【簡単かつ高精度】音声認識AIのWhisperを実装してみた
はじめに
画像生成AIのDALL・E2や文章生成AIのGPT-3で何かと話題のOpenAIですが、今度は、音声認識の世界でもやってくれました。
2022年9月22日に高性能な音声認識AIのWhisperを発表したのです。日本語にも対応していたので、早速、GoogleColaboratoryで実装してみました。
驚くほど簡単に実装でき、かつ、驚くほど精度が高くて、びっくりしました。
ここでは、Whisperの概要について簡単に触れた上で、GoogleColaboratoryでの実装方法、精度をお示ししたいと思います。
Whisperについて
OpenAIの公式サイトから、概要をご紹介します。
- Whisperは、ウェブから収集した68万時間に及ぶ多言語・マルチタスク教師付きデータで学習させた自動音声認識(ASR)システムです。
- 大規模で多様なデータセットを使用したことで、アクセント、背景雑音、専門用語に対する耐性が向上したとももに、多言語での書き起こしや、多言語から英語への翻訳も可能となりました。
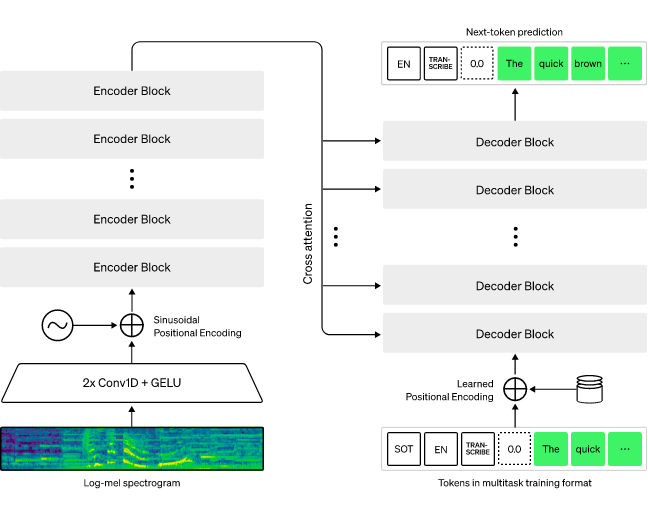
-
Whisperのアーキテクチャはシンプルなエンドツーエンドのアプローチで、エンコーダとデコーダのTransformerとして実装されています。
-
入力音声は30秒ごとに分割され、log-Melスペクトログラムに変換された後、エンコーダーに渡されます。デコーダは対応するテキストキャプションを予測するために学習され、言語識別、フレーズレベルのタイムスタンプ、多言語音声転写、英語音声翻訳などのタスクを単一のモデルに指示する特別なトークンが混ざっています。
-
Whisperは大規模で多様なデータセットで学習され、特定のデータセットに特化したものではないため、音声認識のベンチマークとして有名なLibriSpeechに特化したモデルには勝てません。
-
しかし、多くの多様なデータセットでWhisperのゼロショット性能を測定したところ、これらのモデルよりはるかに堅牢で、エラーも50%少ないことがわかりました。
-
Whisperの音声データセットの約3分の1は非英語であり、原語での書き起こし、または英語への翻訳というタスクを交互に与えます。このアプローチは特に音声からテキストへの翻訳学習に有効であり、CoVoST2から英語への翻訳ゼロショットに対する教師ありSOTAを上回る性能を示すことがわかっています。
Whisperの実装
1.githubからライブラリーをインストールします
!pip install git+https://github.com/openai/whisper.git
2. whisperをインポートし、変数modelでインスタンス化します
import whisper
model = whisper.load_model("small")
モデルのサイズは以下の5種類が用意されています。
largeに行くほど精度は上がりますがメモリを消費し計算に時間もかかります。
| size | parameters |
|---|---|
| tiny | 39M |
| base | 74M |
| small | 244M |
| medium | 769M |
| large | 1550M |
3. 音声ファイルを用意し、pathを取得します
今回は、YoutubeのNewPicksチャンネルを使わせてもらいました。
contentディレクトリにmp3形式でアップロードしました。
path ="/content/NewsPicks.mp3"
Youtubuから音声ファイルを取得する方法はこちら
4. 実行します
model.transcribe()で実行します。
verbose=Trueとすることでログを表示できます。
result = model.transcribe(path, verbose=True, language='ja')

5. 英語への翻訳もできる
task="translate"とすることで日本語を英語に翻訳できます。英語から日本語はできなさそうです。
result = model.transcribe(path, verbose=True, language='ja',task="translate")

6. resultのファイル構造
resultのファイル構造を調べたところ、以下のようなJSONファイル形式になっていました。
データフレーム化して自然言語処理で分析することも簡単そうですね。
{
'text':'僕の周りのすごい企業家とか、めちゃくちゃお金持ちの人たちは10年以内に来るっていう・・・,
'segments': [{
'id': 0,
'seek': 0,
'start': 0.0,
'end': 5.0,
'text': '僕の周りのすごい企業家とか、めちゃくちゃお金持ちの人たちは',
'tokens': [50364,・・・]
'temperature': 0.0,
'avg_logprob': -0.20414161682128906,
'compression_ratio': 0.5611510791366906,
'no_speech_prob': 0.15598918497562408},
],
'language': 'ja'
}
さいごに
いかがでしたでしょうか。
最近、HuggingFaceでやたらwhisperというワードが目につくと思っていたんですよね。まさか、こんな凄いAIが開発されていたとは驚きです。
実装も簡単なので、ぜひ、試してみてください。
Discussion
英語の音声ですが、vimeoで届いたので、Windowsのサウンドレコーダーで音声録音しました。
そして、m4aのファイル形式で試しましたが、読み込みでき文字起こしできました。
この記事のお陰で、助かりました。
ありがとうございます。
感謝しています。
お役に立てて、私も嬉しいてす。
引き続き、どうぞ、よろしくお願いします。