一歩踏み出してみよう。TiDBのアーキテクチャを語る
はじめに
PingCAPの小板橋です。はじめまして!
TiDBの入門記事から上級者編まで幅広く取り扱う本アカウント第4回目は一歩踏み出してみよう。TiDBのアーキテクチャを語ると題して、第1回目の入門記事より少し細かいTiDBのアーキテクチャと動作についてを触れていきたいます。
TiDBのアーキテクチャ
第一回では、ざっくりとしたTiDBの仕組みについてを触れてました。詳細は下記の記事をご覧ください。
おさらいになるのですがTiDBは、下記のようなアーキテクチャをしています。
全体を構成するために、3つのコンポーネントが存在し、動作しています。
- TiDBサーバ: SQLを解析し、最適化をし、ストレージ層に流す役割
- ストレージサーバ (TiKVサーバ, TiFlashサーバ): 実際のデータが格納される場所。TiKVサーバが、行指向ストレージエンジンで、TiFlashサーバが、列指向ストレージサーバになります。
- PDサーバ: クラスタ管理や、メタデータの管理を行います。

OLTPとOLAP
その後、本アカウントで取り扱うNewSQLと呼ばれるものが誕生し、そこにOLTP(オンライントランザクション処理)とOLAP(オンライン分析処理)を両立できるHTAP(ハイブリッドトランザクション/アナリティクス処理)のデータベースであるTiDBが生まれるといった流れを辿ります。
PLTPとOLAPについては、過去に記事でも触れていますが、簡単に説明するとOLTPがオンライントランザクション処理のことつまりは、多数にあるトランザクションを同時実行するデータ処理を意味しており、OLAPが、オンライン分析処理のことつまりは、データベース上に蓄積された大量のデータを使い、集計、複雑な分析を行うような処理を意味しています。

TiDBでは、OLTPについてはシングルTiDBクラスターの構成でも600TB以上拡張することができ、シングルテーブルでも数兆レコード対応しています。
OLAPについても数兆レコードを利用した分析がトランザクションデータと連携し利用することができます。
TiDBにおけるHTAPの実現方法とは?
ちなみに余談ですが、性能という観点でTiDBでは100万QPSに近い性能が出せるという検証結果があるようです。理論値ベースだと300万QPSも達成可能とのこと。
QPSという言葉に聞き馴染みにが無い方向けに説明すると、QPSとは、Queries Per Secondの略で、データベースなどが1秒間に外部から問い合わせ(クエリ)を処理する件数を表しています。
なので、1QPSといえば平均で1秒間に1件のクエリを処理できることを指しています。
容量の観点では、無制限に拡張(性能考慮で600TiBが目安)することができるようです。
さて、ではこれだけの性能と拡張性を持つデータベースがどんな仕組みで動いているのかを見ていきましょう。
HTAP(ハイブリッド オンライントランザクション/分析処理)の実現
TiDBにおけるHTAPの仕組みとしては、下記のようにストレージレイヤの存在する2つのノードに秘密があります。
そもそもなぜHTAPが必要なのかについてを考えた時に、例えば、日々稼働しているアプリケーションによるオンラインのトランザクション処理によってあるデータベースに対してデータが読み書きされ蓄積されていきます。
そのデータをビジネス層が分析かけたい(例えば、作成しているアプリケーションがECサービスのようなものだった時に、その購買データを元に分析し、次の戦略を考えるなど)要件が出た際に、そのワークロードを作成するためのDWHまでのパイプラインを含めて構築するのは大変だと思います。
そうなった時に効果的なことがHTAPの仕組みです。
HTAPを実現するTiDBでは2つに分かれているOLTP用のデータストレージと、OLAP用のデータストレージによって構成されています。
基本は、OLTP用のデータストレージに対して日々のオンライントランザクションの処理が行われ、OLPAをしたい時には、それ専用のデータストレージにリアルタイムでデータがレプリケーションされます。
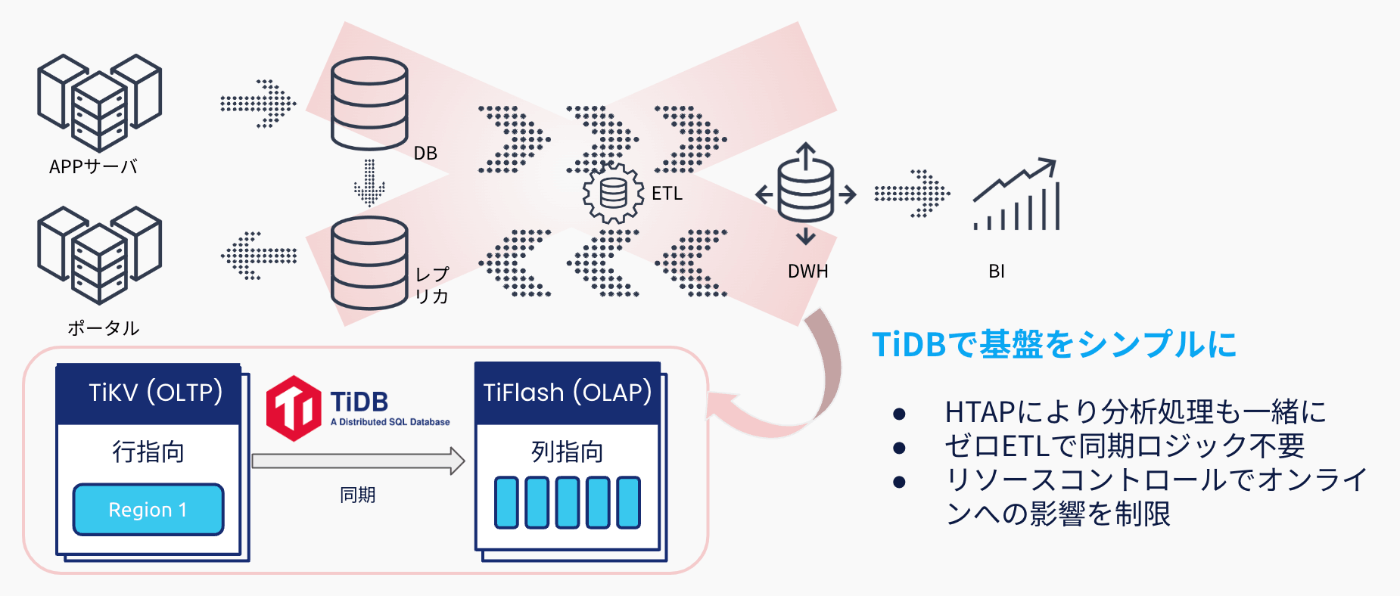
TiDBのアーキテクチャ(OLTP)
さて、ではTiDBの中でOLTPを実現するコンポーネントに注目していきましょう。
TiDBは大きく分けて3つのコンポーネントが動いています。
SQLを解析するレイヤーであるTiDB、実際にデータを保存するRaftというアルゴリズムを採用したTiKV。そして、全体クラスターの状況を監視し、メタデータなどを管理するPDクラスターに分かれます。
TiDBクラスター層については、ステートレスになっているので、クエリの増加に伴い自由にスケールアウト/インをさせることができます。
同じように、データレイヤーであるTiKV, PDについても水平方向のスケールは容易に実施することができます。
このような形で、SQLを解析するコンポーネント、データを保存するコンポーネントが分離されているからこそ容易にスケールさせることができるのがポイントとなります。

TiDBのアーキテクチャ(OLAP)
では、OLAPについてはどうなっているのでしょうか?
上記でも説明したように、TiDBでは、OLAP用にストレージレベルでデータが分離されています。
それがTiFlashと呼ばれるもので、このTiFlashの動きとしては、TiDBクラスターからはデータの書き込みはされません。
動きとしては、TiKVからのデータをレプリケーションする形で動き、分析用のクエリがTiDBクラスターから送られた際は、TiFlashへ流します。
そのため、TiFlashは読みより専用のOLAP専用のクラスターだと思っていただけるといいと思います。
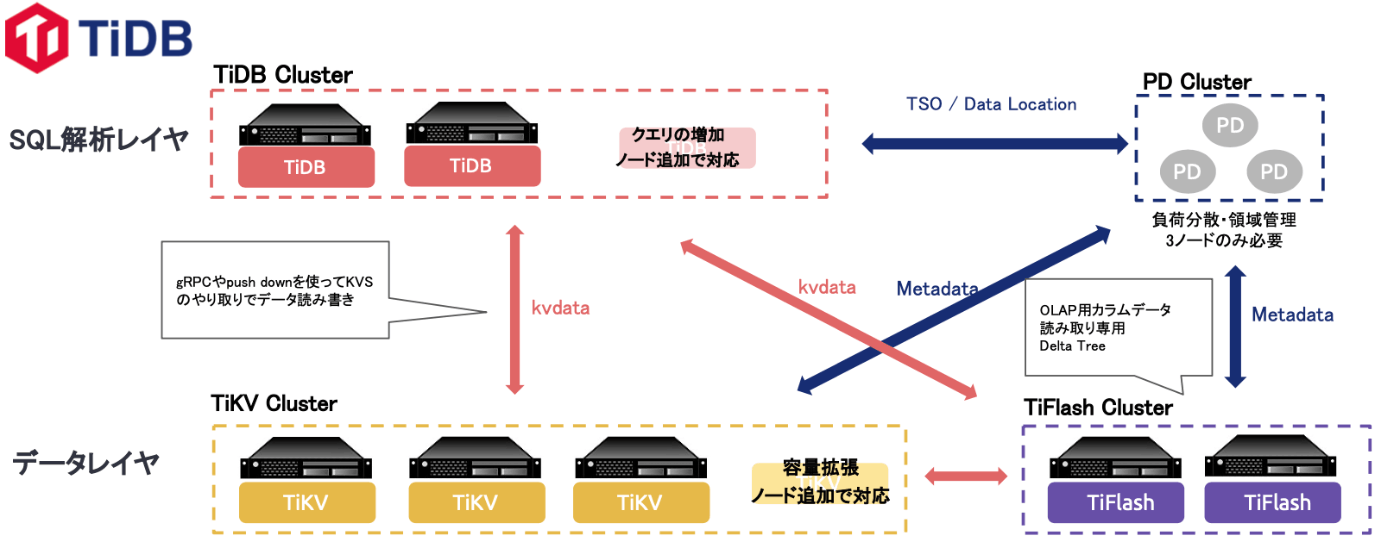
TiKVとTiFlashの同期はどのレベルで行われれる?
OLTPについては、TiKVへ、OLAPについてはTiFlashへとリクエストされるのだが、この2つのストレージはどのレベルで同期されているのでしょうか?
それはmsレベルで常に同期されています。
分析用にクエリがTiFlashへ投げられた際は、下記のようにクエリを実行されたタイミングで、TiKV側に最新の情報が来ていないかを確認。差があれば同期を行うような動きをします。
また、TiFlashクラスターでは必要なテーブル単位でレプリケートを指定することもできます。

どんなクエリに対応ができるのか
基本は、ポイントセレクトのようなクエリからビッグデータのような分析で使うバッチ処理のクエリまで対応しているのが特徴です。
例えば、下記のようなテーブルがあったとします。
-
1つのテーブルには、tenant_idとそのテナントの名前
-
1つのテーブルには、tenat_idに紐づく売り上げ額といった情報が入っています。
このテーブルに対して例えば、下記のようなポイントセレクトをしたとしましょう。
SELECT name, sales FROM tenant_master as tm, user_sales as us WHERE us.time = "2022/11/16 11:10" AND tm.tenant_id = us.tenant_id;
こういったクエリの場合は、TiDBクラスターがオンライントランザクションと判断し、TiKV側へルーティングし、データをユーザ側へ返却します。

逆に下記のような分析をする例を見てみましょう。
テーブルに格納されている情報は同じです。
- 1つのテーブルには、tenant_idとそのテナントの名前。
- 1つのテーブルには、tenat_idに紐づく売り上げ額といった情報が入っています。
テーブルに対しては、次のクエリを実施し、下記の[最終的に欲しい情報]を取得したいとします。
SELECT name.DATE_FORMAT(`time`, '%Y%M')as time, AVG(sales)OVER(PARTITION NY time) tenant_master as tm, user_sales as us WHERE tm.name = "pingcap";
この場合はどうなるのかというと、TiDBクラスターは上記のクエリを解析し、この場合はTiFlash側へルーティングし、データをユーザ側へ返却します。
[最終的に欲しい情報]
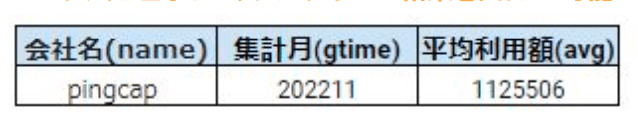
[テーブルの情報]
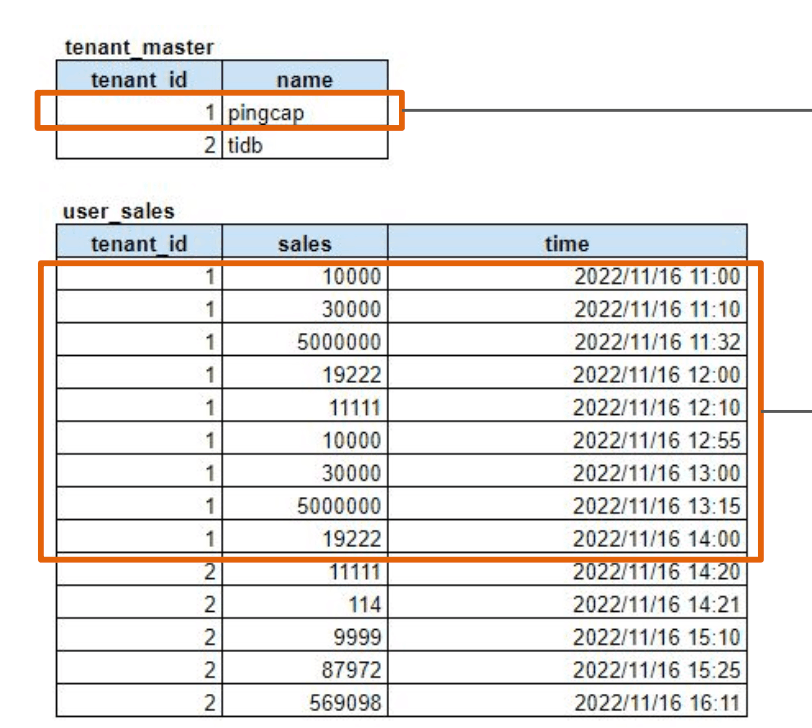
というように、TiDBでは、クエリによりOLTPとOLAPをそれぞれ得意なデータストレージのクラスターにSQLを解析しルーティングさせるTiDBクラスターがいるおかげでHTAPを実現することができるのが特徴です。
またこのような分析のクエリをする際に、今まではETL + DWHの組み合わせを構築しないといけなかったのだが、この一連のパイプライン無しでもできることがポイントです。(OLTPのクエリに影響を与えずに)
TiKVの構造
先ほどから何度も出てくるTiKV。その中の動きはどのようになっているのでしょうか。
TiKVでは、下記のようにマルチAZ(3AZ)の構成を取る場合、TiKV AがとあるAZ、TiKV BがとあるAZのように分散させてTiKVのノードを配置することができます。
次に出てくる考え方が、リージョンと呼ばれるものです。
