この記事について
TL;DR
- AIが「思った通りに動かない」のは、単なるモデルの能力不足ではなく、 情報設計 の問題が大きい
- 情報を増やすだけでは逆効果になることもあり、 整理・最適化して渡す 「コンテキストエンジニアリング」が鍵 となる
- これはプロンプトの工夫を超えた “AIを「消費者」とみなす情報の物流設計” であり、AI活用の新しい必須スキルである
この記事の分量と内容
本記事は 約10分前後で読めるボリューム です。
博士🧑🔬と学生👩🎓の対話形式で、以下の 3つのテーマ を解説します。
(専門知識がなくても読めるように構成しています)
- なぜAIは「思った通りに動かない」のか
- 情報を増やすだけでは解決しない理由
- 情報の“物流設計”としてのコンテキストエンジニアリングの重要性
はじめに
ここ数年でAIは驚くほど賢くなりました[1] 。
しかし実際に使ってみると「思った通りに動いてくれない」と感じたことはないでしょうか?
その原因は単なるモデルの能力不足ではなく、 AIを「高性能な推論エンジン」として捉え、それに供給する情報をどう設計するか という視点が不足しているからかもしれません。
その解決策として注目されるのが 「コンテキストエンジニアリング」 です。
本記事ではこれを 「AIが最適に推論できるように、必要な情報を動的に収集・整理・管理し、体系的な“情報物流”として設計する技術」 と定義します[2]。
博士🧑🔬と学生👩🎓の対話を通じて、その考え方を解説します。
「なぜAIは思った通りに動かない?」
〜とあるラボにて〜
👩🎓 学生「博士、AIって全然思った通りに動かないんです。旅行プランを頼んだら、財布が厳しい私に高そうなプランばっかり紹介してきて…。」
🧑🔬 博士「なるほど。AIがポンコツなんじゃなくて、前提条件が足りなかったんだよ。『予算は?』『日程は?』『どんな旅行にしたいか?』って条件を伝えてなかっただろう?」
👩🎓 学生「ああ、そうか…。じゃあ次からちゃんと『予算は1万円以下、週末だけ、温泉が好き』みたいに全部書きます!」
🧑🔬 博士「そうそう、それを全部毎回書けば確かに伝わる。でも…面倒じゃないか?条件は1つじゃなくて何個もあるし、忘れたらまたズレた答えになる。」
👩🎓 学生「確かに…。毎回の入力で条件リストを全部書くのは大変ですね。」
🧑🔬 博士「だからこそ、人間が毎回細かく書くんじゃなく、システムとして情報を整理して渡す仕組みが必要なんだ。最近はそれを“コンテキストエンジニアリング”と呼んでいるんだよ。」
📖 解説
ポイント:プロンプト職人芸だけではなく、AIに情報を届けるための“情報設計”が必要!
学生の旅行プランの例で考えてみましょう。「思った通りに動かない」を解決するには、実はこんなにたくさんの要素が関わってきます。
- ユーザーの指示:「旅行プラン作って」
- 前提条件:予算、日程、好み(これが不足していた!)
