Googleにより開発されたPercolaterとは
はじめに
PingCAPの小板橋です。はじめまして!
TiDBの入門記事から上級者編まで幅広く取り扱う本アカウント第9回目は「Googleにより開発されたPercolaterとは」についてをまとめていきたいと思います。
Percolater とは
前回お話しした、TiKVにおけるトランザクションの話では、TiDBにおける裏側の仕組みとトランザクションの動きについてを語っていきました。
今回、お話ししていくのはこのTiDBにおけるトランザクションの中で使われている技術であるGoogle のPercolatorの動きについてになります。
GoogleのPercolatorというのは大規模なデータセットの増分処理のためにGoogleによって開発されたアーキテクチャです。
前回の記事でも説明したように、TiKVは分散トランザクションを実装しているのですが、このGoogle のPercolatorからインスピレーションを受けており、そこから分散トランザクションを実装する中での最適化をしてきました。
そこで今日は、そんなTiKVにおける分散トランザクションについてのおさらいをしつつ、Google のPercolatorについてを深掘りしていきたいと思います。
TiDBにおけるトランザクションの動きについて
下の図は、クライアントから側から操作があった時のTiDBノード -> TiKVノードへのデータフローを可視化したものを表しています。
動きとしては、TiDBノード内にあるBatch ClientからTiKV内にあるRaft Storeへ処理を流し、Raftは受け取ったデータのコピーを受け取り整合性を保つ動きをしていることが分かります。
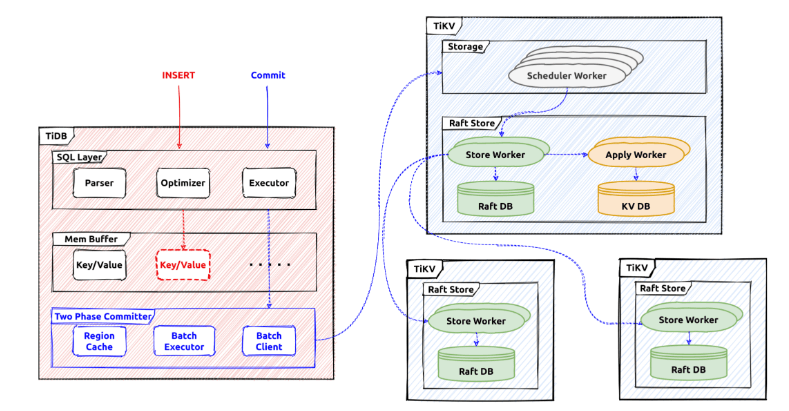
もう少し細かい話をしていくと、実際にセッションでトランザクションが開始されると、そのすべての読み取り/書き込みにてスナップショットが使用されデータをフェッチ、書き込まれたデータはメモリにバッファリングされる動きをします。
commit;のステートメントを受け取ると、Percolatorを使用して、バッファリングされた変更をストレージにコミットする動きをします。
また、TiDBでは、前回の記事でも触れたようにMVCC(MultiVersion Concurrency Control)を実現しているデータベースです。
このMVCCを実現するために、TiDBでは5つの仕組みがあります。
1: Google Percolator
2: TSO (Timestamp Oracle)
3: 2PC (Two Phase Commit)
4: CAS (Compars And Swap)
5: TTL (Time To Live)
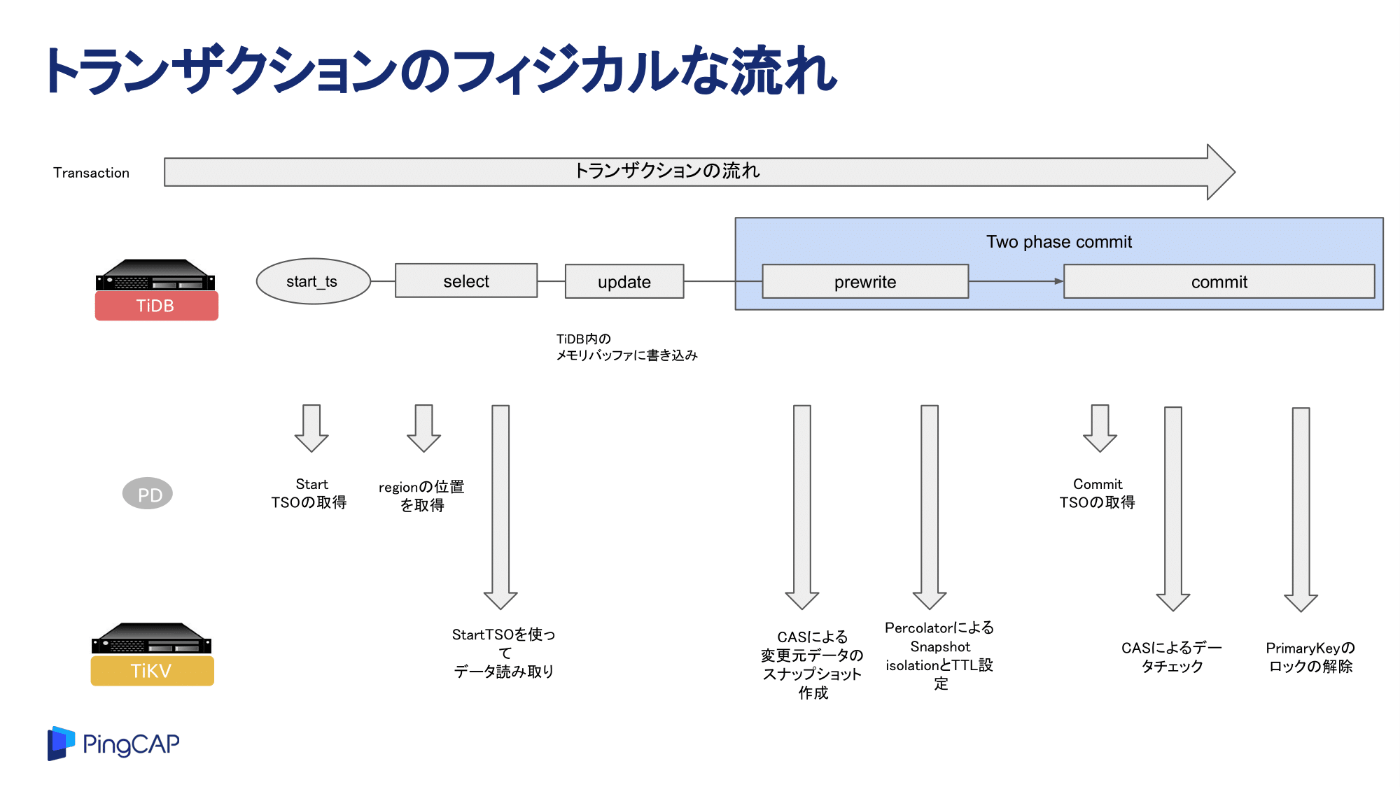
さて、まずは、フィジカルなトランザクションの流れをイメージしていただき、そこからPercolatorの動き、考え方などに触れます。
- 1: 動きとして、まずTiDBノードは、PD(Placement Driver)ノードに対して、start_ts(タイムスタンプ)を取得します。
- 2: スナップショットデータの取得を行うために、実際のI/Oを行っているTiKVノード内のリーダリージョンの情報をPDノードから取得します。
- 3: 1で取得したstart_tsを使用し、TiKVのリーダリージョンからデータを読み取ります。
- 4: 取得したデータを元にTiDBノード内のメモリバッファに書き込みます。
- 5: TiDBでは、commitにTwo phase commitを採用しているので、その処理をする動きをとります。まずは、prewriteが発行されます。このprewrite時に、CAS(Compare And Swap)と呼ばれるメモリにスナップショットしたデータが配置されます。
- 6: 次に、Percolaterにより、SI(Snapshot Isolation)とTTLを設定します。(全てのキーに対してprewriteでロックの取得を行う。)
- 7: commit処理のため、commit_ts(タイムスタンプ)をPDノードから取得し、実際にデータを書き込みます。
- 8: CASによるデータのチェックを行います。
- 9: PrimaryKeyのロックの解除が終わるとcommitが完了し、クライアントに処理が戻ります。
実装されているトランザクションのインターフェース
実際に実装されているトランザクションのインターフェースが下記になります。
例えば、Commitは、現在進行中のトランザクションをコミットする際に使用されるインタフェースです。
type Transaction interface {
RetrieverMutator
// Size returns sum of keys and values length.
Size() int
// Len returns the number of entries in the DB.
Len() int
// Reset reset the Transaction to initial states.
Reset()
// Commit commits the transaction operations to KV store.
Commit(context.Context) error
// Rollback undoes the transaction operations to KV store.
Rollback() error
// String implements fmt.Stringer interface.
String() string
// LockKeys tries to lock the entries with the keys in KV store.
// Will block until all keys are locked successfully or an error occurs.
LockKeys(ctx context.Context, lockCtx *LockCtx, keys ...Key) error
// SetOption sets an option with a value, when val is nil, uses the default
// value of this option.
SetOption(opt int, val interface{})
// GetOption returns the option
GetOption(opt int) interface{}
// IsReadOnly checks if the transaction has only performed read operations.
IsReadOnly() bool
// StartTS returns the transaction start timestamp.
StartTS() uint64
// Valid returns if the transaction is valid.
// A transaction become invalid after commit or rollback.
Valid() bool
// GetMemBuffer return the MemBuffer binding to this transaction.
GetMemBuffer() MemBuffer
// GetSnapshot returns the Snapshot binding to this transaction.
GetSnapshot() Snapshot
// SetVars sets variables to the transaction.
SetVars(vars interface{})
// GetVars gets variables from the transaction.
GetVars() interface{}
// BatchGet gets kv from the memory buffer of statement and transaction, and the kv storage.
// Do not use len(value) == 0 or value == nil to represent non-exist.
// If a key doesn't exist, there shouldn't be any corresponding entry in the result map.
BatchGet(ctx context.Context, keys []Key) (map[string][]byte, error)
IsPessimistic() bool
// CacheIndexName caches the index name.
// PresumeKeyNotExists will use this to help decode error message.
CacheTableInfo(id int64, info *model.TableInfo)
// GetIndexName returns the cached index name.
// If there is no such index already inserted through CacheIndexName, it will return UNKNOWN.
GetTableInfo(id int64) *model.TableInfo
// set allowed options of current operation in each TiKV disk usage level.
SetDiskFullOpt(level kvrpcpb.DiskFullOpt)
// clear allowed flag
ClearDiskFullOpt()
}
Google Percolator
さて、ここで、今回の話の主役であるGoogle Percolatorの話をしていきます。
上記のTiDBにおけるトランザクションの流れにおいて、TiDBではトランザクションの分離レベルをスナップショットアイソレーションで行っています。
ここで、登場するのが、Google PercolatorというGoogleによって開発されたアーキテクチャになります。
トランザクション自体の動きについては、冒頭でもご紹介した下記の記事に詳しい動きを記載しております。
要約していくと、まずTiKVには、その裏側にRocksDBというKey-Vlueデータベースを内包しており、かつ、メモリ領域と実際にデータがディスクにフラッシュされるレイヤーに分け、データを管理している形をとります。
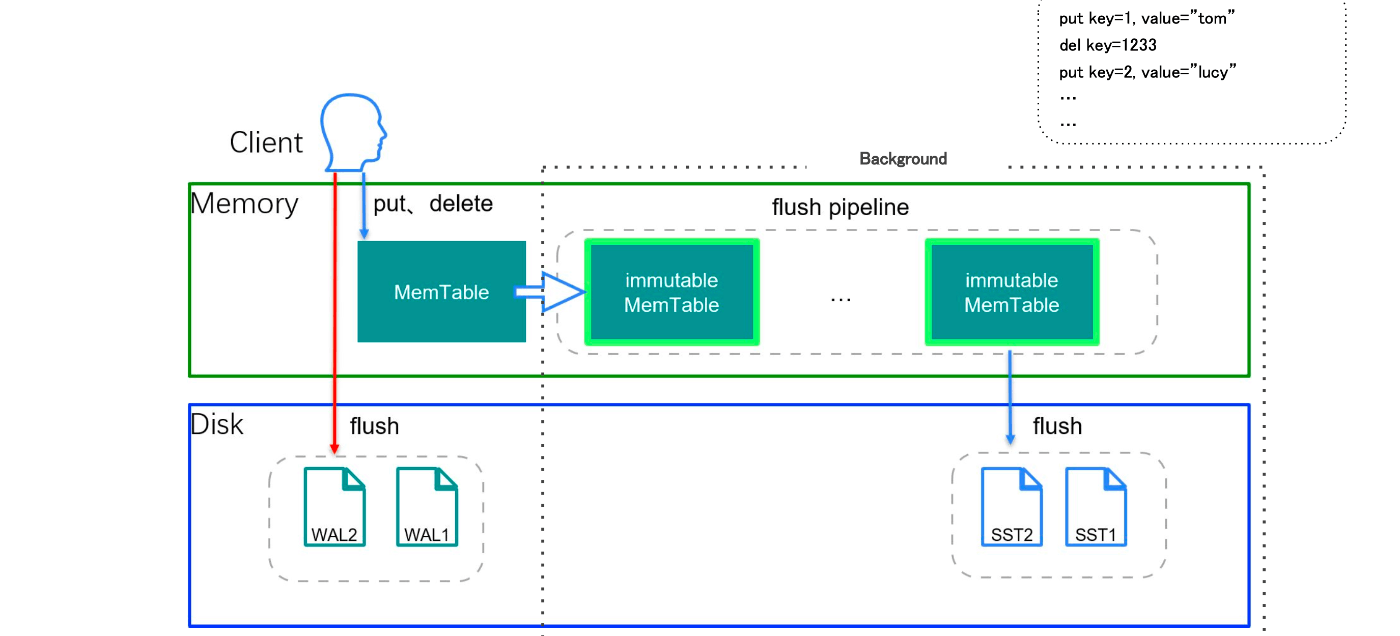
このデータを管理するレイヤーの中でCF(カラムファミリー)という役割を持たせたデータ領域が存在し、そのCFを使い分けながらトランザクションのロックなどを処理しているのです。
クライアント含め、TiDBノードとTiKVノードを含めた際のコミットの動きとしては、TiDBノードがPDノードにトランザクション開始時とコミット時にTSO(タイムスタンプオラクル)を取得し、そのタイムスタンプを含めてCFにデータを追記していく動きを行います。
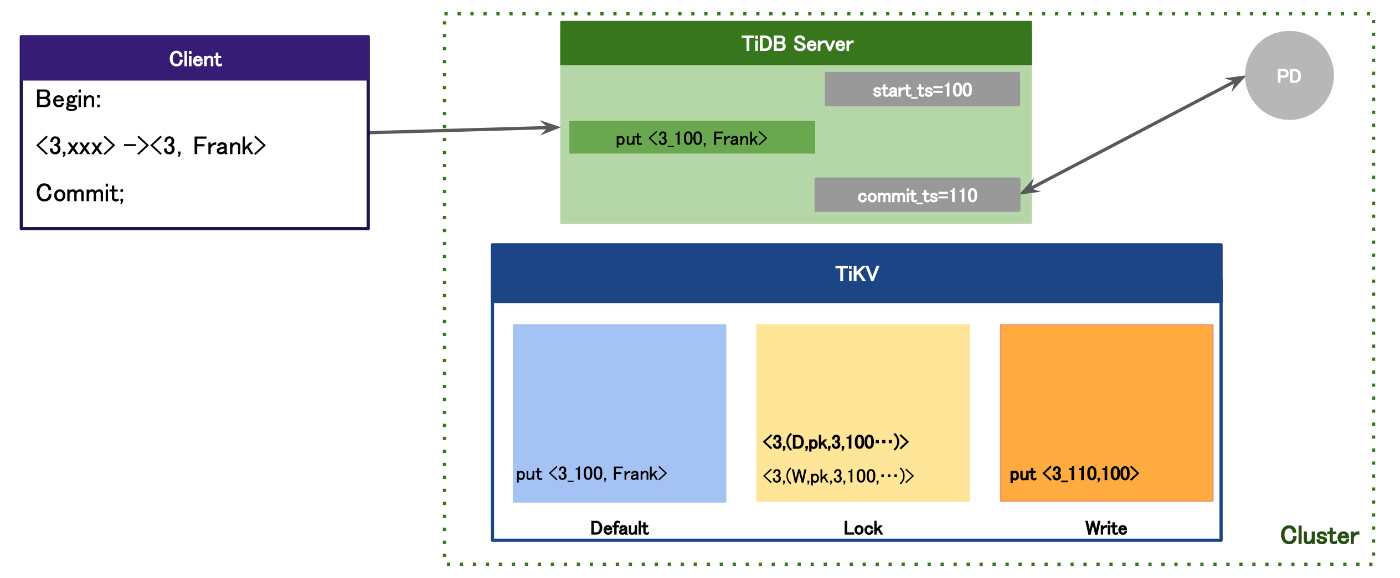
そして、このTiKVの中でのCFを活用しトランザクションの制御のアーキテクチャにGoogle Percolatorによるスナップショットの仕組み、アーキテクチャが採用されているという訳です。

では、そんな、Google Percolatorとはなんなのでしょうか?
ということで、Google Percolatorについて書かれている論文をかいつまんで要約していこうと思います。
論文 「Large-scale Incremental Processing Using Distributed Transactions and Notifications」を要約していく
Google Percolatorについては下記の論文に書かれていますので、こちらを要約していきたいと思います。(あくまで個人の理解をベースに書いているので、正確に読み取るにはオリジナルの論文を読んでください。)
Percolatorを構築したことで得られた結果とは?
Googleの検索エンジン、ユーザが検索できるドキュメントは凄まじい量存在しています。
なので、Webのインデックスを更新するには、新規でのドキュメントが追加される度に超膨大なデータを継続的に変換、更新する必要があります。
この変換/更新するタスクに求められること、それは、巨大なデータのリポジトリに対して、ほんの1部の変更があったときに、全体を変更、更新することです。この処理に求められるインフラ要件としては、ストレージとスループットです。
そもそも、Googleのインデックス作成システムは、数十ペタバイトのデータを保存し、数千台のマシンで1日に数十億件の更新しているそうです。と思うとこの要件も納得ですね。
また、裏側のシステムとして、MapReduceなどのバッチ処理があるのですが、どうしても大規模なデータに対することに特化しているので、小さな更新を個別に処理することもできないという問題を抱えていました。
そこで登場するのが、大規模なデータセットの更新を段階的に処理するシステムであるPercolatorになります。
Percolatorを構築し、Googleウェブ検索のインデックスをPercolatorを使用し作成する方式にしたそうです。結果として、1日あたり同じ数のドキュメントを処理しながら、Googleによるページクロールと検索インデックスでのページ利用ができるまでの遅延を50%削減したというものです。
Percolatorが必要な理由
ここでは、よくあるWeb検索システムを構築したときに、ユーザからの検索クエリが投げられた時のインデックス構築をするとどうなるのか最初に述べられています。
そこから、Googleのような超巨大なデータのリポジトリを持った際に同じことができるのか、そのためのPercolatorが出てきた課題を解決するためのソリューションであることが述べられています。
よくあるWebの検索システムでのインデックスを考える
まずそもそも、GoogleのようなWeb検索システムにインデックスがなかったら、凄まじいデータ量に対する検索のクエリはパフォーマンスが発揮できず、使い物にならないことでしょう。また、全文検索となるため、凄まじいコンピュータリソースをしいられ、コストは跳ね上がることが予想できます。
インデックスを作成する動きとしては、Web上のすべてのページをクロールし、インデックス上の一連の条件を維持しながら、それらのページを処理していきます。
たとえば、同じコンテンツが複数のURLでクロールされた場合、インデックスにはPageRankが最も高いURLだけが表示されます。
PageRankとは、検索エンジンであるGoogleにおいて、ウェブページの重要度を決定するためのアルゴリズムを指し、検索されたクエリに対する適切な結果を取得するために使われる仕組みを指します。
また、考慮しなけれないけないことがあります。それは、よくあるWebページを想像いただきたいのですが、文章内に他のページへのリンクが含まれていることがよくあります。
このリンクには、「アンカーテキスト」と呼ばれるリンクテキスト(リンクとしてクリックできる部分)も含まれています。例えば、あるページAからページBへのリンクがあり、アンカーテキストが「参考資料」となっている場合を考えてみましょう。
インデックスを作成する際には、このリンク情報を反転します。
つまり、「ページAに『参考資料』というリンクテキストでリンクされているページはBです」とインデックスに記録します。これにより、ページBを検索した際に、どのページからリンクされているかが分かるようになります。
これを論文中では、反転リンクという表現をしています。
次に、ウェブページには、同じ内容を持つ複数のURLが存在することがあります。
これを論文中では、重複ページと表現しています。
インデックス作成時には、この重複ページの扱いも考慮する必要があります。具体的には、リンクの反転処理を行う際に、どの重複ページにリンク情報を集約するかを決める必要があるのです
また、重複ページにリンクされる場合、必要に応じてPageRankが最も高い重複ページに転送されるべきとも書かれています。
ただ、これらの処理については、MapReduceによる操作で処理させることができます。
なぜならば、MapReduceは、すべてのドキュメントが次の処理ステップを開始する前に前のステップを完了してから処理が行われます。
なので、例えば、現在のPageRankが最も高いURLに反転リンクを書き込んでいる場合、PageRankが同時に変更されることを心配する必要なく、前のMapReduceステップで既にPageRankが決定されているといった理由があるからです。
では、あるウェブページの更新/追加をきっかけにどのようにインデックスを更新するべきか?
新しいページが追加されたとします。では、この新しいページだけにMapReduceを実行すればいいのでしょうか? いいえ、それでは不十分なことは、これまでの話で分かります。
なぜならば、新しいページとそのページに関連するリンクがあるためです。
なので、純粋に考えればMapReduceを全てのデータのリポジトリに対して実行すればいいんじゃないかと。
確かにそうですが、これの欠点としては全てのデータ量に対しての計算リソースがあるのか、という点です。
また、毎回毎回ページが更新されるたびに過去のMapReduceの処理結果は使えず無駄にもなります。かつ、データ量が時間とともに増えることに伴い、レイテンシもデータ量に比例するので、莫大な無駄が発生するということです。
Percolatorの内部アーキテクチャ
アーキテクチャを大きく分けるとPercolator、BigTable、Google File Systemを組み合わせており、上から順に処理が流れていることが分かります。
次に大事な内部の処理としては、オブザーバと呼ばれるものです。これは、データ変更があった際に自動的に特定の処理を実行するするように動きます。
Percolatorは、オブザーバの連鎖により処理が実行されます。つまりは動きとして、各オブザーバは、自分のタスクが完了すると次のオブザーバを呼び出します。
検索インデックスシステムにこの仕組みを当てはめた時の動きを考えてみましょう。
1: 新しいWebページ、ドキュメントが追加されたことを検知します。
2: 最初のオブザーバがキックされると、例えば、追加されたあ新しいページ、ドキュメントの解析タスクが実行されます。
3: その後、下流のオブザーバに処理を引き渡し、結果をデータストアにあるテーブルに書き込む。また、それにより、その列を監視している次のオブザーバが呼び出され、例えばリンクの解析を行います。
このようにして、連鎖的な処理を繰り返し、実行する動きをしていくそうです。
Percolatorの内部アーキテクチャ内にあるBigTableとは?
Percolatorの内部アーキテクチャを見てみると、その裏側にはGoogle独自のワイドカラムNoSQLストアとして登場したBigTableをベースにしています。
ただ、BigTableはNoSQLストアということもあるので、ここままでは利用すると複数プロセスによる同時のトランザクションに対してACID特性を満たすことができません。
そこで、GoogleはPercolatorを使いつつ、単一行のアトミック性に、2フェーズコミットプロトコルを使用したACIDトランザクションを追加する改造を行い利用しています。
これによりそれぞれ複数プロセスによる同時実行されたトランザクションで不変条件を変えることなく、保持し続けることに成功しました。
そもそもインデックスシステムはどのように構築するべきなのでしょうか?
というのはインデックスのデータが保存されるストレージを含めた時にDBMSを使用できるのかいうことが書かれています。
結論としては、DBMSに保存し、トランザクションを使用して不変条件を維持しながら個々のデータを更新することはできる。しかし、Googleレベルの検索エンジンの場合、既存のDBMSでは超膨大なデータ量を処理することができません。冒頭述べたようにGoogleのインデックスシステムは、数十ペタバイトを数千台のマシンにまたがって保存しています。BigTableを例に挙げると、BigTable自体はデータのサイズ問題に対応することはできるが、同時更新の際のデータの不変条件を維持させる仕組みがありません。
検索インデックスシステムの機能に求められる要件
さて、ここまでインデックスシステムに求められることと、BigTableについて、BigTableでは超えられない壁についてに触れてきました。
では、Googleの検索エンジン、検索インデックスに求められる要件についてをおさらいしてみましょう。
ここで必要な要件とは、超膨大なデータ量に対し、それをのせることができかつ、新しいドキュメントが追加され、クロールされる度に効率的に更新処理ができるものが必要になります。
効率的に、というのは、同時並行で処理を行え、かつ、不変条件を維持し続けることができる機能がないとダメなのです。
インクリメンタル処理システム
上記の特性を持ったシステムを論文中では、インクリメンタル処理システムという表現をしていますが、Percolatorはまさにこの特性にあった仕組みを提供しています。
インクリメンタル処理システムというのは、大きなデータセットを少しずつ、段階的に更新・処理するシステムのことです。
そんなPercolatorの特徴としては、ACID準拠のトランザクションを提供し、トランザクション分離レベルとしては、スナップショットアイソレーションを実装する形をとっています。
詳細なPercolatorアーキテクチャの設計
下記は、GoogleのPercolatorアーキテクチャを分かりやすく図にしており、この図を中心説明していきます。
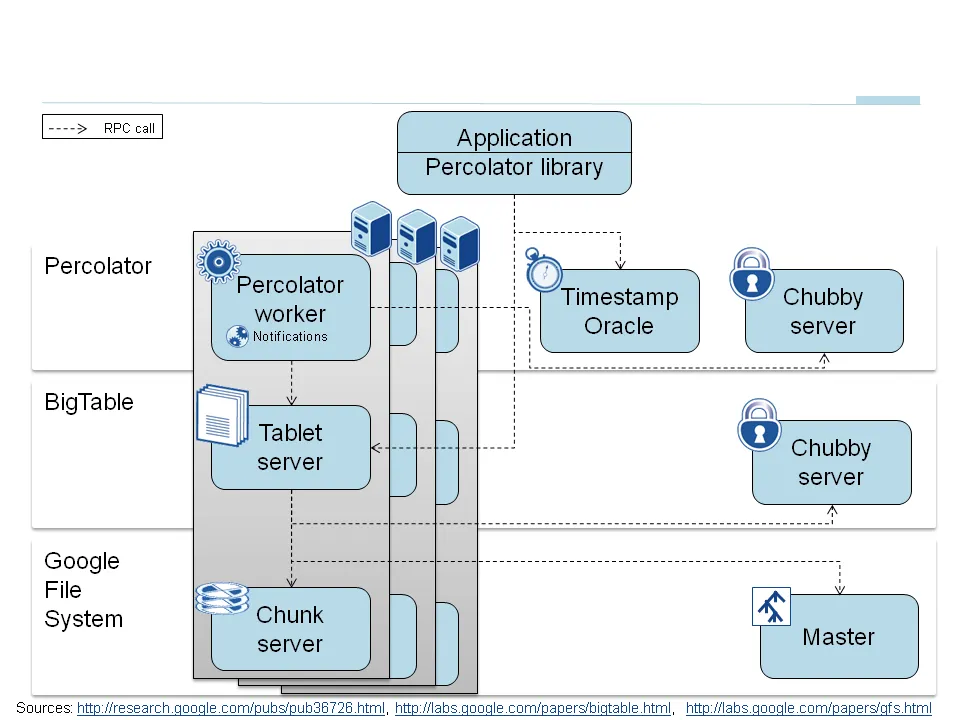
画像引用元: https://medium.com/yugabyte/implementing-distributed-transactions-the-google-way-percolator-vs-spanner-6cbccfc1f2ed
Percolatorは、これまでお話ししてきたように大規模なインクリメンタルな処理を実行するために2つの機能を備えています。
1: ランダムアクセスリポジトリに対するACID特性を実行するための機能
2: インクリメンタルな計算を実行するためのオブザーバ機能
また、Percolatorは3つのコンポーネントで動きます。
①: Percolatorワーカー
②: BigTableタブレットサーバ
③: Google File System(GFSチャンクサーバ)
これらのコンポーネントがあることがまず前提としてあり、そこにオブザーバの動きがそれぞれのコンポーネントの繋ぎ部分となります。
オブザーバーの実際の動きとしては、Percolatorワーカーにリンクされ、Bigtableで変更された列(通知)をスキャンし、対応するオブザーバーをワーカープロセス内の関数呼び出しとして実行します。
そして、オブザーバーはトランザクションを実行し、Bigtableタブレットサーバーに読み取り/書き込みのRPC(リモートプロシージャコール)を送信し、これがさらにGFSチャンクサーバーに読み取り/書き込みのRPCを送信する動きとなります。
BigTable
Percolatorは、BigTableの上に構築しているのはこれまでの話でも触れてきました。
Bigtableは各行に対して検索および更新操作ができ、行トランザクションを使ってアトミックな読み取り-修正-書き込み操作を可能にします。そして、なにより、ペタバイト規模のデータが取り扱え動作するのが特徴です。
また、PercolatorはBigtableのインターフェースを保持し、データはBigtableの行と列に整理され、メタデータは特別な列として一緒に保存されます。PercolatorのAPIはBigtableのAPIに非常に似ており、Percolatorライブラリは主にBigtable操作をPercolator側でラップしているとも言えます。
Percolatorにおけるトランザクション
次に、Percolatorにおけるトランザクションについてです。Percolatorは、スナップショットアイソレーションというトランザクション分離となります。
実際のトランザクションコードをユーザ側で書くときの例を見てみましょう。
下記は論文中に記載のあるC++のコードで、実際にこのコードでは、トランザクションコードとPercolator APIへの呼び出しが書かれています。
このコードにおける、Commit()がfalseを返すと、トランザクションが競合し(この場合だと、同じコンテンツハッシュを持つ2つのURLが同時に処理されたため)、バックオフ後に再試行する必要が発生します。
そのため、Get()およびCommit()の呼び出しはブロッキングされ、並列性はスレッドプールで多くのトランザクションを同時に実行することで達成されます。
このようなトランザクションの機能によりデータの整合性を保ちながら大規模なインクリメンタル処理を可能になります。
bool UpdateDocument(Document doc) {
Transaction t(&cluster);
t.Set(doc.url(), "contents", "document", doc.contents()); int hash = Hash(doc.contents());
// dups table maps hash → canonical URL
string canonical;
if (!t.Get(hash, "canonical-url", "dups", &canonical)) {
// No canonical yet; write myself in
t.Set(hash, "canonical-url", "dups", doc.url()); } // else this document already exists, ignore new copy return t.Commit();
}
タイムスタンプ
次に重要になってくること。それはトランザクションの競合を判断するためのタイムスタンプです。
Percolatorでは、タイムスタンプオラクルを利用しています。
タイムスタンプオラクルとは、厳密に増加する順序でタイムスタンプを提供するサーバです。
すべてのトランザクションがこのサービスに2回(Begin;とcommit;時)アクセスする必要があるため、このサービスは高いスケーラビリティが求められます。
通知
トランザクションを利用すると、ユーザーがテーブルを変更しながら不変条件を維持することを可能にしますが、ユーザーはトランザクションをトリガーして実行する方法も必要なはずです。
Percolatorでは、ユーザーがテーブルの変更によってトリガーされるオブザーバーを記述し、システム内のすべてのタブレットサーバーで実行されるバイナリにリンクできます。
各オブザーバーは、Percolatorに関数と列のセットを登録し、データがこれらの列の1つに書き込まれた後に関数を呼び出す動きをします。
あとは先ほど説明した通り、オブザーバはタスクを処理し、その後の次のタスクの実行をと連鎖的に処理していきます。
ここでいう通知は、データベーストリガーやアクティブデータベースのイベントに似ていますが、データベーストリガーとは異なり、データベースの不変条件を維持するために使用することはできません。Googleのインデックスシステムには約10のオブザーバーしかないようです。複数のオブザーバーが同じ列を監視することも可能ですが、特定の列が書き込まれたときにどのオブザーバーが実行されるかを明確にするためにこの機能は避けいるようです。各通知の変更には1つのオブザーバーのトランザクションしかコミットされないことを保証しています。
また、通知の検索を効率的に行うために、Percolatorは特別な「通知」列をBigtableに保持します。トランザクションが観測されたセルを書き込むと、対応する通知セルも設定されます。そうすると、オブザーバーがトリガーされ、トランザクションがコミットされると、通知セルが削除される動きをします。
その他の工夫
- PercolatorはMapReduceベースのシステムに比べて、1つの作業単位あたりのRPCの数が多いため、非効率な面があります。
- MapReduceはGoogle File Systemに対して1回の大きな読み取りを行い、10ページまたは100ページのデータを取得しますが、Percolatorは1つのドキュメントを処理するために約50個のBigtable操作を行うようです。
コミット中の追加のRPCの動きとしては、ロックを書き込む際には、競合するロックや書き込みをチェックするために2回のBigtable RPCが必要です。このオーバーヘッドを削減するために、Bigtable APIに条件付き変更を追加し、単一のRPCで読み取り/修正/書き込みステップを実行します。
同じタブレットサーバーに向けた多くの条件付き変更を1つのRPCにまとめることで、総RPC数をさらに削減します。ロック操作を数秒遅延させてバッチにまとめます。ロックは並行して取得されるため、各トランザクションのレイテンシーに数秒加算されるだけとなります。
読み取り操作のバッチ処理としては、同様に各読み取り操作を遅延させ、同じタブレットサーバーへの他の読み取りとバッチを形成する機会を与えます。この遅延により、トランザクションのレイテンシーが大幅に増加する可能性がありますが、事前取得とキャッシュを組み合わせることで、Bigtableの読み取り回数を10分の1に削減するそうです。Percolatorは、各列が読み取られるたびに、その行の他の列が後で読み取られるかどうかを予測し、事前に取得します。
全体のおさらい
Googleは、このPercolatorアーキテクチャを構築し、2010年4月からGoogleのウェブ検索インデックスを生成するために使用しています。
このシステムは、以前のインデックスシステムと比較して、単一のドキュメントのインデックス作成のレイテンシを大幅に削減し、リソース使用量の増加を許容範囲内に抑えるという目標を達成することができたのです。
そして、このPercolatorの論文にインスピレーションを受けたのがTiDBとなります。
TiDBのトランザクションの仕組みは、まさにこのPercolatorの動きを参考にし実装されたものとなっているのです。
もし、興味がある方がいれば、ぜひTiDBのトランザクションの動きをまとめた記事があるので、ご参照ください。
まとめ
いかがだったでしょうか?
TiDBの世界は奥が深いです。引き続き様々な機能についてを深掘りブログ化していきたいと思います。
公式ブログ/資料等
Discussion