TiDB によるインデックス作成の高速化
はじめに
PingCAPの小板橋です。はじめまして!
TiDBの入門記事から上級者編まで幅広く取り扱う本アカウント第7回目は「TiDB によるインデックスの高速化」についてをまとめていきたいと思います。
TiDBのアーキテクチャなどについては、下記の記事をご確認ください。
TiDB によるインデックス作成の高速化をする方法とは
TiDBにおけるIndexの作成については、オンラインで実施されるので、例えばあるテーブルにインデックスを追加しつつ、同一テーブル上のDMLトランザクションを同時に実行することができるというわけです。
=> これを実現するために、TiDBにおけるIndex作成プロセスは内部的に5つの状態に分けられます。
- None
- DeleteOnly
- WriteOnly
- WriteReorganization
- Public
None
この状態は初期状態を指します。
DeleteOnly
インデックスのスキーマオブジェクトは、トランザクションに対しては内部的に表示されますが、インデックスのレコードは削除のみできます。
WriteOnly
インデックスのスキーマオブジェクトは、トランザクションに対して内部的に表示され、インデックス のレコードを追加/削除/更新することができます。
WriteReorganization
インデックスのスキーマオブジェクトは、トランザクションに対して内部的に表示され、インデックス のレコードを追加/削除/更新できます。
また、バックフィルワーカーはこの状態でスケジュールされることになり、インデックスのレコードがすべて既存の行に対して「バックフィル」されるようにします。
Public
すべての作業が完了し、インデックスがユーザーに表示される状態が、Publicな状態です。
バックフィルプロセス
例えば、すでにある既存のデーブルに対して新しいIndexを作成したいとします。
その時に、バックフィルプロセスが動くわけですが、動きとしては、まずテーブルスキャンを全てのレコードに対し行い、レコードごとにIndexキーと値のペアを生成します。
インデックスデータはTiKVに戻し、新しいインデックスデータを作成します。
=> この新しいインデックスデータを作成する処理なのですが、当然のようにデータ量が増えれば、かかる時間も増えることになります。
そこで、このIndex作成のパフォーマンスを向上させるため、下記の2つの対策が施されています。
①: 並列実行するバックフィルタスク
②: 全てのバックフィルバッチのサイズ等を調整する
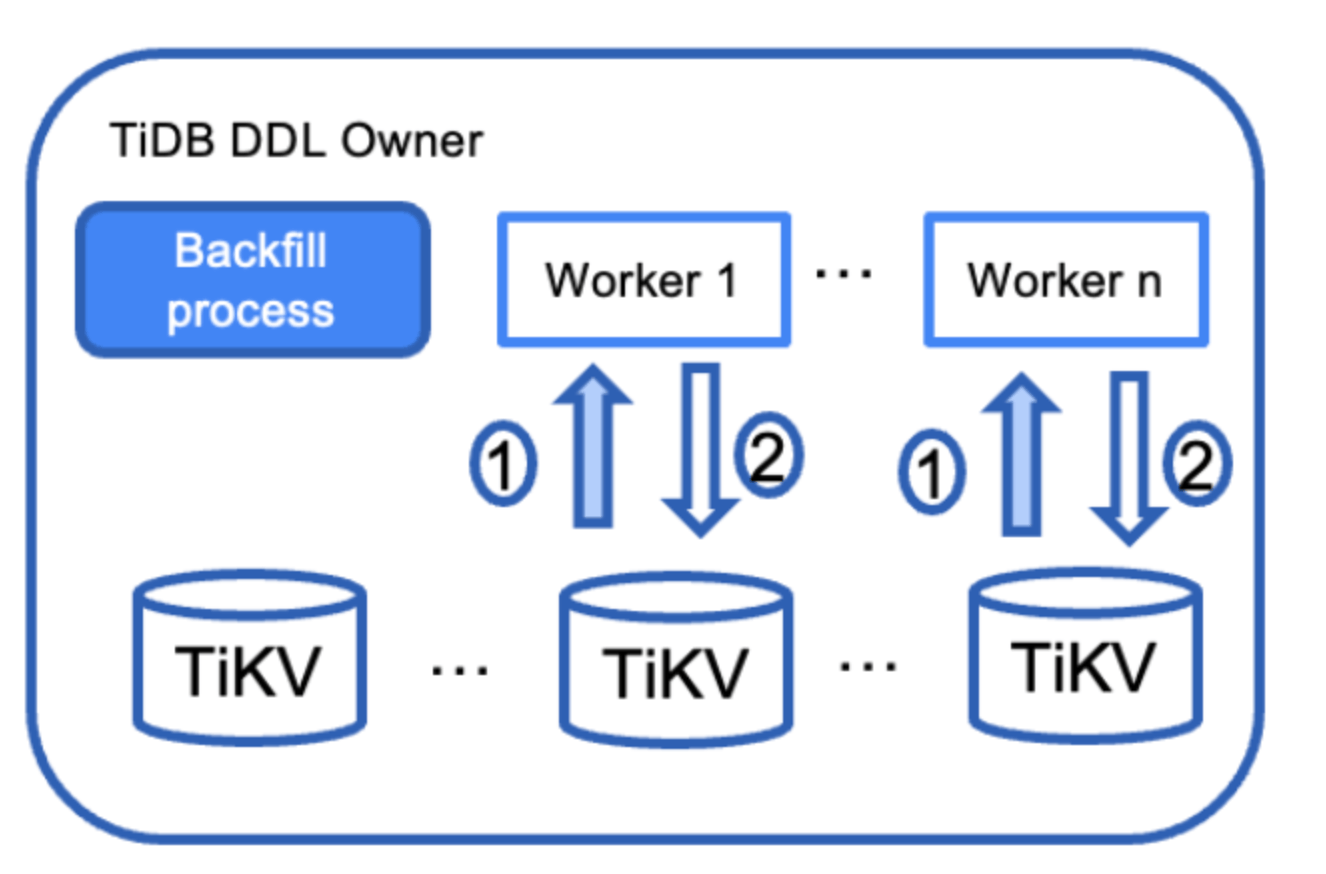
下記はバックフィル実行時の動きを表しています。
TiDBクラスター内にいるTiDBノードのなかでDDLオーナーになっているノードとTiKVがあったとします。
- まず、バックフィルのタスクが作成された時にこのバックフィルのタスクはシリアルサブタスクに分割され、各サブタスクには1つのバッチサイズレコードが含まれています。
- 次に、Workerが起動されるのですが、このWorkerもシリアルに起動され先ほどのバックフィルのサブタスクが並列実行される動きとなります。
- 各Workerの動きとしては、テーブルから特定のレコードをスキャンする動きをします。
- 最後に、このバッチのレコードのインデックスデータを生成し、Optimisticな書き込みトランザクションを使用してTiKVに書きます。
実はこの並列実行される動きは、tidb_ddl_enable_fast_reorgというパラメータのデフォルトの設定となります。この変数に"ON"が設定されていると、大量のデータを含むテーブルでのインデックス作成のパフォーマンスを向上するため並列実行する動きとなるのです。
Indexを作成する際の新しい方法
まだ、実装されてはいないのだが、今後上記のIndexを作成する仕組みが変わるかもしれない提案がされているようです。
どんなものなのかを簡単に説明していきます。
すごい簡単にまとめると下記の図になるのですが、要はバックフィルトランザクションをTiKVにコミットするのではなく、Lightningというツールを利用し、バックフィルを取り込む方式です。
動きとしては、最初にインデックスデータをローカルストレージに書き込む動きをすることで、ユーザによるトランザクションとの競合を解消し、バックフィル自体のトランザクションコミット時間も不要になるメリットがあるようです。

詳細な動き
①: まず初めに、現行の動きと同じなのですが、Workerはサブタスクを割り当て、WriteReorganization状態のデータをスキャンします。
②: インデックスデータのトランザクションをコミットする代わりに、このインデックスデータのバッチを生成します。各Workerのために構築されたLightningが組み込まれたバックフィルライターは、インデックスデータをローカルバッファに書き込み、SSTファイルとしてローカルストレージにフラッシュします。
③: 複数のSSTファイルを1つに圧縮する際に、インデックスデータが並び替えられ、各ファイルは提供されれている既存のインターフェースによってTiKVに取り込まれます。
④: TiKVは最終的に、取り込んだインデックスデータのフルコピーをユーザによるDMLトランザクションによって更新されたインデックス部分と結合します。
なぜ現在のバックフィルプロセスは非効率と思われているのか
理由は2つあるとされています。
①: トランザクションの実行には、2フェーズコミットプロセスが必要で、TiKVに対する一連のPut操作が行われるので、大量のインデックスレコードを構築しようとすると余分なオーバーヘッドが発生してしまいます。
②: インデックスデータは、バッチ書き込みトランザクションでTiKVに書き込まれます。フォアグラウンドによるトランザクションと競合する可能性があるため、再試行する必要が発生してしまいます。
まとめ
いかがだったでしょうか?
TiDBの世界は奥が深いです。引き続き様々な機能についてを深掘りブログ化していきたいと思います。
Discussion