Whisper + T5 + ワードクラウドで,会議内容を一目瞭然に
はじめに
昨今の情勢でZoom会議などの遠隔会議が増え,会議の内容を容易に録画できるようになっています.しかし,録画したはいいものの,1時間以上の動画を後から見直すには負担が大きいです.
この負担を減らすため,録画からの議事録作成などが挙げられます.この調査をしてみると,音声認識のライブラリであるWhisperを利用して議事録作成に活かそうとする試みが多くみられました.
そこで,本記事では,Whisperによる文字起こしした文章を利用し,自然言語処理モデルのT5による抽象型要約とワードクラウドによる可視化を行うことで,会議内容をぱっと見て理解できるようにするという試みを行います.
目次
- 実装環境
- 実装の流れ
- T5
- Whisper
- ワードクラウド
- 実験対象の動画
- 実験結果
- おわりに
実装環境
Google Colaboratoryを利用し実装しています.
実装の流れ
全体像は以下の図のようなイメージとなっています.
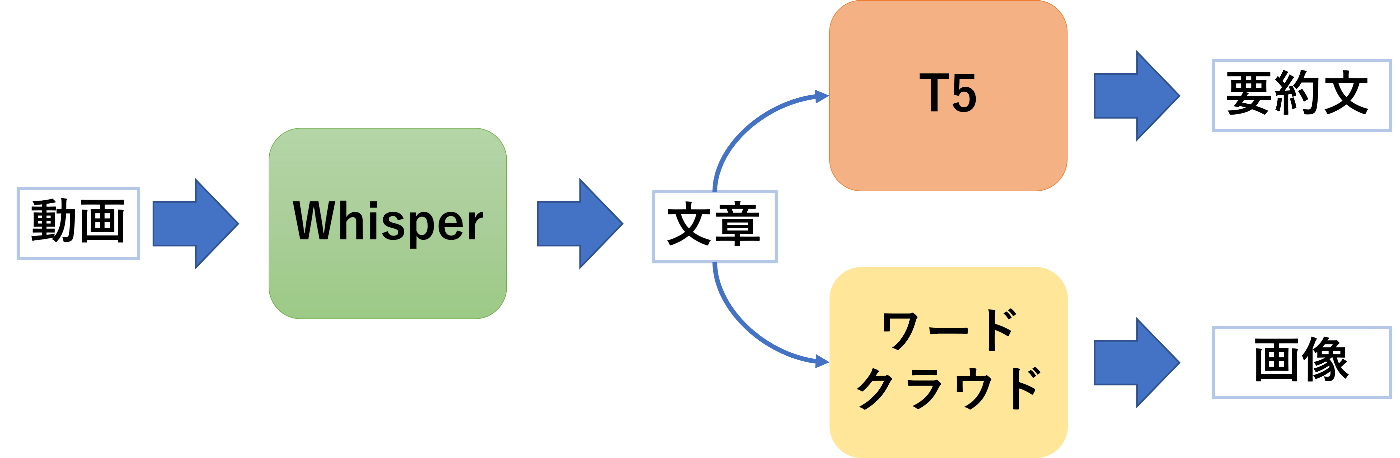
T5の学習が一番時間がかかるためT5の実装を先に行います.
そのため,実装順であるT5,Whisper,ワードクラウドの順に説明をしていきます.
T5
まずは,T5を軽く説明します.T5(Text-to-Text Transfer Transformer)は,Googleから発表されたモデルとなっており,この論文の中で提案されています.このモデルは抽象型要約と呼ばれる,入力文章の意味を捉えて要約し,短い文にして出力することが可能となっています.論文の中で紹介されている以下の図の青い枠部分が参考になるかと思います.
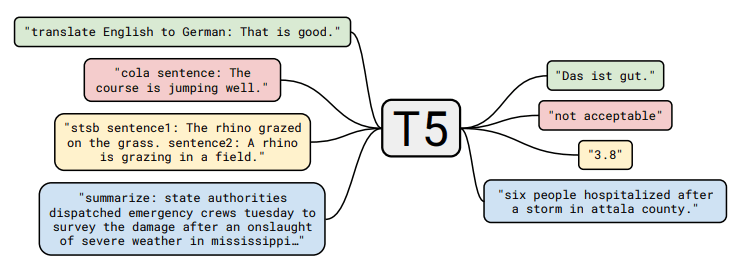
出典:https://arxiv.org/pdf/1910.10683.pdf
次にT5の実装ですが,こちらのブログを参考に実装しました.丁寧に説明されていたので,流れに沿って実行すれば問題なくT5の学習ができると思います.
Whisper
Whisperは,OpenAIから発表された音声認識モデルとなっています.こちらのモデルを利用し,録画データからの文字起こしを行います.
Whisperの実装はこちらの記事を参考に実装しました.モデルのサイズはlargeとし,以下のように時系列で出力されるデータに対して,半角空ける形で出力させてファイルに書き込みをしています.
# ここで半角空けたテキストの書き込みをする
sound2text = ""
for i in range(len(result['segments'])):
sound2text += result['segments'][i]['text'] + " "
print(sound2text)
f = open('/content/drive/MyDrive/vis_meeting/data/kapibara.txt', 'w')
f.write(sound2text) #書き込み
f.close()
ワードクラウド
ワードクラウドは,文章にでてくる文字の頻度を考慮して可視化させる方法です.
ワードクラウドの実装は,こちらの記事とこちらのブログを参考に実装しました.
また,ワードクラウドに表示したくない文字が出たため,こちらの記事を参考にstop_wordsを設定しています.
具体的な実装は以下の通りです.
import MeCab
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import codecs
f = open('/content/drive/MyDrive/vis_meeting/data/sound2text.txt', 'r')
text = f.read() #読み込み
f.close()
m = MeCab.Tagger()
node = m.parse(text) #MeCabで分割
word_list = []
for line in node.splitlines():
word = line.split()[0]
criteria =line.split()[-1]
if criteria.split(",")[0] in ["名詞"]: #名詞の抽出
word_list.append(word)
words = ""
for word in word_list:
words += word
words += " "
print(words) # listを文字列にする
stop_words = [u'ところ', u'もの', u'ある', u'いる', u'する', u'ない', u'れる', u'ため', u'こと', u'これ', u'よう', u'たち', u'の']
wordcloud = WordCloud(font_path = '/usr/share/fonts/truetype/fonts-japanese-mincho.ttf',
stopwords = set(stop_words),
background_color="white",
width=1000,height=400).generate(words)
plt.figure(figsize=(15,12))
plt.imshow(wordcloud)
plt.axis("off")
plt.savefig("word_cloud.png")
実験対象の動画
実験として,以下の2つの動画を対象にしました.
1本目の国会の動画は,2時間30分と長い動画となっており,2本目のカピバラの動画は,1分弱と短い動画となっています.
実験結果
国会動画の出力結果
T5による出力:
子育ての苦労を6年前に国会に送っていただいた
ワードクラウドによる出力:

カピバラ動画の出力結果
T5による出力:
40周年を前にカピバラのゆず湯が行われた
ワードクラウドによる出力:

おわりに
実験結果から,T5の入力長が512となっているため,長時間動画ではうまく要約できないことが分かりました.そのため,文字起こし後の文章に対して,要約に関係がなさそうな文を処理したりするなど一工夫する必要があると感じました.一方で,短時間動画の方では,上手く要約ができており,一目見て内容が理解できるかと思います.
以上より,T5を工夫せずそのまま利用する場合,長時間動画では,ワードクラウドによる可視化のみを利用し,短時間動画では,T5の要約とワードクラウドの両方を利用するのが良いのではないか思います.
Discussion