TiDBにおけるリージョンとは、ストレージを小さく切り分けてある領域になります。
実際に書き込み処理が行われた時の動きとしては、このリージョンにおいて、リーダとフォロワーのような役割を持ち、リーダーに対して、I/Oが行われます。残りのフォロワーについては、リーダに書き込まれたデータをリアルタイムでレプリケーションする動きとなります。
また、このリージョンはデフォルト96MBで保存され、格納されていく、いわばこの区切りでシャーディングしていくそんなイメージになります。

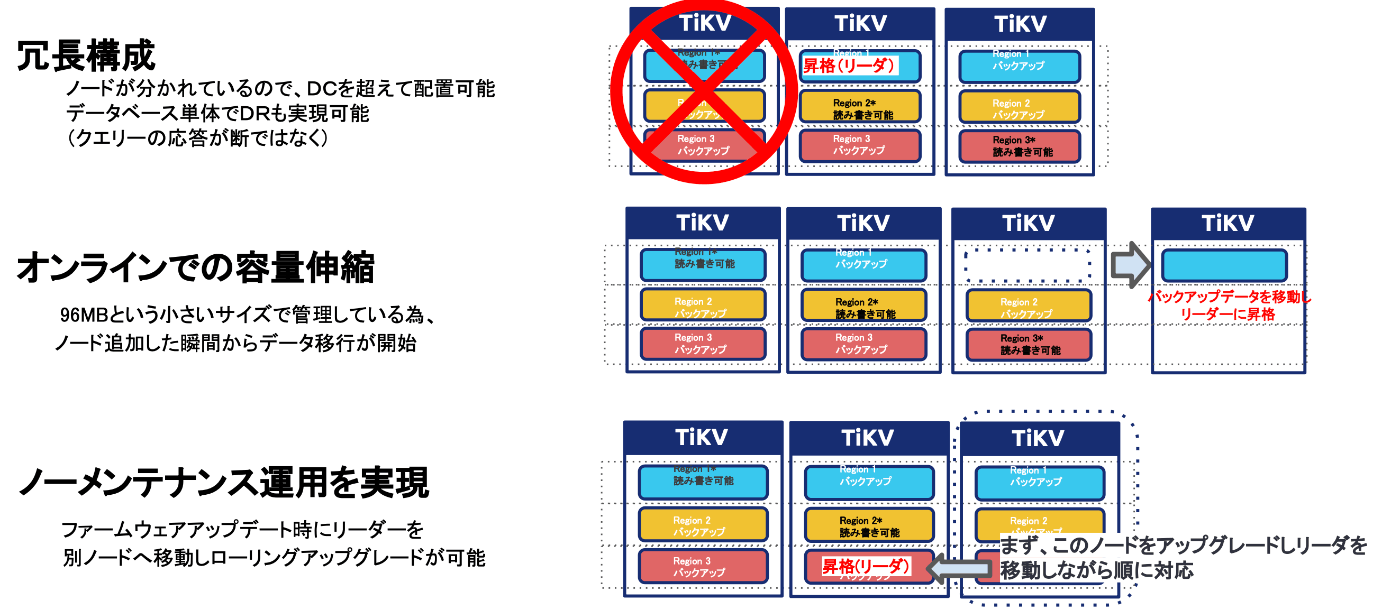
TiKVの特徴によるメリット(冗長性/無停止運用等)
上記で説明した構造をとっている為、TiKVは次のような効果が期待できます。
例えば、あるTiKVノードで障害が発生した時には、特定のリージョンがリーダだった場合に、別のTiKVノードにあるフォロワーがリーダに昇格し、稼働する動きとなります。
そのため、障害が起きても動き続けるというわけです。
次に、TiKVのノードを追加したとしても、デフォルト96MBというリージョン単位でデータを保存しているので、ノード追加が瞬殺で終わるというのもメリットの1つです。
最後にTiKVノードでアップデート対応を行う必要がある時、TiKVの動きとしては、特定のTiKVのノードから順次ローリングアップデートを行うため、アップデートのメンテナンス時にダウンタイム無しで実施されるというのが特徴になります。
PDノードの動き
PDは、TiDBクラスター全体の動きを指令する、司令塔のような動き方をします。
例えば、TiKVの生き死にを確認したり、データの偏りを調整したり、リージョンのマージ、分割などを行います。
セルフホストする場合は、このPDノードを自分たちでスケールさせたり、コンピュートリソースの割り当て等行う必要があるのですが、TiDB CloudについてはこのPDノードを意識する必要がないようになっています。

まとめ
いかがだったでしょうか?
TiDBの世界は奥が深いです。引き続き様々な機能についてを深掘りブログ化していきたいと思います。
公式ブログ/資料等
Discussion