本記事では、RAGの性能を高めるための「Plan×RAG」という手法について、ざっくり理解します。株式会社ナレッジセンスは、エンタープライズ企業向けにRAGを提供しているスタートアップです。
この記事は何
この記事は、RAGの文脈消える問題を克服する新手法「Plan×RAG」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合はこちらの記事もご参考下さい。
本題
ざっくりサマリー

Plan×RAGは、RAGの精度を上げるための新しい手法です。アールト大学とMicrosoft Researchの研究者らによって2024年10月に提案されました。
ざっくり言うと、Plan×RAGとは、「計画を立ててから検索する」手法です。Plan×RAGでは、ユーザーの質問を、まず最初に小さな単位に分解。その後、それらの関係性を整理して「計画」を立ててから、検索を行います。
通常のRAGの問題点として、「複数の知識を組み合わせなければ正答できない」質問に弱いという点がありました。これに対して、Plan×RAGでは、①質問を小さなサブクエリに分解し、②それらの関係性を有向非巡回グラフ(DAG) [2]として表現(=「計画」を作成)してから検索します。
この「DAGを使う」という点が、この手法のオリジナリティです。こうすることで、類似手法の「Chain-of-Thought (CoT)」[3]や、クエリ分解する手法[4]と違い、回答精度を高く・回答時間は短くできる、というメリットがあります。
問題意識
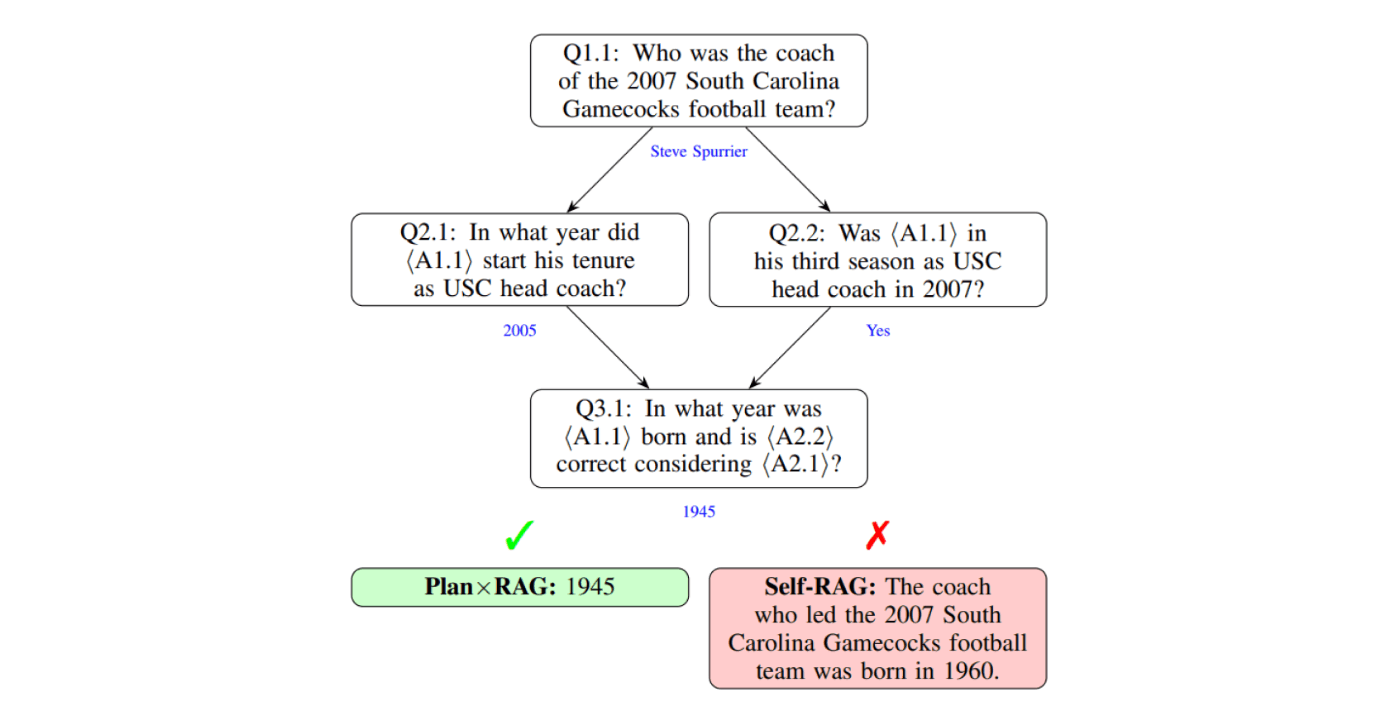
通常のRAGは、「複数の知識を組み合わせなければ正答できない」質問で、回答精度が低くなります。
苦手な質問の例: 「2007年のサウスカロライナ・ゲームコックス・フットボールチームを指揮した監督は、USCのヘッドコーチとして3年目のシーズンを迎えていましたが、その監督は何年に生まれましたか?」
なぜ苦手かというと、通常のRAGでは、「文書検索→LLMが回答生成」というフローであり、このフローでは1回しか文書検索できません。の「1回」だけでは、上記のような、「複数の知識の組み合わせが必要な質問」で、必要な全てのドキュメントを取得することができず、回答精度が落ちます。
最近、これを克服しようとしている手法(CoTやQuery Decompositionなど)は出てきていますが、まだ回答精度がイマイチだったり、回答速度が遅かったりという問題が残っています。
手法
