【ソフトウェア設計】モジュール、依存、そしてカプセル化
はじめに
前回に引き続き、ソフトウェア設計に関しての自分の考え方を整理していきたいと思います。今回は前回のモジュールの話の後続として、依存(=モジュール結合度)の話です。
モジュールの依存と種類
コードの複雑さをもたらすものの一つが、モジュールへの依存です。依存とはモジュールAとモジュールBの関係性のことです。あるモジュールのインタフェースに依存が多ければ多いほど、複雑性が高いと言えます。また、前回と同様にここでいうモジュールとは言語機能ではなく、関数/クラス/サービスなどの何等かの機能の塊です。様々な依存が考えられますが代表的なものは以下となります。
- 外部モジュールへの依存(メッセージ/データ結合)
- 構造体など入出力I/Fへの依存(スタンプ結合)
- グローバルな値への依存(共通結合)
- データフォーマットへの依存(外部結合)
- 実行順の依存
- トランザクション境界の依存
基本的には古典的な結合度のモデルと被る部分もあるかと思います。
外部モジュールへの依存 はシンプルに別なモジュールを呼び出している、という事ですね。呼び出し先であるモジュールAへの改修が呼び出し元であるモジュールBに影響を与えてしまいます。当然に発生する構造ですが、特にモジュールAが複数のモジュールから呼ばれる際に問題になりやすいです。理想的にはあらゆる依存が無いコードが望ましいですが、現実世界にそれはありえません。少なくとも標準ライブラリには依存しますし、低機能なモジュールを避けるためには一定の規模が必要なので、適度な別モジュールの呼び出しは必須となります。とはいえ、過剰に依存したり、不必要に依存することで余計な複雑性を招くこともあるので、常に妥当性を考えましょう。
構造体など入出力I/Fへの依存は例えば以下のようなコードです。
Record User(String name, int age){};
int countByUserName(User user){
var name = user.name();
// なんかnameで検索してカウントする処理
}
このUserというレコード型に依存しています。そのため、Userのnameが例えば仕様変更でfirstNameとlastNameに分かれた場合は、それを利用しているcountByUserNameも修正する必要があります。これはRecord型やClassに限らず同じです。これも本質的には避けられない依存で、仮にcountByUserNameの引数をString name, int ageとしたところで、特に変わりません。むしろ、単なるString nameでは影響範囲の特定が難しいのでUserで渡している方が良いことが多いでしょう。
グローバルな値への依存は名前通りの実装としてのグローバル変数というよりは、広い範囲に共通し変更を与えるパラメータへの依存です。Javaでいえばstatic変数やシングルトンはもちろん、巨大なインスタンスであればインスタンス変数も実質的にそうなりますし、他にもマスターテーブルの値や、設定ファイルの値もこの文脈においてはグローバル変数です。共通的に利用するパラメータを設定ファイルやマスタテーブルに格納し、シングルトン等を経由して参照することは変更箇所の増大を防ぐためにも必要なテクニックなのでダメではありません。ただ、これは前述の2つと比べても影響が見えづらくなる傾向があります。特にRead Onlyではなく、何かしらの変更をグローバル変数に動的に行える場合は、認知的負荷を著しく増大させます。それらの処理を行うときは慎重に、いえ、そもそも本当にグローバル変数を変更しなきゃダメなのか、を真剣に何度も考え直すべきです。
データフォーマットへの依存は、ファイルのフォーマットやDBのスキーマ、あるいは通信プロトコルなどへの依存です。例えば以下のようなCSVを書き込むコードを考えます。
write("hoge.csv", "AAA,BBB,CCC");
当然、読み込む側もこれをCSVだと期待して例えばカンマ区切りでスプリットとかするわけです。本来はエスケープ処理がいるけど、それはそれ。
var lines = read("hoge.csv").split(",");
では、これを書き込み側でTSVやJSONに変更したら? 当たり前ですが読み込み側の修正も必要です。このようにロジック上で直接の依存が付いていなくても、データフォーマットが変わればそれに紐づくコードの修正が必要です。これは何もPGの外側のデータとは限らなくて、インメモリで固定長データ等を持ってる場合も似たようなものです。この依存の厄介なところは不透明性が高く、本質的にドキュメントや暗黙知に頼るしか方法が無いので、この手の依存が散らばっていると著しく認知的負荷を上げてしまいます。フォーマットに対する構造体を作り、それに依存させるのは不透明性の緩和策としては非常に効果的ですが、フォーマット修正の影響を受ける、という点では変わりませんし、読み書きの部分は避けざる得ないですよね。
実行順の依存はモジュールAとモジュールBがあった時に、Bより先にモジュールAを呼んでおかなければいけない、というものですね。いわゆる先行処理。これの発生理由は様々ですが完全に避けるのは難しいでしょう。そして最悪なのが完全に不透明性の塊だ、という事です。フォーマットの依存ですらファイル名で引っ掛けるとか探しようがありますが、これは完全に無い。いくらかの回避テクニックも状況によっては無くは無いですが、基本的にはドキュメントや暗黙知に頼るしかありません。
トランザクション境界の依存 は実行順の依存の亜種となりますが、同一のトランザクション内で振る舞うモジュールです。関数等の粒度ではRDBなどミドル側とFW側で透過的に解決されるため依存として意識しなくて良いケースが多いと思いますが、マイクロサービスなどではグローバルトランザクションが無いので自前でロールバック相当の事をする必要があり注意しないといけないケースも多いでしょう。
カプセル化による依存の封じ込め
どのような依存があるかに関して、前章で列挙しましたが、依存を無くす事は不可能です。不必要な依存を無くすのは前提として、それでも残る排除しきれないのが依存。しかしながら、そうした依存とも上手に付き合う事は出来ます。そのための方法がカプセル化です。
カプセル化はオブジェクト指向で良く用いられる考え方でIT用語辞典によると以下のように定義されています。
カプセル化(encapsulation)とは、オブジェクト指向プログラミングにおいて、互いに関連するデータの集合とそれらに対する操作をオブジェクトとして一つの単位にまとめ、外部に対して必要な情報や手続きのみを提供すること。外から直に参照や操作をする必要のない内部の状態や構造は秘匿される。
オブジェクト指向の文脈なので、そこに限定されていますが本来的にこれはあらゆるモジュールに拡張できる概念です。関数レベルでもマイクロサービスレベルでも考え方は同じ。そして 「互いに関連するデータの集合とそれらに対する操作」 とは 依存です。
つまり、こう言い換える事が出来ます。
- 依存があるモジュールはなるべく近くに置け
- 依存の詳細を上位のモジュールで隠蔽して外部に出すな
例えば先ほどのデータフォーマットの話であれば同じ関数の中は難しいと思いますが、ReadメソッドとWriteメソッドを同じクラスの中に入れることは通常は問題はありません。その二つのメソッドで暗黙のフォーマットの依存を無くすことは出来ないですが、同じクラスという上位モジュールに封じ込めることが出来ます。これにより、依存同士が近いところにあるので、認知負荷が比較的低く、理解/保守しやすい状態を保てます。
これは関数でなくても同様です。メソッド単位の依存であれば同一のクラスに、クラス単位であれば同一のパッケージに、パッケージ単位であればバッチジョブやAPIといったアプリケーションレベルで、閉じ込めて隠蔽するのが肝心です。
ここで注意が必要なのはカプセル化による隠蔽とは単にprivate属性を与えて外部から直接アクセスを禁止することではありません。外部から存在を意識させないことです。setter/getterが付いた場合は言うまでもありませんが、インターフェースから意図せぬ詳細が見え隠れするような状態は適切にカプセル化が出来ているとは言えません。
またカプセル化された中のモジュール群は密結合でも構いません。テストのしやすさ等もあるので程度はありますが、基本的に一緒に使う事を前提としたモジュール群なのでその中を過度に抽象化したり分割すると複雑性が増したり、コード管理を含む運用性に課題が出てくるからです。もちろん、モジュールの粒度(関数、クラス、パッケージ、サービス、etc)で程度は変わってきますが大事なのは「常に疎結合じゃないとダメ!」という想いに捕らわれ過ぎない事です。
関心事の分離とビジネスロジックの独立
モジュールは関心事、すなわち役割の単位で分類すると理解がスムーズになります。たとえば以下の図は典型的な3層アーキテクチャの例です。もし各機能が単一の箱の中に混然と入っていれば、どこに何があるか分かりませんが、各レイヤーごとに機能を整理してやります。また、例えばプレゼンテーション層はユーザとの対話と隣接するビジネスロジックの実行に関心がありますが、例えば離れているDBの処理には興味がありません。

この構成ではそれぞれのレイヤーはモジュールは隣接する別のモジュールに依存を持ちます。ここで重要なルールが3つあります。一つは 「依存の循環を避ける」 という事で、2つ目は 「異なるレイヤーに異なる抽象を付ける」 、最後が 「抽象から具象に依存しない」 です。
「依存の循環を避ける」、つまり双方向に呼び合うモジュールを作るのは避けるべきです。これは意図せぬ振る舞いを発生させがちですし、なによりユニットテストが非常にやりづらいです。
また、APoSDでも言われていますが、異なるレイヤーには異なる抽象を付けます。言い換えると関心事が異なるということ。関心事が異なる抽象化をしていくことで、そのモジュールの複雑さを下げていけるのです。例えばファイルシステムというモジュールが上位レイヤーにブロックデバイスの生の振る舞いとかを漏らしていたら意味が無いですよね? 異なるレイヤーで関心事が一緒だったり、同一レイヤーのモジュールを呼ぶことは、通常は複雑性を減らすことには大きく寄与しません。認知負荷や変更箇所の局所性に繋がるので、無意味ではありませんが、Shallow Moduleとなり変更コストが増える事とのトレードオフになるでしょう。一方で、プレゼンテーションとビジネスロジック、ビジネスロジックとデータアクセスで引き渡すパラメータが同一、という事はしばしばあると思います。このようなケースでも異なるレイヤーで似たパラメータを扱う場合でも、「異なるレイヤーで異なる抽象」と考えることは妥当です。各レイヤーが持つ役割と関心は異なります。
- プレゼンテーション層では、ユーザー入力の受け取りと表示に焦点を当てます。
- ビジネスロジック層では、データに対するビジネスルールの適用と処理を行います。
- データアクセス層では、データの永続化とデータベースとのやり取りを管理します。
そのため、たとえ同じパラメータでもプレゼンテーション層ではValidationが、ビジネスじっくでは業務的な処理が..という風に使われて型も異なっているので、原則に反するものではありません。
最後に 「抽象から具象に依存しない」 ことです。ここでいう抽象とは実質的にビジネスロジックであり、具象はDBやUI、外部APIなどを指します。一般的にビジネスロジックはDBやUIとは独立して成立できます。例えば同じ機能を持ったシステムでも単純なWebアプリから、API化してAndroidやiOSのバックエンドになる事はありえますし、永続化レイヤーでるDBが別のものになるかもしれません。逆にビジネスロジックが変わればUIやDBは何等かの変更が入る事が多いです。そのため拡張しやすいコードは、ビジネスロジックからそうした具象への直接的な依存を作らないようにします。
「UI -> ビジネスロジック」は呼び出しの方向自体が「具象 -> 抽象」なので、特に気にする必要はないでしょう。一方でDBの場合は呼び出し方向は「ビジネスロジック -> DB」です。少し工夫が要ります。例えば「ビジネスロジック -> DAO -> DB」と依存を付ける事で、ビジネスロジックとDBへの実装が直接依存を持たないようにできます。ここに登場させたDAO(Data Access Object)はDBの実装を隠蔽しハイレベルなAPIを提供する抽象モジュールです。これによりビジネスロジックからDB実装への依存を無くすことが出来ました。単に、実装の詳細がDAOに移動しただけに見えますが、こうした実装に関する内容はなるべく下位モジュールに押やることで、上位モジュールのシンプルさが保てますし、本質的なロジックに集中出来るので保守しやすい構造となります。
実際のところ、この 「抽象から具象に依存しない」 というルールは 「異なるレイヤーには異なる抽象」 の派生ルールです。DBの操作はビジネスロジックとは明らかに違う関心事ですし、その場合は抽象化されたモジュールが生まれるはずです。
こうした、関心事の分離とビジネスロジックの独立の考え方をより洗練させたのが、Clean Architectureでも紹介されている4層のモデルです。
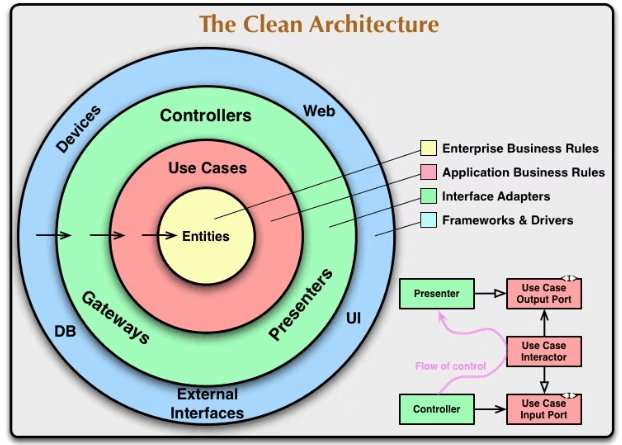
個人的には、このモデルをそのまま実装するのはやや過剰なケースが多い気もしますが、とても参考になる設計なので実際の本の記述やネットの解説記事を読むのも良いと思います。
まとめ
今回は、モジュールを作製するにあたり避けては通れない依存の話、そのリスクを低減させるためのカプセル化の話、そして関心事に関する話をしました。特別な事ではなく、ある程度自然にやってる部分では無いかと思いますが、言語化するとより意識が出来て設計時に注意しやすくなるかと思います。
次回は共通化の話か、シンプルなコードの話をしたいと思います。
それでは、Happy Hacking!
Discussion