導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
本記事では、Pinterest社のエンジニアチームが紹介していた、実運用環境におけるText-to-SQLの構築方法に関する記事の紹介をします。
Text-to-SQLを実際の運用レベルで実現するための手法が解説されているので、その内容を解説、そして考察していきたいと思います。
なおこの手法には特に名前などは設定されていなかったので、以降Pinterest社の提案するText-to-SQLをPinterest Text-to-SQLと呼称します。
サマリー
Pinterest Text-to-SQLは、RAGのシステムを最適化することで
- 検索に必要なTableのより正確な抽出
- 実際に使用されている値に準拠した検索パラメータ設定の実現
- SQLの作成にかかる時間を35%削減
といった成果を上げており、データベースでText-to-SQLする際にかなり有益な手法となっています。
この記事について
この記事では、Pinterest Text-to-SQLの仕組みの解説といくつかの考察をしていきたいと思います。元の記事は以下から参照可能です。
Pinterest Text-to-SQLの特徴は、全般を通して実際のサービス運用で用いられるような大規模なデータベースにおける実践的なText-to-SQLの運用、という点に尽きると思います。
様々な論文でText-to-SQLの手法に関する提案とその成果は語られますが、実際にそれをサービスに組み込もうとすると、元の記事でも触れられていますがデータの規模や、入力パターンの違いなどから想定外に低い性能になることがあります。
そうした問題を乗り越えて運用されている本手法は、多くの新しい気付きを与えてくれる物となっています。
解説
Pinterest Text-to-SQLの解説と関連する情報について説明します。
問題意識
Text-to-SQLとは?
Text-to-?という形式の言葉は、いろいろな場所で用いられていますが、これはテキストを元に任意の形式に変換するシステム、ないしは変換することそのものを指しています。
そしてText-to-SQLはというと、テキストを入力としてSQL文を作成するもののことです。
以下のようなものがその例です。
「Aさんの書いた記事のタイトルの一覧を確認したいです。」
SELECT a.title
FROM articles a
JOIN users u ON a.user_id = u.id
WHERE u.name = 'Aさん';
Text-to-SQLの必要性は?
Text-to-SQLがなぜ必要なのか?
そもそもSQLが必要な背景には、多くの組織でデータを保持する手段としてRDBを利用していることがあげられます。RDBから適切な情報を得ようとするとSQL文を書き出す必要があるのですがエンジニアであれば、要求に対して必要なSQL文を書き出すのは難しくないでしょう。しかし、要望に合わせたクエリを書き出すのは労力を要しますし、さらにSQL文に慣れ親しんでいない人にとってはクエリを書き出すのは困難でしょう。
そうした観点から、要望に合わせたSQLを自動的に生成してくれるText-to-SQLというのは、多くの組織で重要な役割を果たすと考えられます。
Pinterest Text-to-SQLとは?
Text-to-SQLの必要性の観点から、昔からこの分野の研究は盛んに行われていました。LLMが一般的に登場するようになってからは、さらに応用の可能性が注目されるようになっています。
論文などで精度の向上などが報告される一方で、実際にそれを運用されているサービスのRDBに置き換えてみると、Tableの種類であったり、カラムの多さなどに起因して言われているほどの成果があがらないことがあります。
その中で、Pinterest社は実際のデータベースでPinterest Text-to-SQLの運用を行い、そこで得られた知見を元に改良されたシステムのアーキテクチャを公開しました。もちろん、組織ごとに要件は異なりうまく利用できない場合もあるかと思いますが、より地に足ついた、より現実的な運用の手がかりになると考えています。
手法
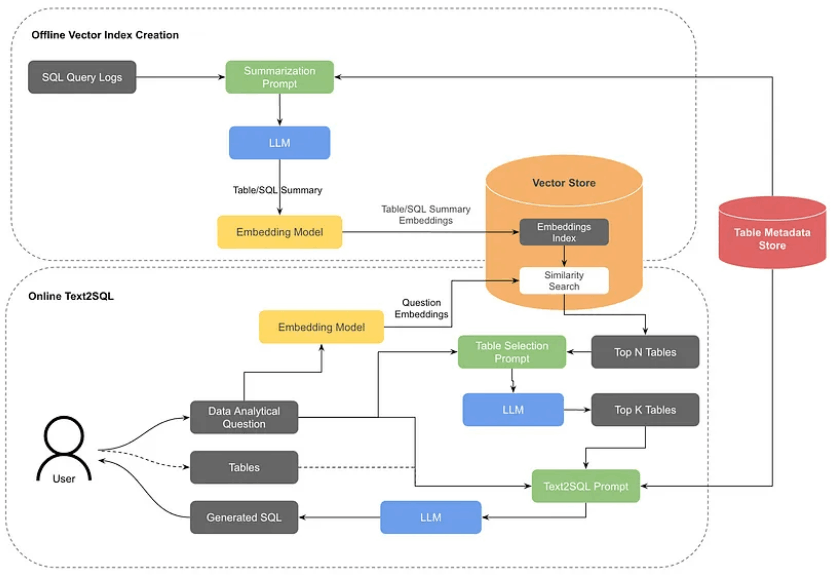
Pinterest Text-to-SQLの詳細な仕組みを解説します。以下の画像のようにいくつかのプロセスに分かれていますが、Text-to-SQLのプロセスとTable検索用のベクトルデータベース更新のプロセスを分けて説明していきます。
Text-to-SQLのプロセス
入力されたテキストが、SQLに変換されるまでのプロセスを解説します。
1. 関連テーブルの抽出
入力されたクエリを元に、Table検索用のベクトルデータベースからセマンティックサーチを行い関連するテーブルを取得します。
Table検索用のベクトルデータベースは以下の二種類存在します。
- Table要約用のベクトルデータベース
Tableごとの要約を作成しそれをベクトルデータベースに保管します。詳細は後ほど説明しますが、カラムの情報や直近のクエリを元にTableの説明の要約を作成し、検索した際に関連するTableが見つかりやすいよう工夫されています。
- クエリ要約用のベクトルデータベース
検索に使用されたサンプルクエリと関連するテーブルの情報を元に要約を作成します。このデータを保管したベクトルデータベースからも同様に関連すると考えられるテーブル情報を取得しています。
これらのベクトルデータベースに検索をかけたうえで、関連度の高いテーブル情報を抽出します。特にTable要約のほうに比重をおいて検索を行い関連すると考えられるテーブルをN個抽出します。
2. 関連テーブルの決定
抽出された最大N個のテーブルから、より関連していると思われるK個のテーブルに絞ります。ここではLLMが使用されており、質問者の入力したクエリとN個のテーブル情報をプロンプトでつなぎ合わせ、上位最大K個の使用するテーブルを決定します。
抽出されたK個のテーブルは一度ユーザーに返され、その後のステップで利用してよいかの確認が行われます。
テーブル決定用のプロンプト
You are a data scientist that can help select the most relevant tables for SQL query tasks.
Please select the most relevant table(s) that can be used to generate SQL query for the question.
===Response Guidelines
- Only return the most relevant table(s).
- Return at most {top_n} tables.
- Response should be a valid JSON array of table names which can be parsed by Python json.loads(). For a single table, the format should be ["table_name"].
===Tables
{table_schemas}
===Question
{question}
最新のプロンプトは以下のリンクから確認できます。
3. 関連テーブルの最終決定とクエリの入力
ユーザーは最終的に利用するテーブルを選択し、さらにクエリを入力することでText-to-SQLのプロセスが開始されます。なお、テーブルを決定するプロセスはユーザーが事前にある程度構造を把握している場合は1, 2のステップなしに指定できるようになっています。
Text-to-SQLには入力されたクエリや、使用するテーブルそしてそのテーブル情報に関するメタ情報をプロンプトでつなぎ合わせてSQLを作成します。
テーブルのメタ情報に関して簡単に補足すると、テーブルのメタ情報は以下のようにものが含まれています。
- テーブル名
- テーブルの説明
- カラム名
- カラムの型
- カラムの説明
メタ情報をLLMのプロンプトに含める際に以下のような問題が想定されます。
- a. フィルタの値が実際に使われてい値と一致しない(システム内ではすべて小文字表記なのにLLMが大文字を使用してしまうなど)
- b. コンテキストウィンドウの制限によりテーブルによってはすべての情報を乗せきれない
この問題に対してPinterest Text-to-SQLでは以下のような工夫が施されています。
- 一部の重要な値は、カラムの説明に値の候補を入力している
- カラムのうち検索に使われづらいものはそもそもデータに含めない
- カラムにタグ付けをしておいて関連していないカラムの情報は含めない
これにより実運用に耐えうるテーブル情報の形成を成功させています。
SQL生成用のプロンプト
You are a {dialect} expert.
Please help to generate a {dialect} query to answer the question. Your response should ONLY be based on the given context and follow the response guidelines and format instructions.
===Tables
{table_schemas}
===Original Query
{original_query}
===Response Guidelines
1. If the provided context is sufficient, please generate a valid query without any explanations for the question. The query should start with a comment containing the question being asked.
2. If the provided context is insufficient, please explain why it can't be generated.
3. Please use the most relevant table(s).
5. Please format the query before responding.
6. Please always respond with a valid well-formed JSON object with the following format
===Response Format
{{
"query": "A generated SQL query when context is sufficient.",
"explanation": "An explanation of failing to generate the query."
}}
===Question
{question}
なお最新のプロンプトは以下のリンク先から確認できます。
Table検索用のベクトルデータベース更新のプロセス
Text-to-SQLのプロセスの解説の中でも簡単に触れましたが、使用するテーブルを決定する上で2つの検索用のベクトルデータベースを作成します。
Table要約用のベクトルデータベース
Table要約用のベクトルデータベースには、よく使用されるテーブルに限定したデータが登録されます。登録の際には、LLMを使用してテーブルのメタデータと、そのテーブルを使用した最新のクエリを複数個とで要約を作成、その要約文をベクトル化し保管しています。
これによりテーブルそのもののデータと、実際に使用されるシナリオが文章中に含まれるようになるため、クエリによる検索の際により関連性の高いテーブルを発見できるようになっています。
Table要約用のプロンプト
You are a data analyst that can help summarize SQL tables.
Summarize below table by the given context.
===Table Schema
{table_schema}
===Sample Queries
{sample_queries}
===Response guideline
- You shall write the summary based only on provided information.
- Note that above sampled queries are only small sample of queries and thus not all possible use of tables are represented, and only some columns in the table are used.
- Do not use any adjective to describe the table. For example, the importance of the table, its comprehensiveness or if it is crucial, or who may be using it. For example, you can say that a table contains certain types of data, but you cannot say that the table contains a 'wealth' of data, or that it is 'comprehensive'.
- Do not mention about the sampled query. Only talk objectively about the type of data the table contains and its possible utilities.
- Please also include some potential usecases of the table, e.g. what kind of questions can be answered by the table, what kind of analysis can be done by the table, etc.
なお最新のプロンプトは以下のリンク先から確認できます。
Query要約用のベクトルデータベース
Table要約用のベクトルデータベースとは別に、サンプルクエリを使用して関連するテーブルを発見するためのベクトルデータベースも作成します。これにより、目的の類似したクエリに対して関連するテーブルを発見することができるようになります。
Query要約用のプロンプト
You are a helpful assistant that can help document SQL queries.
Please document below SQL query by the given table schemas.
===SQL Query
{query}
===Table Schemas
{table_schemas}
===Response Guidelines
Please provide the following list of descriptions for the query:
-The selected columns and their description
-The input tables of the query and the join pattern
-Query's detailed transformation logic in plain english, and why these transformation are necessary
-The type of filters performed by the query, and why these filters are necessary
-Write very detailed purposes and motives of the query in detail
-Write possible business and functional purposes of the query
なお最新のプロンプトは以下のリンク先から確認できます。
検証と成果
Pinterest Text-to-SQLが現在の仕組みに至るまでには、いくつかの検証が行われその検証の中で決定された仕組みがあります。
1. 既存手法の再現と問題の特定
Pinterest Text-to-SQLの実装を進めていくにあたって、まずは既存の手法を利用し再現を行なうところから始めました。その結果、既存の研究によく用いられるデータセットを利用することで、既存手法で言われている様な成果を上げることに成功しています。その一方で、実際のサービスに使われているテーブルをそのまま流用しようとすると問題が発生しました。既存のデータセットではテーブルの数が少なく、問題がテーブルありきで作成されているため、実際にPinterset Text-to-SQLを利用するユーザーの解決したい課題と比較して大幅に簡単であったことに起因していると考えられます。
この様な問題をかかえつつ、実際の現場で運用を開始してみたところ、生成されたSQLが一回目の生成で必要としたものになる確率は最終的におおよそ40%でした。そして、多くの場合では複数のやり取りを繰り返すことで最終的なクエリに到達しました。加えて、クエリの生成がうまくいくまでの時間はおよそ35%程度も改善されています。ただし、一般に論文等で報告されている、完了速度が50%上昇したといったものと比較すると程度は小さいものであり、これは上でも触れた通り実データとのギャップによるものと考えられます。
2. テーブル検索機能の検証と改善
Pinterest Text-to-SQLでは、テーブルとサンプルクエリをベースとしたTableの検索機能を採用しています。検証の上でこれまで使用されたクエリを参考にして検索用のクエリを作成し、それぞれのデータベースの比重を調整しながら、目的とするTableを取得できるかを検証します。その結果サンプルクエリをベースに作成したデータベースから優先的に取得しようとするとTableの取得成功率は40%程度であったのに対して、テーブルの要約をもとに作成されたデータベースから優先的に取得しようとするとTableの取得率は90%程度まで上がりました。このため、実際の運用の中では、テーブルの要約を含むデータベースからの結果を優先しています。
考察
ここからはさらに、いくつかの観点で内容を筆者の視点で深堀りたいと思います。
既存手法とのギャップ
元となる記事を読んで、既存手法と実運用のギャップを正しく認識することの重要性を再認識しました。論文の内容などを元にシステムを実装してみると、期待通りの結果が出ないことは往々にして発生します。
そのときに重要なのは、仮説を立てることとその検証を行なうことです。今回の元の記事ではそれをTableの規模の話や、ユーザーの求める要求の複雑性と仮定し改善を行っています。前者については、Tableの優先度や、関連するカラムに限定して取得できる仕組みを採用することで問題を解消し、後者についてはテーブル決定とSQL生成のロジックを分離することで改善しています。
仮説として考えられる他の問題は、テーブルの構造がLLMが認識し辛くなっていることや、入力が適切でないなどがあり、これらも検証コストと予測される成果を秤にかけて検証してみる必要がありそうです。
使用するテーブルをユーザーに決定させる手法について
初めて元となる記事を読んだときに違和感を覚えたポイントとして、テーブルを最終的に決定するプロセスをなぜユーザーに行わせているのか、という点でした。LLMへの問い合わせを経てTableの候補を出し、そこからTableをユーザーに決定させるプロセスはユーザーへの負担が大きいのではないか、と考えたためです。
しかし、冷静に考えてみるとこの部分は社内の効率化のためのツールという観点では、重要な意味があると考えています。ここからはなぜこの手法が統合された手法と比べて優れていそうと考えたかをまとめます。
1. Table決定の重要性
Table選択に失敗すると、そのままSQL生成の失敗に繋がります。そのため、適切なTable決定は非常に重要です。ユーザーが実際にシステムを使用する場合、Tableの選択をミスするごとにクエリを修正する必要があります。これは特にTableの構造を把握しているユーザーからすると、使いにくさの要因となりえます。このためTableの決定のプロセスを分けることは、運用上重要になってきそうです。
ただし、Tableの選択の精度が改善されれば、この問題は軽減されると考えています。
2. システムの目的
Pinterest Text-to-SQLは、検索したいデータへアクセスするまでの時間を短縮するために導入されました。それを前提にまずシステムの用途を2つ想定します。
- クエリはシンプルだが手書きが面
- ある程度複雑なため、必要なTableの把握からクエリの生成までサポートしてほしい
1つ目の使い方は、必要な情報等は把握しているがSQLを書くのが面倒な場合です。テーブルをあらかじめ把握しているので、Tableが直接指定できることで目的とするSQLをすぐに生成することが可能そうです。
2つ目の使い方は、Table取得が難しく、正しいTableを取得するまでに繰り返しクエリを調整する必要があります。この場合プロセスが分割されていることで、手戻りを減らすことができそうです。
このプロセスの分割は、Tableの重要性に対して精度が追いついていないことに起因して発生していますが、作業の効率化の観点で見れば適切な手段と言えます。
速度の改善について
Pinterest Text-to-SQLの強みに焦点を当てていましたが、ここではいくつか手法に関する疑問をまとめたいと思います。ここでの観点は、Pinterest Text-to-SQLの速度改善と、効率的な代替案の考察です。ただし実際の運用状況を知るわけでは無いので参考程度にご覧ください。
Table候補の並べ替え
Table候補の並べ替えの手段として、LLMが採用されていますが、入力と内容の類似度による並び替えにはRerankという手法があります。こちらは経験上LLMによる並び替えと比較すると応答が早くなるため速度の改善を考えるうえで大きな候補の一つになると考えられます。そうした手段を比較した結果ないしは、検証に入らなかった理由が気になります。
Table選択の必要性
Pinterest Text-to-SQLでは、一度選択されたTableを再評価して候補を出すという手段を採用しています。しかし、そもそも並び替えや絞り込みは必要なのでしょうか?並び替えのために情報をすべてLLMに与えているので、そのデータをそのままSQLの生成プロセスにいれることも可能なはずです。そうでなくともTableの候補をユーザーに提供するまでのプロセスはLLMを使用しなければより短縮できるはずです。なぜLLMを使用しているのか、その効果の程がわかるとより納得的だなと感じました。
まとめ
改めて以下の記事は、RAGのサービス運用の様子を知ることができる、とても良い記事だと思います。
SQLを扱う人は、昔はエンジニアに限られていたと思いますが、時代がすすむにつれてより多くの人が直接関わるようになっていると思います。
その中では扱いに慣れていないことに起因して、作業が進まなくなるといった事態は増えているかと思います。そうした課題を解決できるというのは、RAGにとって一つの大きなユースケースなのでは無いでしょうか。
今後会社内でも、同じ様なサービスが求められる機会も増えてくることが想定できるので、こうした運用の実体を知れたのはとてもありがたいです。ぜひとも今後の開発の役に立てたいと思います。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion