論されているので、物体検出モデルに比べると非常に時間がかかります。具体的には、YOLO であれば数十~100ms程度で済む推論に、数秒~10秒程度の時間を要します。(ただし、これは VRAM が豊富な環境で試すと3倍くらいは改善するはずです)
また、矩形数と出力トークン数がおおむね対応するので、物体が多い画像のほうが時間がかかる傾向があります。
今回試した画像での初回の推論時間は次の通りです。(2回目からはトークンのキャッシュが効いて2~3割ほど速くなります)
| 画像 | 時間[msec] |
|---|---|
|
5946.40 |
|
9841.10 |
 |
9749.00 |
 |
1543.90 |
まとめ
- 既知の多クラス、少数のアノテーションが必要な場合には最適
- クラス自体が未知なアノテーションにはあまり強くないが、プロンプト次第で改善の余地がある
- 単純な画像なら精度も十分
- 小さいオブジェクトや未知クラスに対しては未検出が目立つ
- 通常の物体検出モデルに比べると2~3桁遅い
- VLM を物体検出モデルに置き換えて使うのは厳しい
- ツールとしても改良の余地がある
- 誤検知・過検知を見やすくしたい
- ラベルの構造をプロンプトから指定できるようにしたい
- ラベルのない画像とクラスを指定するだけで(従来型の)物体検出モデルができるアプリも作れそう
Discussion