導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
本記事では、大規模な従来のデータベース(SQLなど)を使ったRAGの手法である「Middleware for LLMs」について簡潔に解説していきます。
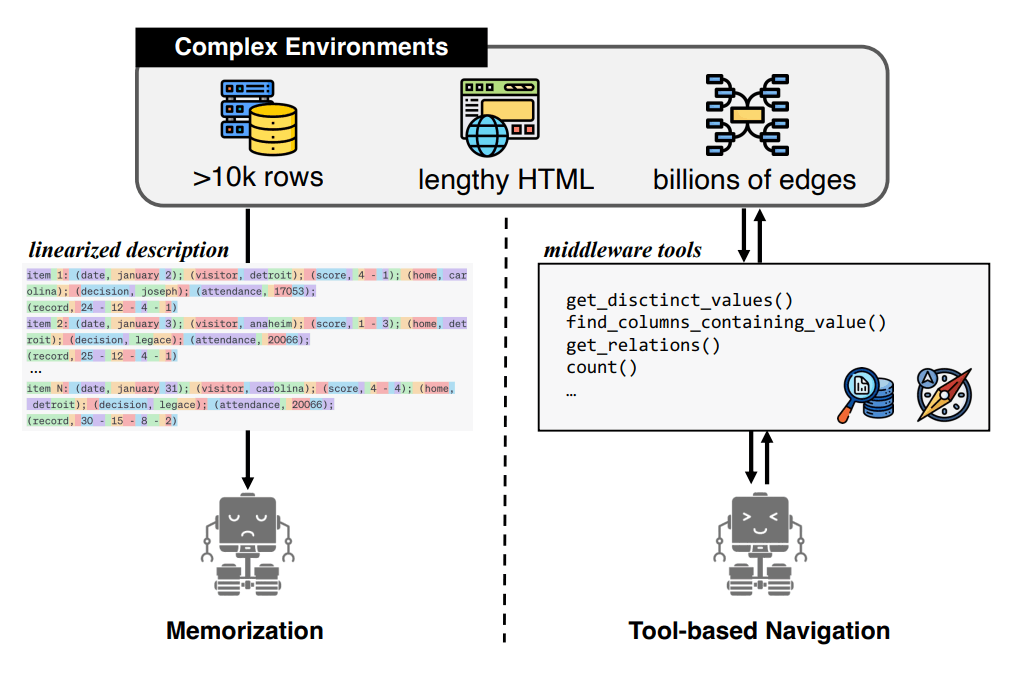
以前にも、データベースとLLMを利用して、適切なクエリを発行するための手順を解説しています。
気になる方は、そちらも参照してみてください。
より詳しい手法や、実際に使用したプロンプトのテンプレートは以下を参照してください。
サマリー
Middleware for LLMsは従来のSQLデータベースや、知識グラフデータベースを対象に、適切な検索を行い回答精度のの向上をはかっています。従来のデータベースを利用したRAGと比較して、LLMの指示の出しやすい形にクエリを抽象化することでより検索精度が向上しています。
問題意識
大規模なRAGの回答精度
RAGは、独自の情報をLLMに回答させる方法として注目を受けています。その一方で、参照データが莫大になったり、構造化されたデータの取得があまり得意ではありません。そのため、RAGは参照するデータの候補が増えるごとにその精度を落とすことになります。
構造化したデータを参照する方法として、LLMにSQLクエリを生成させる手法などが提案されていますが、データソースが大規模化するにつれて、時間と正確性の観点でパフォーマンスが低下します。
手法
この問題に対して、Middleware for LLMsは以下の二つの方法で、データソースからのデータ検索の精度を上げようとしています。
- 検索クエリの抽象化
- ReActの使用
クエリを直接生成する手法とは異なり、シンプルな関数を予め定義しておきLLMにはそれを利用して回答してもらうようにしています。そして、ReActを使用することで、シンプルな関数による操作を繰り返し、複雑性の高い質問に対する回答の精度を向上させている点が特徴的です。
ChatGPTのプロンプトでの利用
ChatGPT内でもAssistant APIからBrowserを操作するために、簡易的な関数を用いて操作を抽象化し、利用しやすいようにしています。
(https://gist.github.com/alexandreteles/8aa56ec416b7fe2fc1ee0a687995925a#file-chatgpt-4-txt より抜粋)
The `browser` tool has the following commands:
`search(query: str, recency_days: int)` Issues a query to a search engine and displays
the results.
`mclick(ids: list[str])`. Retrieves the contents of the webpages with provided IDs
(indices). You should ALWAYS SELECT AT LEAST 3 and at most 10 pages. Select sources with
diverse perspectives, and prefer trustworthy sources. Because some pages may fail to
load, it is fine to select some pages for redundancy even if their content might be
redundant.
`open_url(url: str)` Opens the given URL and displays it.
回答までの手順
Middleware for LLMsをReActに組み込んだ手法をFUXIと論文では命名しています。このFUXIは以下のような手順で回答を作成しています。
- データベースに合わせて、利用可能なツールと質問文を入力し、次に考えといけないこと(Thought)とその考えに対する回答を得るための方法(Action)を出力します。
- Actionを元に、得られた結果(Observation)を含めたプロンプトをLLMに渡します。
- ここまでの情報を元に回答が可能な場合は回答を、それができない場合は1に戻り再度ツールを使用。
以上のステップを繰り返していくことで回答に辿り着くことを目指します。
以下に論文内での例を掲載します。

質問に対して、LLMが必要な情報を集めている様子が伺えるかと思います。
また、FUXIはToolの実行の手法として以下の二つのどちらかを使用しています。
- error feedback
提示したツールをそのままLLMに利用してもらうための手法です。正しい結果が得られなかったり、使用方法に誤りがある場合のフィードバックを以下のように行っています。

- decoupled generation
提示したツールをそのまま使用するのではなく、いくつかの候補を提示してその中からLLMに操作を選択してもらう方法です。LLM判断はより限定的なものとなっています。

結果の中ではそれぞれの手法ごとの精度が掲載されるので、その点にも注意して見てみてください。
ツールの例
以下のようなツールを十数個提示しています。
確認してみるとわかるのですが、想像以上に細かい粒度で動作を指定させているように見えます。
from(from_statement)
This function specifies the FROM clause, e.g.,
from("FROM table1") or from("FROM table1 JOIN table2
ON table1.id = table2.id")
Prerequisite: n/a
結果
BIRD'sという評価手法のうち、文章中に回答が含まれていないタスクに限定して検証した結果になっています。w/ Oracle Knowledgeとw/o Oracle Knowledgeとがありますが、Oracle Knowledgeとはタスクの回答に役立つ情報源を指しているようなので、基本的に比較はw/o Oracle Knowledgeで行っています。
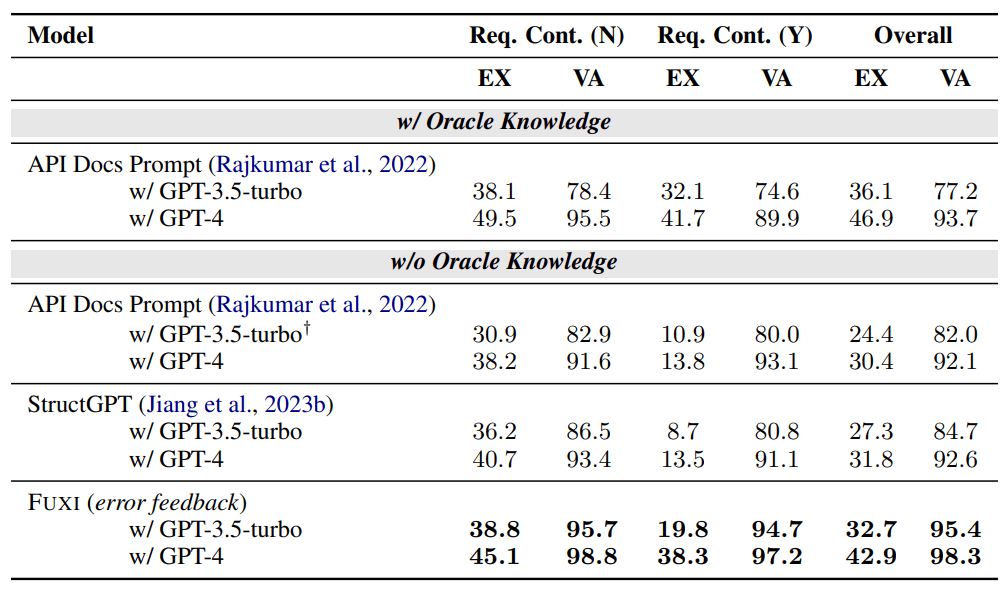
API Docs Promptはこの評価手法を提唱した方が提案した手法のようです。FUXIは既存の手法と比較しても高い水準を維持しています。
つづいて、知識グラフを対象とした評価手法であるKBQA-AGENTでの検証結果は以下のようになります。
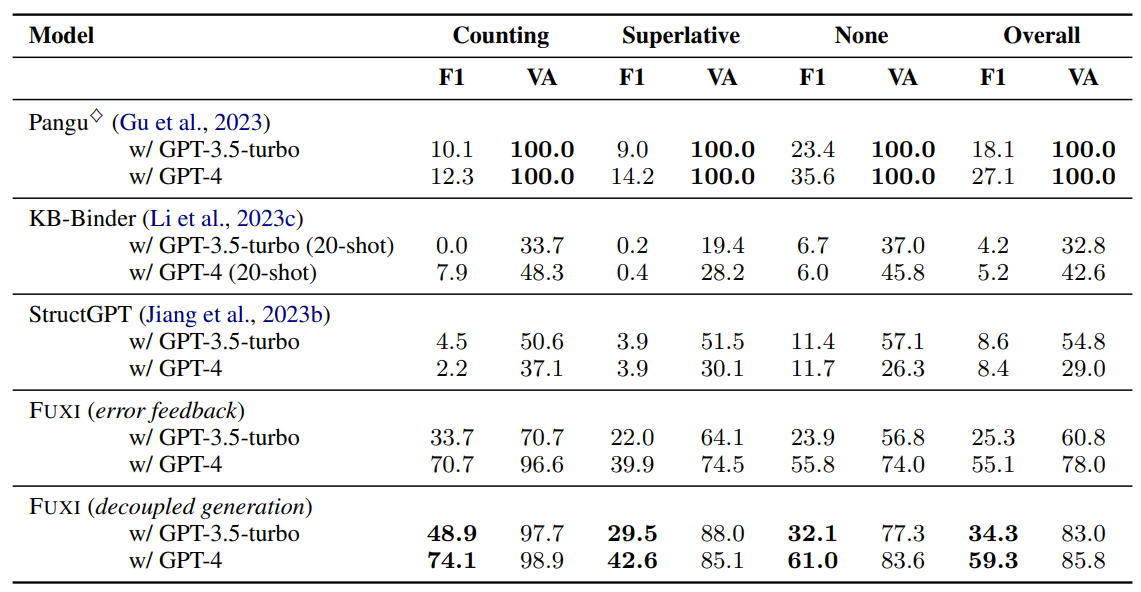
F1とVAという評価基準がありますが、基本的にF1で比較すると良いかと思います。
こちらの比較でも軒並みFUXIの精度が高く見えます。また、2つの手法のうち次の操作の候補を渡す手法(decoupled generation)でより高い精度を実現しています。
考察
二種類のデータベース検索を利用した精度の検証でこれまでの方法と比べて、高い性能を示しました。複雑なタスクにおいては既存の手法と比較して高い精度を実現しています。
これはタスクに応じて、適切な粒度のツールを提供することで精度の向上が実現できるという良い例になっているかと思います。
精度が向上した反面、ReActという手法の特性や一度の入出力で行えることの少なさを考えると、費用や時間の面で劣後する部分があるのでは無いかと考えています。
また、提案された2つの手法のうち、操作の候補を提案するほうが精度が高いことから、行動の生成よりも選択のほうが得意で選択肢を狭めることの重要性を示していると考えられます。
まとめ
Middleware for LLMsの考え方は非常に非常に汎用的で、LLMにとって利用しやすいインターフェースを整えることで、さらにLLMそのものの活躍の場面が増えるかもしれません。
特に個人的に重要だと思うのはツールの粒度で、複雑なタスクであれば少し細か目にインターフェースを作ることが精度向上の鍵となりそうです。
その一方で、ReActを使った手法は時間とお金がかかることが何よりも欠点かと思います。プロンプトの入力と出力を繰り返すため、それが完了するまで結果が得られません。なので現時点ではチャットに組み込むなどの利用方法は難しい面があるのではないかと考えています。
精度が一定の水準で非常に高速なLLMが登場するとこうした技術もより積極的に採用できるようになるので、今後そうした方向での成長も期待したいです。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion