株式会社ナレッジワーク SRE の tapih(@_tapih) です。
本記事では、 SLO (=Service Level Objective) の PDCA サイクルを各チームが自律的に回せる (=セルフサービス化) ようにするために、運用基盤を整備した事例をご紹介します。
本記事で得られる点は以下の通りです。
- Terraform Module を活用した Datadog SLO 実装の事例を学ぶこと
- SLO のセルフサービス化を推進するために必要な体制づくりの事例を知ること
- Platform Engineering 的な観点での施策の推進の事例を知ること
背景
2024年後半から2025年前半にかけて組織が成長し、チーム数・システムコンポーネント数が着実に増加しました。この変化によって、SRE チームが各プロダクトの詳細な仕様や運用特性に全て目を配ることがいよいよ不可能になり、 SLO のセルフサービス化の機運が高まりました。
SLO は Datadog SLO 機能を利用し、 SLO を設定する毎に必要なリソースを Terraform で実装しています。
まず、 PdM が各プロダクトのコアとなる体験に対して CUJ を設定し、それと対になる SLO をエンジニアが設計・実装します。各チームには "Product SRE" を任命し、各チームの SRE 活動の旗振りを担ってもらっています。
当時、 SLO 周りで発生していた問題は次の通りです。
- SLO 定義に必要な Terraform リソースが意外に多く実装コストが高い
- Product SRE が実装を完結できない
- SRE (以降、区別のために Platform SRE とします) のサポートコストが高い
- SLO の定義揺れや定義ミスが発生
- SLO の改善のフローが整備されていない
- 一度作った SLO がしばらくの見直されない
- チーム再編により、自チームで持っている SLO を把握していないメンバーが増加
- リアーキテクチャ時にデプロイされた、様々なサーバが依存する Intenal なサーバに対する SLO が設定されず漏れていた
特に、各チームで自走する体制が整っていなかったために、各チームで Ownership を持ち切れていないことが問題でした。 SRE & プロダクトエンジニアの双方の意に反して、どうしても SRE を頼らないと SLO に関するアクションを取りづらい状況でした。
このような状況の最中、実際に SLO が頻繁に違反する問題が発生し、 SLO の一連の仕組みを見直すことへの意識が全社的に高まりました。
施策
大きく以下の 3 点を行いました。
- Terraform Module の実装による標準化
- SLO Review フォーマットの策定
- SLO を理解するためのラーニングコース (弊社提供プロダクトの一機能を社内利用) の提供
Terraform Module の実装による標準化
以下の Terraform Module を実装しました。
-
1 CUJ に複数 SLO が紐づく
-
1 SLO 毎に 1 Moduled Resource を作成
-
SLO は Metric Based
-
以下を Module 内に実装・実装詳細は Module の README を自動生成して記載
- Multi-Window の Burn Rate Alert (Fast Burn & Slow Burn)
- Error Budget 枯渇時のアラート (Error Budget Exhaustion)
- 週末・夜間を計測除外する Correction
- アラートを受け取った後の対応手順の概要と詳細へのリンク
- 多数の SLO をうまくフィルタするためのタグ (
env/service/team/slietc.)
-
SLO Reiview 会 (後述) を円滑に進めるためにリンクを追加
- (ユーザが明に指定する) そのエンドポイントを使っている代表的なフロントエンドへのリンク
- (ユーザは明に指定しない) そのエンドポイントの Latency の代表的なパーセンタイル値 (例: P50/P99) のグラフへのリンク
module "awesome_backend" {
source = "./path/to/slo_kit"
for_each = {
for i, v in [
{
cuj = "〇〇詳細を素早く取得する"
run = "awesome-backend"
endpoint = {
path = "/AwesomeService/GetXXX"
method = "GET"
}
latency = {
enabled = true
threshold_ms = 2000
success_rate = 99
}
availability = {
enabled = false
}
page_url = "https://our.service.com/home"
},
# ここに追加する
] : "${v.endpoint.method} ${v.endpoint.path}" => v
}
env = var.env
run = each.value.run
location = var.location
endpoint = each.value.endpoint
owner = local.owner
slack_channels = ["notify-${local.owner}-${var.env}"]
page_url = each.value.page_url
cuj = each.value.cuj
latency = each.value.latency
availability = each.value.availability
}

SLO 一覧画面

SLO 詳細画面
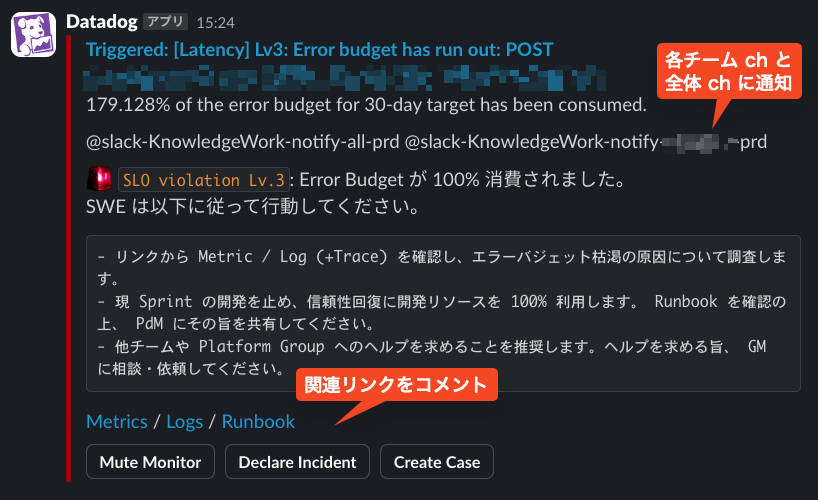
アラート通知の例
以上により、 Availability と Latency といった標準的な SLO に関しては、社内のベストプラクティスに沿った SLO を非常に低コストで実装できるようになりました。実際に、各 Product SRE が Coding Agent を駆使して SLO の追加を自発的に行ってくれています。将来的にはレビューも各チーム側に移譲していこうと思っていますが、現時点でも Platform SRE はレビューするだけで実装が完結する状態になっています。
Module を使って SLO を広く社内展開していく際には、 SLO アラートの発火状況を見てアラートがノイズになっていないかを確認しながら進めました。 Datadog のアラートの発火は Event として Datadog 上に蓄積されます。アラート発火の Event をチームやコンポーネント単位で可視化することで、各チームの SLO の状況を定期的に観測しました。
SLO Review フォーマットの策定
SLO 違反がない場合でも SLO を定期的に見直すため、各チームで最低でも四半期に 1 回 SLO Review 会を開催することとしました。
- 毎 Q の最終月月初頃に GitHub Actions で GitHub Issue を自動作成
- 各チーム Product SRE は PdM 及びエンジニアを MTG に招待
- MTG 開催時は GitHub Issue に記載された進行手順をベースに Review を実施
会の進行は各チームの Product SRE が行います。各チームが自律的に Review 会を運営できるようにするために SLO Review のテンプレートを Google Docs で作成しました。

SLO Review テンプレート
テンプレートは大きく以下のセクションから構成されています。 Product SRE はこのセクションに沿って会を進行します。
- 違反した SLO
- 違反しそうな SLO
- 保守的すぎる SLO
- 新しい SLO
- Next Actions (1~2 程度、多くても 3 つ)
SLO Review テンプレートの責務は、同期的なレビューのガイドラインのみで、変更履歴の管理は目的外です。 SLO の変更履歴は SLO の Terraform コードにタグを打って GitHub のリリースノートで管理 (必要に応じてノート内から背景等を説明するドキュメントをリンク) する構想を個人的には考えています。現状でもある程度履歴をトラックできているためあまり深くは考えてはおらず、明確に必要になったタイミングで対応しようと思います。
また、各チームの SLO Review 会の実施状況を外から把握しやすくするため、以下 2 点を GitHub Issue のチェックリストに追加しています。
- SLO Review 会のスケジュールを Google Calendar の "SRE イベントカレンダー" に登録
- 会が終わったら Doc と会の録画を特定の Google Drive に格納
SLO を理解するためのラーニングコースの提供
SRE の専門的な書籍は比較的充実してきた一方で、エンジニアの初学者や非エンジニアが迅速に SLO の概念を理解するための資料は決定的なものがない認識です。 SLO の重要な概念に絞ってミニマルに学習用の資料を用意し、ラーニングコースを作成しました。
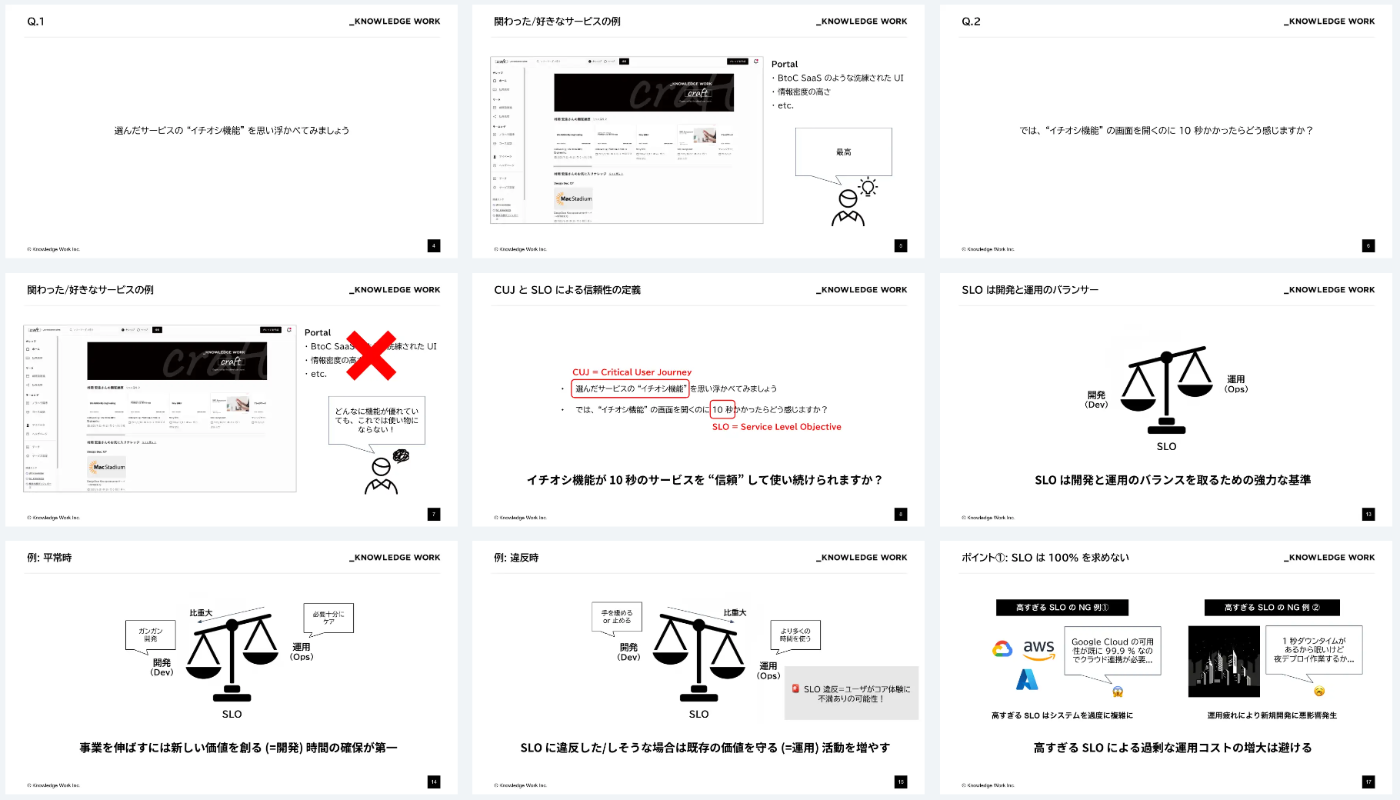
学習用資料の一部
ラーニングコースとは、弊社のプロダクトの機能の一つです。 Google Slide 等で作った複数のナレッジをグループ化し、ナレッジの理解度を測るためのクイズを提供することができます。学習者はラーニングコースをベースに学習をしつつ、わからない点や深堀りしたい点は SRE や ChatGPT に質問したり、巻末の SRE 本へのリンクから発展的な内容を学習することができます。
ラーニングコースのゴールは、先述の Terraform Module を使えるようになることとしました。例えば、先述の Multi-window の Burn Rate アラートは各チームの観点では (内容を理解しておくにはもちろん越したことはないものの) アラートが適切に上がってくれさえすれば OK です。こういった内容はラーニングコースには含まずに、 Module 内に隠蔽して README.md にその旨を記載、各自気になったタイミングで参照できるようにしています。
まとめと今後の展望
以上の施策により、各チームが自発的に SLO の議論を行い、 SRE の手をほぼ介さずに実装まで完了することができています。
これはすなわち SLO の運用に対する Ownership が SRE -> Engineer に移ってきたことを表しています。今後はこの Ownership を、 PdM まで移していきたいと考えています。現時点でも PdM が SLO に対する Ownership を発揮しているものの、例えば SLO を使った意思決定フローを自ら設計したり、もっと SRE に対して要望を push してくれる状態まで Ownership を高めていくことが理想と考えています。
なお、 SLO の運用を始めるときに頭を悩ませるトピックとして SLO 違反時に本当に開発を止めるのか があると思います。この問いに対する答えは教科書的には Yes ですが、実際の現場はそこまで単純ではありません。違反したら必ず止めることをいきなり原理主義的に強要せず、まずは議論を通してチームで目線を揃えることと意思決定者たる PdM の意識を高めることが先決と考えています。最近では、インシデントの判定基準に CUJ を使う議論が PdM 側で進んでいたりと、いい兆しが見えています。一旦は PdM サイドに自由に動いてもらいつつフィードバックを収集して Next Step につなげていく、というのが足元の動きになっています。
その他、よりよい SLO as a Service を提供していくために課題は山積みですが、必要なタイミングを見極めて仕組みを進化させていきたいと考えています。
- Internal Service の SLO 運用方法の確立
- "このエンドポイントが X 秒になったらどういう体験になるか" をシミュレートする Fault Injection 基盤の構築
- 定期的なチーム別 SLO レポートの提供
KNOWLEDGE WORK Blog Sprint、明日 9/13 の執筆者は QA エンジニアの guncha です。

Discussion