本記事では、社内に散らばる非構造的なコミュニケーションデータ(暗黙知)を、AIを使って整理 し、RAGで活用しやすくする手法について、ざっくり理解します。
株式会社ナレッジセンスは、「エンタープライズ企業の膨大なデータを掘り起こし、活用可能にする」プロダクトを開発しているスタートアップです。
この記事は何
この記事は、メール文面・チャットログのような「非構造データ」を、RAGに使える知識ベース(構造化データ)に自動で変換するマルチエージェントシステムの論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は、こちらの記事もご参考下さい。
本題
ざっくりサマリー

今回の手法は、社内のサポートチケットやチャットログのような、整理されていない「暗黙知」 を、AIエージェントを使って RAGで使える「形式知」 に自動で変換する手法です。Amazonの研究者らによって2025年6月に提案されました。
この手法では、3つの「AIエージェント」が連携します。
まず、①「カテゴリ発見エージェント」が元の膨大なデータを分析して、カテゴリを構築します。②次に、「分類エージェント」が各データを適切なカテゴリに仕分けます。③その後、「知識生成エージェント」が、各カテゴリから重要な情報だけ要約して、ナレッジ記事を作成します。
問題意識
人類には、「暗黙知」という未解決問題があります。
大企業だと「あるある」なのですが、貴重なノウハウが、特定の「ベテラン」の頭の中にあります。あとは、過去のメール/チャットの中に埋もれてしまっています。
こういうデータは、 そのままRAGのソースにした場合でも、「ある程度」回答可能 です。ただし、こういうメールやチャットのデータは、ノイズが多かったり、体系化されていなかったりで、RAGの回答精度も低くなってしまうことが多いです。
今回の手法では、こういう非構造データを 「事前にAIエージェントで整理して、RAGの回答精度を上げる」というコンセプトです。
手法
この手法は、RAGの事前準備を工夫する手法です。3ステップです。
(※上の図解は、Amazonのサポートチケットを形式知にする例。)
【事前にやっておくこと】
-
カテゴリ発見
- 「カテゴリ発見エージェント」が、膨大なデータを見てカテゴリーを作成。
- (例えばAmazonの顧客対応に関するチケットを整理するなら、「システムアクセス障害」や「在庫管理エラー」などに分類)
- いわゆる「分割統治法」で大規模データを「分類→マージ」していく。
- 分類
- 「分類エージェント」が、改めて全てのデータを読み、1で作成されたカテゴリの中から最も関連性の高いカテゴリに割り当て。
- 知識の統合
- 「知識生成エージェント」が、カテゴリごとに一つずつ、ナレッジ記事を生成。
- カテゴリのデータが多すぎた場合、サブカテゴリに分けてから、それぞれナレッジを作成。(※上図の黄色いBox部分の話)
【ユーザーが質問を入力して来たとき】
(ここは通常のRAGと同じ。なので省略)
この手法のキモは、カテゴリー作成を自律的なエージェントに任せていることです。これを人間がやるとなると、膨大なデータに全て、目を通す必要があり、かなりコストがかかります。適当にAIに任せてしまうと、カテゴリ分けの精度が甘くなってしまうのですが、今回の手法では、この問題を「分割統治法」を使って解決しています。
成果
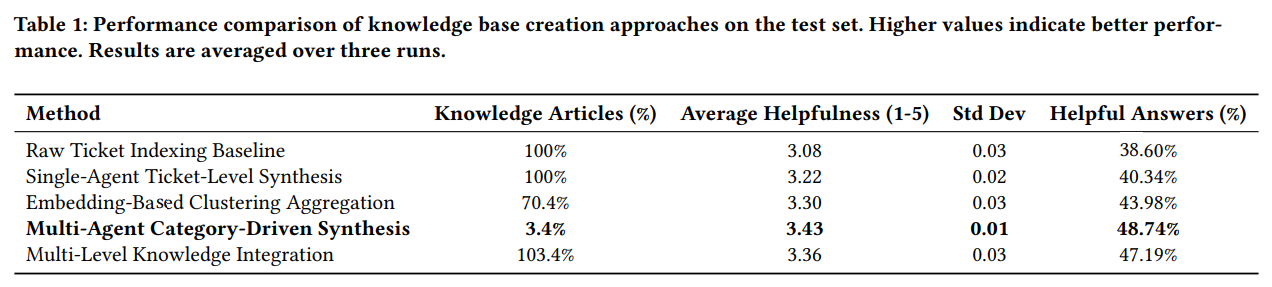
- 元のチケットデータの総量に対して、知識ベースをわずか 3.4% のコンパクト化
- 従来のRAGに比べて、有用な回答の割合が 38.60% から 48.74% へと大幅に向上
- 「全く役に立たない」と評価された回答は 77.4% 減少
将来的には、サプライチェーンに関する問い合わせの約 50% が、この仕組みによって自動解決出来る可能性があるとのことです。
まとめ
弊社では普段、エンタープライズ企業向けにRAGサービスを提供しています。RAGで度々課題になるのは、メールやチャットのような「ハイコンテクスト」になりがちなデータに基づいて回答させたい場合です。こういうデータ、従来のRAGのような処理の仕方だと、回答精度がイマイチ上がりません。
そこで、「AIが膨大なデータを事前に読んだ上で、自律的に抽象化して、知見化してくれる」という今回の手法は、こういう非構造データを整理したい時、ぴったりの手法です。
ぜひ、みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion