TiDB入門 ~TiDBと周辺ツール群~
はじめに
PingCAPの小板橋です。はじめまして!
TiDBの入門記事から上級者編を取り扱う本アカウント第一回目はTiDB入門ということで、TiDBの仕組みや周辺ツール群をご紹介していきたいと思います。
TiDBとは
簡単に表現するのであれば、MySQL互換のNewSQLデータベースです。
数百TB、100万以上QPS(Queries Per Second)以上を捌くことができるとされています。
また、これだけの高負荷を捌きつつ、OLTP(オンライントランザクション処理)とOLAP(オンライン分析処理)、この2つのワークロードを処理するHTAPデータベースとなっているのが強みですね。
OLTP - Online Transaction Processing(オンライントランザクション処理)
OLTPは、多数にあるトランザクションを同時実行するデータ処理の一種となります。
例えばユースケースとして、ECサイトのショッピングや、オンラインバンキングの処理などといった処理です。基本、行ベースのストレージエンジンを利用し、現在のデータを保存しそれをリアルタイムで更新していくような動きをします。
OLAP - Online Analytical Processing(オンライン分析処理)
OLAPは、データベース上に蓄積された大量のデータを使い、集計、複雑な分析を行うような処理をさせることを行います。
OLAPの多くはカラム型(列指向型)データベースです。
で、例えばOLTPによって蓄積されたデータに対して、OLAPのような分析をやろうとした時に、そもそものリクエスト要件が違うので、これらの技術を構築する技術も異なってきます。
例えば、実現しようとすると下記の図のように、Onlineデータの処理を蓄積するデータベースと分析用データを分け、処理を分けるそんな構成になるのではないでしょうか。
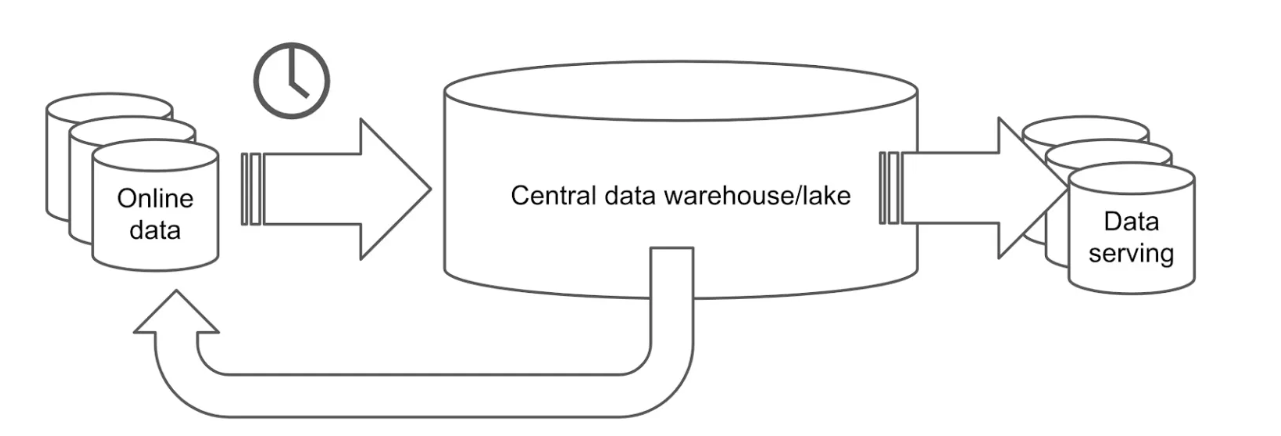
このプロセスをとると処理に時間がかかり、複雑です。データ処理工程が増えるほど、遅延が増加する問題も抱えます。
HTAP - Hybrid transactional/analytical processing
そこでHTAPの出番です。
HTAPは冒頭にもお話ししたように、OLTPワークロードとOLAPワークロードの両方を処理するデータベースです。そのため、それぞれの処理を分けるという考え方ではなく、同じデータベースで実現できるというのが特徴です。
また、なぜ今になってHTAPが必要になってきているのかというのは、トランザクションワークロードと分析するワークロードの境界が曖昧になってきているからです。
これは、例えば、分析をするワークロードを考えた時に分かるのですが、OLAPが一番必要になるケースは、例えばセールスが必要とするようなとある購買データの履歴など、だったり、ただ、もっとリアルタイムなデータが欲しいというと、その分、分析するデータの新しさを求める、そんなことが起こるのではないでしょうか。
そうなった時に、それぞれのワークロードに対して、オンライントランザクションを保証し、分析もできるそんな要件を満たすのが、HTAPなのかもしれません。
特徴
スケーラブルな分散DB
TiDBのアーキテクチャ設計として、コンピューティング部分(SQLを解析し、最適化したりする部分)とデータストア、言うなればストレージレイヤーとが分離されている構成になっています。
これにより、何が実現したのかというと役割を別にしたクラスターを立てたことで、それぞれのクラスターごとに必要に応じてスケールイン/スケールアウトをオンラインで実施できるようになったことで、水平方向のスケーラビリティを実現することができます。
高い可用性
もちろん上記のそれぞれのクラスターを水平方向にスケールさせることができるので、それだけでも可用性があるのですが、リージョンごとに配置されたクラスター毎に冗長化する動きをとるので、耐障害性や負荷分散にも強い設計となっています。
分析ワークロードも実現できるHTAP
蓄積されているデータを分析させるためのDWH入りません。
TiDBでは、上記でも触れたようにHTAPを実現するデータベースとなっているので、TiDBのみで分析ワークロードも実現します。
これ、実際にはどうやっているのかというと、TiDB はストレージレイヤーに2つのstorageエンジンを保持しています。それが、TiKVとTiFlashです。
- TiKVは行指向のstorageエンジンです。
- TiFlashは列指向のstorageエンジンです。
TiFlash は、Multi-Raft Learnerプロトコルというものを使用し、TiKVからリアルタイムでデータを複製し、TiKVのstorageエンジンとTiFlashのstorageエンジンの間で一貫したデータを保証するような動きをします。
TiKVとTiFlashは、HTAP リソース分離の問題を解決するために、必要に応じて別のマシンにデプロイすることもできるのです。
移行容易性
なんといってもMySQL互換のデータベースということもあり、アプリケーションの変更が不要のままMySQLのツールとしてサードパーティで提供されているものも使用することができます。
提供しているサービス
さて、そんなTiDB。実は提供しているサービス形態が3種類に分かれます。
TiDB Serverless
TiDB Serverless これは、クラウド上で実現するマルチテナント型のフルマネージドTiDBです。
HTAPも含めた機能が利用でき従量課金での提供となるはなるのですが、例えば、SLA(1AZで稼働しているため)や性能については制限があったりなど、使うユースケースが限られるサービスとなります。
ただ、サーバレスという言葉を使っていることもあり、従量課金、よくあるVPCみたいなものはなく、クレジットカードの申請なしで使えます。
TiDB Cloud (Dedicated)
TiDB Cloud これは、お客様毎の専用VPC内に構築するクラウド型のフルマネージドTiDBです。
のこれは99.99%というSLAを担保し、性能についてもServerlessとは違い、お客様環境毎に分けているので、性能による制限などはありません。
データ移行なども周辺サービスを利用できるといったメリットもあります。
現在(2024年4月2日時点)では、利用できるプラットフォームとしてAWSとGCP(ともに東京リージョンは使えます)が選択できます。
OSS (Self-Hosted)
これはOSSで提供されているTiDBを自分たちでセルフホストするといったパターンです。
無償で利用できるものの、運用を全て自分たちでしなければいけないというのが注意する点になります。
ただ、enterpriseプランというものがあり、これを契約するとサポートをつけることもできるとのことです。
全体のアーキテクチャ
さて、ではTiDBにおける全体のアーキテクチャがどうなっているのかを見ていきましょう。

お主に3つの役割を持った構成に分解できます。
TiDBサーバ
これは、MySQLプロトコルの接続エンドポイントを外部に公開するステートレスSQLレイヤーです。
つまり役割としては、SQLリクエストを受信した後にSQLの解析を行い、最適化をした後に実行プランを作成します。
この分析処理が終わった後に実際のデータを読み取るためのリクエストをTiKVノード(または、TiFlashノード)に送ります。
PDサーバ
これは、クラスター全体のメタデータ管理をするコンポーネントです。全ての単一TiKVノードのリアルタイムなデータ分散のメタデータとクラスタ全体の構造を保存し、TiDBのUIダッシュボードを提供し、分散トランザクションにおけるトランザクションIDを割り当てます。
いわばTiDBの頭脳とも言えます。
このPDサーバについては、少なくとも3つのノードで構成され、高可用性を保持しています。
ストレージサーバ
ストレージサーバについては、先ほども述べたように2つの種類があります。
TiKVサーバ
TiKVは、分散トランザクションのキーと値を保持するストレージエンジンです。
各リージョンには、StartKey から EndKey までの特定のキー範囲のデータが格納されています。
このリージョンというのは、論理的にバケットと呼ばれる小さな範囲に分割されているものを指します。TiKV はバケットごとにクエリ統計を収集し、バケットの状況をPDサーバに報告します。
TiFlashサーバ
TiFlash はデータを列ごとに保存し、主に分析処理を高速化するように設計されています。
どのようにHTAPを実現しているのか
TiDBにおける、HTAPを実現できている大きな要素は、TiFlashにあります。
TiKV のカラムナ型storage拡張機能として提供されています。

TiFlashの動きとしては、直接データをTiFlashに書き込むことはできません。データを TiKV に書き込んでからTiFlashにレプリケートする必要があり、そのように動きます。また、TiFlash はテーブル単位でのデータ複製についてはサポートしていますが、展開後のデフォルトではデータは複製されないようです。
TiKVは、TiKVノード内のデータをリアルタイムでレプリケーションします。また、TiKVと同じ読み取り一貫性を保持し、最新のデータを確実に読み取ることができます。
周辺ツール群
tiup
まずは、tiupです。これは、TiDB4.0で導入されたクラスターの運用および保守ツールです。
TiUP自体はGo言語で書かれており、クラスター管理コンポーネントであるTiUPクラスターを提供しています。
TiUPクラスターを利用することで、tiDBクラスターのデプロイ、開始、停止、破棄、スケーリング、アップグレードなどをすることができます。
主にOSSをセルフホストで管理する場合に利用します。
TiDB Operator
TiDB Operatorとは、K8s上のTiDBクラスターの自動運用システムになります。導入からアップグレード、スケーリング、バックアップ、フェイルオーバー、構成変更など、TiDB のライフサイクル管理をすることができます。
TiDB Operatorを使用すると、TiDB はパブリッククラウドまたはプライベートクラウドにデプロイされたK8sクラスター内でシームレスに実行することができるのです。
TiUP Playgroud
TiUP Playgroudとは、ローカル環境にて簡単にセットアップが可能なPlaygroudになります。
tiupをインストールし、下記にようなコマンドを実行するだけで簡単にクラスタがローカル環境に構築できます。
tiup playground ${version} [flags]
Chat2Query
下記のように、Open AIのAPIを利用し、自然言語の問い合わせからスキーマーを意識したSQL生成を可能にする機能です。

Data Service
任意のSQLをAPIとして公開するローコードAPIサービス構築機能になります。
TiProxy
MySQLクライアントとTiDBサーバ間に入るリバースプロキシになります。
これにより、例えば、クライアントが接続しているTiDBを透過的に切り替えたり、利用可能なTiDBサーバの情報を動的に更新したりします。
まとめ
いかがだったでしょうか?
TiDBの世界は奥が深いです。引き続き様々な機能についてを深掘りブログ化していきたいと思います。
公式ブログ
Discussion