【ソフトウェア設計】例外処理を考える
はじめに
最近書いてるソフトウェア設計シリーズです。今回は例外に関して。以前、以下のような記事を書いたのですが、もう少し深堀して書いてみました。
ちなみにソフトウェア設計シリーズは他には以下を書いています。
TL;DR
- 例外は「原則」キャッチしない
- 業務例外や必ずハンドリングさせたい例外はOptionalなど戻り値の方が便利
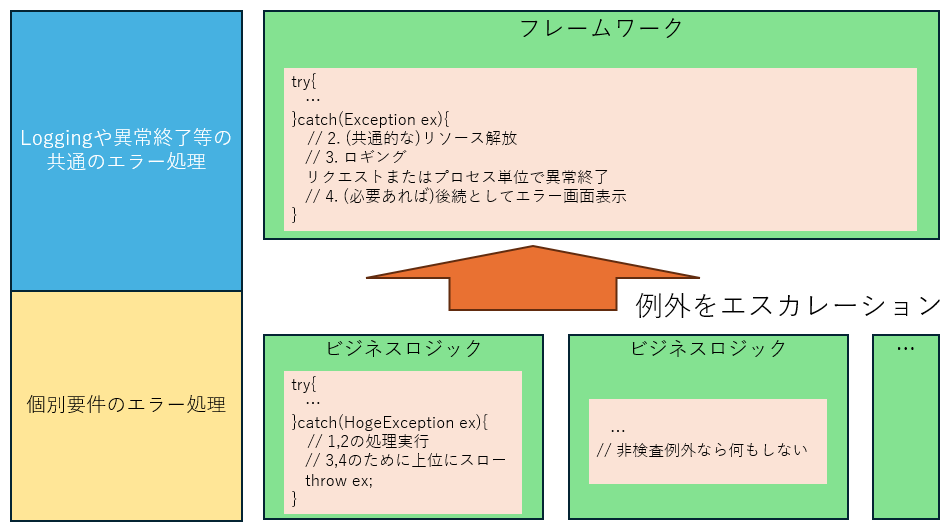
- だいたい以下の図が言いたい事のすべて
例外処理とは?
「例外処理(Exception Handling)」は言語に依らず普遍的な関心事です。端的に言えば例外処理は異常やシステムの動作に不備が発生した際の特別な分岐処理です。リカバリやリソースの解放、あるいはユーザへの通知などがありますね。
例外処理には多くの流儀や仕組みがあり、言語やコミュニティによって異なります。例えばJavaのようなtry-catchを利用した大域脱出の仕組みもあれば、多くの関数型言語のようにOption/Eitherを使う方式、あるいはGo言語のように単純に戻り値で表現するパターン。こうした例外処理の表現方法だけでは無く、例えばJavaのようにエラーと例外を区別する考え方、検査例外と非検査例外、システム例外と業務例外を区別する考え方など、様々な分類や考え方があります。
「どれが最適なのか?」は状況によって異なりますし、好みもあります。この記事では、基本的な分類を説明しつつ、JavaでWebアプリやバッチといった業務システムを書く上での設計ポイントを私なりにまとめてみました。
例外の分類方法
例外とエラー
例外(Exception) と エラー(Error) という言葉を聞いたことはありますか? 似た印象を受けると思いますが、「例外とエラーは違う」 という話も良く聞く話題ですね。例えば「エラーの場合はプログラムで対処できない致命的な状態を指し、例外の場合はプログラムで対処できる状態を指す」、などです。実のところ、これはプログラミング言語やコミュニティによって定義が異なるので、「普遍的な概念として両者を明確に定義することは不可能」と言われています。逆に言えばコンテキストを決めれば明示的な場合もあります。Javaでは、以下のように定義されています。
ErrorはThrowableのサブクラスで、通常のアプリケーションであればキャッチすべきではない重大な問題を示します。 そうしたエラーの大部分は異常な状態です。
Exceptionクラスとそのサブクラスは、通常のアプリケーションでキャッチされる可能性のある状態を示すThrowableの形式の1つです。
ref: https://docs.oracle.com/javase/jp/21/docs/api/java.base/java/lang/Exception.html
ref: https://docs.oracle.com/javase/jp/21/docs/api/java.base/java/lang/Error.html
Errorの子クラスにはVirtualMachineErrorとかOutOfMemoryErrorに代表されるようにアプリケーション上で対処のしようの無い状態が表現されています。Javadocにもある通り通常はアプリケーションでキャッチするべきではありません[1]
一方でExceptionは子クラスにあるArrayIndexOutOfBoundsExceptionのようにコーディング上の考慮不備であったり、FileNotFoundExceptionのようにプログラム中でハンドリングを考慮するべき状態です。個人的な経験としてはコーディング時にはそもそもErrorを原則扱わないので、そこまで気にする必要はありませんが、トラブルシューティングの際にどのレイヤーに起因する問題なのかを把握しやすくるなるので、違いは覚えておくべきでしょう。
検査例外と非検査例外
Javaには検査例外(checked exception) と 非検査例外(unchecked exception) という分類があります。
| 種類 | 説明 | 具体的な例 | 扱い方 |
|---|---|---|---|
| 検査例外 (Checked Exceptions) | コンパイラによってその処理を強制される例外。プログラムの実行時に発生が予見される問題を表し、適切に捕捉するかメソッドで例外を宣言する必要がある。 |
FileNotFoundException, IOException
|
プログラマが事前に問題に対処するためのコードを書くことを強制し、堅牢なプログラムを作る。 |
| 非検査例外 (Unchecked Exceptions) | コンパイラがチェックを強制しない例外。主にプログラムのバグによるもので、例えば配列の範囲外アクセスやnullオブジェクトの参照操作が含まれる。 |
NullPointerException, ArrayIndexOutOfBoundsException
|
主にプログラムのデータやロジック誤りを指摘し、プログラムのテスト中に発見されるべき。 |
非検査例外は実装的にはRuntimeExceptionを継承したもので、テスト中に発見されるべきコーディングの不備です。一方で、検査例外はIOExceptionやSQLExeptionのようにコーディングの不備とは関係なく起こりえる問題で適切なハンドリングが漏れていないかをコンパイラがチェックする事で、抜け漏れないの無い堅牢なアプリケーションを実現するための仕組みです。
一方で、この仕組みは古くから議論を呼んでおり、2004年の記事でも言及されています。その理由は以下の通りです。
-
冗長性とコードの可読性の低下:
検査例外を適切に処理するためには、try-catchブロックを多用する必要があり、これがコードの複雑さを増加させ、可読性を低下させることがあります。 -
例外の伝播:
検査例外が発生する可能性のあるメソッドを使用する場合、その例外をキャッチするか、または再度throwsすることによって呼び出し元に伝播させる必要があります。これが連鎖的に多くのメソッドに影響を及ぼし、コード管理を困難にすることがあります。また、それを避けるための誤ったコーディングを助長します。 -
モジュールの使用者への制約:
モジュールが検査例外を使用する場合、そのモジュールを使用するすべての開発者がその例外を処理する必要があり、しばしばモジュールの使用を困難にします。またDAOのようにRDBを使うとは限らない処理もSQLExceptionを投げる等、内部の実装が漏れ出してしまう場合もあります。
では、実際に上記の課題を含んだサンプルコードを見てみましょう。
public class DataProcessor {
public static void main(String[] args) {
try {
processData("data/config.txt");
} catch (FileNotFoundException e) {
System.out.println("設定ファイルが見つかりません: " + e.getMessage());
}
}
public static void processData(String filePath) throws FileNotFoundException {
File file = new File(filePath);
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream(file);
int data;
while ((data = fileInputStream.read()) != -1) {
// データを処理する
System.out.print((char) data);
}
} catch (IOException e) {
System.err.println("データ読み込み中にエラーが発生しました: " + e.getMessage());
} finally {
if (fileInputStream != null) {
try {
fileInputStream.close();
} catch (IOException e) {
System.err.println("ファイルストリームのクローズ中にエラーが発生しました: " + e.getMessage());
}
}
}
}
}
このコード例にはいくつかの点で検査例外の課題が表れています。まず、processDataメソッドは FileNotFoundException を throws キーワードを使用して明示的に宣言しています。これは、このメソッドを呼び出すすべてのメソッドが、この例外を処理するか、さらに上位に伝播させる必要があることを意味します。このような伝播は、モジュールの使用者に対してボイラーコード的なエラーハンドリングを強制し、複雑にします。次に、FileNotFoundException はファイルが見つからなかった場合に発生する特定のシナリオを示しています。そのため将来的にDBやAPI経由でデータを処理したい場合に、その設計を適用出来ないか広範囲の改修が要求されてしまいます。
また、例外ハンドリングの一貫性の無さも上げられます。processData メソッド内で IOException をキャッチしている一方で、FileNotFoundException は外部でキャッチされています。こうした不一致は、例外処理の一貫性を損ね、コードの読みやすさと保守性に影響を与えます。実際、例外ハンドリングのロジックが分散した結果として、System.out.printlnを使うケースとSystem.err.printlnを使うケースに分かれてしまっています。意図的にハンドリングのレベルを変えたい時には適切ですが、このような同じ 「ログとして出力する」 というレベルのコードが散らばってしまうのは認知的負荷を上げ、変更箇所の増大も発生して、複雑性を増す要因になります。
あるいは、別の視点として、FWなどの上位の例外ハンドラで共通の例外処理をすると想定した場合、前述の通り伝播を繰り返すボイラーコードを延々と書くことになり非常に冗長です。特に最悪なのはこうした冗長なコーディングを嫌って以下のように例外を握りつぶされる場合です。
try {
readFile("example.txt");
} catch (IOException e) {}
単に 「エラー」 とだけ出す処理も同罪ですが、このコードは例外を無視しているので処理が正常に続いてしまいます。これは意図しない重大な業務上の問題を引き起こすことがあり、かつデバッグも困難になる典型的なアンチパターンです。これは煩わしいからと例外を握りつぶすプログラマと見過ごすレビューアが悪いので、直接的に検査例外が悪い分けではありませんが、守れないルールは違反を誘引する傾向はあります。
以上のように、堅牢なアプリケーションを組むという理念に基づいた設計なんですが、実際の現場では 「扱いづらいのでは無い?」 と議論を呼んできました。その反動なのか、後発のScalaやKotlinといった言語は、JVM系でJavaとの相互運用を謳っていても検査例外は実装しない傾向にありますし、Optionalのような別の例外ハンドリング機構が利用される事も多いですしね。
システム例外と業務例外
プログラマが知るべき 97 のことにも 「技術的例外とビジネス例外を明確に区別する」 というものがありますが、システム例外 と 業務例外という考え方は一般的に良く利用されます。
システム例外とは例えば「DBに繋がらない」とか「必要なファイルが見つからない」とか「配列の要素外にアクセスしている」とかシステムの技術的な要素に絡んだ例外です。一方で、業務例外とは例えば「ポイント残高が足りない」とか「カタカナのみを入れる場所に漢字が入っている」とか、そうした業務プロセスに依存した例外です。
どちらも例外として考える事が出来ますが、これは分けて考えるべきです。それぞれの適切な処理は、アプリケーションの耐久性とユーザー体験を大きく向上させる事が出来ます。システム例外に対しては、ログ記録、アラート、システムの回復メカニズムを実装することが重要ですし、業務例外に対しては、具体的なエラーメッセージをユーザーに表示し、再入力や修正を促すことが効果的です。
一方で、業務例外は本質的に正常処理です。そのためtry-catchなどの例外処理機構で表現する事には議論もあります。よくある反対意見としては、例外でないものに例外を適用すると本当に異常が発生しているのか、そうでないのかの見分けが困難になります。また、try-catchは管理されたgoto文なので、大域脱出を伴いそれも認知負荷を上げる傾向にあります。こうした観点もあり、個人的には業務例外はtry-catchで扱うより、JavaであればOptional等を活用したり、Result型やValidation型といった独自クラスを戻り値にするのが扱いやすいです。
2種類の例外管理の仕組み - try-catchか戻り値(Optional/Result型)か
プログラミング言語における例外処理機構として、try-catch型と戻り値、特にOptional/Result型は一般的によく使用されます。これらの方法は例外を扱う哲学が異なり、それぞれにメリットとデメリットがあります。
Try-Catch 型
特徴:
- Try-catchは、例外が発生する可能性があるコードを
tryブロック内に記述し、例外が発生した場合にcatchブロックで捕捉して処理。 - 例外がスローされると、実行スタックは逆順にたどられ、適切な
catchブロックが見つかるまで実行は上位にthrowされる
メリット:
- 分離された例外処理: 通常のビジネスロジックと例外ハンドリングが物理的に分離されるため、コードが読みやすくなる。
- 例外処理のエスカレーション: catchせずにthrowする事で、共通の例外処理を上位層で記述できる。
デメリット:
- 例外処理のミスユース: 例外をプログラムの通常の制御フローとして使用されることがあるため、コードが理解しにくくなることがある。
- パフォーマンスコスト: 例外が生成されると、スタックトレースが記録されるなど、リソースを消費される。
- 例外の伝播: 例外は呼び出し元に自動的に伝播されるため、特に検査例外で意図せぬ複雑性を導入する。またモジュール境界を越えた意図しないフローになるケースがある
Optional/Result 型
特徴:
-
OptionalやResult型は、値が存在するかもしれないし、しないかもしれない、または操作が成功したか失敗したかを表す。 - これらは関数が特定の結果を返すことが保証されない場合、または例外を明示的に返す必要がある場合に使用される。
メリット:
-
明示的な例外ハンドリング: 呼び出し元は返された
OptionalやResultを検査して適切に対応する必要がある。これにより、例外が見過ごされるリスクを減らす。 - 関数型プログラミングのサポート: 例外を値として扱うことで、関数型プログラミングのパラダイムに適合し、不変性や純粋性を保ちやすくなる。
デメリット:
-
冗長性: すべての操作に対して
OptionalやResultをチェックする必要があり、コードが冗長になることがある。
JavaはTry-Catch型の例外処理の仕組みを持っていますが、Java8よりOptionalを導入しており戻り値型の例外処理を行う事も出来ます。最近の言語は戻り値型を好む傾向はあり、特にGo言語ではOptionalはありませんが、error型を原則的に多値として返すプラクティスが標準的に利用されおり、徹底した運用がされる傾向があります。
個人的な所感としては、戻り値型の方がミクロなレベルでのハンドリングはやりやすく、FWなどでの共通処理はtry-catch型の方が簡単です。このあたりは何を重視するかにも大きく左右される点でしょう。
例外的状態にのみ例外を使用する
例外の分類に関して述べましたが、少し異質なのが正常系なのに例外として扱う業務例外です。この考え方には議論の余地がある、と述べましたが 「例外的状態にのみ例外を使用する」 というのも以前よりベストプラクティスとして語られてきている話です。
try-catchはfor文などと同様に制御されたgoto文です。大域脱出という観点ではfor文より強力でgoto文に近いパワーを持っています。しかしながら、Effective Javaや達人プログラマーでも 「例外を制御フローに使うな」 という点が戒められています。
達人プログラマーでは具体的に以下のように述べています。
「例外とは予期せぬ事態に備えるためのものであり、プログラムの通常の流れの一部に組み込むべきでない」
「すべての例外ハンドラーを除去しても、このプログラムは動作することができるだろうか?」
-> ノーであれば、例外ではない状況下で例外が使われているはずです。
例えば典型的な例外を制御フローに利用しているコードは以下のようなケースです。
public static void main(String[] args) {
try {
voting("Taro", 17); // 投票年齢が足りない場合に例外をスロー
System.out.println("投票完了");
} catch (IneligibleToVoteException e) {
System.out.println("投票権がありません: " + e.getMessage());
}
}
public static void voting(String name, int age)) {
checkAgeForVoting(age); // 投票年齢が足りない場合に例外をスロー
// 実際の投票の処理
}
public static void checkAgeForVoting(int age) {
if (age < 18) {
throw new IneligibleToVoteException("投票年齢に達していません。");
}
System.out.println("投票可能です。");
}
class IneligibleToVoteException extends RuntimeException {
public IneligibleToVoteException(String message) {super(message);}
}
本来はif文や戻り値で表現するべき処理を自作した非検査例外のIneligibleToVoteExceptionで実現しています。votingメソッド自体は一見するとシンプルになっていますが、暗黙のモジュールへのインターフェースとしてIneligibleToVoteExceptionのハンドリングを強制することが入っているので、実はとても認知負荷が高いです。他にもJavaの例外処理はスタックトレースなどトラブルシューティングに有用な情報を出すため比較的重い処理なので、頻繁に行われる条件分岐に入っているとパフォーマンスを大きく阻害します。
このケースであれば以下のように、事前にチェックロジックを走らせる事でシンプルに書くことが出来ます。
public static void main(String[] args) {
if (!checkAgeForVoting(17)) {
System.out.println("投票権がありません: 投票年齢に達していません。");
} else {
voting("Taro", 17);
System.out.println("投票完了");
}
}
public static void voting(String name, int age) {
if (checkAgeForVoting(age)) {
System.out.println("投票可能です。");
// 実際の投票の処理
} else {
System.out.println("投票年齢に達していません。");
}
}
public static boolean checkAgeForVoting(int age) {
// メソッド名が不適切だけど、元コードに合わせるため
return age >= 18;
}
JavaであればOptionalを使うことでよりシンプルに表現できます。
public static void main(String[] args) {
Optional<String> result = voting("Taro", 17);
result.ifPresentOrElse(
System.out::println,
() -> System.out.println("投票権がありません: 投票年齢に達していません。")
);
}
public static Optional<String> voting(String name, int age) {
if (checkAgeForVoting(age)) {
System.out.println("投票可能です。");
// 実際の投票処理をここで実行すると仮定
return Optional.of("投票完了");
} else {
return Optional.empty();
}
}
public static boolean checkAgeForVoting(int age) {
// メソッド名が不適切だけど、元コードに合わせるため
return age >= 18;
}
また、異なる解決方法としてより適切なI/Fを設計をすることで、そもそも自然な形で状態を検査できるので、例外に頼る必要がなくなります。例えば、IteratorのhasNextは状態の事前チェックを自然な記述で表現出来ています。
List<String> fruits = Arrays.asList("Apple", "Banana", "Cherry", "Date");
Iterator<String> iterator = fruits.iterator();
while (iterator.hasNext()) {
var fruit = iterator.next();
System.out.println(fruit);
}
システム例外とは異なり業務例外も含めて、例外を制御フローに利用しようとするケースでは最上位まで貫通させたいニーズ自体が稀なので、goto文の亜種であるtry-catchよりも戻り値やI/F設計で解決できます。特にOptional等を利用することで、よりスッキリとした見通しの良いコードになります。
業務例外は設計も扱いも難しいので、可能であれば戻り値やOptional等を活用した処理として実装した方が良いでしょう。FW等で統一的に処理する必要があって初めて検討をするレベルだと思います。
例外ハンドリングの原則
例外は原則キャッチしない
色々課題がありながらも、try-catchはgoto文の亜種であり、モジュールの境界を無視した大域脱出という強力な機能を持っています。また、特に大域脱出と相性の悪い検査例外がJavaでは嫌われがちです。これは実際の業務アプリケーションにおいては、ほとんどの例外処理が横断的関心事であり、フレームワークやランタイムといった最上位に例外を貫通させ、共通処理を行う必要があるからです。
言い換えると、「例外はキャッチしない」 というのが原則です。
絶対に例外をキャッチするべきでは無い、という話ではありません。ただ、日々のビジネスロジックを書く中で、非検査例外に関する説明や、学校の授業などで習うサンプル問題からは想像しづらいので、あえてこの言葉を使います。実際の例を見てみましょう。
学校の授業等では、以下のような例外のサンプルを見たことがあると思います。
try (var in = new FileInputStream(new File("no-file"))) {
in.read(); // なんか必要なビジネスロジックを書く
}catch(FileNotFoundException ex){
System.out.println("ファイルが見つかりませんでした");
System.exit(-1);
}
実行結果は以下の通り。
ファイルが見つかりませんでした
これはtry-catch構文の説明としては良いと思いますが、実際の業務アプリケーションの開発/運用の現場では多くの問題があります。より実践に適したコードは以下です。
try (var in = new FileInputStream(new File("no-file"))) {
in.read(); // なんか必要なビジネスロジックを書く
}
シンプルにキャッチがありません。本当にこのコードで良いのでしょうか? 最初のコードの最大の問題はスタックトレースが出ないことです。修正版のコードの実行結果は以下の通りです。
Exception in thread "main" java.io.FileNotFoundException: no-file (No such file or directory)
at java.base/java.io.FileInputStream.open0(Native Method)
at java.base/java.io.FileInputStream.open(FileInputStream.java:213)
at java.base/java.io.FileInputStream.<init>(FileInputStream.java:152)
at example.MyTest.main(MyTest.java:19)
Javaのスタックトレースはとても雄弁なので、ただ例外をキャッチしないだけでFileNotFoundException(=ファイルが見つからない) という情報に加えて、 失敗したファイル名や何行目でエラーが発生したかも即座に確認できます。トラブルシュートの時にスタックトーレスがなく 「ファイルが見つかりません」 では原因の特定に多くの時間を割いてしまいます。言い換えると、最初のコードは必要な情報を隠蔽しています。この場合、まったく例外処理を記述せずにJavaランタイムのデフォルトの挙動(=スタックトレースを吐いて異常終了)にしてしまったほうがはるかに都合が良いのです。そのため、不用意に例外をキャッチしない事が例外設計の原則となります。
このような教科書との乖離は業務アプリケーションという限定的な視点だからです。コンシューマ向けのゲームやスマホアプリとは異なり、バッチやサーバサイドのエラーログはユーザでは無く、エンジニアが障害調査等のためにみるものです。そのため、「ファイルがありません」 という形でスタックトレース等のエラー情報を丸めるのは確かに不適切です。一方で、ゲームやスマホのアプリ等の場合は、障害調査のための情報をユーザに見せる必要はありませんし、java.io.FileNotFoundException: no-file (No such file or directory)等の謎の呪文では無く適切なエラーメッセージを返すべきでしょう。エラー情報は 「誰が」 見て、「何に」 使うのか、という点を意識するべきです。
例外処理で何をするのか?
前章では 「例外は原則キャッチせずにFWやランタイム層で処理する」 という話をしました。この理解を深めるために、例外処理で行う事を整理してみます。例外処理は大きく分けると、主に以下の4つです。
- 自動リカバリ
- リソースの解放
- Logging
- ユーザへの通知(エラー画面の表示, エラーメッセージの表示など)
まず、1の自動リカバリは例外発生時に自動で回復を試みます。例えば、DBの接続エラーは発生した際にリトライをする、などです。DBへの接続はNWやDBサーバのリソース状態等で一時的に接続する事が出来なくなるケースが想定されるので、リトライで復旧する可能性があります[2]。
次に、リソースの解放です。これはファイルやメモリを解放したりするclose処理です。一番イメージがしやすいのはDBのロールバックかもしれません。適切にリソースを解放する事で、他のシステムからそのリソースへのアクセスが出来なくなったり、中途半端な状態でデータが不整合になったり、パフォーマンス上の問題が発生するのを防ぎます。リソース解放としましたが中途半端なファイルやデータ等を消すクリーンアップ処理もこちら。特にバッチの場合は、単純にリラン出来るようにDBのロールバックに依存するか、常に上書きする冪等性のある処理にしときたいですね。そうするとクリーンアップ系の処理が簡単になります。
Loggingはそのままで、ログを取得する事ですが単にスタックトレースなどのエラー情報をそのまま記録する事もありますし、システムによっては調査がしやすいように関連情報をパッキングしてバイナリやzipファイルで出力するケースもあります。
最後に、Webアプリケーション等の場合はユーザにエラーの通知、つまりエラー画面を表示したり、エラーメッセージを出力したりします。エラーの内容や粒度はシステムのユーザがシステム担当者なのか、カスタマーのような外部の人間かでも異なってくるでしょう。
このうち、個々のビジネスロジックで実装する可能性が高いのは実は1の「自動リカバリ」と、2の「リソースの解放」だけです。3と4は通常はFWで実施するので、個別のビジネスロジックで対応するべきではありません。2の一部、例えばJTA + CMTを利用している場合はロールバックやリソース解放もFW側で実施されます。これは、そうした2-4の作業は横断的関心事であり、個別に実装してしまうと似たような処理が散らばってしまうため一貫性を損ない、複雑性を上げる事に繋がるからです。
1や一部の2をビジネスロジックに書くのは、リカバリの方法を共通化する事は困難ですし、リソース解放も対象のリソースに触れないといけないためです。ただし、自動リカバリできるケースが少ないですし、DB周りなどはFWが処理してくれることも多いので、個別のビジネスロジックで例外処理をするケースは少ないでしょう。
ありがちなアンチパターンは3のロギングを個別にやってしまうケースです。これは一部の監査ログやデバックのためのトレースログなどを除いて適切ではありませんし、エラーハンドリングの中で考えるロギングとは種類が違います。
という分けで、例外を原則キャッチしない、という意図は、業務アプリの場合は、FW層よりビジネスロジックを書くことが圧倒的に多く、かつ自動リカバリやリソース解放を明示的にするケースはそこまで頻発しないので、基本戦略としては 「例外は原則キャッチしない」 になるという事です。共通処理はFWやランタイムに共通のエラー処理としてハンドリングさせます。
例外が出たら速やかに殺す
例外処理で行う事の中で、実際のところ自動リカバリ、というのは極めて難易度の高い設計です。先ほど例に出した接続の自動リトライも、複数のクライアントからリトライする事でサーバの性能をダウンさせ、さらにはそれによって他のサーバの負荷が高まり、悪循環が始まるカスケード障害を引き起こす可能性があります。また、処理を継続させる場合、ファイルへの書き込みやメモリなどの状態が中途半端に残ってしまったり、誤った処理フローに入ってしまうなど、意図しない状態を引き起こす事もあります。
こうした業務処理の自律的な回復というのはリスクが高く、システムやドメインへの深い理解が必要です。そのため、基本的にはフェールセーフの考え方に則り、例外が発生したらバッチであればプロセスレベルで、Webアプリであればリクエストレベルで速やかに殺す というのが基本になります。もちろん、異常終了のプロセスに紐づいて、必要に応じてリソースの解放やエラー画面の表示などのユーザへの通知は行います。
一時的な問題であればユーザが再入力したタイミングで回復しているかもしれませんし、バッチの場合はオペレーターが再実行前にデータやリソースなどの状態を確認し、必要であれば手動で状態を正常化した後に再実行する事も出来ます。
透過的/自律的にそうしたチェックや回復を行えるようになるのがベストですが、バッチやWebアプリケーションといった業務アプリの場合は、例外が発生する原因のほとんどがバグ(データ不備/ロジック誤り/権限不一致)か、システムリソースの不足か、外部システム起因(関連ジョブの不備で入力データが無い、APIが死んでる)なので、自動リカバリは困難です。
もちろん、再起動で直る事もありますし、接続のリトライも慎重に設計すれば有効なので、原因と影響が十分に特定出来ている場合は、それも有用です。いずれにしても重要なのは業務プロセス、システムの運用プロセスを含めて適切な異常系処理を設計する必要なので、単なるソフトウェア設計以上にドメインへの理解が重要になる部分です。
余談ですが、流行りのマイクロサービスを適用する理由の一つに、連携先のシステムの機能が小さく分解されていれば、問題があってそのシステムを停止させても、サービス全体としては機能縮退(フェールソフト) で済む、というのもあります。こうしたアプローチも速やかに殺した後の影響を小さくする方法の一つです。
それでも例外をキャッチするとき
これまで、原則例外をキャッチしないと述べましたが、もちろん例外をキャッチするべきケースは存在します。そもそもFWやそれに近いレイヤーを書くならば、その中で例外ハンドリングを実装する必要がありますし、下記の1,2といった、自動リカバリやリソース解放の一部はビジネスロジックで書きます。
- 自動リカバリ
- リソースの解放
- Logging
- ユーザへの通知
本章では、個別にビジネスロジックの中で例外をキャッチするケースに関して、少し変則的な、しかしながら頻繁に発生するケースを紹介します。
検査例外を非検査例外に変換したい
恐らく最も現実的に多く、かつ賛否の多いケースです。検査例外を一度キャッチして非検査例外にラッピングすることで、上位のモジュールで明示的にキャッチをしなくても良いようにします。なお、これはJava特有のケースなので普遍的なケースである1-4にはあたりません。
検査例外が有用なケースもあると思いますが、個人的にはほとんどのケースで単に上位にエスカレーションするだけですし、Stream APIとも相性が悪いので、非検査例外にラッピングしています。
try (BufferedReader reader = Files.newBufferedReader(path)) {
reader.lines().forEach(System.out::println);
} catch (IOException e) {
throw new UncheckedIOException("Failed to read from the file: " + path, e);
}
UncheckedIOExceptionは公式で用意されているIOExceptionの非検査例外版です。これで呼び出し元などの上位のメソッドでは直接的に例外ハンドリングは不要で自動でFWなどの適切にキャッチする層までエスカレーションされます。
特にこだわりが無ければRuntimeExceptionでそのままラッピングしても良いですし、SpringのようにRuntimeExceptionを継承したDataAccessExceptionなど独自の例外クラスを作るのも分かりやすくなって良いです。
また、明示的なクリーンアップ処理が必要なモジュールである場合も、検査例外で対応するよりは、クラスにClosableを実装し、try-catch-resourcesで自動的にcloseするようなコードにして、ドキュメント化をしっかりしておくのが良いです。
例外情報をenrichしたい
例外情報をスタックトレース等含めてログに出す、というのは障害調査のために非常に重要な点です。ただし、デフォルトの例外には必要な情報が含まれておらず、FWで適切なログが出せないケースも考えられます。このような場合に、ログをビジネスロジック側で出しがちですが、いくつかの方法で例外の追加の情報を付与できます。3のケースの亜種として最終的なログはFW層で出すが、障害調査に必要な情報をビジネスロジックでキャッチして再スローします。
例えば、以下のコードはファイル名の一覧から拡張子を取得するサンプルです。
List<String> getExtensions(List<String> names){
var extentions = new ArrayList<String>();
for (var name : names) {
extentions.add(name.split("\\.")[1].toLowerCase());
}
return extentions;
}
// 実行
try {
var names = List.of("hoge.jpg", "foo.png", "bar");
getExtensions(names);
} catch (Exception ex) {
// FW層としてログを出力して異常終了
ex.printStackTrace();
System.exit(1);
}
実行結果は以下のようになります。
java.lang.ArrayIndexOutOfBoundsException: Index 1 out of bounds for length 1
at Sample.getExtensions(Sample.java:9)
at Sample.main(Sample.java:18)
at java.base/jdk.internal.reflect.DirectMethodHandleAccessor.invoke(DirectMethodHandleAccessor.java:103)
at java.base/java.lang.reflect.Method.invoke(Method.java:580)
at jdk.compiler/com.sun.tools.javac.launcher.Main.execute(Main.java:484)
at jdk.compiler/com.sun.tools.javac.launcher.Main.run(Main.java:208)
at jdk.compiler/com.sun.tools.javac.launcher.Main.main(Main.java:135)
これだけだと、一見すると何が問題か分かりません。スタックトレースを元にコードを追えばnamesが期待値と違う事は分かりますが、これがDBやファイルなどのコードの外から渡された値であれば、コードだけ読んでも状況の特定が困難です。
ビジネスロジックであるgetExtensionsの中であればnamesやnameの値を取得できるので、ここでログを出したくなりますが、前述のように例外に付与する形にgetExtentionsを修正します。
List<String> getExtensions(List<String> names){
var extentions = new ArrayList<String>();
for (var name : names) {
try {
extentions.add(name.split("\\.")[1].toLowerCase());
} catch (ArrayIndexOutOfBoundsException ex) {
throw new IllegalArgumentException("'" + name + "' is broken format.", ex);
}
}
return extentions;
}
実行すると以下のようなログになります。
java.lang.IllegalArgumentException: 'bar' is broken format.
at Sample.getExtensions(Sample.java:12)
at Sample.main(Sample.java:22)
at java.base/jdk.internal.reflect.DirectMethodHandleAccessor.invoke(DirectMethodHandleAccessor.java:103)
at java.base/java.lang.reflect.Method.invoke(Method.java:580)
at jdk.compiler/com.sun.tools.javac.launcher.Main.execute(Main.java:484)
at jdk.compiler/com.sun.tools.javac.launcher.Main.run(Main.java:208)
at jdk.compiler/com.sun.tools.javac.launcher.Main.main(Main.java:135)
Caused by: java.lang.ArrayIndexOutOfBoundsException: Index 1 out of bounds for length 1
at Sample.getExtensions(Sample.java:10)
... 6 more
nameの内容が付与出来ましたし、IllegalArgumentExceptionにすることで引数の誤りである事も明確にすることが出来ました。IllegalArgumentExceptionの代わりに単なるRuntimeExceptionを使っても、より分かりやすいようにカスタム例外を使ってもかまいません。
また、状況によっては元がSQLExceptionなどで例外に応じたハンドリングをしているため、RuntimeException等でラップしたくない事もあります。その場合は、JDK7から登場したaddSuppressedが使えます。
List<String> getExtensions(List<String> names){
var extentions = new ArrayList<String>();
for (var name : names) {
try {
extentions.add(name.split("\\.")[1].toLowerCase());
} catch (ArrayIndexOutOfBoundsException ex) {
ex.addSuppressed(new IllegalArgumentException("'" + name + "' is broken format.", ex));
throw ex;
}
}
return extentions;
}
実行結果は以下の通り。あくまでArrayIndexOutOfBoundsExceptionが発生していますが、その中にIllegalArgumentExceptionとビジネスロジックで埋め込んだメッセージが表示されてるのが分かります。
java.lang.ArrayIndexOutOfBoundsException: Index 1 out of bounds for length 1
at Sample.getExtensions(Sample.java:10)
at Sample.main(Sample.java:23)
at java.base/jdk.internal.reflect.DirectMethodHandleAccessor.invoke(DirectMethodHandleAccessor.java:103)
at java.base/java.lang.reflect.Method.invoke(Method.java:580)
at jdk.compiler/com.sun.tools.javac.launcher.Main.execute(Main.java:484)
at jdk.compiler/com.sun.tools.javac.launcher.Main.run(Main.java:208)
at jdk.compiler/com.sun.tools.javac.launcher.Main.main(Main.java:135)
Suppressed: java.lang.IllegalArgumentException: 'bar' is broken format.
at Sample.getExtensions(Sample.java:12)
... 6 more
Caused by: [CIRCULAR REFERENCE: java.lang.ArrayIndexOutOfBoundsException: Index 1 out of bounds for length 1]
IllegalArgumentExceptionやその他非検査例外に合わせてラッピングしたい意図が無い時は、addSuppressedを使うほうが上手くいくでしょう。
バッチ処理で特定行の問題は異常終了ではなくskipにしたい
基本的に例外が発生したら、リソース解放やロギングをしながら速やかに異常終了にするべきです。しかしながら、長時間実行されるバッチでは毎回何かあるたびに終了させると以下の問題も発生します。
- バッチの再実行に時間がかかり業務上のリミットに間に合わない(いわゆる突き抜け)
- 夜間にバッチが異常終了すると、リモートまたは現地に行って対応をしなくてはならない
こうした運用上の問題を起こさないために、問題があったレコードをスキップして、処理を続行させるケースがあります。
try (var br = Files.newBufferedReader(Path.of("data.csv"), StandardCharsets.UTF_8)) {
int procCount = 0;
int skipCount = 0;
for (var line = br.readLine(); line != null; line = br.readLine()) {
try {
parse(line);
procCount++;
} catch (CharacterCodingException ex) {
skipCount++;
System.out.println("WARN: Skip: line=" + line);
}
}
System.out.println("End Job, proc=" + procCount + ", skip=" + skipCount);
}
これは自動リカバリの特殊なケースと考えても良いかと思っています。ただし、行為だけみると例外の握りつぶしに近く注意深く行う必要がります。まず、大前提としてスキップしても翌日ないしは影響日にリカバリすれば業務的に問題ない、あるいは業務プロセスの中に不整合を許容する処理が必要です。また、ジョブを異常終了させないまでも、スキップしたことに気付けるようにWARN等でログを出し、監視システムと連携する事も必須です。最後にExceptionなど範囲の大きなエラーでキャッチしない事です。これをしてしまうと、思わぬ例外も取ってしまい、本来想定しているスキップして良いケースでは無いのに、スキップしてしまう事があります。このような事態を避けるために、CharacterCodingExceptionなど具体的な例外をキャッチする必要があります。
まとめ
例外処理は実際のアプリケーションを作るうえでは避けては通れない処理です。try-catch型にしろ、戻り値型にしろ、どこでハンドリングするのか? という点が重要になってきますし、それがロギング等の共通処理であれば、ビジネスロジックでは無くFW層でやるべきです。
業務アプリを書く場合は、FW層よりビジネスロジックを書くことが圧倒的に多く、かつ自動リカバリやリソース解放を明示的にするケースはそこまで頻発しないので、基本戦略としては 「例外は原則キャッチしない」 になるわけですね。
また、例外が発生したのに処理を継続する、というのはリスクが高いので、一部の状況を除いては速やかにプロセスないしはリクエストを異常終了させる事で、全体として業務影響の小さいシステムを組むことが出来ます。
併せて読みたい
Discussion
例外をできるだけ使わない、ということですが
boolean, Optionalで対応できなくなった場合はどうしてますか?
Pairを作ってenumと合わせて表現したり、sealed interfaceで分岐を表現したりしてるのか、この辺が気になりました。
例外を使ったほうがFWの対応などもあるので、自分は例外をうまく使いたい気持ちがあります。
私の書き方が少し伝わりにくかったかもですが、「例外を極力避けよう」という意図でも無いのです。
むしろ、最終的にエラー画面にメッセージだしたり、ログに出したりするだけのFWにお任せレベルは例外で良いと思います。例えば、たいていのシステムでRDBへの接続等の問題が本番で出るならなすすべが無くエラーにするしかないので、普通にSQLExceptionとして扱ってFWに処理させればよいと思います。
どちらかというと、FWにお任せでは無い個別の要件への対処、特にメソッドの呼出し元で何らかの処理を失敗時に強制させたい検査例外的な使い方は、Optionalとかの使うのが便利ってくらいですね。自分的に。あとは、そもそも通常の業務フローに例外があると、記事に書いたような課題があるので、そうした表現はOptionalを始めとして戻り値で表現したほうが良い、と。
実際に、Optionalで対応出来なくなるケースですが、例えば失敗の原因が複数あり、かつそれぞれの原因に合わせて振舞いを変える必要がある時ですかね? パッと、良いケースが出てこないですが、例えばvalidateメソッドを作って入力フォームの内容を検証して「文字数超過」とか「英数字以外が含まれている」とかを判別するケースだと、それを表現できるValidationクラスを作って、それを戻り値にしますね。まあ、この例のvalidateメソッドだと最終的なアクションがエラーメッセージの表示くらいだろうからエラーメッセージを格納出来るList<String>とかで十分な気もしますが。。。
今なら、そうしたケースならsealed interfaceでやるのも良い気がしますね。try-catchで複数の例外に対してのキャッチをたくさん書くより、パターンマッチの方が分岐処理である事が分かりやすく表現出来て良い気がします。