- 利用可能な情報:観光地データベース、交通情報、宿泊情報
- 過去の会話:以前の旅行の話、予算感の会話
これら全体を「コンテキスト」と呼び、これらを人間がAIに手で渡すのではなく、システムが自動的かつ動的に構築・最適化する仕組みを設計することがコンテキストエンジニアリングです。
こんなに多いと、毎回手動で集めるのは大変ですね。
🔬 研究(参考)
近年の研究[3] でも、ユーザーが与える情報の不足が「思った通りに動かない」原因の大半だと指摘されています。従来の「プロンプトの工夫(プロンプトエンジニアリング)」から一歩進み、「背景情報をどう設計して渡すか」というコンテキストエンジニアリングの重要性が強調されています。
コンテキストエンジニアリングの世界はこれほど多岐にわたります。
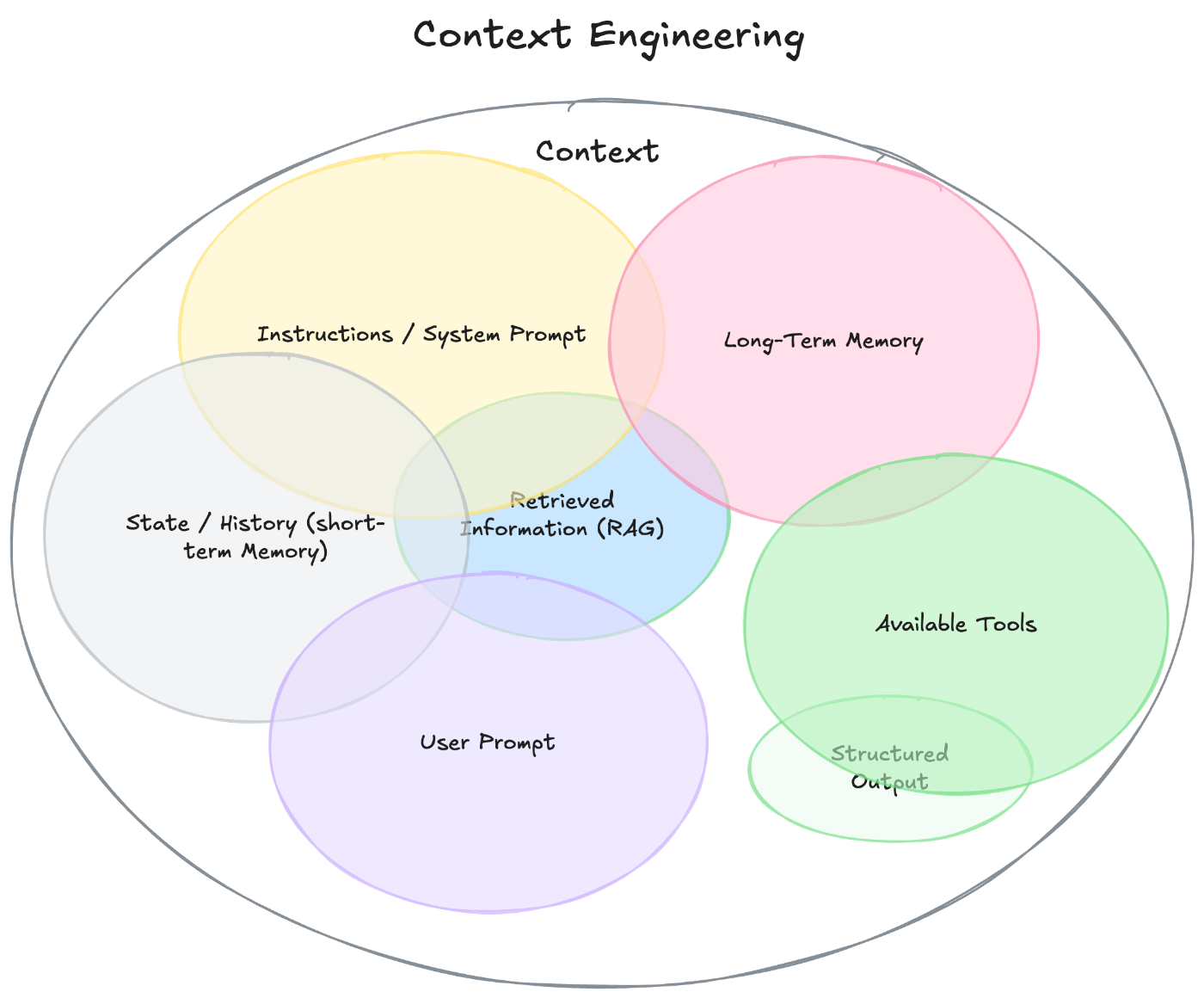
図: コンテキストエンジニアリングの全体像のイメージ図 。ざっと挙げるだけでも、、命令(システムプロンプトなど)、ユーザー入力(ユーザー指示)、ナレッジ(外部知識)、ツール(利用可能なAPIや関数)、記憶(会話履歴や長期メモリ)などがある。[4]
コンテキストエンジニアリングの考え方に基づく理論やフレームワークは、今もかなりのハイスピードで進化しています。[5]
「AIに渡す情報を増やせば解決する?」
👩🎓 学生「博士!じゃあAIが思った通りに動かないのは、単純に“情報が足りない”からなんですね?だったら、いっぱい情報を渡せば解決じゃないですか!」
🧑🔬 博士「惜しい!実はそれでもうまくいかないことがあるんだ。AIは、長い文章の真ん中あたりの情報をすっぽり忘れちゃうことがあるんだよ。」
👩🎓 学生「えっ、そんなことあるんですか?まるで会議の内容を冒頭と最後しか覚えてない私みたいですね。」
🧑🔬 博士「はは、それは人間なら普通のことさ。AI も同じでね。“lost-in-the-middle”[6] って呼ばれていてね。AIは先頭や最後の情報は拾いやすいけど、真ん中の重要な部分は抜け落ちやすい。」
👩🎓 学生「なるほど…。じゃあ大量に詰め込んでも、真ん中に大事な条件を置いたら無視されるかもしれないんですね。」
🧑🔬 博士「そういうこと。だから単に“足す”だけじゃダメで、どう整理するかが大事になってくるんだ。」
📖 解説
ポイント:情報を増やすだけでは逆効果、整理が必要!
大規模言語モデル(LLM)は入力の中央にある情報を見落としやすい傾向があることがわかっています。
これは渡すコンテキストの順序やノイズの量で性能が変わり得ることを意味しています。何も考えずに巨大コンテキストウィンドウに大量のテキストを流し込むと、「コンテキストを渡したのに無視される」現象が起こる可能性があるというわけです。
コンテキストを何も考えず一つのプロンプトに詰め込みすぎると、不整合や矛盾が起こる可能性もある。過去の古いデータと新しいデータで矛盾があったりすると、どちらを参照すれば良いか自明にはわからないことも起こります。
このように、ただ情報を詰め込むだけでは逆に性能を落としかねません。ただ、この問題への対処を人間が毎回手作業で調整するのは非現実的です。
だからこそ、次のテーマである「システムによる自動的な整理整頓」が不可欠になるのです。
🔬 研究(参考)
2023年の研究[7]では、LLMは入力の中央にある情報を見落としやすく、「U字型」の性能低下(lost-in-the-middle現象) を示すことが報告されました。2025年現在も様々な論文で”長文脈”の性能変化が研究されています[8] [9] 。

図: Lost-in-the-middleの"U字カーブ"。中央付近で性能低下が起こることがあることが示された一例 [10]
図:平均アテンション重み。
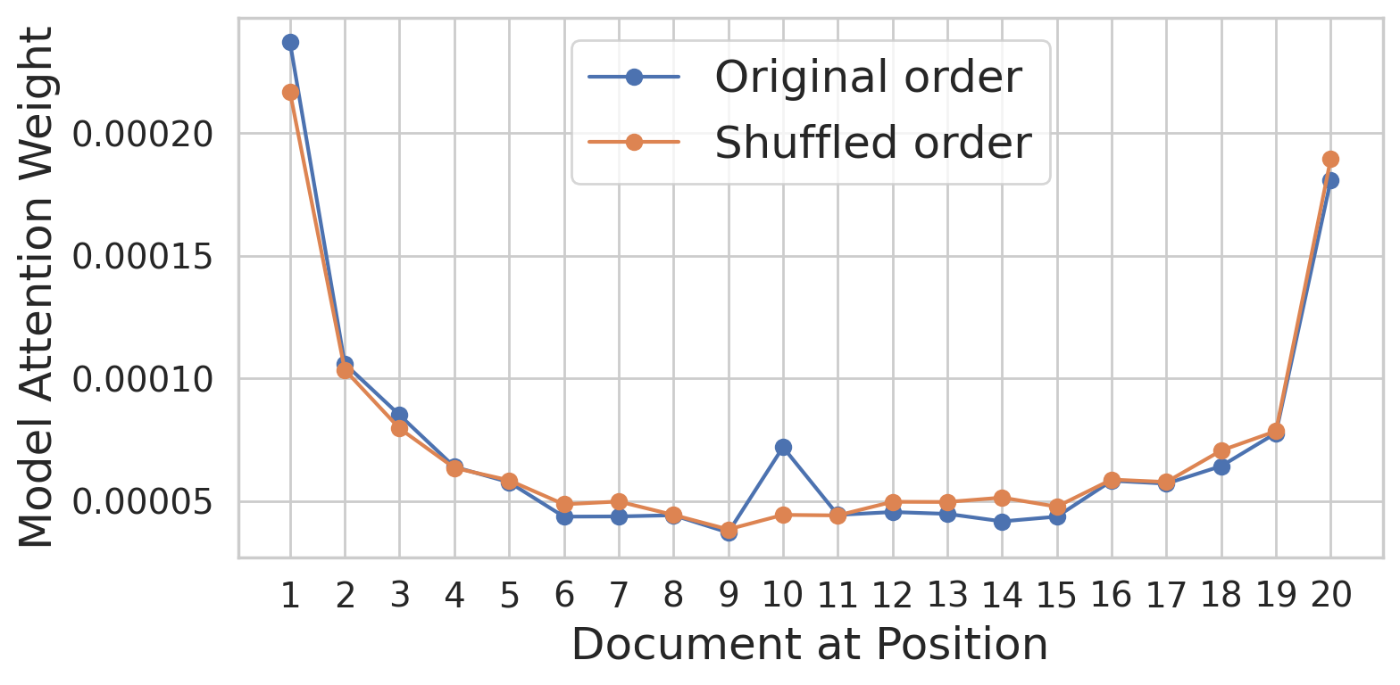
図:平均アテンション重み。位置によってアテンションの獲得の仕方が変わる”配置バイアス”があることが示された。[11]
「どうすればうまくAIを使える?」
👩🎓 学生「博士、ここまでで“情報が足りないとダメ”とか“多すぎてもダメ”とか聞きましたけど…結局どうすればAIをちゃんと使えるんですか?」
🧑🔬 博士「一言でいうと“整理整頓”だね。でも机の片付けじゃなくて、AIが受け取る情報の物流全体をどう設計するかという話なんだ。」
👩🎓 学生「物流?トラックや倉庫のあの物流ですか?」
🧑🔬 博士「そう。物流では“調達→輸送→加工→保管→流通→消費”のサイクルがあるだろう? 情報も同じで、AIにうまく働いてもらうには“AIの元に情報がどう集まり、どう運ばれ、どう整理され、AIにどう使われるか”を設計する必要があるんだ。」
👩🎓 学生「なるほど!だから“プロンプトを毎回工夫する職人芸”じゃなくて、“AIに届く情報の流れ全体を設計する物流”の視点が必要なんですね。」
🧑🔬 博士「その通り。AIは優秀なエンジンだけど、燃料(情報)の物流が滞れば本領を発揮できない。だから“情報の物流の設計”こそが、いま一番大事なんだ。」
👩🎓 学生「情報の物流を設計する…それが“コンテキストエンジニアリング”なんですね!」
📖 解説
ポイント:AIに届く情報の“物流”全体を設計せよ!
AIに正しく働いてもらうには、単に「情報を増やす」「要約する」といった部分的な工夫だけでは不十分です。
大事なのは、情報がどこから来て、どう運ばれ、どう整えられ、どう使われるか、というその物流全体を設計することです。
実際の物流が「調達→輸送→加工→保管→流通→消費」の流れで回っているように、情報も同じサイクルで考えることができます。
色んな情報をかき集め、最後、AIという”消費者”にコンテキストを届けるわけです。
大体こんなイメージ。
実際の物流だと最後に製品ができたりしますが、この”情報物流”では、最後にAIを”消費者”とみなして、AIに渡すための”コンテキスト”を作ることがゴールです。
例えば、「調達→輸送→加工→保管→流通→消費」のそれぞれのステップをAIシステムに当てはめると、ざっくりどんなイメージになりそうかを(筆者なりに)まとめます。
情報物流の6ステップ(全体像)
- 調達(必要な情報を集める)
- 輸送(必要な場所に届ける)
- 加工(整理・変換して使いやすくする)
- 保管(短期・長期の形で保持する)
- 流通(必要な場面で情報を流す)
- 消費(AIが推論に使う)
ただし、実際のAIシステムでは、それぞれが独立したコンポーネントになるのではなく、複雑に絡み合って構築されることになるはずです。
AIシステムにおける”情報物流”の具体的なイメージ(流し読み可)
ここでは、具体的なイメージというよりも、そのシステム全体が持つであろうその本質を抽象的な意味での”情報物流”に例えることで説明してみようと思います(気になる人向け)。
1. 調達
AIが必要とする情報を取ってくる要素です。人間の質問やフィードバックのような一時的な情報もありますし、永続化されたデータベース、ナレッジデータベースに対する検索や、Web検索など、情報収集をします。
2. 輸送
どういう通信で調達対象のデータを取ってくるかを扱う部分です。普通にDBアクセスやAPIアクセスもあるでしょうし、クローリングや同期などもここに当たりそうです。
3. 加工
「輸送」で得られた情報を整理したり、変換して使いやすくする仕組みです。検索インデクシングや、ナレッジグラフ、要約や構造化などがこれにあたるでしょう。
4. 保管
加工したデータを保存する仕組みです。検索インデクシングなどは加工+保管に対応するでしょう。ユーザーの会話を一時的保存したりするのもこの部分と捉えられます。
5. 流通
調達して得られた情報や、保管された情報を送り届ける仕組みです。実際には、データベース読み取りや検索実行、エージェントによるツール呼び出し(MCPなど)を通じて行われます。ここでAIに渡すコンテキストのオブジェクトが生み出されるイメージです。
6. 消費
ようやくAIにコンテキストが渡り、推論を行い、出力を作ったり、意思決定をしたりすることになります。
このように、コンテキストとして組み立てるまでの情報を物流の比喩で考えると、「最適化問題」に帰着して捉えられますね。
もはや人間の工夫による静的な情報提供では不十分で、これらのような動的な情報アーキテクチャを「設計」する視点が不可欠であることが大事となります。
🔬 研究(参考)
Mei et al. (2025) とこの記事の関連性
Mei et al. (2025) のサーベイでは、1400以上の研究を整理し、コンテキストエンジニアリングの体系化が行われています。
主に「取得(Retrieval)」「処理(Processing)」「管理(Management)」に焦点が当てられています。
しかし物流で比喩をしてみると、それ以外の 「輸送」「流通」「消費」 といった工程も含めて、より包括的に整理できるのでこの記事ではそちらの説明を軸にしました。
まとめ
本記事では、博士と学生の対話を通じて 「AIが思った通りに動かないのはなぜか?」 を追いかけました。いかがでしたか?
- 情報が不足していれば、AIは適切に動けない。
- しかし情報を増やすだけでは逆効果になることもある。
- だからこそ、情報の流れ=物流全体をどう設計するか が重要になる。
この視点こそが コンテキストエンジニアリング です。
プロンプトを工夫する“職人芸”から、システム全体を見渡した“情報設計”へ。これが今、AI活用に求められている転換点だといえるでしょう。
さいごに
いいね・シェアお願いします!
Xやってます。
#kw_blog_sprint をつけてシェアいただけると嬉しいです!
KNOWLEDGE WORK Blog Sprint 、明日9/7の発表者は hassi です。お楽しみに!
参考文献
[Context Engineering: Survey and Perspectives](https://arxiv.org/abs/2507.13334) (Mei et al., 2025)
1400以上の研究を体系的に整理し、コンテキストエンジニアリングを「取得・生成」「処理」「管理」の3つの要素に分類。RAGやマルチエージェントなどの実装パターンを包括的にまとめた最新のサーベイ論文[12]。
[The New Skill in AI is Not Prompting, It's Context Engineering](https://www.philschmid.de/context-engineering) (Philipp Schmid)
プロンプトエンジニアリングからコンテキストエンジニアリングへのパラダイムシフトを解説。実践的な例を通じて、なぜ「プロンプトの工夫」だけでは限界があるのかを説明。
[The Rise of Context Engineering](https://blog.langchain.com/the-rise-of-context-engineering/) (LangChain Team)
LangChainの開発経験から見たコンテキストエンジニアリングの重要性と、実際のシステム構築における具体的なアプローチを紹介。
論文やブログ
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics, 12, 157–173. arXiv
- Hsieh, C.-Y. et al. (2024). Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization. arXiv preprint. arXiv
- Mei, L., Yao, J., Ge, Y., et al. (2025). A Survey of Context Engineering for Large Language Models. arXiv
- Philipp Schmid, The New Skill in AI is Not Prompting, It's Context Engineering Blog
- LangChain Team, The Rise of Context Engineering Blog
-
一応、貼っておきます https://chatgpt.com/ ↩︎
-
より厳密に定義すると、コンテキストエンジニアリング (Context Engineering) とは、AIが正しく働けるように、AI自身が最適な情報を動的に集め、処理し、管理するための環境や仕組みを体系的に設計する技術です。AIのための「高度な情報供給システム」を構築する工学とも言えます。 ↩︎
-
A Survey of Context Engineering for Large Language Models(arXiv) ↩︎
-
The New Skill in AI is Not Prompting, It's Context Engineering ↩︎
-
A Survey of Context Engineering for Large Language Models(arXiv) ↩︎
-
Lost in the Middle: How Language Models Use Long Contexts(arXiv) ↩︎
-
Lost in the Middle: How Language Models Use Long Contexts(arXiv) ↩︎
-
マルチターンで信頼性が大きく低下する「lost in conversation」を報告(平均-39pt)。長文文脈活用の難しさと隣接領域。 arXiv ↩︎
-
“開始/終端にアテンションが溜まり中間が落ちる”アテンション地形を同定し、AttnRankで並べ替えによる緩和を提案。 arXiv ↩︎
-
(a) Lost-in-the-middle とは、入力内で関連コンテキスト (クエリの回答を含むゴールド ドキュメントなど) の位置が変化するため、モデルの U 字型の RAG パフォーマンスが変化することを意味します。(b) モデルは、実際の内容に関係なく、先頭および末尾のコンテキストを優先する U 字型の注意重みを示すことがわかります。(c) モデルは、中間に配置されていても関連コンテキストに注意を払いますが、最終的には先頭/末尾のコンテキストに気を取られてしまいます。(d) U 字型の注意バイアスの影響を分離し、モデルが位置に関係なく関連コンテキストに注意を払うことができる、中間にあるというキャリブレーション メカニズムを提案します。 ↩︎
-
モデルにU字型の配置バイアスがあることを示している。先頭と末尾の文書は、順序に関わらず、より大きなアテンションを獲得する(ゴールド文書は元々10番目に位置していた)。アテンションは、異なるデコーダー層とアテンションヘッド間で平均化される。 ↩︎
-
対象とする問題:制約(最大コンテキスト長など)の下で、期待される出力品質を最大化するような関数集合(Retrieve, Select, Assemble…)を見つける」こと。
→ これは情報理論的(相互情報量最大化)、ベイズ的(コンテキスト事後分布推定)、決定理論的(期待報酬最大化)な枠組みで表現される。 ↩︎

Discussion