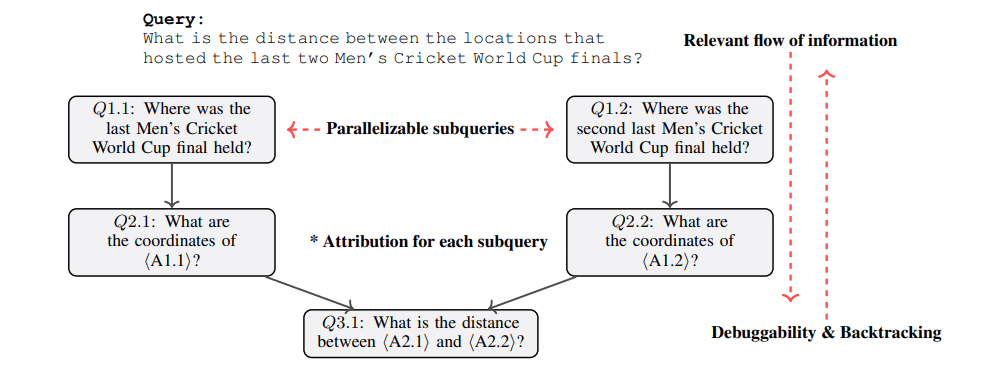
【ユーザーが質問を入力して来たとき】
-
計画(DAG)の生成
- 質問を分析し、サブ質問に分解
- サブ質問間の依存関係をDAGとして表現
- このステップでは、GPT-4oを利用
-
サブ質問を順番に処理
- DAGで計画した順序に従って各サブクエリを処理
- 同じ深さのノードは並列で実行できる(ので、速い)。例えば、上図のQ1.1とQ2.1。
-
各サブ質問での処理
- 各サブ質問では、普通のRAGと同じようにベクトルDBを検索
- 検索後、「Critic Expert」と名付けたLLMが、追加情報の必要性を判断
- 検索後、「Relevance Expert」と名付けたLLMが、関連しない文書を除外
- ここで「Expert」として利用するLLMは、小さいモデル(Llama3-8B)
-
最終回答の生成
- 各サブ質問の回答を統合して、最終的な回答を生成
Plan×RAGのキモは、ユーザーの質問を有向非巡回グラフ(DAG)に落とし込む部分です。これは、単に「ステップ・バイ・ステップ」で考えるだけの「CoT手法」よりも進化した形と言えそうです。DAGに落とし込むことで、並列して考えることができます。並列化のメリットは速さです。より複雑で多角的なリサーチが必要な場合、速く・正確な回答ができるようになります。
成果

- 従来のRAG手法と比較して、ハルシネーションの削減、信頼性の向上、パフォーマンスの向上を達成。
- 特に複雑なマルチホップクエリにおいて、他の最新手法を上回る性能。
- LLMのファインチューニングが必要なく、実装コストも低い。
まとめ
弊社では普段、大企業向けにRAGシステムを提供しています。その中で「複数の知識を併せて回答する必要がある質問に弱い」という問題がたびたび起きます。そういう問題についてはPlan×RAGで対応可能です。
よく考えると、このような「何がわからないのかを明らかにして、順番に処理する」という作業は、普段から人間が行っていることです。例えば、何かのリサーチ中、専門用語が分からなければ、その都度調べるのが普通ですが、逆に、調べないで突き進んだら、最終的なアウトプットの質は低くなります。
このように、人間にとっては自然な問題解決アプローチを、RAGにもできるようにするだけで回答精度が向上するというのは、当然ではありますが、忘れられがちな観点です。
みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion