TiKVにおけるトランザクションとMVCCの話
はじめに
PingCAPの小板橋です。はじめまして!
TiDBの入門記事から上級者編まで幅広く取り扱う本アカウント第5回目は「TiKVにおけるトランザクションとMVCCの話」についてをまとめていきたいと思います。
TiKVの仕組み
まずは、TiKVの仕組みについてを見ていきましょう。
全体のTiDBクラスターのアーキテクチャについては、下記の記事をご覧ください。
TiDBクラスターにおけるデータレイヤーにあるストレージノードとしてTiKVと呼ばれるものがあります。
TiKVは、分散型のキーバリューデータベースになり、ACIDに準拠したトランザクションAPIを提供しています。このTiKVの裏には、RocksDBとRaftコンセンサスアルゴリズムによって動作しています。
Raftコンセンサスアルゴリズムについては、また別の記事で深ぼっていきます。(こちらはこちらでお楽しみに!)
RocksDBに格納されたコンセンサス状態により、TiKVは複数のレプリカ間のデータの一貫性と高可用性を保証する。TiDB分散データベースのストレージ層として、TiKVは読み書きサービスを提供し、アプリケーションから書き込まれたデータを永続化します。また、TiDBクラスタの統計データも格納する動きをします。
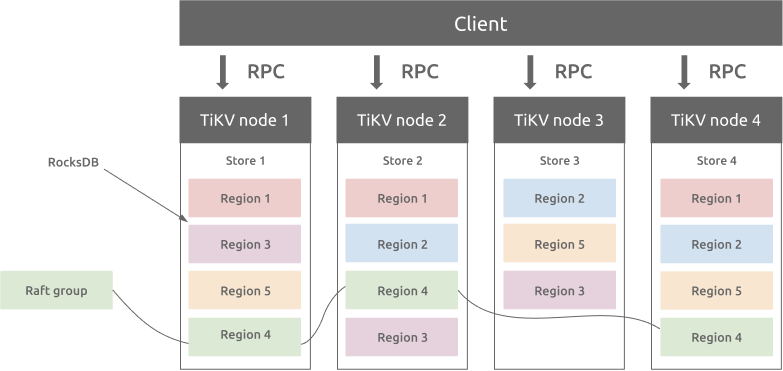
TiKVは元々、Google Spannerの論文に基づき、multi-raft-group レプリカ機構を実装しています。
過去の記事にも触れているようにTiKVにおけるリージョンというものは、ストレージ内における小さなデータ領域だと思ってください。格納形式は、key-valueの形でデータが保存されます。
各リージョンは、複数のTiKVノードにレプリケーションされる動きをします。 デフォルトの設定だと96MBというデータ領域がリージョンの単位となります。
これらの複数にレプリケーションされたレプリカ達はRaftグループを形成します。
RegionのレプリカはPeerと呼ばれ、通常においてはリージョンには3つのPeerが存在します。
- 1つのリージョン: リーダに選出されたリージョンは、読み書きのI/Oを担当します。
- 2つのリージョン: それ以外のリージョンは、フォロワーになり、リーダに書き込まれたデータがリアルタイムでレプリケーションされ、バックアップとして機能します。
ここで、過去にも触れたPDノードが全てのリージョンのバランスを自動的に調整し、読み書きにおけるスループットのバランスを保証します。これらPDノードとRaftグループの仕組みにより、TiKVは水平方向のスケーラビリティに優れており、100TBを超えるデータを保存することができるという特性を持ちます。
また、この後にお話しするのだが、TiKVは分散トランザクションをサポートしています。
同じリージョンにどうか書き込むのかなどを気にする必要はなく、複数のKeyとvalueのペアで書き込むことができるのです。
また、TiKVはACID特性を実現するために2フェーズコミットを利用しています。
RocksDBとは?
先ほども、TIKVの仕組みで触れた通り、TiKVの内側にはRocksDBと呼ばれるデータベースがいます。
RocksDBは、LSM-Treeストレージエンジンの仕組みをとっています。要は下記のように、書込みに特化した構造となっており、追記型でデータを格納していきます。格納していく中で、ソート/マージしつつディスクに保存動きをします。

-
RocksDBは、Facebookによって開発されたLevelDBを基としたデータベースになります。
ユーザによって書き込まれたKeyとValueのペアは、まずはWAL(Write Ahead Log)に挿入され、その後、メモリ上のSkipList(MemTableと呼ばれるデータ構造)に書き込まれます。 -
LSM-Treeストレージエンジンの動きは、変更をWALファイルへシーケンシャルな書き込みに変換するので、B-Treeよりも書き込むのスループットが向上するそうです。
-
メモリ上のデータが一定のサイズになると、今度はRocksDBがディスク上のSST(Sorted String Table)ファイルにデータをフラッシュする動きをします。
-
SSTファイル複数のレベルで構成されます。このレベルは、デフォルトだと最大6レベルとなっています。
-
あるレベルの合計サイズにSSTファイルが達すると、SSTファイルの一部を選択し、次のレベルにマージする動きをします。上記の簡略化された図を参考にしてください。
-
下のレベルになればなるほど、前のレベルより10倍大きなサイズを持っているので、データの90%が最後のレイヤに保存される動きとなります。
-
RocksDBでは複数のCF(カラムファミリ)を作成することができます。
-
CFの構成は、それぞれ独自のSkipListファイルとSSTファイルを持ち、同じWALファイルを共有します。
下記がTiKVの全体アーキテクチャになります。

全体のアーキテクチャを見た時に2つのRocksDBがいると思うのですが、実際にはデータの永続化には下記のようにKeyとValueのペアを保存するRocksDBとRaftログを保存するRocksDBになります。

RocksDBにおける書き込み処理
まずは、RocksDBにおける書き込み処理についてを見ていきましょう。
RocksDBにおける書き込みは、例えば、削除や更新といった処理をリクエストした時に、元のデータの位置に対して書き込む訳ではなく、新しいデータとして書き込まれる形で動いていきます。
下記の図の右上に記載されているように、put key=1, value="tom"、del key=1233、 ・・・といったように順番にデータが書き込まれる動きとなるのです。
この動きにより書き込み処理のパフォーマンスが優れており、なぜならば元のデータを探す処理はせずに動くからです。
次にRocksDBにおける書き込み処理の詳細を見ていきましょう。
まず、クライアント側から書き込み処理が行われた時は、下記の2つにデータが保存されます。
これはあくまでフロント側での処理となります。
1: Memory上にあるMemTable
2: Disk上にあるWAL(Write Ahead Log)ファイル
1にあるMemTableがフルになった時は、バックグラウンド処理としてimmutable MemTableに書き込まれ、その後SST(Sorted String Table)にフラッシュされる動きとなります。
また、MemTableについては、サイズが 128 MB を超えると、新しいMemTableに切り替わります。
同時に最大5つのMemTableが存在でき、それ以外の場合、フォアグラウンド書き込みはブロックされます。この部分が占有するメモリは最大 2.5 GB(4x5x128 MB) になります。
この制限を変更するとメモリの消費が少なくなるため、変更することはお勧めされていません。

RocksDBにおける読み取り処理
次にRocksDBにおける読み込み処理の詳細を見ていきましょう。
順番としては、下記の順で読み取りを行います。
1: Memory内にあるMemTable
2: immutable MemTable
3: Block Cache
4: SST
ここで重要なことは、SST読み取る際に二分探索での検索を行っていきます。

TiKVにおけるBlockCache
また、RocksDBはディスクに保存されているファイルを特定のサイズ(デフォルトで64KB)に基づきブロック単位で分割しています。
このブロックを読み取る時に、まずデータがメモリ内のBlockCacheに存在しているかを確認し、もしあれば、ディスクにアクセスせずにメモリから直接データを読み取ることができます。
このBlockCacheは、LRUのアルゴリズムに従い、最も最近使用されていないデータを破棄する動きとなります。
また、BlockCacheはデフォルトとしては、TiKVのシステムメモリの45%をBlockCacheに割り当てます。
※ ちなみに、ユーザーは、storage.block-cache.capacity設定を自分で適切な値に変更することもできます。ただ、総システムメモリの 60% を超えることは推奨されていないようです。
RocksDBのスペース使用量
RocksDBは、LSMツリー構造を備えたKey/Valueのstorageエンジンであるので、上記の図のようにMemTable内のデータは最初にL0にフラッシュされます。
ファイルは、生成された順に配置されるので、L0のSSTの範囲の間で重複が存在する可能性もあるようです。
=> なので、結果的に同じキーがL0に複数バージョンを持つ可能性があります。ファイルをL0->L1に結合すると、デフォルト8MBで複数ファイルに分割されます。
ちなみに、同じレベルの各ファイルのキー範囲重複は内容で、L1以降のレベルでは各キーのバージョンが一意に定まります。
各レベルのファイルの合計サイズは、一段上のレベル✖️10倍(デフォルト)であるので、データの90%が最後のレベルに保存されることになります。
RocksDBにおけるCF(カラムファミリ)
1つのRocksDBは、複数のカラムファミリ(以降、CF)を持つことができます。
TiDBでは、Default, Write, Lock, Raftという4つのCFを持ち、トランザクションおよびMVCCを実現する動きとなっています。(各CFの1つのMemTableのサイズ制限は128MBです。)
それぞれのCFが何をしているのかをみていきましょう。
Raft CF
各リージョンのメタデータを格納します。使う領域は小さいです。
Lock CF
悲観的ロックと分散トランザクションのPrewriteロックを格納します。
動きとしては、トランザクションがコミットされた後、Lock CF内に格納されるデータはすぐに削除される動きをします。(Lock CF内のデータサイズは、1GB未満)
Write CF
ユーザが書き込んだデータとMVCCメタデータ(データが属するトランザクションの開始時のタイムスタンプ / コミットタイムスタンプ)を保存しています。
rowデータを書き込むとき、データ超が255バイト未満の場合、データはCFに保存されます。
それ以外の場合は、Default CFに保存されます。
TiDB では、ユニークでないインデックスに格納されている値は空であり、ユニークインデックスに格納されている値が主キーインデックスであるため、セカンダリインデックスはWrite CFのスペースのみを占有します。
Default CF
255 バイトを超えるデータを格納します。
CFは、Memory(Block Cache, MemTable, immutable MemTable)とDiskにSSTファイルとWALを持ちます。
ただ、複数のCF間でWALは共有しています。

トランザクションの仕組み
分散型のデータベースにおける課題として、トランザクションにおけるACID特性が上がると思います。
特にA(Automicity)- 原子性についてですね。
トランザクションにおける原始性とは、そのトランザクションの処理が全て成功する/失敗することを保証するという意味になります。
なので、例えば、ECサイトの購入トランザクションを考えた場合、物品の購入と在庫の更新がすべて成功するか、何も行われないかのどちらかです。
逆にいうと、トランザクションの中で一部の処理が成功するといった動きは、この原子性が保てていないということになります。
分散型データベース、今回だとTiDBになるのですが、この原子性のトランザクションを担保するためにどうしているのでしょうか。
クライアントは、Begin;から始まるトランザクションをTiDBに送ると、TiDBはTiDBノードが受け取ります。TiDBノードは、SQLを解析するTiDBクラスターにおけるコンピューティング層になります。
その後TiDBノードは、トランザクションが始まることを解析すると、PDノードからstart_tsと呼ばれる"開始タイムスタンプ"を受け取ります。
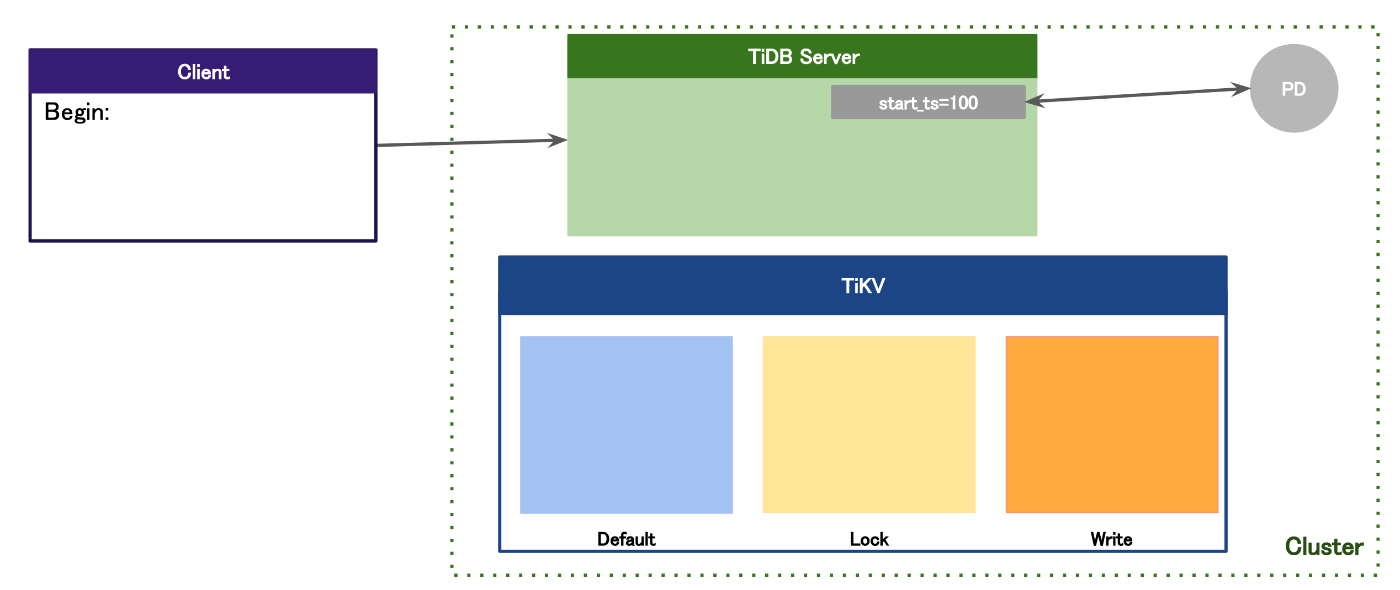
DML発行後の動き
その後、DMLを発行する動きでは、クライアントが送ったDMLをTiDBノードが受け取った際に、先ほどPDノードから受け取ったstart_tsを使い、PKとstart_tsを組み合わせたキーとします。そして、Key-valueの形を作成します。
この時、他のトランザクションにより同じキーに対応する値の更新が行われる処理が走るとまずいので、ロックする必要があります。
このロック情報というのが、先ほど説明したTiKV内にあるLock CFに書き込まれるのです。
このような動きを悲観トランザクションと呼びます。
TiDBについては楽観トランザクションのモードもあるので、そちらはこのあと説明していきます。

2フェーズコミット-Prewriteの動き
トランザクションの中で最後にCommit;された時の動きについてです。
2フェーズコミットの動きとしては、1:Prewrite、2:コミット/ロールバックという2段階に分かれます。Commit;されるとRocksDB内にデータが永続化される動きとなります。
1:Prewrite
まず、Prewriteの動作としてはCommit;されると一時的にTiDBノードのメモリ上に書き込まれます。
その後、書き込まれたデータをTiKVのDefault CFに永続化されます。
つまりは、TiDBノードにあるデータは、Default CFに書き込まれるという流れですね。
2:コミット
次に、コミットの動作になります。
まずTiDBノードは、PDノードよりcommit_tsを獲得する動きをします。
次にデータ内にある、下記だと3+獲得したcommit_tsを組み合わせた形をキーとし、Begin;時に獲得したstart_tsをValueとして、この組み合わせたものをWrite cfに書き込みます。
Write CFにはトランザクションの書き込み情報が書き込まれるので、その際にLock CFに書かれたデータの削除を行うのですが、実際には削除されるわけではなく、削除したという情報をLock CFに追加する形となります。
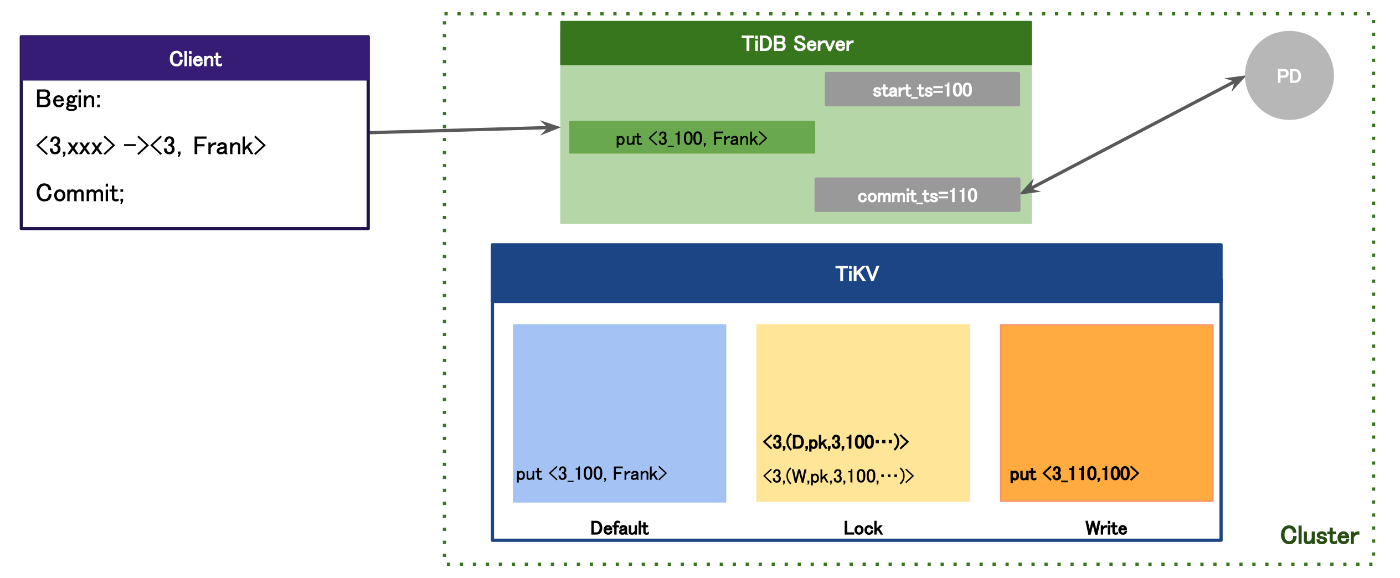
悲観トランザクション(デフォルト)の動きまとめ
1: Clientからbegin;が入ると、TiDBノードによるPDノードからstart_tsを獲得する
2: DMLを受け取ると、TiDB ノードのメモリにデータを一時的に書き込み、それぞれのTiKVノードの Lock CF にロック情報を書き込む
3: commit;が入ると、2フェーズコミットされる。
3-1: それぞれのTiKVノードのDefault CFもしくはWrite CFに行データを書き込む
3-2: PDノードからcommit_ts を獲得し、それぞれのTiKVノードのWrite CFにcommit_tsを含めたコミット情報を書き込む。その後、ロックが削除された情報をそれぞれのTiKVノードのLock CFに書き込む
楽観トランザクションの動きまとめ
楽観トランザクションモード場合、DMLではなくCommit;が発行された時の、2フェーズコミットにおけるPrewriteのタイミングでロックを取りにいきます。
ただ、楽観トランザクションモードの場合の優位点としては、オーバヘッドが少ないので、トランザクションが少ないようなワークロードに対して有効です。
1: Clientからbegin;が入ると、TiDBノードによるPDノードからstart_tsを獲得する
2: DMLを受け取ると、TiDB ノードのメモリにデータを一時的に書き込む
3: commit;が入ると、2フェーズコミットされる。
3-1: それぞれのTiKVノードのDefault CFもしくはWrite CFに行データを書き込み、TiKVノードのLock CFにロック情報を書き込む
3-2: PDからcommit_ts を獲得した後、それぞれのTiKVノードのWrite CFにcommit_ts を含めたコミット情報を書き込みます。また、ロックが削除された情報をそれぞれのTiKVノードのLock CFに書き込みます
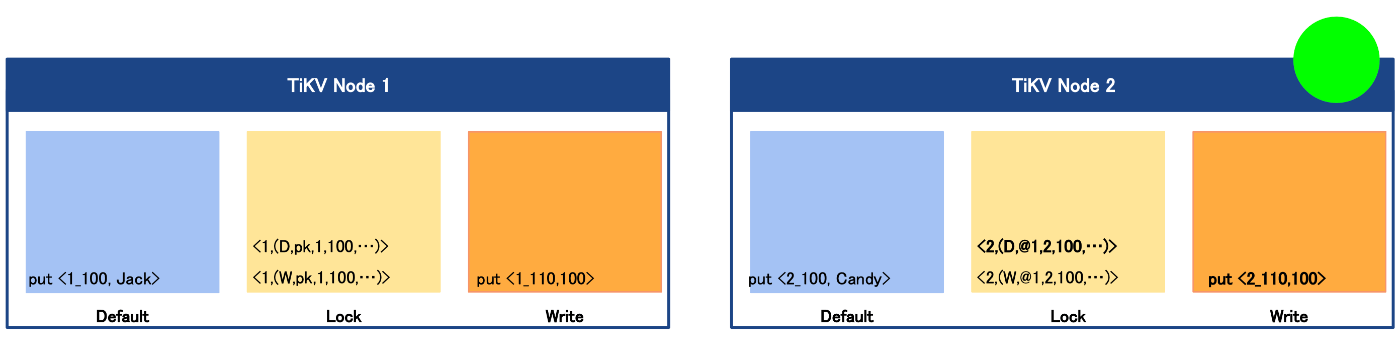
プライマリーロック(PK)
プライマリーロックは、複数の行を更新するトランザクションに有効です。
仕組みとしては、トランザクションの中で最初に更新された行にかけるロックです。
どう動くのかというと下記のような更新をするトランザクションがあった時に、行としては1行目のものにロックをかけ、その後2行目のものについては、1行目のロックへのポインタを保持する形となります。なので下記でいうid2を参照した際に、id1のロック状況をポインタを使い、参照し、ロック中かどうかを確認する動きとなります。
Begin;(start_ts = 100)
<1, Tom> -> <1, Jack>
<2, Andy> -> <2, Candy>
commit;(commit_ts = 110)

この仕組みでどのように原子性を保っているのか?
まずは、先ほどと同じトランザクションを例にしてみましょう。
Begin;(start_ts = 100)
<1, Tom> -> <1, Jack>
<2, Andy> -> <2, Candy>
commit;(commit_ts = 110)
例えば、上記のトランザクションがあり、PK=2の更新が発生したタイミングでTiKVノード2がダウンしたとします。
そうすると、pk2のコミット情報は下記のように入らなくなってしまいます。

その後、TiKVノード2が障害から復旧し、回復したとします。
そうすると、TiKVノード2のLock CF上では、まだPK=2のものがロックされているように見えますが、プライマリーロックに仕組みで、TiKVノード1をポインタ参照しLock CFを確認します。
そうすると、PK=1のロック情報は削除されていることが分かるので、その時TiKVノード2のLock CF上でPK=2のロック情報を削除する動きをします。

なので、プライマリーロックがとても重要で、プライマリーロックの更新が成功すれば、トランザクションは成功し、プライマリーロックの更新が失敗すればトランザクションは失敗するという動きになるのです。
MVCC
次に、TiDBにおけるMVCC(MultiVersion Concurrency Control:多版型同時実行制御)についてをお話ししていきます。
MVCCは更新中のデータ読み込みに有効な仕組みになっています。
よくあるRDBMSの動きの場合
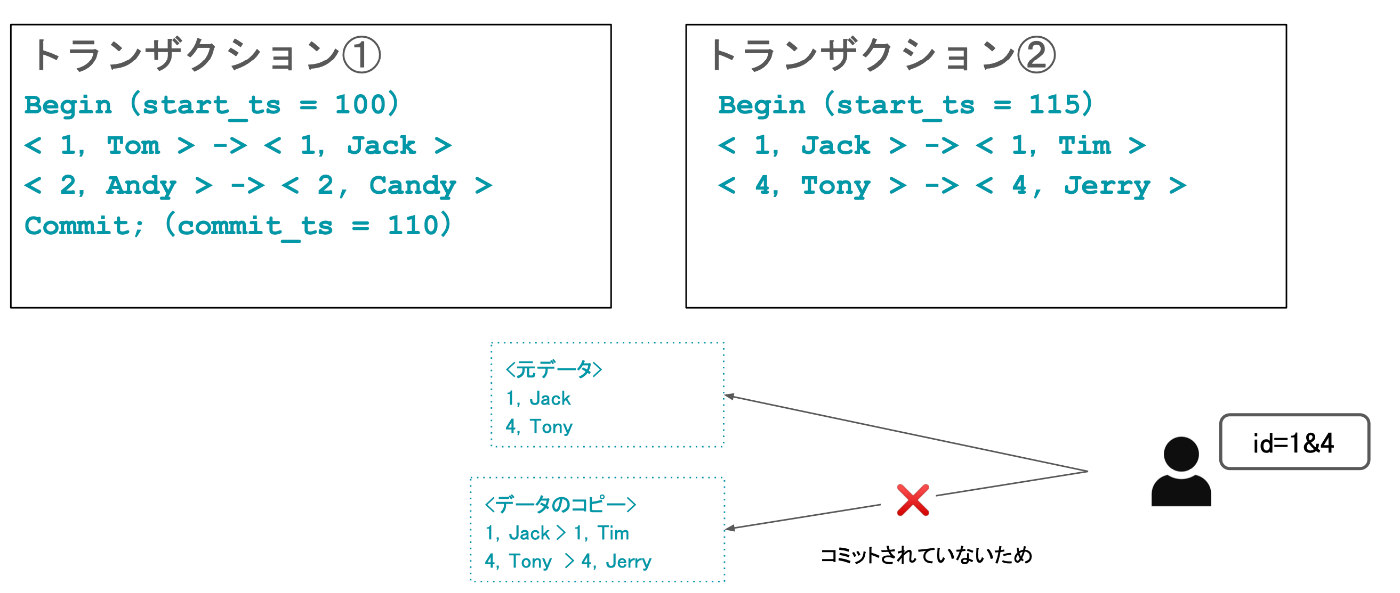
例えば、下記のように、トランザクション①とトランザクション②があった時に、トランザクション②がまだコミットされていないとしましょう。
この状況下の中でユーザがPK1,4を引こうとした際に、トランザクションの分離レベルのよって取れるものが変わってくるのが全体ですが、多くのデータベースではコミットされていないデータは読み込まれれない動きとなる。なので、コミットされる前のデータが取れる動きとなります。
更新する際には、よくあるパターンとして、元あるデータのコピーを作成し、そのコピーに対して更新する動きとなります。そして、他のトランザクションにより読み取ろうとしたら、元のデータを読み取る位動きとなります。
TiDBの動きの場合
TiDBは、先ほどのRocksDBの仕組みが効いてくるので、基本データの書き込みは順序書き込みとなるので、元のデータは残っていることになります。
なので、読み取る時の動きは古いバージョンの情報を読み取るだけでいいことになります。
あとは、下記の図にもあるようにTS(タイムスタンプ)の時間をみながら、最終的にコミットされた時間と比較し、データを読み取る動きとなります。

まとめ
いかがだったでしょうか?
TiDBの世界は奥が深いです。引き続き様々な機能についてを深掘りブログ化していきたいと思います。
公式ブログ/資料等
Discussion