本記事では、最近流行りの「生成AIエージェント」に替わる「Agentless」(エージェントレス)という手法について、ざっくり理解します。株式会社ナレッジセンスは、エンタープライズ企業向けにRAGを提供しているスタートアップです。
この記事は何
この記事は、ソフトウェア開発自体を自動化する際の新しい手法「Agentless」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもAIエージェントとは?」については、知っている前提で進みます。確認する場合は、こちらの記事などをご参考下さい。
本題
ざっくりサマリー

最近、ソフトウェア開発で生成AIを使うことは当たり前になっています。(GitHub Copilot、Cursor、Devinなど、様々なツールがリリースされています。)
「AGENTLESS」は、ソフトウェア開発を自動化する、という文脈でLLMを使う際の、新しい手法です。イリノイ大学アーバナ・シャンペーン校の研究者らによって2024年7月に提案されました。
Agentless とは、ざっくりいうと、「特定の用途に特化させてLLMを使うなら、AIエージェントで実装しない方が、速度も、性能も上がるよね」という考え方です。
最近、「AIエージェント」という考え方が流行していますが、今回紹介する「Agentless」という手法は、その名の通り、AIエージェント の流行とは真逆を行くものです。
問題意識
ソフトウェア開発の自動化が進んでいます。例えば「Devin」は、自律型AIソフトウェアであり、裏側はいわゆる「エージェント」の仕組みを使った実装になっています。
しかし、「エージェント」にもデメリットがあります。例えば、複数の複雑なツールをLLMに使わせると出力が安定しなかったり、変なところでハマってしまい、無駄にAPIコストを浪費してしまったり。まだまだ完璧ではないです。
そこで今回、「エージェント化せず、むしろ決まったフローの中にLLMを組み込む」という「Agentless」なアプローチが提案されています。
手法
Agentlessは、ユーザーからソフトウェアに関する問題を相談された時、以下の3ステップで、自動的に解決します。
- 絞り込みフェーズ
- 上の画像でいうと上半分。
- レポジトリのファイル群をツリー構造で表現
- LLMとembedding検索を組み合わせて、関係があるファイルを特定
- さらに、修正が必要なクラス・関数まで絞り込み
- 修正フェーズ
- 1で特定した箇所について、修正パッチの候補を複数生成
- diff形式で表現するので効率的

- 検証フェーズ
- 再現テストを自動生成。問題が修正されたことをチェック
- 既にある自動テストも実行し、最適なパッチを選択
Agentlessのキモは、「LLMに、次のアクションを決めさせない」という部分です。ここが、エージェントベースのアプローチと大きく異なる部分です。これにより、「簡単な問題はサクッと安く、間違いなく解いてくれる、難しいときは難しいと白状するAI」が実現する形になっています。
成果
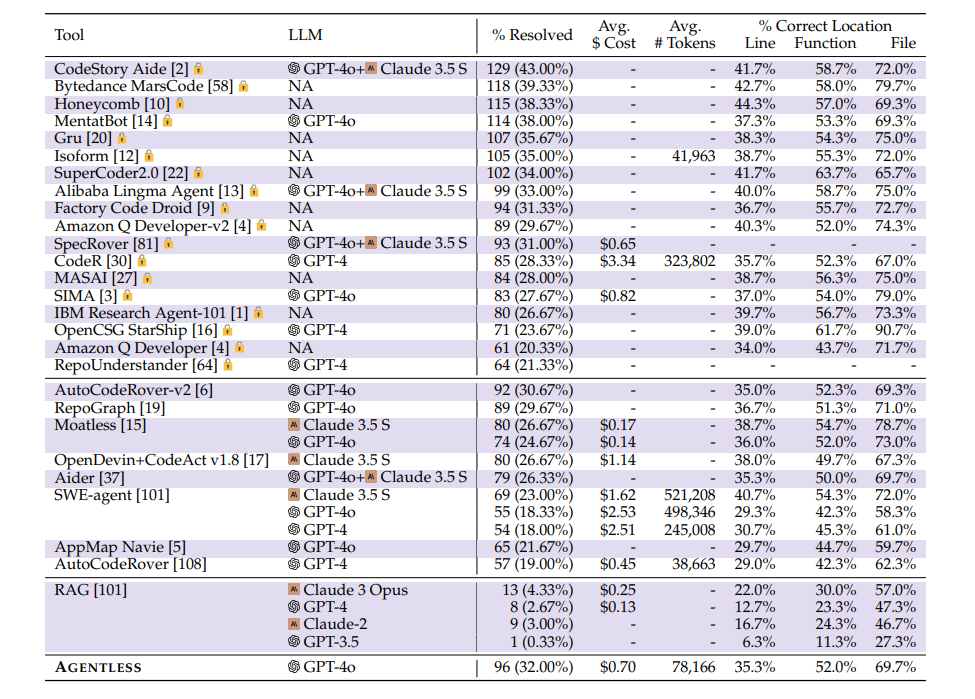
- SWE-bench Liteベンチマーク(300問)において、オープンソースの手法の中で最高性能を達成(32.00%の修正に成功)
- コストも1件あたり$0.70と低コスト
まとめ
弊社では普段、大企業向けにRAGシステムを提供しています。今後は、単なるRAGにとどまらず、「エージェント」と組み合わせたRAGが流行するのではないかと予想しています。
しかし今回の手法は逆に、エージェントを使わずに、普段の業務での課題を解決するという考え方です。
個人的には、エージェント(特に「RAG x エージェント」)の使い所はまだまだあると考えますが、とはいえ確かに、普段の業務レベルでは、Agentlessな手法がかなり使えそうです。
また他にも、Agentlessなアプローチが活躍するのは、社内向けではなく、お客様向けに、生成AIシステムを提供する場合です。エージェントよりも簡単な問題しか解決できませんが、素早く、安定して動作するので、システムに組み込みやすいです。
みなさまが業務で生成AIシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、生成AI・RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion