Snowflakeのviewの仕様がすばらしかったので活用しよう
前置き
こんにちは。株式会社GENDAのこみぃです。
突然ですが皆さん、Viewを使っていますか?
今日のお話は、snowflakeのViewはデータエンジニアに非常に優しいので、積極的に使っていこうというものになります。
Viewとは?
Viewというのはテーブルのように扱うことができるSQLのエイリアスのようなものです。
テーブルと違って
例えばサービスに以下のような2つのテーブルがあるとします。
ユーザーID,年齢,性別
1,25,男
2,23,女
ログID,ユーザーID,行動,時間
1001,1,login,2022-05-13 12:00:00
1002,1,buy_item,2022-05-13 12:20:00
1003,2,login,2022-05-13 12:40:00
ログデータの分析をする場合にはユーザーの属性と紐づけて集計したいことが多いので、この2つのテーブルをユーザーIDでjoinするクエリは頻繁に書かれることになります。
この場合、以下のようにViewを定義しておきます。
create view log_with_user as
select
a.log_id,
a.action_type,
a.action_date,
b.user_id,
b.age,
b.gender
from
log_data a
inner join
user_data b
on a.ユーザーID = b.ユーザーID
すると、テーブルのように参照できるViewとして以下のようなものを作っておくことができます。
ログID,行動,時間,ユーザーID,年齢,性別
1001,login,2022-05-13 12:00:00,1,25,男
1002,buy_item,2022-05-13 12:20:00,1,25,男
1003,login,2022-05-13 12:40:00,2,23,女
このViewはテーブルのように参照することができます。
テーブルと違い、実際には参照する過程で定義しておいたSQLが中間テーブルとして実行される感じになります。

これにより、毎回joinを書く必要がなくなり、分析で使っている各種クエリがスッキリします。
テーブルにするか、Viewにするか?
分析のためにデータの非正規化や中間集計を行い、その結果をテーブルにしておいて参照できるようにするというのはデータ基盤でよくある構成です。
前述の例でも「それ、テーブルにすればよくない?」と思う方も多いと思います。
テーブルとViewのそれぞれの特徴を列挙すると以下のようになります。
テーブルの特徴
- ◯ 集計しておけば結果を直接参照できるので毎回のクエリの処理が軽い
- ☓ 再集計をするまでデータが更新されない
- ☓ 中間集計のテーブル間で依存関係がある場合に集計の順番などの管理が結構面倒
Viewの特徴
- ◯ 常に最新のデータを参照できる
- ☓ 毎回集計の処理が入るので重い中間集計は毎回処理されてしまう
これらを総合すると、集計処理が重い場合にはテーブルを使い、軽いならViewで済ませるというのが良さそうですね。
RedshiftのViewは結構使いにくかったお話
さて、そうなると単純にうまく使い分けようという話になってきそうなのですが、実は使い分けが気軽にできるというだけでsnowflakeの仕様はかなりうれしいんです。
というのも、RedshiftのViewが結構使いにくいという事情があります。
私の場合は前職でRedshiftを使っていて、Viewがやや使いにくかったので結局すべてテーブルにしていて依存関係の管理はやや苦戦していました。
そういう経緯もあって、Snowflakeでも最初はViewを使うのは少しだけ慎重になっていました。
というのも、 RedshiftのViewは依存関係が厳密 です。
どういうことかというと、、、
- View Aを参照しているView Bがあった場合にはView Aは削除できない
- このケースでView Aを強制的に削除(CASCADEオプション)するとView Bも削除される
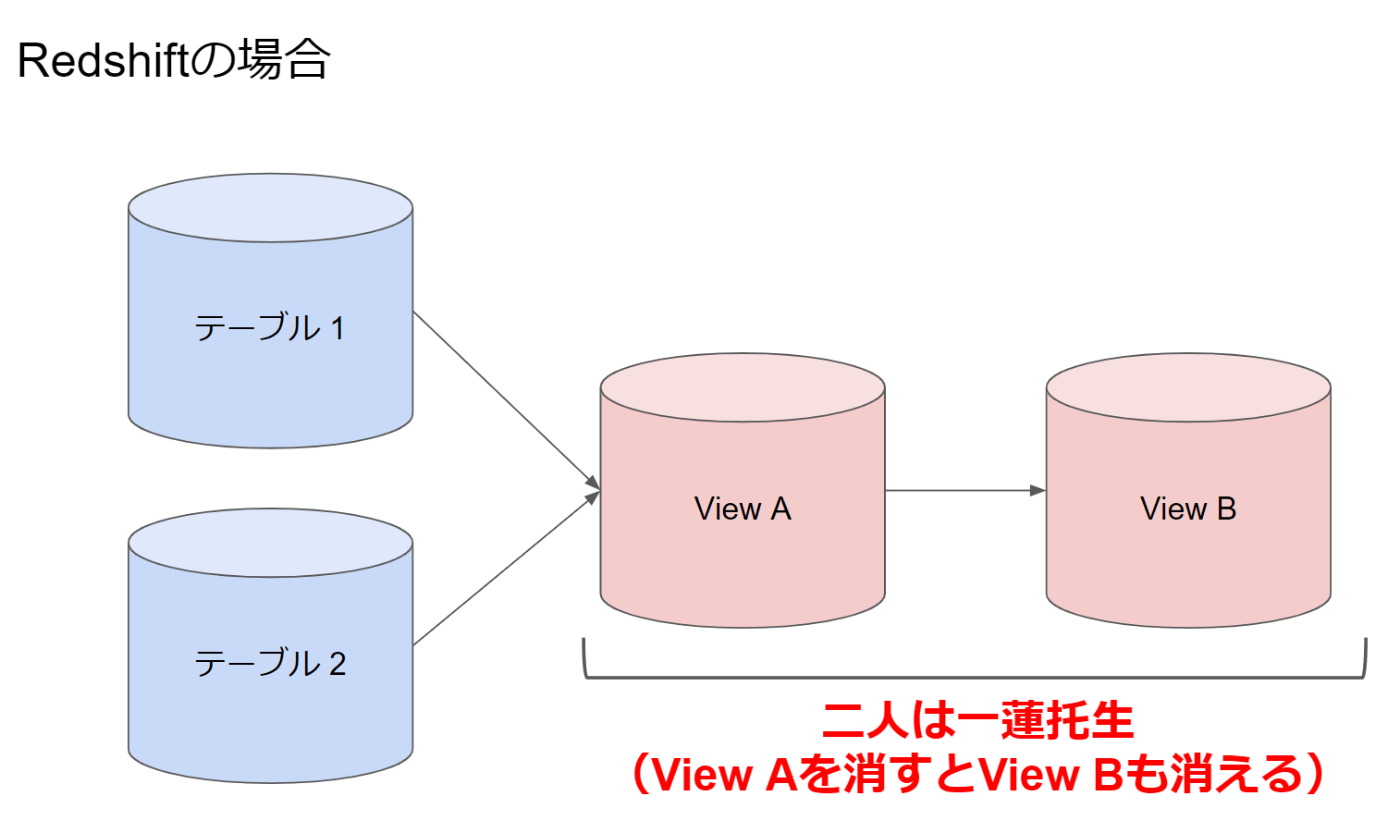
データ基盤においてはView Aを参照するView Bを作ることも、その状況でView Aを書き換えたいことも割と頻繁に起こります。
Redshiftだとこれができません。実はやり方はあるのですが、少なくともデフォルトではないのです。
SnowflakeのViewは依存関係を意識しないで使える
さて、そこに来てSnowflakeではViewは依存関係が緩い仕様になっています。
わかりやすく言うと、View Bの元になっているView AがあったとしてもView Aを削除できます。作り直すこともできます。
SnowflakeはあくまでViewはSQLのエイリアスというだけであり、元になっているテーブルやViewが存在しているかはそのViewが参照されてSQLが実行されるまで意識されないわけです。
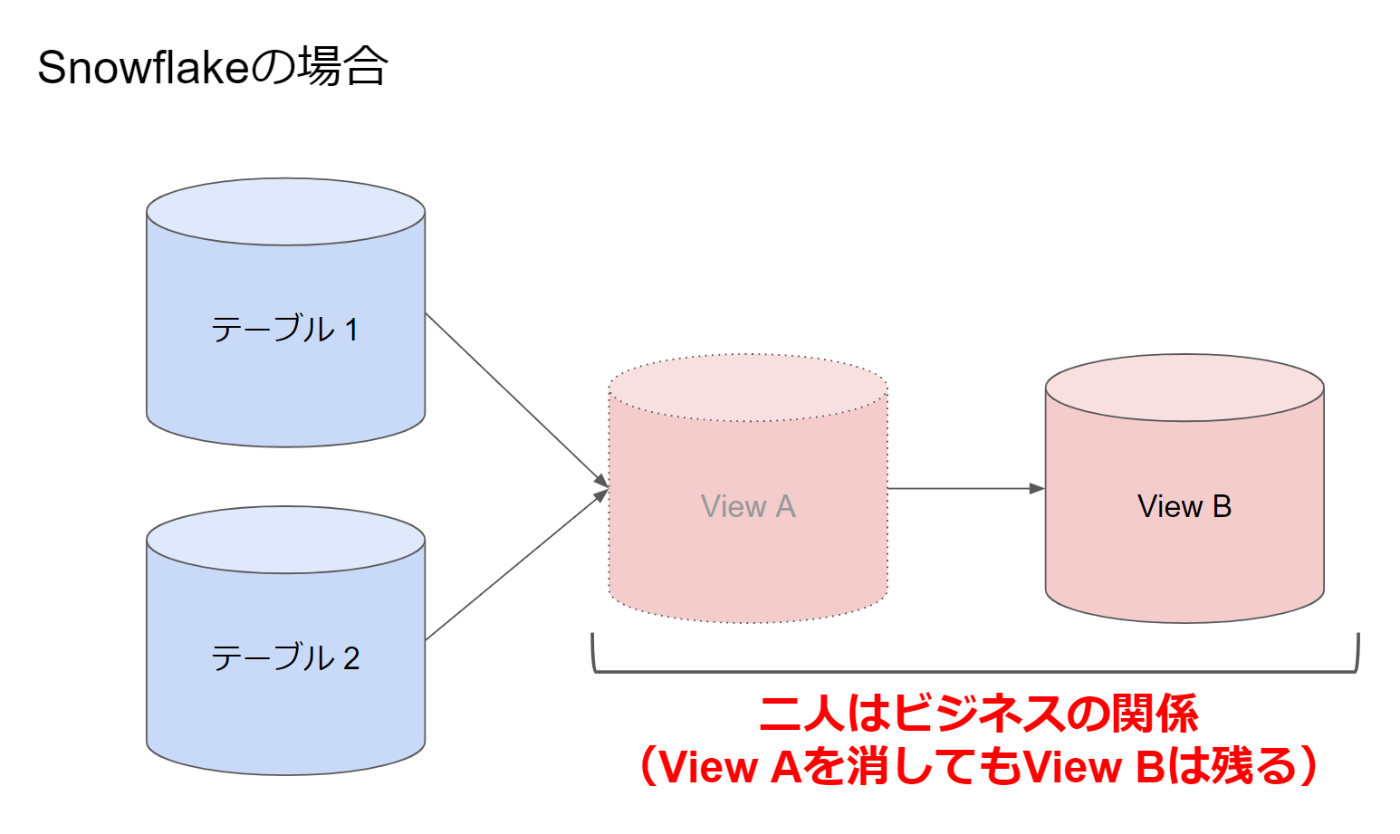
上の例でView Aを削除すると、View Bを参照したときに「View Aなどというテーブルはない!!」とエラーが返ってくる感じですね。
誤って消してしまったときのためにViewの定義を保存しておくなどの工夫は必要ですが、気軽に作り直せるのは非常にありがたい仕様です。
実際に使ってみないとピンとこないかもしれませんが、使っていくとこの仕様がありがたいことが骨身にしみて理解できます。
依存関係がもっと複雑な場面で、根本にあるViewに手を入れたいという場面を想像してください。運用しているとそれが割と頻繁に起こるのです。
結びの言葉
そういうわけで、本日はViewの素晴らしさと、ちょっとうれしいsnowflakeの仕様のお話をしました。
今回の例もそうですが、デフォルトの仕様が自分の直感にあっているとうれしいですし、違ってるとちょっともやっとしますよね。
デフォルトの仕様が直感にあっているのは設計の思想が近いということなので、サービスを選ぶ基準の一つにしてもいいかもしれません。
さらに詳細が聞きたいという方は、私がわかる範囲であればお答えしますので、Twitterあたりでお気軽にお声がけください。
@kommy_jp
本日はこのあたりで。
それじゃあ、バイバイ!
Discussion