はじめに
※本記事は、KNOWLEDGE WORK Blog Sprint 第 18 日目の記事です。
ナレッジワークのソフトウェアエンジニア yamaryoxxxx です。今回は AWS Step Functions のワークフローについて、数年にわたる本番運用で培った実践的なノウハウを共有します。
本記事の対象読者
- Step Functions の基本概念を理解している方
- CDK または Terraform での IaC 経験がある方
- Lambda 関数、ECS タスクの開発経験がある方
- 中級〜上級レベルの AWS サービス利用経験をお持ちの方
- Step Functions の実践運用をしている方
用語の整理
本記事では Step Functions の公式用語に準拠し、以下の用語を使い分けます:
- ワークフロー: 業務プロセス全体の流れ(汎用的な意味)
- ステートマシン (StateMachine): AWS Step Functions で定義されるワークフロー定義
- 実行 (Execution): ステートマシンの 1 回の実行インスタンス
- ステート (State): ステートマシン内の個々の処理ステップ
背景
Step Functions に出会ったのは約 7 年前。AWS のフルマネージド/サーバーレス志向の私は、その軽快な動作、履歴の追いやすさ、スケーラビリティに強く惹かれました。
一方で、Step Functions は実装の自由度が高く、複雑なワークフローを実際のサービスで活用するには多くの設計判断が求められます。
直近 4 年間、以下のような環境で本番運用を続けてきました:
- 用途: Web 会議の録画 → 音声認識 → 要約生成の AI ワークフロー
- 実行時間: 10 分〜数時間
- 負荷: 常に大量のステートマシン実行が並行稼働
- 変更頻度: 月に数回のワークフロー更新、年に 1 回程度大規模なリファクタリングが発生
- 処理コンポーネント: Lambda 関数(軽量処理)と ECS タスク(重量処理)の組み合わせ
何度かのリファクタリングを経て、ワークフローのコードは少しずつ保守しやすい形へと整ってきました。以下では、Tips 形式で現時点の取り組みをご紹介します。
Tip 1: インフラ定義は CDK で
AWS Step Functions のステートマシン定義には AWS CDK が適しており、保守性と生産性の両面で有用です。
例えば、次のような簡単なワークフローを考えます。処理を実行して結果を出力しますが、既に出力済みの場合はスキップするというものです。
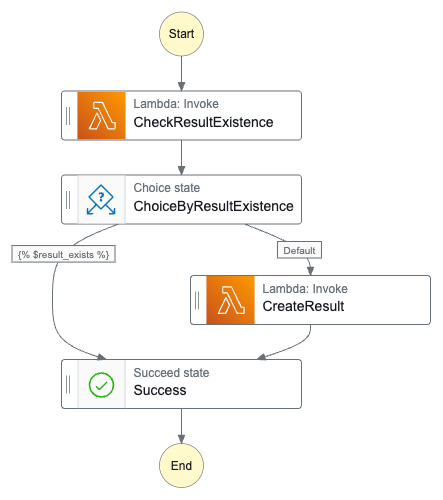
これを CDK で記述する場合、次のようなコードになります。
# 各ステートを定義
check_result_existence = tasks.LambdaInvoke.jsonata(
self,
"CheckResultExistence",
lambdaFunction=check_result_existence_function, # 定義済みとします
assign={
"result_exists": "{% $states.result.Payload.result_exists %}"
}
)
choice_by_result_existence = sfn.Choice.jsonata(
self,
"ChoiceByResultExistence"
)
when_result_exists = sfn.Choice.jsonata(
"{% $result_exists == true }"
)
create_result = tasks.LambdaInvoke.jsonata(
self,
"CreateResult",
lambdaFunction=create_result_function # 定義済みとします
)
success = sfn.Succeed(self, "Success")
# ステートマシンを定義
definition = check_result_existence
check_result_existence.next(choice_by_result_existence)
choice_by_result_existence
.when(when_result_exists, create_result)
.otherwise(success)
create_result.next(success)
sfn.StateMachine(
self,
"StateMachine",
state_machine_name="DemoStateMachine",
definition=definition
)
このように CDK でステートマシンを定義すると、次のような保守性面のメリットがあります。
- 各ステートを個別に定義し、それを組み合わせる形でワークフローを定義できるため、ワークフローの構成がコードからわかりやすい
- ステートマシンの部品化と再利用が容易になる
- ステートマシンからの Lambda 関数や ECS タスクの呼び出しに関する IAM 権限の付与が自動的に行われるため、コードが非常にシンプルになる
- デプロイ前の型チェックが可能になる
Tip 2: インフラコードとアプリコードを同じレポジトリに
多数の Lambda 関数や ECS タスクの実行を含む複雑なワークフローを作成する場合、Lambda 関数や ECS タスクとステートマシンでデータのやりとりが多く発生します。ステートマシンの複数の Variable を Lambda 関数の入力として渡し、その出力の一部を別の Variable に assign するといったことがよくあります。
複雑なワークフローを保守する上では、ワークフロー側と処理側(Lambda 関数や ECS タスク)の I/O 管理が重要です。ワークフロー定義(CDK)と処理側(例えば Docker コンテナ内のアプリケーション)のコードは、当然ながら別ディレクトリに置かれますが、両者は同期して更新する必要があります。
そこで、インフラコードとアプリコードは同一の Git レポジトリにまとめ、変更は 1 本の PR に集約しています。私たちは次のようなディレクトリ構成で両者を同居させており、チームはインフラとアプリの双方を継続的にメンテナンスする体制にしています。
project-root/
├── deploy/ # CDKインフラコード
└── apps/
├── workflow_lambda_function/ # 細かい処理を行う多用途Lambda 関数のコード(Tip 3で後述)
├── speech_recognizer/ # 音声認識のECS タスクのコード
├── speech_diarizer/ # 発話者分離のECS タスクのコード
└── acoustic_feature_extractor/ # 音響特徴抽出のECS タスクのコード
Tip 3: 多用途 Lambda 関数を使う
複雑なワークフローを保守する場合、Lambda 関数の数が多くなります。例えば私たちのワークフローでは、音声認識や要約生成などの重めの処理はECS タスクで行い、それ以外の細かい処理はLambda 関数を利用しています。具体的には以下のような処理をLambda 関数で行っており、処理の数は50個以上あります。
- ステートマシン入力データのバリデーション
- 各種 ECS への入力データの整形、出力データの整形
- Feature Flag の管理
- メディアデータの正規化、変換処理
- 各種ファイルの存在確認
- ジョブの状態管理(DB 更新など)
- サービス品質管理のためのメトリクス送信
- エラー時の障害通知
私たちは、処理ごとに別々の Lambda 関数を作るのではなく、1 つの多用途 Lambda 関数を用意し、入力ペイロードに応じて処理を分岐させています。例えば同じ Lambda 関数に、
{
"action": "check_file_existence",
"params": {
"s3_uri": "s3://some-bucket/some/result.json"
}
}
という入力ペイロードを与えた場合は、"check_file_existence" アクションで対象ファイルの存在確認を行い、
{
"action": "put_cloudwatch_metrics",
"params": {
"metric_name": "speech_recognition_processing_time",
"value": 127.3
}
}
という入力ペイロードを与えた場合は、"put_cloudwatch_metrics" アクションで処理時間を CloudWatch のメトリクスとして記録します。Lambda 関数側の実装は、action に応じて分岐して処理するだけです。
このように多用途Lambda 関数を使うメリットには以下のようなものがあります。
- ワークフローのリファクタリングにおけるコード修正量が小さくなる
- Lambda 関数はデプロイ直後の起動オーバーヘッドが非常に大きいが、関数を共有することでその影響を小さくできる
- Lambda 関数のバージョン利用(Tip 4にて後述)と併用することで、デプロイ時に既に実行中のジョブがエラーになる問題を回避できる
最後のポイントは少し複雑ですが、Lambda 関数を処理ごとに分割している場合、リファクタリングに伴って不要になった関数を削除してデプロイすると、デプロイ前から実行中のワークフローが削除済みの関数を呼び出してエラーになる恐れがあります。多用途 Lambda 関数は削除対象になりにくいため、この問題を避けやすくなります。詳細は Tip 4 で説明します。
Tip 4: Lambda 関数はバージョン固定で呼び出す
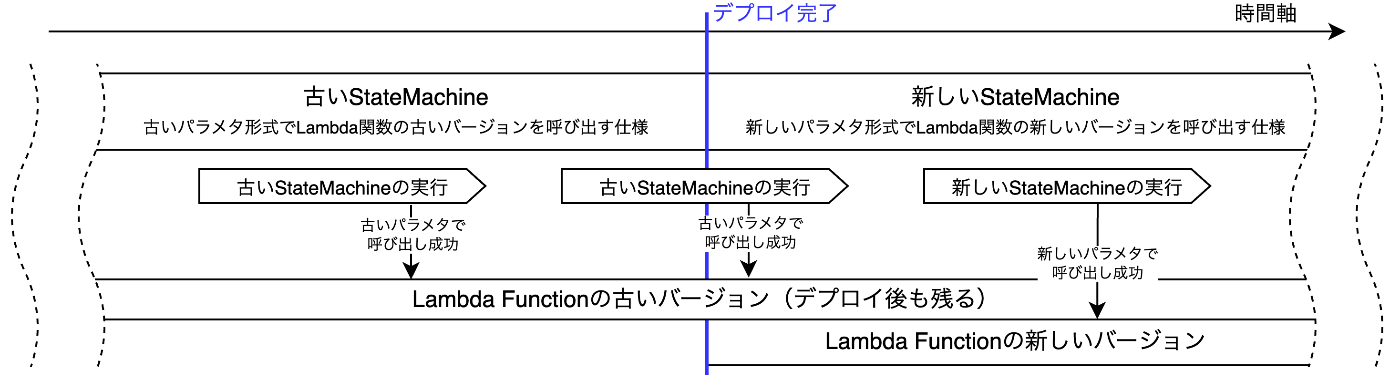
Step Functions のワークフローが実行中の環境下で、ステートマシンと Lambda 関数(もしくは ECS タスク)の入出力を変更する修正をデプロイする際は、特に慎重さが求められます。デプロイが完了しても、デプロイ前に開始された実行は旧定義のまま動き続けるため、下図のように呼び出しパラメータ形式の不一致が発生し、エラーに至る可能性があるからです。

この問題を避けるためには、Lambda 関数のバージョンを固定してステートマシンに組み込むのが有効です。例えば先ほどの例をバージョン固定で呼び出すと、次のようになります。
check_result_existence = tasks.LambdaInvoke.jsonata(
self,
"CheckResultExistence",
lambdaFunction=check_result_existence_function.current_version, # バージョンを指定
assign={
"result_exists": "{% $states.result.Payload.result_exists %}"
}
)
このようにバージョンを固定すると、古い実行はデプロイ後も残る過去バージョンの Lambda 関数を旧パラメータ形式で呼び出すため、エラーは発生しません。これにより、実行中のワークフローが多数存在する環境でも、リファクタリングを安全にデプロイできます。
あわせて、以下の点にも留意が必要です。
- Lambda 関数のデプロイ時に、古いバージョンを残す設定が必要です
- AWS Lambda のコードストレージ上限があるため、古い Lambda 関数のバージョンは定期的に削除する必要があります
- 上記のように定義した場合、CDK の Step Functions モジュールは、ステートマシンの IAM ロールに指定されたバージョンの Lambda 関数の実行権限しか付与しません。古いバージョンの Lambda 関数も呼び出す必要があるので、実際にはステートマシンの IAM ロールに、該当 Lambda 関数の任意のバージョンの実行権限を付与する必要があります
Tip 5: Variables と JSONata を使う
2024 年 11 月に、Step Functions に Variables と JSONata という 2 つの便利な機能が追加されました。これらを活用することで、ワークフロー設計は大幅にシンプルになります。
Variables は、処理の出力値を変数に格納し、後続の任意ステップから参照して利用できる機能です。
従来は、前ステートの output を次ステートの input に渡す設計が前提で、ワークフロー全体が“データのバケツリレー”になりがちでした。例えば冒頭の Lambda の出力値を最後の Lambda で利用する場合、間にあるすべてのステートでその値を明示的に引き継ぐ必要があり、各ステップの入出力設計に常時配慮が求められました。
Variables によって出力値を変数に保持し、後から参照できるようになったため、この“バケツリレー”は実質的に不要になりました。Variables の登場で Step Functions の設計アプローチは大きく変わり、私たちの運用でも output を使う機会はほとんどなくなりました。
JSONata は JSON のクエリ言語で、算術演算・文字列操作・配列処理などの簡易ロジックを組み込めます。Step Functions の定義で使えるようになったことで、軽微なデータ加工はステートマシン側で完結可能になりました。従来の JSONPath ではできなかったため、例えば現在時刻の取得でも Lambda 関数を別途用意して呼び出す必要がありましたが、JSONata によりこの手間を省けます。
例えば、ECS タスクを実行し、その処理時間を CloudWatch メトリクスに送信するワークフローは、Variables と JSONata を組み合わせることで、次のようにシンプルに定義できます。

start_timer = sfn.Pass.jsonata(
self,
"StartTimer",
assign={
"timer_start_at": "{% $millis() %}", # JSONataで現在時刻を取得してVariableに格納
},
)
do_process = tasks.EcsRunTask.jsonata(
self,
"DoProcess",
task_definition=do_process_task_definition,
...
)
put_metrics = tasks.LambdaInvoke.jsonata(
self,
"PutMetrics",
lambda_function=workflow_lambda_function.current_version,
payload=sfn.TaskInput.fromObject({
"action": "put_cloudwatch_metrics",
"params": {
"metric_name": "process_time",
"metric_value": "{% $millis() - $timer_start_at %}", # VariableとJSONataで処理時間を計算してLambda 関数に渡す
}
}),
)
definition = start_timer
start_timer.next(do_process)
do_process.next(put_metrics)
sfn.StateMachine(
self,
"StateMachine",
state_machine_name="DemoStateMachine",
definition=definition
)
このように Variables と JSONata を活用すると、ワークフロー設計が大幅に簡潔になり、保守性も高まります。
Tip 6: State Machine Fragment を使う
複数のワークフローで共通処理を扱う場合の定番は、共通処理を 1 つのステートマシンに切り出し、他ワークフローから呼び出す方法、すなわち階層化です。
私たちも以前はこの方法をとっていたのですが、実際に頻繁にワークフローに機能追加が入る条件下では多少難がありました。
例えばメインワークフローからサーブワークフローを呼び出し、そこからさらにECSタスクを呼び出すようなケースで、機能追加のためにECSタスクに渡すパラメタを増やしたい、というちょっとした修正を行う場合にも以下のような修正が必要で、修正箇所が大きくなっていました。
- メインStateMachineがサブStateMachineを呼び出す箇所で渡すパラメタの修正
- サブStateMachineの入力パラメタをバリデートするLambda関数の修正
- サブStateMachineがECSタスクを呼び出す箇所で渡すパラメタの修正
またサブワークフローを用いると、Tip 4と同様のバージョン問題があるため、StateMachineについてもバージョン管理が必要になり複雑さが上がります。ワークフローをフラットに書けばこのような問題はなくなりますが、一方で共通処理を再利用することができなくなります。
そこで CDK の State Machine Fragment を用いると、ワークフローを部分定義として切り出し、簡単に再利用できるようになります。例えば Tip 5 の例を Fragment 化すると、以下のようになります。
class DoSomeProcessFragment(sfn.StateMachineFragment):
def __init__(self, scope, id):
super().__init__(scope, id)
start_timer = sfn.Pass.jsonata(
self,
"StartTimer",
assign={
"timer_start_ms": "{% $millis() %}",
},
)
do_process = tasks.EcsRunTask.jsonata(
self,
"DoProcess",
task_definition=do_process_task_definition,
...
)
put_metrics = tasks.LambdaInvoke.jsonata(
self,
"PutMetrics",
lambda_function=workflow_lambda.current_version,
payload=sfn.TaskInput.fromObject({
"action": "put_cloudwatch_metrics",
}),
)
definition = start_timer
start_timer.next(do_process)
do_process.next(put_metrics)
self._start_state = start_timer
self._end_states = put_metrics.end_states
@property
def start_state(self) -> sfn.State:
return self._start_state
@property
def end_states(self) -> List[sfn.INextable]:
return self._end_states
このように StateMachineFragment として定義すると、そのフラグメントを他のワークフローに埋め込むことができるようになります。
do_some_process = DoSomeProcessFragment(self, "DoSomeProcess")
do_this_process = DoThisProcessFragment(self, "DoThisProcess")
do_that_process = DoThatProcessFragment(self, "DoThatProcess")
do_some_process.next(do_this_process)
do_this_process.next(do_that_process)
sfn.StateMachine(
self,
"StateMachine",
state_machine_name="DemoStateMachine",
definition=do_some_process
)
注意点としては、State Machine Fragment はあくまでも CDK のモジュールであり、AWS 上にデプロイされるリソースではありません。また、Fragment 自体に変数のローカルスコープ化などの機能は全くない点にも注意が必要です。上記の例だと、DoSomeProcessFragment の中で定義した変数は、DoThisProcessFragment や DoThatProcessFragment から参照・更新が可能で、Fragment の利用にあたってはそのことを踏まえて設計する必要があります。
State Machine Fragment でフラットに構成してシンプルさと修正容易性を取るか、サブワークフローで責務をカプセル化して見通しと変更影響の局所性を高めるかは、状況に応じて判断が必要です。
Tip 7: 「1 要素 Parallel」を使う
Step Functions は AWS マネジメントコンソールから実行の詳細を追いやすいのがメリットの 1 つですが、複雑なワークフローを組むと、コンソール上での表示が非常に長くなり、視認性が落ちます。例えば電話音声を書き起こして要約するという比較的単純なワークフローでも、下図のようにステートが多いため、全体像を把握しにくくなります(画像は粗めにしています)。
この見づらさを解消するため、私たちはワークフローをブロック単位に分割し、それぞれを「ブランチが 1 つの Parallel ステート」で囲っています。これは Parallel ステート本来の用途ではありませんが、コンソール表示でグループ化・折りたたみが効くため、全体構造を把握しやすくなり、必要に応じてブロック単位で展開表示に切り替えられます。(ブロック名称はダミーの名前に置き換えています)

また Parallel ステートで囲むことで変数スコープが区切られ、内部にローカルな Variable を定義できます。これにより、ワークフローの変数スコープを汚さずに局所的な変数を利用でき、保守性が高められるメリットもあります。
おわりに
本記事では、公式ドキュメントにあまり記載のない事項や、賛否が分かれうる設計方針も含め、実運用の中で磨いてきたノウハウをまとめました。Step Functions は本番環境での大規模な AI ワークフローにも十分に耐える強力なサービスであり、Variables や JSONata の登場により、使いやすさと保守性は大きく向上しています。最適な設計はワークフローの複雑性・実行頻度・更新頻度などの条件によって異なりますが、本記事の内容が設計検討や改善のヒントになれば幸いです。
KNOWLEDGE WORK Blog Sprint、明日9/19の執筆者は redsloop さんです。 お楽しみに!

Discussion