はじめまして。ナレッジセンスの門脇です。生成AIやRAGシステムを活用したサービスを開発しています。本記事では、RAGの性能を高める手法である「Document Screenshot Embedding(DSE)」について、ざっくり理解します。
この記事は何
この記事は、RAGの文書検索精度を高めるための論文「Document Screenshot Embedding(DSE)」[1]について、日本語で簡単にまとめたものです。
「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は以下の記事もご参考下さい。
本題
ざっくりサマリー
Document Screenshot Embedding(DSE)は、RAGシステムの一部分を効率化する手法です。具体的には、「ユーザーの質問に対して最適な文書を検索をする」部分の性能を高めます。ウォータールー大学の研究者らによって2024年6月に提案されました。
DSEを使うメリットは、文書の中に含まれる画像や表についても考慮して、文書検索できるようになることです(通常のRAGではテキストしか考慮できない)。DSEでは、全ての文書のスクリーンショットを事前にベクトル化しておきます。ユーザーから質問が来たときには、ユーザーからの質問に近いスクリーンショットを検索します。このようにして、画像や図表も考慮した文書検索を実現します。
問題意識
RAG(Retrieval-Augmented Generation)は便利ですが、限界もあります。普通のRAGでは、文書の中のテキスト部分だけをベクトル化し、検索・回答に用います。なので、本来は文書に含まれているはずの画像や表などの情報は、削ぎ落とされてしまいます。
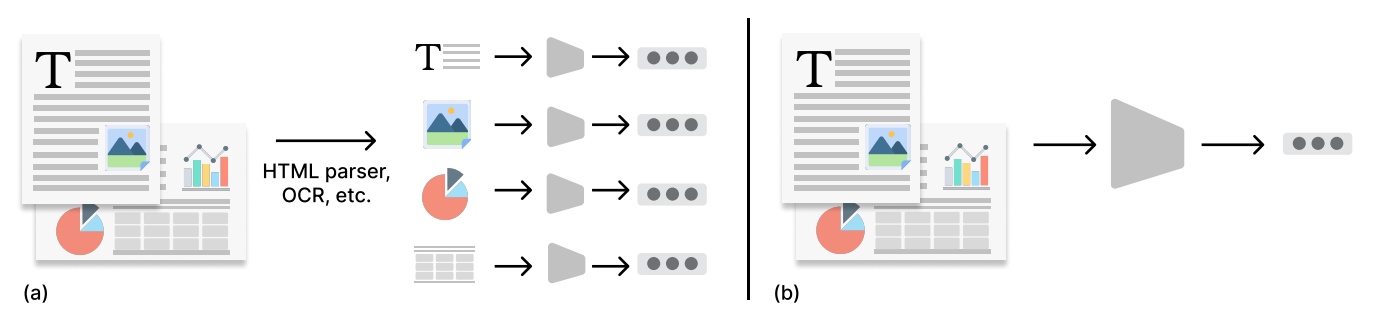
最近ではRAGで、画像や表も考慮できるようにするためのテクニックもあるのですが、個別に面倒な処理が必要になります。(↑の画像の左側、(a)に当たる部分)
そこでDSEでは、スクリーンショットだけをベクトル化・検索に利用することで、個別の煩雑な処理をなくせないか、と試みています。(↑の画像の右側、(b)に当たる部分)
手法
DSEを使ったRAGが従来のRAGと大きく違う点は、ユーザーからの質問に最適な文書を検索する際に、文書中のテキストデータを利用しない点です。DSEをちゃんと説明しようとするとかなり複雑なので、以下、ざっくり理解できる説明を目指します。
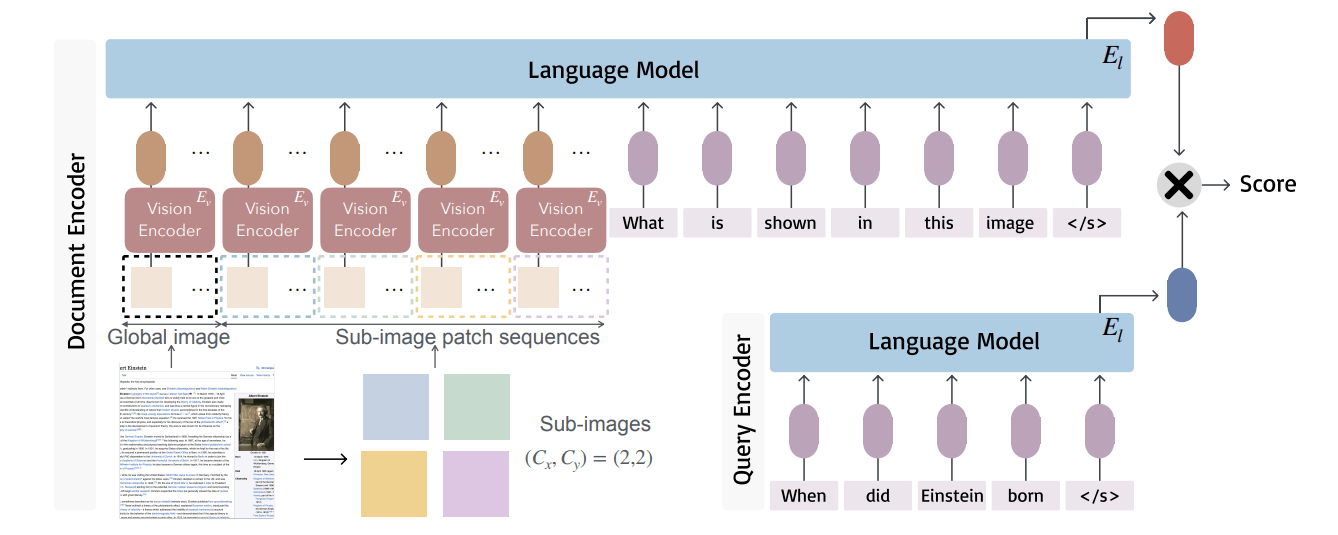
【事前にやっておくこと】
- 回答に使いたいドキュメントについて、スクリーンショットを用意しておく
- スクリーンショット(画像データ)を視覚エンコーダーでベクトル化
- そのベクトルをPhi-3-Vision(マルチモーダルな言語モデル)に入れ込み説明させる
- Phi-3-Visionの最終層の出力(隠れ状態)をそのスクリーンショットのベクトルとする
→普通に出力させたらテキストが出力されてしまうので、その手前のベクトル状態を活用
(※ここまでが、↑の画像の上方「Document Encoder」の説明です。)
【ユーザーが質問を入力して来たとき】
- ユーザーからの質問をPhi-3-Visionでベクトル化する(↑と同様、最終層の出力を活用)
- 事前にベクトル化しておいたスクリーンショットと、ユーザーからの質問のベクトルを使ってコサイン類似度が高いドキュメントを抽出する
また、DSEでは、文書検索までの手法なので、ここで抽出したドキュメントをどのようにLLMに渡すか、ということについては論文中では触れていません。(個人的にはRAG全体として精度高めるにはこの点も重要ではと思います。)
成果
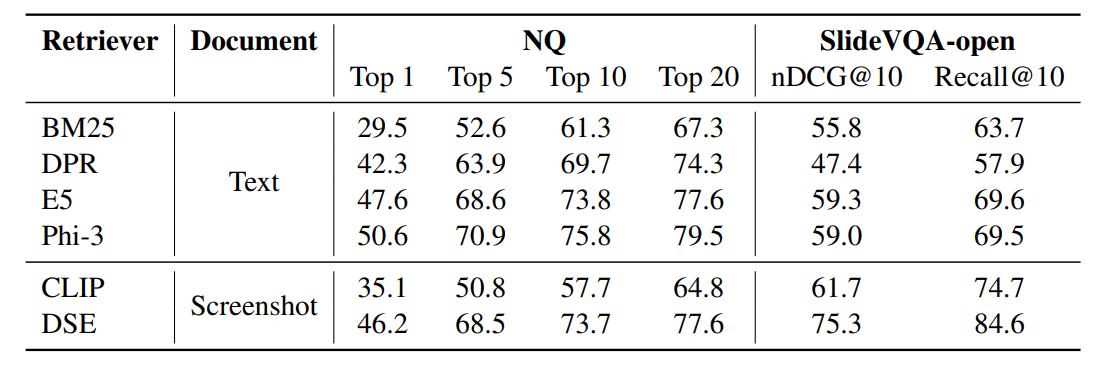
DSEでは、主に以下のような性能向上が報告されています:
- Wikipediaのスクリーンショット130万件から検索するタスクにおいて:
- DSEはBM25を大幅に上回り、ニューラルRetrieverとも同等
- とはいえPhi-3だけでベクトル化した手法(つまりスクショを使わない)に劣る
- パワーポイントのスライドを検索するタスクにおいて:
- DSEはOCRベースのテキスト検索手法を大幅に上回る
- Phi-3だけでベクトル化した手法にも勝利
まとめ
DSEの論文を初めて読んだ時、かなり「面白い!」と衝撃を受けました。とはいえ、ちゃんと理解しようと思うとかなり複雑なので、ざっくり理解できればOKだと思います(実際、色々な説明を省略しました)。また、普段のRAG業務で実際に精度向上できるのか、についてはまだまだ検証が必要なテクニックです。
DSEの面白い点はいくつもありますが、従来のRAGでは使い物にならなかったデータを活用できるかも知れない、という点も重要です。大企業の方とお話していると、「紙の書類をスキャンしてPDFにしただけのデータ」が大量に眠っているという話題になります。DSEではこういう、OCR処理されていないデータも活用できる可能性があります。
みなさまが業務でRAGを構築する際も、精度を上げる工夫として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていきます。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion